Avec l’arrivée récente de différentes réglementations impactant les données (RGPD, Bâle III, Bâle IV, BCBS 239), il est devenu primordial de connaître son patrimoine de données afin de pouvoir identifier et appliquer les bonnes politiques de gouvernance de la donnée (qualité, sécurité, accessibilité). Il faut que les entreprises voient cette contrainte comme une opportunité qui leur permettra à terme de faciliter leurs différents projets de transformation et de mieux valoriser leurs données.
Quel Data Scientist ou Responsable de Traitementmétier ne s’est pas interrogé sur la source d’une donnée à utiliser pour son cas d’usage ? Comment connaître son origine et son cycle de vie et s’assurer de sa qualité ? Comment savoir, au sein d’une entreprise, qui est le Data Owner sur une donnée en particulier ? Ou trouver le glossaire des termes métier associés à cette donnée ? Comment montrer à un RSSI, un DPO ou un Régulateur que les mesures de sécurité liées à une réglementation ont été associées à une donnée et mises en œuvre ?
C’est là où une solution de Data Catalog (ou catalogue de données) devient essentielle et peut vous aider à répondre à ces différentes questions. Celui-ci deviendra la base d’information centrale, un peu comme une bibliothèque, qui vous permettra de rechercher, trouver et connaître les bonnes sources de données pour vos cas d’usages Big Data ou vos traitements métiers. Ceci permet de regrouper les données au sein d’un même référentiel, de collecter, d’enrichir et de partager toutes les métadonnées associées.
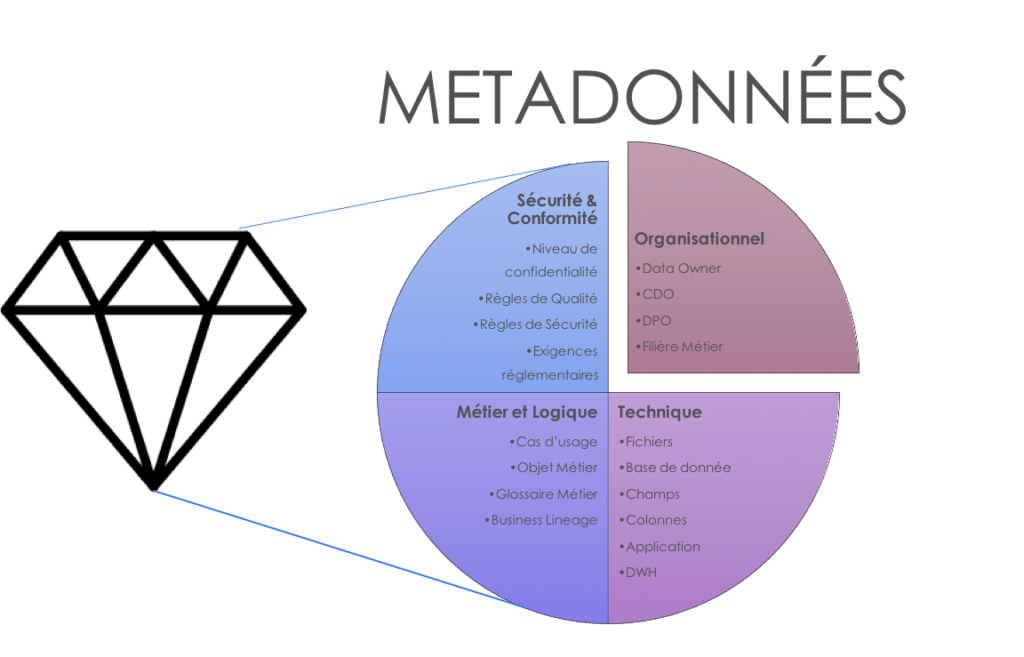
Figure 1 – Exemple de métadonnées
Mais comment faire pour s’y retrouver ? Les différentes offres du marché se vantent toutes de pouvoir gérer et maîtriser votre patrimoine de données, générant, ainsi, de la valeur. Il faudra d’abord définir le périmètre de la gouvernance de données à mettre en œuvre et recueillir les exigences fonctionnelles et techniques. Ce qui suit vous aidera ensuite à comprendre ce que pourra couvrir une solution « Data Catalog ».
La fonctionnalité de base est déjà de pouvoir récupérer automatiquement les métadonnées techniques, c’est-à-dire les informations décrivant vos données d’un point de vue infrastructure (fichier, base de données, table, colonne, etc). Les éléments différenciant pour le choix de la solution vont dépendre de votre écosystème et des connecteurs nécessaires. Est-ce que vos données sont structurées, non structurées ou sont-elles sous format document ? Est-ce que vos données sont contenues dans des bases de données SQL ou noSQL ? Quel socle technologique Big Data utilisez-vous ? Avez-vous des données dans des Cloud Public ? Comment transporter ou partager vos données ? Via des traitements spécifiques, un ETL, un ESB ou via une API Gateway ?
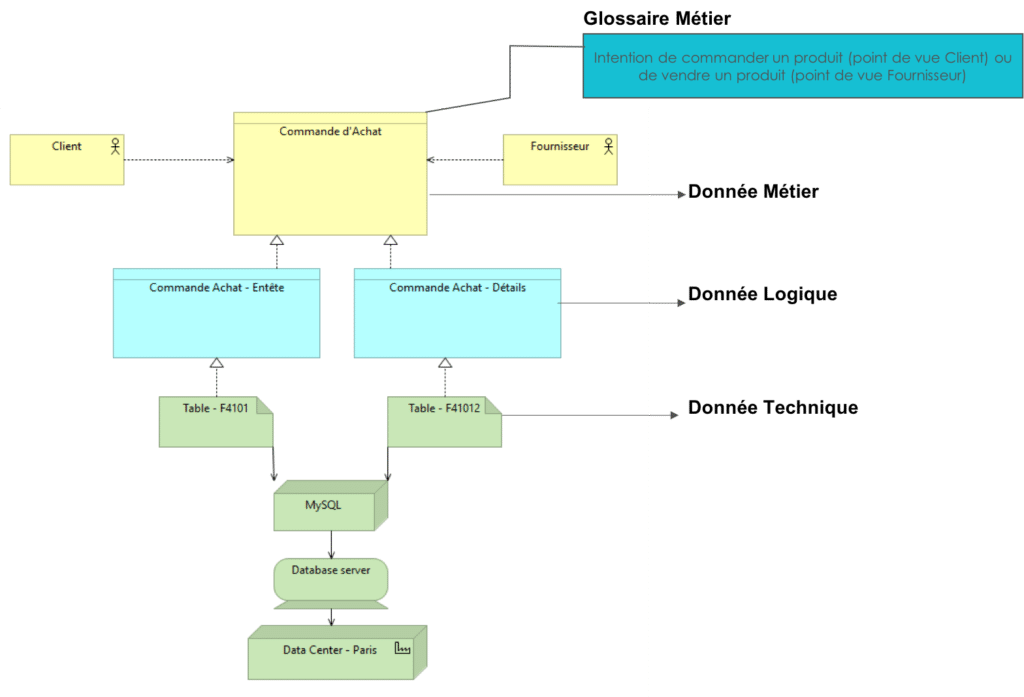
Ces métadonnées décrivant vos données techniques comme un dictionnaire devraient être reliées à une donnée logique et une donnée métier qui sera elle-même à l’aide d’un glossaire métier.
Figure 2 – Architecture de Donnée
Un cadre de gouvernance des données avec une organisation, des acteurs, des processus et des livrables documentaires doit aussi pouvoir être décrit et déployé via un métamodèle opérationnel .
Ce métamodèle implémenté dans l’outil devra permettre de gérer des rôles et des organisations afin de pouvoir définir des responsabilités pour appliquer cette gouvernance de données. Celle-ci ne pouvant être mise en œuvre que si la donnée a d’abord été classifiée et que des politiques de gouvernance liées à un référentiel d’entreprise ou demandé par un Régulateur ont été identifiées et reliées à cette donnée métier. Tout ceci n’étant possible que si l’outil permet de gérer un modèle opérationnel de gouvernance des données personnalisables.
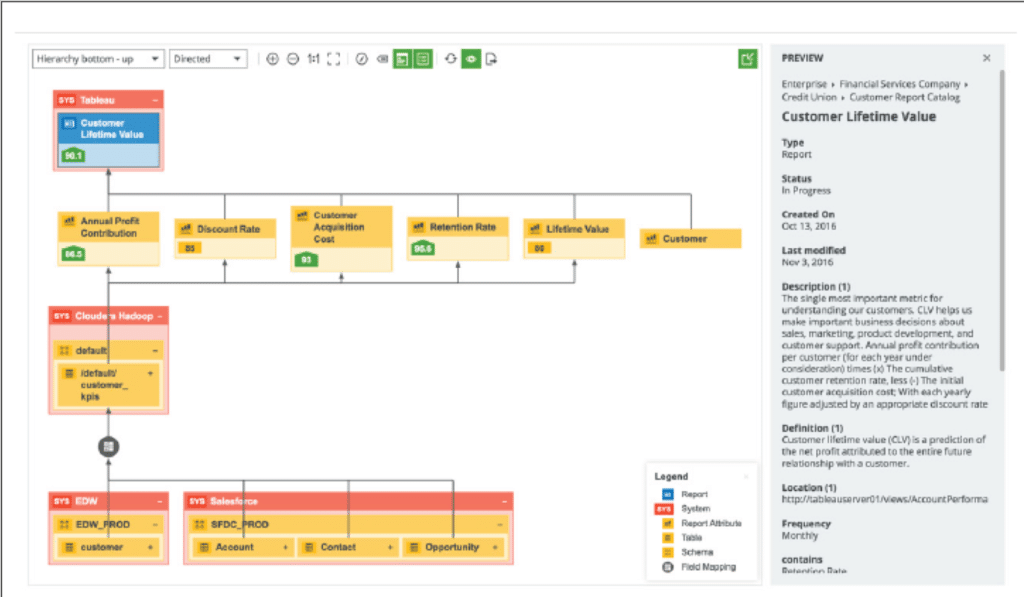
Parmi les autres fonctionnalités attendues pour cet outil il y a également la capacité de générer des états de Data Lineage.
Figure 3 – Exemple de Data Lineage
Cette fonctionnalité est majeure et permettra de traduire visuellement la vision 360° de vos données. Ceci vous habilitera par exemple à réaliser des analyses d’impact en cas de changement sur un système aval vous fournissant la donnée. Ces états peuvent vous aider également à analyser l’écart entre deux KPIs ou de répondre à une exigence réglementaire demandant de documenter de bout en bout comment tel indicateur aura été généré. L’outil vous permettra aussi d’avoir une vision sur la qualité de ces données via par exemple du data profiling ou des indicateurs. Ceci permettra de faire gagner du temps à vos Data Scientist pour sélectionner l’algorithme le plus approprié ou motivera votre Data Steward à sélectionner le jeu de données le plus approprié pour votre cas d’usage ou traitement métier.
Figure 4 – Exemple de Data profiling
Enfin pour terminer, cet outil devra être accessible via une application web, fournir un moteur de recherche et proposer un référentiel de cas d’usages avec les sources de données associés. Ceci activera le partage de la connaissance de ce patrimoine au travers de votre organisation et l’identification des sources de données critiques à vos traitements métiers. A terme, ce patrimoine permettra plus facilement aux métiers de générer de la valeur pour votre entreprise tout en maitrisant les règles de sécurité et accessibilité de cette donnée.
Voilà pourquoi le Data Management ne peut plus se faire via un tableau Excel et qu’un catalogue de donnée devient essentiel.
Les autres articles qui peuvent vous intéresser
Ce que tout le monde devrait savoir de l’agilité en 2017
Ce que tout le monde devrait savoir de l’agilité en 2017
La mise en place de la pensée agile, c’est comme un Paris-Brest : on peut choisir le savoir-faire de l’artisan, ou bien l’industrialiser et le vendre en surgelé. Pour ma part, je préfère la première version… J’aurais pu choisir la métaphore du kouign amann, mais je ne veux pas visualiser le blasphème de sa congélation…
Dans cet esprit, je partage avec vous ici quinze idées de clarification qui me paraissent fondamentales pour vraiment obtenir ce que l’agilité promet, quinze idées qui ont tendance à disparaître quand on industrialise trop l’activité de conseil en transformation.
La majorité de ces idées relèvent du bon sens… quand on vit dans un contexte déjà agile, mais il ne faut pas oublier les autres organisations qui doivent vivre avec leurs cultures et leurs réflexes inconscients. L’héritage inconscient (la force des habitudes) en matière de méthodes de décision et de management devient un élément prépondérant, et ces cultures interprètent à leur façon le nouveau paradigme. Le problème apparaît quand leur interprétation s’enkyste : elles finissent se convaincre qu’elles se sont transformée et devenue agile dans leur ADN, alors qu’elles n’ont fait que surfer sur l’idée, à la limite du détournement de sens… et il faut reconnaître que beaucoup d’organisations s’arrêtent au milieu du gué de leur transformation !
Une vision trop rapide des équipes agiles peut donner l’impression des symptômes de la réunionite. Certains croient que Scrum exige de 5 à 10 h de réunion par semaine à tous les développeurs. Au risque de vous perturber, il n’y a au contraire plus aucune réunion ; plus aucune réunion mais beaucoup d’ateliers. Dès qu’on se met ensemble, ce n’est pas pour parler, mais pour produire quelque chose. Et pour rendre les choses factuelles :
Stand up : 15 min par jour
Sprint planning + demo + retro : 5h par 3 semaines…et ce sont ces rituels/ateliers qui empêchent les développeurs de s’enfermer dans la myopie du quotidien. Si vous voulez de l’information sur l’avancement de l’équipe, allez voir directement son « radiateur d’information » : aucune réunion n’est nécessaire pour ça.
L’agile qui se limite au développement applicatif oublie tout le reste de la chaîne… Il faut s’intéresser à l’ensemble du cycle de vie du produit et de la façon dont il répond au problème des clients. Si on laisse les développeurs dans un bocal hermétique, en s’assurant que l’agilité ne perturbe pas le reste de l’organisation, on construit une vérité schizophrène… On ne peut pas être agile sur un seul segment de la chaîne de valeur.
En agile, le rôle fondamental de chacun envers tous les membres de l’équipe de développement est de dédramatiser les « fails » : un échec, c’est bien si on tombe très vite avant de se faire trop mal. Et si on en apprend quelque chose. Sinon, on fera mieux la prochaine fois, mais on en parle ensemble pour que chacun en retire quelque chose.
La logique de timebox s’inspire effectivement – entre autres – du fonctionnement des sections spéciales US en particulier, mais cela ne justifie en rien un rythme insoutenable. Après une mission, ces dernières ne retournent pas dans un régiment classique. Un sprinter de 100 m ne passe pas les 24h de ses journées à courir de façon maximale. Il y a des temps de relaxation, des temps de récupération active, des compétitions sans enjeu, et des compétitions essentielles. De même, le management autour de Scrum doit s’assurer que ces alternances sont réelles. Il y le temps de la production de code opérationnel, il y a le temps du team building et le temps de l’amélioration en compétence (clin d’œil à nos amis du Craftmanship !).
De la même façon, il n’y a pas de notion d’urgence dans la réalisation d’un sprint (ou d’une mission) : seul l’impact compte ; le sprint est un mot qu’il aurait mieux valu traduire par « timebox » et qui oblige à se poser régulièrement, quel que soit l’état d’avancement, pour relever ensemble la tête du guidon.
Il n’y a pas de « war room » pour les sections spéciales ; la « war room » est l’organe de pilotage pour les officiers supérieurs qui dirigent des campagnes militaires et pas des missions individuelles. De la même façon, les « radiateurs d’information » et les stand up ne sont absolument pas des « war rooms », mais des points de coordination et des opportunités de travailler au quotidien le team building. Dans les sections spéciales, on parle de briefing et de « l’intention du commandement sur l’effet majeur ». On parle de l’essentiel pour la mission en cours. La stratégie, c’est pour le sprint planning et la démo.
La logique agile n’est surtout pas « customer first » ou « customer only » : au contraire, il s’agit maintenant de répondre de façon équilibrée à toutes les parties prenantes, et pas uniquement l’utilisateur final le plus évident (rem : le management interne est une partie prenante). Si les arbitrages ne se faisaient que dans l’intérêt exclusif d’un client, on laisserait ce dernier arbitrer. Si la demande à prendre en compte venait uniquement des utilisateurs finaux, une équipe de « business analysts » suffirait et il n’y aurait pas besoin de Product Owner.
La sociabilité « obligatoire » de l’agile est plutôt le retour à ce qu’il était normal d’avoir avant la spécialisation des ouvriers du modèle Fayol/Ford. Dans un monde « normal », où l’on ne peut pas supposer que chacun est essentiellement indépendant de tous les autres, il faut savoir parler, motiver, influencer, recadrer, écouter, être écouté… On ne peut plus se cacher derrière des processus aussi pléthoriques que mal maîtrisés pour se déresponsabiliser.
Les paradigmes classiques RH et hiérarchiques deviennent effectivement obsolètes tel quel : il ne peut plus y avoir de pilotage de gestion de carrière, ni de détection des « High Pot ». On va plutôt créer et nourrir un système d’interrelations entre personnes qui permet l’émergence de l’intelligence collective, et que l’innovation ne s’arrête jamais. On va chercher des talents pour aiguillonner les réflexions, plutôt que de trouver des profils trop compatibles. On devient beaucoup plus exigeant sur la motivation à apprendre collectivement que sur la production immédiate de valeur. Une personne n’est pas incompétente par son incompétence technique uniquement, mais surtout parce qu’elle n’est pas intrinsèquement motivée pour apprendre et transmettre son savoir
Les réflexes comportementaux qui viennent du paradigme bureaucratie/spécialisation sont effectivement un sujet : il faut souvent les accompagner pour qu’ils apprennent à se responsabiliser sur ce qu’ils sont et comment ils sont influencés. En particulier, chacun doit être responsable de sa propre protection, de son propre bien être, du respect de ses valeurs. Plusieurs méthodes, qui incluent des étapes de coaching personnel et de groupe, sont raisonnablement efficace.
On reproche – entre autres – à l’ancien système d’induire une hiérarchie de valeur : le plus noble étant dans la contact proche du client et l’écriture de son besoin, et le moins noble, au fond de la soute étant le développement logiciel, la maintenance et la production. Des développeurs juniors s’enfuient vers les MOA avant de devenir de bons codeurs ; de bons chefs de projets deviennent des experts du contentieux contractuel avant de savoir gérer des dynamiques de groupe. En agile, comme on aime bien les réponses extrêmes et réalistes, on automatise tout ce qui est de faible valeur. On ne donne aux Hommes que ce qui nécessite vraiment des neurones. Ecrire des tests est une activité critique : on met plusieurs cerveaux autour de la table. Passer des tests ? Un click… et des automatismes qui savent très bien faire ça sans nous.
Oui, on a besoin de beaucoup moins de types d’acteurs… les experts isolés n’ont plus leur place. Des profils disparaissent. Ou ils deviennent coachs/mentors sur plusieurs équipes, ou ils font évoluer leurs compétences en « T-shape » pour être utile dans une équipe. Chacun a une place dès qu’il apporte de la valeur à quelqu’un, et chaque équipe est solide quand chacun individuellement s’enrichit du travail que fait l’équipe et enrichit réciproquement l’équipe par son travail.
J’ai lu quelque part que ce qu’on appelle les « user stories » étaient une énorme manipulation des managers. Il s’agirait d’une escroquerie pour faire coexister des développeurs très bons (qui ont besoin d’une vision globale) avec des incompétents complets (qui ont besoin de faire perdre du temps aux autres en demandant au jour le jour ce qu’il faut faire) … en autorisant ces derniers à se positionner presque ouvertement en passagers clandestins qui usent de leur furtivité en se noyant dans le dans le groupe.
Et bien non encore… Le découpage en « user stories » n’est pas une méthode de management… mais un atelier de design technique. On y utilise l’intelligence collective et des points de vue complémentaires pour réfléchir ensemble sur les solutions techniques possibles. Donner une vision globale au développeur n’est pas jeter des perles à des pourceaux : c’est juste fondamental !
Les technologies utilisables sont tellement évolutives que vous – clients, MOA, Chefs de projet et mêmes développeurs des autres équipes – n’êtes pas les mieux à mêmes de connaître ce qui est le plus pertinent. On reprochait il y a quelques dizaines d’années aux informaticiens d’imposer leurs mots et leurs concepts aux non-informaticiens. Ils ont bien compris le message : ils vous écoutent maintenant. Parlez-leurs de vos vrais besoins ; ne leur parlez pas d’informatique : ils ont l’impression que vous leur parlez d’événements préhistoriques, voir d’uchronies. Non… défragmenter un disque dur ne va pas accélérer votre cloud… Et non encore : ce n’est pas une bonne pratique de faire une multitude de forks de votre code.
La démo en fin de sprint est TOUT SAUF une recette : c’est une occcasion/prétexte de faire du liant entre le client et l’équipe de développement. L’agile va de pair avec le DevOps et donc le Continuous Delivery. Le développeur est anxieux de la démo ? Il vaudrait mieux qu’il soit anxieux — au jour le jour – du risque de laisser prospérer de la dette technique… L’automatisation des tests de non-régression, le monitoring et la qualimétrie lui donnent instantanément, à chaque ligne de code, la portée de ce qu’il fait, et il peut donc agir au moment où son stress est légitime et utile.
La vie en « open space » oblige effectivement un autre savoir-vivre, celui du collectif, de l’équipe, de l’esprit de corps… Le coaching et le team building sont très importants pour éviter les effets de groupe qui peuvent s’emballer… L’esprit de corps, ce n’est pas non plus idéaliste : une équipe de mercenaires peut être très efficace, mais il faut savoir la gérer. C’est probablement un type de compétence que les managers n’ont pas toujours.
Une dernière clarification, qui est plutôt un recadrage…Il faut quand même être très clair : l’agile n’est absolument pas un monde idéal, une utopie fouriériste qui deviendrait possible au XXIème siècle. De la même façon que le cycle en V n’était pas un délire déshumanisé de Saint-Simoniens. Les « passagers clandestins » se font exclure sans autre forme de procès. La motivation peut compenser des compétences trop faibles. Le caractère de chacun est un sujet en soi : toute personne doit se sentir responsable de son intégration et de son utilité, et agir en fonction. Les conflits existent et doivent devenir des opportunités constructives : c’est aussi la responsabilité de chacun d’oser provoquer le conflit utile.
« Il nous faut innover ! Relancer la créativité », tel est le cheval de bataille des entreprises pour « rester compétitives ». Mais force est de constater que les entreprises historiques peinent à bâtir du neuf, à créer ces synergies en interne dont elles rêvent tant : des équipes transverses, cross-fonctionnelles, auto-organisées qui se mettent à monter des projets innovants sans que personne ne leur ait demandé quoi que ce soit.
Or l’innovation ne vient pas des processus*, mais de la capacité des salarié.e.s à penser en dehors du cadre et, plus difficile encore, à exécuter cette même idée dans un environnement hostile à l’inconnu… Mais alors, comment infuser du neuf ?
De manière opérationnelle, faire du neuf signifie notamment favoriser deux phases : l’inspiration et la création. Voici quelques exemples concrets.
#1. Inspiration : organiser des « Learning Expeditions » ou expéditions d’apprentissage
Quel est le pire ennemi des organisations contemporaines dans ce monde « ouvert », « agile », « disruptif » et tout le tralala ?
Le cloisonnement ! Et pour cause, comment créer du neuf si l’on a comme seul modèle d’inspiration le vieux et le poussiéreux que l’on veut changer ?
Or, vous avez peut-être remarqué que personne ne sait réellement ce qui se passe en dehors de leurs murs, chacun fantasme et raconte à la machine à café ce qu’il a entendu du fonctionnement des uns et des autres : « le petit frère du cousin de ma belle-mère travaille chez Google et il paraît que là-bas on innove en faisant la sieste ! ». Ben voyons.
Alors pour explorer de nouveaux possibles et (enfin) innover, les expéditions d’apprentissages sont indispensables ! Prendre du dehors pour inspirer dedans.
Dans les faits, il s’agit d’aller visiter une entreprise libérée* pour s’apercevoir que laisser des salariés s’auto-organiser ne mène pas au chaos ; ou encore d’assister à une conférence chez The Family pour prendre conscience qu’il ne faut pas plus de 48h pour créer un Produit Minimum Viable, l’innovation de rupture de demain !
48h pour monter sa startup https://www.youtube.com/watch?v=ieq4Ugzr8Uw&t=4s
Bref, vous l’aurez compris ces expéditions ont vocation à casser les préjugés de chacun sur ce qui est possible ou non. Et sortir de sa zone de confort.
Astuce : chez Rhapsodies Conseil nous avons construit un calendrier d’inspiration. Par exemple, dans le cadre de notre transformation d’organisation les membres du comité exécutif reçoivent des contenus inspirants sur les entreprises organiques : un jour un contenu qui parle des prises de décisions dans les entreprises libérées ou d’une autre manière d’engager les nouvelles générations.
#contenu inspirant pour changer les pratiques actuelles
*Entreprise dans laquelle chacun est susceptible de prendre toutes les décisions qu’il pense être bonne pour l’entreprise sans en avoir à référer à un supérieur hiérarchique.
#2. Création : organiser un product day
Lorsque j’ai débuté dans le monde professionnel dans une grande entreprise, j’ai eu le sentiment que pour créer quoi que ce soit tout était plus compliqué que dans la « vie réelle ». Par exemple pour ajouter deux fonctionnalités à l’application de ce mastodonte dont je tairai le nom, les étapes étaient les suivantes :
Remplir un dossier avec les spécifications, les risques, etc. ; durée : 2 mois
Envoyer son dossier au comité de pilotage qui se réunit 4 fois par an ; durée : 4 mois
Le projet est rétorqué parce qu’il manquait les notes de bas de page, durée : bien trop longue
Vous l’aurez compris, dans ces conditions ni les entreprises, ni les individus ne s’y retrouvent. Alors voilà comment nous nous y sommes pris pour créer le programme « devenir intrapreneur : de 0 à 1 » sous la forme d’un produit minimum viable lors de notre dernier product day :
Jour 1 :
Interviews pour recenser les attentes des entreprises et des individus #CarteEmpathie
Première curation de contenus (vidéos, article, etc.) sur le thème : « développer un état d’esprit de hacker »
Jour 2 :
Envoi des contenus sous forme d’un mailing à quelques cobayes + recueil des avis + amélioration du premier mailing
Seconde curation de contenus sur le thème : « création de valeur en cycle court » (c’est quoi un produit minimum viable, les étapes pour y arriver, etc.)
Jour 3 :
Envoi d’un second mailing sur la « création en cycle court » + recueil des avis + amélioration du second mailing
Curation de contenu sur le thème : « vendre son projet en interne » (pitcher un projet, fédérer des individus autour d’un projet, etc)
Envoi du troisième mailing sur le thème : « vendre son projet en interne » + recueil des avis + amélioration du troisième mailing
Jour 4 :
Présentation du programme de 40 jours : « devenir intrapreneur » dans son entreprise Il nous a donc fallu 4 jours pour fabriquer un produit minimum viable, c’est-à-dire un produit qui répond aux premiers besoins que l’on avait détecté pendant la phase d’interviews. Un investissement de temps et de moyen faible pour un impact maximum.
Pour aller plus loin !
Favoriser la créativité des individus et du collectif fait émerger des comportements et des pratiques durables liés à une culture d’entreprise où la prise d’initiative et de risque devient la norme. Car comme je l’évoquais en introduction, l’innovation et la créativité sont intrinsèquement liées à la capacité de l’organisation à bâtir un environnement et un état d’esprit favorables à ces prises risques. Et pour cela, la transparence et la confiance ne sont plus seulement des valeurs, mais au cœur de l’organisation et du pilotage de l’entreprise.
*sinon les grandes entreprises seraient championnes du monde de l’innovation ! 😉
L’évaluation de notre RSE par Ecovadis, reçue cette année, nous gratifie d’un 69 /100 qui nous classe parmi les toutes premières entreprises du secteur (le top 5% se situe au dessus de 62). Après les évaluations « Silver » des années 2016 et 2017, nous recevons ainsi le badge “Gold” d’Ecovadis, le plus élevé.
Cette distinction vient couronner l’amélioration continue d’une politique inscrite au coeur de notre ADN depuis 2014. Depuis, nous n’avons cessé de développer la démarche RSE au sein du cabinet : l’évaluation progresse pour la 5ème année consécutive. Nous sommes aujourd’hui heureux et fiers de ce résultat soutenant et récompensant le travail collaboratif et participatif mené par l’ensemble de nos collaborateurs/collaboratrices.
Cette année, nous avons prolongé l’excellent travail déjà réalisé avec un effort particulier consacré à la stratégie RSE des prochaines années. Nous avons ainsi terminé la définition de nos politiques pour l’ensemble des 4 domaines évalués par Ecovadis : social, éthique des affaires, environnement et achats responsables. Nous avons également associé à chacune d’elles les indicateurs permettant d’évaluer et de critiquer notre action, pour contredire l’adage “ce qui n’est pas mesuré n’est pas géré”.
Au delà de cet effort de cadrage, nous pouvons enfin citer quelques actions notables de l’année :
développement de la démarche participative : organisation d’ateliers RSE dédiés à la co-construction des feuilles de route 2018. Ouverts à tous, ils ont réuni 30% des collaborateurs et ont permis de définir et prioriser 12 grandes actions. À ce jour, toutes ont été initiées et 75% réalisées
organisation de groupes de travail dédiés à la valorisation et à l’optimisation des parcours d’intégration et des intermissions
mise en conformité GDPR
mise en place de registres “matières” et “énergie”, afin d’identifier les actions pertinentes permettant de poursuivre la réduction de notre empreinte environnementale. L’achat de nos ordinateurs, thé, café, cadeaux de fin d’année (miel issu de ruches parrainées par l’entreprise) etc. répondent ainsi à des critères environnementaux (et aussi sociaux)
étude approfondie de la performance sociale et des impacts sociétaux des organisations de travail “libérées” afin de développer encore davantage la performance globale de nos clients
et on a même arrêté l’usage des gobelets en plastique
Confortés par ce résultat, nous nous attelons désormais à la définition du plan 2019 et sommes impatients de vous le partager.
Ma série d’articles sur l’Architecture et l’agilité en arrive à son 5ème chapitre. J’ai fait beaucoup de recherches, échangé avec des agilistes et des confrères Architectes. Mais avais-je vraiment pris le temps d’intégrer l’agilité dans mon mode de fonctionnement ? Pris le temps d’en discuter et d’y travailler avec mes équipes ? Et qu’a fait notre cabinet de conseil pendant ce temps-là ? Voici mon retour (d’expérience) sur ce qui s’est passé dans mon écosystème dernièrement.
Avoir dans notre cabinet une équipe dédiée à la Transformation Agile est vraiment un atout dont je n’avais pas encore mesuré toute la portée. L’évolution se fait doucement mais sûrement et en profondeur. Que ce soit par des formations, des conseils ou des exemples, elle se fait sentir à tous les niveaux du cabinet. Nous sommes en train de trouver notre voie et c’est bien là le secret !
Former les managers
En tant que consultant d’abord puis manager, je suis des formations régulièrement. Depuis plus de 15 ans ces formations portent sur mon expertise, l’Architecture, mais aussi sur le métier de consultant et de manager d’équipe.
Notre équipe de Transformation Agile propose une formation au Management 3.0. Comment refuser une telle opportunité ? Prendre 2 jours de réflexion sur ma pratique de management qui n’avait pas évolué depuis quelques années. Avoir les bonnes pratiques et de nouvelles techniques autour du management à intégrer dans mon fonctionnement et celui de mon équipe.
Je pensais bien que le changement était en marche, mais là, j’ai vraiment réalisé le retard que j’avais pris. Nous sommes donc en train de changer notre fonctionnement interne, nos modes de réunions, de travail etc. L’équipe en parlera surement plus en détail dans un prochain article.
Je ressemble à ça maintenant, j’ai bien changé, non ?
La formation pour tous, mais laquelle ?
En parallèle, la réflexion m’avait mené aussi sur la formation des consultants vers l’agilité et les changements que cela implique. Quelle formation ? Pour quel but ? Pour commencer, 2 formations fondamentales tiennent la corde. Elles correspondent aux 2 rôles principaux des projets agiles aujourd’hui : le Scrum Master et le Product Owner.
Les 2 formations sont pour partie les mêmes. Les bases de l’agilité y sont présentées. La suite diffère selon le rôle que l’on est amené à jouer. Est-ce que vous allez travailler en tant que responsable du produit ou en tant qu’animateur du projet ?
Le Product Owner se focalise sur la valeur, les finances, la stratégie, et est connecté avec les différents intervenants et clients autour du projet.
Le Scrum Master est un facilitateur de l’atteinte des résultats, un leader non autoritaire qui connecte les gens et les aide à tirer le meilleur d’eux-mêmes dans la constitution de l’équipe. Il est là pour catalyser les résultats.
Pour le métier d’Architecte, les 2 aspects semblent importants. Dans ce cas, pourquoi choisir ?
Nous avons alors pris le parti de former certains architectes en Scrum Master et d’autres en Product Owner. L’avenir nous dira si nous devons compléter par la suite la formation des uns ou des autres.
L’essentiel est de se lancer.
Nous ferons au fur et à mesure des projets et des missions, les constats et les retours d’expérience des uns et des autres sur l’utilité et la spécificité de chacune des formations (par exemple, sous le format des rétrospectives présentées dans SCRUM !)
La détection des faux positifs
Maintenant que nous sommes formés à l’agilité, que nous en connaissons les principes, le 1er changement qui nous vient à l’esprit est de détecter tous les projets qui se prétendent Agile (le terme étant très galvaudé en ce moment) et qui ne le sont pas. Et surtout de pouvoir dire en quoi ils ne sont pas agiles.
Un projet qui conserve un découpage de ses travaux en lots. Un projet sans autonomie. Autant de projets avec lesquels nous travaillons, qui se prétendent agiles, voire sont convaincus de l’être.
Nombreux sont les exemples que nous voyons dans les entreprises au quotidien.
Un des principaux défauts, que j’avais souligné dans un article précédent, est qu’il est très difficile pour un projet d’être vraiment Agile si les managers ne le sont pas et ne font pas évoluer leur posture.
Même s’il est toujours aussi difficile de travailler avec ces projets, au moins nous pouvons échanger avec eux, les aider aussi et peut être trouver des axes d’amélioration ?
Et au niveau du cabinet, le LAB !
En parallèle, notre cabinet a initié une pratique de Lab : dispositif de créativité, de co-construction et d’intelligence collective aussi bien orienté vers l’interne que vers l’externe. Les initiatives sont venues, les projets ont commencé, les premiers résultats arrivent. La dynamique est en place et le mode de fonctionnement se rode.
Il y aura des réussites, des échecs, mais surtout plein de belles histoires.
Mais le plus important dans tout ça, ce n’est pas le Lab, c’est bien le symbole. Dans notre cabinet, comment trouver une place dédiée pour le Lab où nous puissions travailler avec les bons outils ? Le seul endroit qui s’y prêtait était déjà occupé. Et pas par n’importe qui, pensez donc : le président et ses 2 DG Adjoints. Ce sont eux-mêmes qui ont proposé de laisser leur bureau pour le Lab.
Si ça, ce n’est pas un changement visible !
Fini la V1, vive le MVP !
Dans l’ancien mode de fonctionnement d’un projet, nous annoncions toujours la mise à disposition d’une V1, complète et exhaustive. Elle prenait du temps et consommait des ressources. Pour un résultat rarement satisfaisant.
Avec l’agilité, nous faisons des MVP (Minimum Viable Product). Un produit suffisamment complet du 1er coup pour qu’un client y trouve de l’intérêt (juste les bonnes fonctionnalités). Pas avec toutes les fonctionnalités bien sûr mais plus qu’une V1 bancale. Une approche qui oblige à se focaliser sur l’essentiel.
Nous essayons de démocratiser cette approche pour tous nos projets, y compris pour nos projets en interne.
Et cela fonctionne mieux. Les MVP sont mieux acceptés, consomment moins de ressource, apportent plus de retours d’expérience.
Est-ce que ça change vraiment ?
Oui ça change. Surtout la perspective avec laquelle on aborde les sujets.
La mise en pratique se fait avec un plus grand partage de toutes les informations. La transparence est primordiale.
Les échecs sont permis. On apprend à marcher en tombant. Il faut essayer. Les nouveaux modes de fonctionnement ne marchent pas du 1er coup ? Quoi de plus normal. Apprendre de nos erreurs et continuer à avancer.
La confiance était déjà de mise dans notre cabinet mais le management agile va encore plus loin.
Ne plus imposer mais fournir les informations pour que chaque niveau puisse décider de son mode de fonctionnement, de ses actions et de ses buts.
Rome ne s’est pas faite un jour, mais les changements sont visibles et je pense maintenant que personne ne pourrai / ne voudrai retourner en arrière.
Aller très loin ou aller trop loin ?
Dans la formation Management 3.0 certains aspects bouleversent complètement nos modes de fonctionnement. « Ne pas promettre de récompense », « Récompenser des comportements pas des résultats » sont des exemples de préconisations de cette formation. Ces règles visent à valoriser le collectif plutôt que l’individu / l’individualisme.
Quel changement quand on est habitué à avoir des objectifs fixés en début d’année et d’être jugé, et récompensé, sur la base de l’atteinte ou non de ces résultats.
Imaginer des commerciaux qui ne soient plus récompensés sur l’atteinte de leurs résultats mais sur leur comportement ! Impensable de nos jours dans la plupart des entreprises. Et pourtant, on sent bien la justesse des arguments de ces nouvelles techniques de récompense.
Certaines habitudes auront la vie plus dure que d’autres, et le trajet sera d’autant plus long.
Conclusion
C’est une révolte, sire ? Non, juste une belle évolution ! En faire moins (exit les V1 fastidieuses) mais mieux (les MVP).
Le principal est que cela soit le fait d’une volonté commune et que les dirigeants (un fort niveau de sponsoring est indispensable) comme les collaborateurs y adhèrent. Nous avons tous à y gagner et à grandir dans ces nouveaux modes de fonctionnement.
Nous avons les techniques, des formations sont à disposition et des vidéos pour nous guider.
A nous de jouer !
Chapitre(s) suivant(s) ?
Je ne vais plus annoncer de suite, car cela évolue / change tellement vite ! Mais ne vous inquiétez pas, vous ne serez pas déçus.