
22 février 2024
Louis Allavena
Consultant Transformation Data
Julien Leverrier
Consultant Transformation Data
Au cours des dernières décennies, l’évolution de la technologie a vu émerger une culture et une philosophie qui ont profondément influencé la manière dont nous développons, partageons et utilisons les logiciels et les données. Cette culture repose sur des principes fondamentaux de transparence, de collaboration et de partage. Pour faire suite à notre premier article, explicitant ce qu’était l’Open Data, nous aborderons ici l’histoire de la Culture Open Source et expliquerons en quoi l’open data en découle naturellement.
Qu’est-ce que la Culture Open Source ?
La culture open source est un mouvement qui promeut l’accès ouvert et le partage de logiciels et de ressources, permettant à quiconque de consulter, d’utiliser, de modifier et de distribuer ces ressources. Cela contraste avec le modèle de développement de logiciels propriétaires, où les entreprises gardent le code source secret et limitent les droits de modification et de distribution. Bien que le terme « open source » ait été popularisé au début des années 2000, les principes qui le sous-tendent remontent beaucoup plus loin dans l’histoire de l’informatique.
La Culture Open Source repose sur plusieurs principes clés :
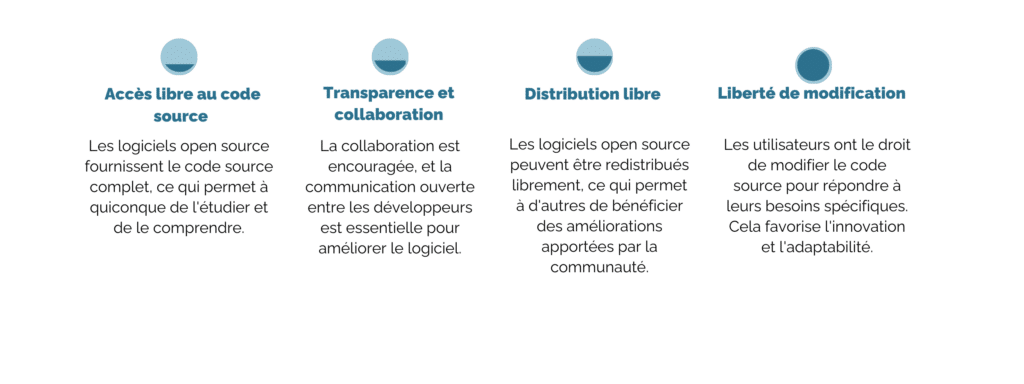
Longtemps considérée comme une culture ne renfermant que des geek et informaticiens, l’Open Source s’est démocratisée et se retrouve dans de nombreux outils que nous utilisons tous (VLC, Mozilla Firefox, la suite LibreOffice, 7Zip…). Le partage des logiciels Open Source est favorisé par des plateformes de centralisation dont la plus connue est GitHub. Malgré une réputation de visuel dépassé et d’une utilisation parfois laborieuse et incomplète, le logiciel Open Source est souvent considéré comme plus sûr car ses failles sont rapidement identifiées, les mises à jour disponibles et l’adaptabilité favorisé (on n’est pas obligé de mettre à jour constamment son logiciel si on ne le souhaite pas, gardant ainsi la possibilité ou non d’ajouter des fonctionnalités).

L’Histoire de la Culture Open Source
L’histoire de la culture open source remonte aux débuts de l’informatique moderne. En effet, dans les années 1950 et 1960, les chercheurs construisaient souvent les premiers ordinateurs en tant que projets collaboratifs, et ils partageaient librement des informations sur la conception et le fonctionnement de ces machines, considérant le partage d’informations comme essentiel pour faire progresser la technologie.
L’une des premières incarnations de la culture open source telle que nous la connaissons aujourd’hui est le mouvement du logiciel libre, lancé par Richard Stallman dans les années 1980. Stallman a fondé la Free Software Foundation (FSF) et a développé la licence GNU General Public License (GPL), qui garantit que les logiciels libres restent accessibles à tous, permettant la modification et la redistribution. Cette licence a joué un rôle crucial dans la création d’une communauté de développeurs engagés dans le partage de logiciels.
Dans les années 1990, le développement de Linux, un système d’exploitation open source, a été un événement majeur. Linus Torvalds, son créateur, a adopté la philosophie du logiciel libre et a permis à des milliers de développeurs du monde entier de contribuer au projet. Linux est devenu un exemple emblématique de la puissance de la collaboration open source et a prouvé que des logiciels de haute qualité pouvaient être produits sans les restrictions du modèle propriétaire.
Plus récemment, le sujet de l’open source apparait comme un marqueur majeur de différenciation entre les différents acteurs AI :
Si l’on regarde du côté de l’entrainement de différents moteurs, une majorité des acteurs de l’IA utilise des données publiques issues d’espace de stockage disponible tels que CommonCrawl, WebText, C4, BookCorpus, ou encore les plus structurés Red Pajama et OSCAR. C’est lorsque l’on observe l’usage et la publication des résultats que plusieurs stratégies s’opposent.
Le leader de l’IA générative Open AI a un positionnement “restrictif” dans la publication de ses avancées, au motif de protéger l’humanité de publications trop libre de sa création. Cela a par ailleurs contribué au feuilleton médiatique récent qui a secoué la direction de la structure. De l’autre côté du spectre, nous avons Mistral AI, que nous avons eu l’occasion de présenter auprès des journalistes de Libération et du site internet d’Europe 1. En effet, celle-ci propose l’ouverture totale de l’ensemble des données, modèles et moteurs, dans une orientation typiquement Européenne (Data Act).
Les données ouvertes dans l’histoire
Le développement de cette culture open source, par le développement des outils informatiques, marque le vingtième siècle. Mais l’humanité n’a pas attendu ces progrès technologiques pour se poser des questions sur la libre diffusion des connaissances.
Au premier siècle avant JC, Rome édifie une bibliothèque publique au sein de l’Atrium Libertatis, ouverte aux citoyens.
De plus, si le moyen-âge marque une restriction des accès aux livres pour la population, de nombreux ouvrages restent accessibles à la lecture, mais pas encore à l’emprunt ! Les livres sont attachés aux tables par des chaînes, et l’on trouve dans certaines bibliothèques des avertissements assez clairs : « Desciré soit de truyes et porceaulx / Et puys son corps trayné en leaue du Rin / le cueur fendu decoupé par morceaulx / Qui ces heures prendra par larcin » (voir plus)
Enfin, plus récemment, la révolution française provoque des évolutions significatives dans la diffusion des connaissances, et cette ouverture à tous des données: la loi fixe maintenant l’obligation de rédiger et de diffuser au public les comptes rendus des séances d’assemblées.
Qu’il s’agisse de processus de démocratisation, ou simplement d’outil de rayonnement culturel, on voit donc que la question du libre accès à l’information ne date pas de l’ère de l’informatique.

L’Open Data : Une Conséquence Logique
L’open data est une extension naturelle de la culture open source. Cependant, comme nous l’avons déjà présenté dans notre premier article, l’Open Data est un concept qui repose sur la mise à disposition libre et gratuite de données, afin de permettre leur consultation, leur réutilisation, leur partage. Elle repose sur des principes similaires à ceux de l’open source, à savoir la transparence, la collaboration et le partage.
L’open data présente de nombreux avantages. Il favorise la transparence gouvernementale en rendant les données gouvernementales accessibles au public. Cela renforce la responsabilité des gouvernements envers leurs citoyens. De plus, l’open data stimule l’innovation en permettant aux entreprises et aux développeurs de créer de nouvelles applications et solutions basées sur ces données.
Par exemple, de nombreuses villes publient des données ouvertes sur les transports en commun. Cela a permis le développement d’applications de suivi des horaires de bus en temps réel et d’autres outils qui améliorent la vie quotidienne des citoyens.
En conclusion, la culture de l’Open Source repose sur des principes de transparence, de collaboration et de partage. Tout cela a permis la création de logiciels de haute qualité et l’innovation continue. L’open data, en tant qu’extension de cette culture, renforce la transparence, l’innovation et la responsabilité gouvernementale en permettant un accès libre aux données publiques et privées. Ensemble, l’open source et l’open data façonnent un monde numérique plus ouvert, collaboratif. Par conséquent, cette culture est quasi omniprésente de nos jours, en 2022, selon un rapport Red Hat. 82 % sont plus susceptibles de sélectionner un fournisseur qui contribue à la communauté open source. De plus, 80 % prévoient d’augmenter leur utilisation de logiciels open source d’entreprise pour les technologies émergentes.
Merci d’avoir pris le temps de lire ce second article de notre trilogie consacrée à l’open data. Retrouvez-nous prochainement pour le dernier tome, consacré aux modes opératoires et aux bonnes pratiques de la publication de données en open data.