Il n’est pas toujours évident de s’y retrouver dans la jungle que constituent les différents comités en entreprise, et les comités d’architecture ne font pas exception. Vous êtes perdus et ne savez pas comment définir la comitologie qui répondra aux besoins de votre organisation ? Suivez le guide !
Dans cet article, nous aborderons deux grandes étapes :
la définition de la comitologie d’architecture, dans un premier temps,
suivie par un focus sur l’animation de cette comitologie.
Une comitologie utile et intéressante doit être construite pour répondre à vos objectifs
Identifier clairement les objectifs de la comitologie
Les objectifs des organisations étant très divers, il est naturel qu’une myriade de comités d’architecture différents existent :
des comités transverses ou spécifiques à un programme de transformation,
des comités de partage entre architectes,
ou des comités d’arbitrage.
L’un des écueils principaux consiste à faire surgir dans les agendas autant de comités que de champignons après les premières pluies d’automne. On voit souvent des participants occasionnels se mélanger les pinceaux avec les trois ou quatre réunions portant un nom approchant. Et s’ils ne savent pas les différencier, nul doute qu’ils ignorent leurs objectifs…
Mais dans ce cas, comment créer une comitologie d’architecture claire, lisible et utile ?
Afin de choisir la plus adaptée, il est tout d’abord capital de bien comprendre le contexte de votre entreprise et d’identifier vos objectifs. Cela peut passer par des interviews mais aussi être exploré dans le cadre d’un audit de maturité de l’architecture, qui comporte un volet sur la comitologie.
Définir ensemble la comitologie qui répond aux objectifs identifiés
Une fois les objectifs clarifiés, la construction collaborative de la comitologie peut ensuite débuter !
Rhapsodies Conseil vous aide à dessiner la comitologie qui vous conviendra le mieux en s’appuyant sur :
les éléments de contexte,
un catalogue d’exemples de comités d’architecture,
un arbre de décision.
Votre connaissance fine de l’organisation dans laquelle vous évoluez sera également précieuse et devra être prise en compte.
Vous obtiendrez à terme une description des différents comités d’architecture à mettre en place précisant :
leurs objectifs,
la fréquence à laquelle ils seront tenus,
leurs périmètres respectifs,
les différents participants.
Ces éléments seront bien sûr diffusés au sein de l’organisation pour bien expliquer le rôle du ou des comités d’architecture. Bien communiquer en amont de la mise en place des comités permettra de s’assurer que tous les participants, récurrents ou occasionnels, n’aient pas de doutes sur leurs objectifs.
Il ne reste plus qu’à les mettre en œuvre et les animer !
Pas si simple me direz-vous ? Comment s’assurer que cette comitologie soit animée de manière efficace et réponde ainsi aux objectifs de l’organisation ?
Tout en évitant à tout un chacun d’écouter distraitement d’une oreille en travaillant sur un autre sujet en parallèle ou en traînant sur son téléphone…
Eh bien, en s’appuyant sur le PMO de l’architecture !
Le PMO de l’architecture : cet acteur clé qui rend vos comités efficaces et productifs
Qui est le PMO de l’architecture ?
Ce terme de “PMO” a été dévoyé et il peut paraître n’être qu’un scribe qui n’apporte pas de vraie valeur ajoutée. Notre conviction chez Rhapsodies Conseil est la suivante : cet acteur doit avoir une culture de l’architecture d’entreprise. Il peut alors faire tellement plus pour l’équipe architecture que compléter un fichier excel une fois par mois !
Il dispose ainsi de nombreuses compétences :
bonne connaissance du SI
maîtrise de la gouvernance de l’architecture,
bon relationnel,
compréhension de l’organisation et du rôle de l’équipe d’architecture,
compréhension des enjeux projets,
connaissance des dossiers d’architecture et des modèles,
techniques d’animation de réunions.
C’est pourquoi il est le plus à même d’animer la comitologie d’architecture et de la rendre intéressante pour l’ensemble des participants, décideurs y compris.
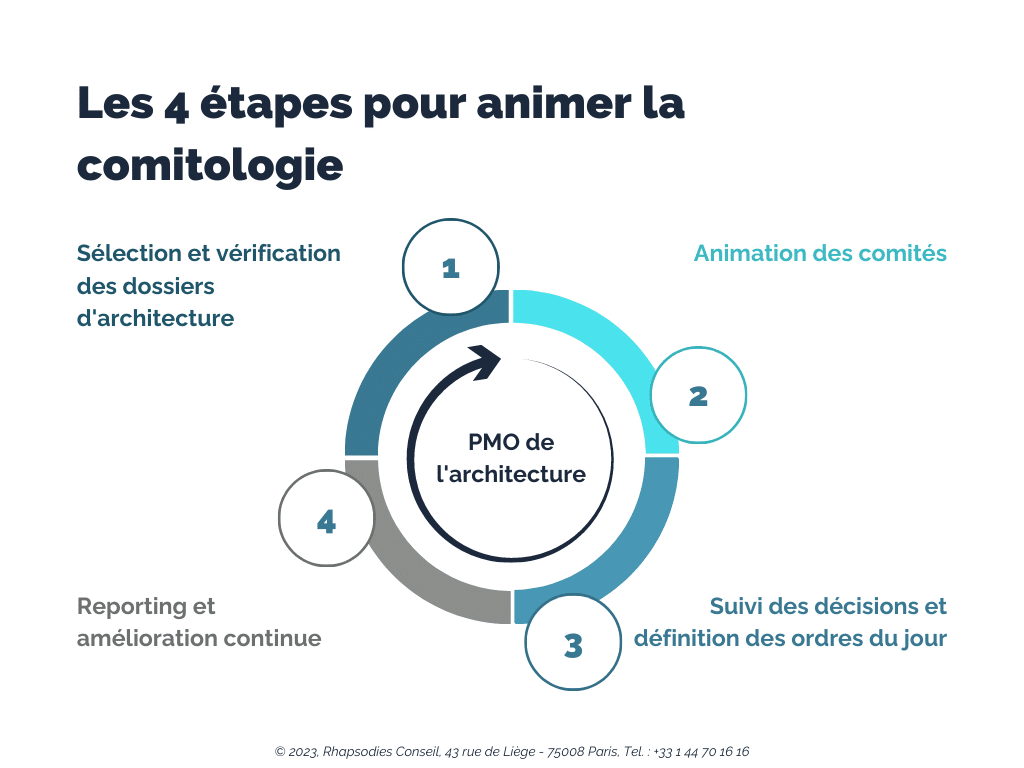
La première activité du PMO de l’architecture : sélectionner et vérifier les dossiers d’architecture
C’est lui qui propose un ordre du jour en fonction de la maturité et du niveau d’urgence des dossiers d’architecture. Il vérifie que ceux-ci sont bien complets avant leur passage en comité. Il comprend les enjeux et peut donc appuyer les différents architectes dans la préparation de leurs dossiers. Il dispose aussi de templates de dossiers d’architecture afin de guider les architectes nouvellement arrivés dans la rédaction de leurs premiers dossiers.
Une bonne préparation avec des attendus précis, dont le PMO de l’architecture est le garant, permet d’éviter bien des désillusions en comité… Et de devoir à de nombreuses reprises rapporter les mêmes éléments complémentaires devant des participants qui ont oublié une bonne partie du sujet…
Le PMO de l’architecture est aussi en charge de l’animation des comités le jour J
L’animation des comités en tant que tels fait également partie de son rôle : il partage l’ordre du jour, suit le bon déroulement du comité, recueille les avis en séance et prend les notes explicatives. Il établit le relevé de décision et partage le compte-rendu aux différents participants.
Il peut aider à remettre le comité sur le droit chemin quand les échanges s’enlisent.
Un suivi est mis en place par le PMO pour que les décisions ne restent pas lettre morte
Suite aux comités, il réalise le suivi des dossiers en fonction des décisions :
passage en mode projet,
programmation d’un deuxième passage du dossier,
études à refaire ou à compléter.
Il établit donc les ordres du jour des prochains comités.
Ce suivi fin des ordres du jour permet d’éviter ce que l’on voit parfois :
un ordre du jour déformé car il a été mal compris par la personne chargée du suivi,
la présentation d’un sujet devant des décideurs qui ont oublié l’avoir demandé.
Il peut identifier les décisions qui donnent lieu à de la dette et en faire le suivi.
De plus, connaissant les différents dossiers en cours, il maîtrise les dépendances entre les sujets. Il est donc à même de prévenir les architectes dont les sujets peuvent être impactés par les décisions du comité. Le PMO de l’architecture ayant une vision globale de l’avancement des sujets, il peut créer du lien entre les architectes. Cela permet aussi d’assurer que l’ensemble des décisions prises lors des comités restent cohérentes.
Le PMO de l’architecture participe également à l’amélioration continue de la gouvernance de l’architecture
Enfin, son rôle transverse lui permet de construire le reporting de la comitologie : il suit le nombre de dossiers qui passent en comité, les décisions et les avis émis… Il peut alors proposer des améliorations de la comitologie afin d’optimiser la gouvernance de l’architecture. Il pourra donc vous aider à ajuster la comitologie si nécessaire en fonction de ce qu’il observe en comité et des issues des présentations.
J’ai tenu ce rôle pendant 1 an et eu la chance de travailler avec des collègues qui avaient aussi tenu ce rôle. J’espère que cette synthèse vous sera utile et que vous connaissez désormais mieux le PMO de l’architecture, cet acteur qui garantit le succès de vos comités. N’hésitez pas à nous contacter pour échanger sur vos retours d’expérience.
Les autres articles qui vont vous intéresser
Auto-ML : outil ou menace pour le Data Scientist ?
Auto-ML : outil ou menace pour le data scientist ?
Après avoir été successivement décrit comme le job le plus sexy du 21ème siècle puis comme aisément remplaçable par la suite, le data scientist a de quoi souffrir aujourd’hui de sacrés questionnements. Son remplaçant le plus pertinent ? Les solutions d’Auto-Machine Learning, véritables scientifiques artificiels des données, capables de développer seuls des pipelines d’apprentissage automatique pour répondre à des problématiques métier données.
Mais une IA peut-elle prendre en charge la totalité du métier de data scientist ? Peut-elle saisir les nuances et spécificités fonctionnelles d’un métier, distinguer variables statistiquement intéressantes et fonctionnellement pertinentes ? Mais aussi, les considérations d’éthique des algorithmes peuvent-elles être laissées à la main … des mêmes algorithmes ?
Le Data Scientist, vraiment éphémère ?
Le data scientist est une figure centrale de la transformation numérique et data des entreprises. Il est l’un des maîtres d’œuvre de la data au sein de l’organisation. Ses tâches principales impliquent de comprendre, analyser, interpréter, modéliser et restituer les données, avec pour objectifs d’améliorer les performances et processus de l’entreprise ou encore d’aller expérimenter de nouveaux usages.
Toutes les études sur les métiers du numérique depuis 5 ans sont unanimes : le data scientist est l’un des métiers les plus en vogue du moment. Pourtant, il est plus récemment la cible de critiques.
Des observateurs notent une baisse de la « hype » autour de la fonction et une décroissance du ratio offre – demande, qui viendrait même pour certains à s’inverser. Trop de data scientists, pas assez de postes ni de missions.
Deux principales raisons à cela :
La multiplication de formations et bootcamps certifiants pour le poste, résultant en une inondation de profils juniors sur le marché ;
Une rationalisation des organisations autour de l’IA et une (parfois) limitation des cas d’usage – l’époque de l’armée de data scientists délivrant en série des POCs morts dans l’œuf est belle est bien révolue.
Mais également, et c’est cela qui va nous intéresser pour la suite, pour certains experts, le « data scientist » ne serait qu’un buzzword : l’apport de valeur de ce rôle et de ses missions serait surévalué, jusqu’à considérer le poste comme un effet de mode passager voué à disparaître des organisations.
En effet, les mêmes experts affirment qu’il sera facilement remplacé par des algorithmes dans les années à venir. D’ici là, les modèles en question deviendraient de plus en plus performants et seraient capable de réaliser la plupart des tâches incombées mieux que leurs homologues humains.
Mais ces systèmes si menaçants, qui sont-ils ?
L’Auto-ML, qu’est-ce que c’est ?
L’apprentissage automatique automatisé (Auto-ML) est le processus d’automatisation des différentes activités menées dans le cadre du développement d’un système d’intelligence artificielle, et notamment d’un modèle de Machine Learning.
Cette technologie permet d’automatiser la plupart des étapes du procédé de développement d’un modèle de Machine Learning :
Analyse exploratoire : préparation et nettoyage des données, détection de la typologie de problème à adresser ;
Ingénierie et sélection des variables : analyse purement statistique (et non fonctionnelle, c’est l’un des points faibles) des différentes variables, sélection des variables pertinentes, création de nouvelles variables (ces modèles peuvent-ils le faire… ?) ;
Sélection du ou des modèles à tester, entraînement, mise en place de méthodes ensemblistes de modèles, fine tuning des hyper-paramètres, analyse et reporting de la performance ;
Agencement de l’analyse : mise en place du pipeline sous contrainte (coût / durée d’entrainement, complexité du ou des modèles, …) ;
Industrialisation et cycle de vie : restitution à l’utilisateur des résultats sous la forme de graphes ou d’interface, branchement simplifié à un tableau de bord prêt à l’emploi, sauvegarde et versionning des différents modèles.
L’Auto-ML démocratise ainsi l’accès aux modèles d’IA et techniques d’apprentissage automatique. L’automatisation du processus de bout en bout offre l’opportunité de produire des solutions (ou à minima POC ou MVP) plus simplement et plus rapidement. Il est également possible d’obtenir en résultat des modèles pouvant surpasser les modèles conçus « à la main » en matière de performances pures.
En pratique, l’utilisateur fournit au système :
Un jeu de données pour lesquelles il souhaite mettre en place son usage d’intelligence artificielle – par exemple une base de données client et d’indicateurs calculés (chiffre d’affaires total, sur la dernière année, nombre de transactions, panier moyen, propension à abandonner son panier, …)
Une variable cible d’entraînement, qu’il souhaite prédire dans le cadre de l’usage en question – par exemple la probabilité de CHURN du client en question ;
Des contraintes vis-à-vis de la sélection du modèle : quelle typologie de modèle à utiliser / exclure, quelle(s) métrique(s) de performance considérer, quels seuils de performance accepter, quelle durée d’entraînement maximale tolérer, …
Le système va alors entraîner plusieurs modèles – ensemble de modèles et modéliser les résultats de cette tache sous la forme d’un « leaderboard », soit un podium des modèles les plus pertinents dans le cadre de l’usage donné et des contraintes listées par l’utilisateur.
Source : Microsoft Learn
Quelles sont les limites de l’Auto-ML ?
Pour autant, l’Auto-ML n’est pas de la magie et ne vient pas sans son lot de faiblesses.
Tout d’abord, les technologies d’Auto-ML rencontrent encore des difficultés à traiter des données brutes complexes et à optimiser le processus de construction de nouvelles variables. N’ayant qu’une perception statistique d’un jeu de données et (aujourd’hui) étant dénué d’intuition fonctionnelle, il est difficile de faire comprendre à ces modèles les finesses et particularités de tel ou tel métier. La sélection des variables significatives restant l’une des pierres angulaires du processus d’apprentissage du modèle, apparaît ainsi une limite à l’utilisation d’Auto-ML : l’intuition business humaine n’est ainsi pas (encore) remplaçable.
Également, du fait de leur complexité, les modèles développés par les technologies d’Auto-ML sont souvent opaques vis-à-vis de leur architecture et processus de décision (phénomène de boîte noire). Il peut être ainsi complexe de comprendre comment ils sont arrivés à un modèle particulier, malgré les efforts apportés à l’explicabilité par certaines solutions. Cela peut ainsi amoindrir la confiance dans les résultats affichés, limiter la reproductibilité et éloigner l’humain dans le processus de contrôle. Dans une dynamique actuelle de prise de conscience et de premiers travaux autour de l’IA éthique, durable et de confiance, l’utilisation de cette technologie pourrait être remise en question.
Enfin, cette technologie peut aussi être coûteuse à exécuter. Elle nécessite souvent beaucoup de ressources de calcul (entrainement d’une grande volumétrie de modèles en « one-shot », fine tuning multiple des hyperparamètres, choix fréquent de modèles complexes – deep learning, …) ce qui peut rendre son utilisation contraignante pour beaucoup d’organisations. Pour cette même raison, dans une optique de mise en place de bonnes pratiques de numérique durable et responsable, ces technologies seraient naturellement écartées au profit de méthodologies de modélisation et d’entrainement plus sobres (mais potentiellement moins performantes).
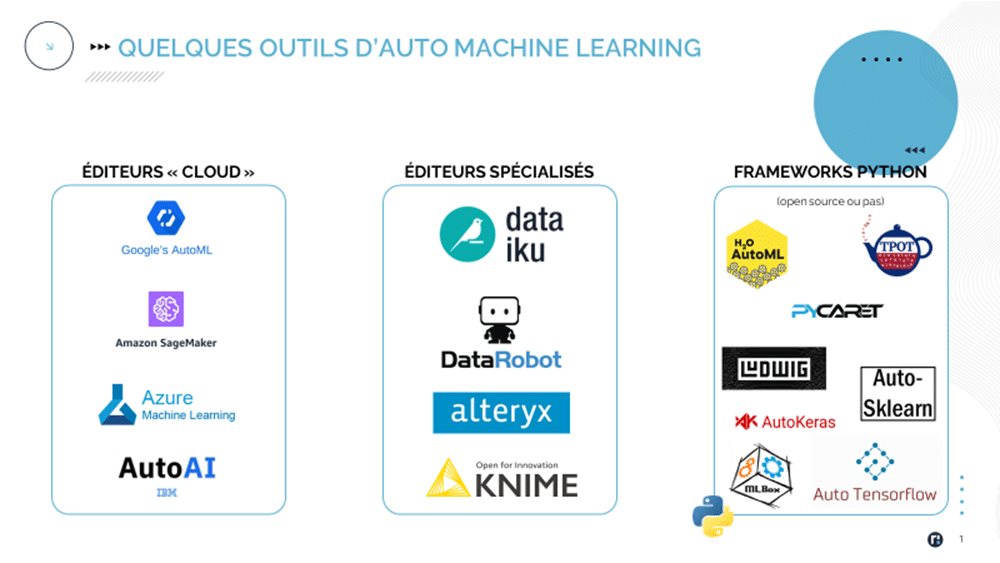
Quelles solutions d’Auto-ML sur le marché ?
On peut noter 3 typologies de solutions sur le marché :
Les solutions des éditeurs de cloud (GCP, AWS, …), pré-packagées dans les offres, permettant de profiter d’infrastructures d’entraînement performantes et de modèles pré-entraînés ;
Les éditeurs spécialisés dans les plateformes de data science, comme la licorne française Dataïku ou le pure-player ML DataRobot ;
Les librairies Python (et leur pendant R, parfois) open-source, certaines se branchant sur des frameworks bien connus de la profession (Auto Sklearn, AutoKeras, …)
H2o Auto-ML en pratique
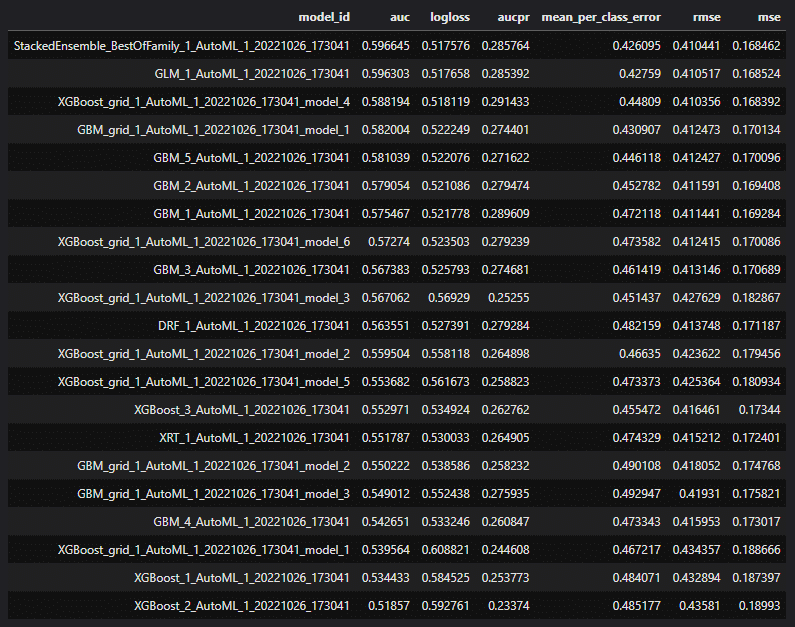
Jetons un coup d’œil à H2o.ai, librairie Python open source d’Auto-ML développée par l’entreprise éponyme. Nous prendrons comme cas d’usage un problème de classification binaire classique sur des données tabulaires, issu du challenge mensuel Kaggle d’Août dernier.
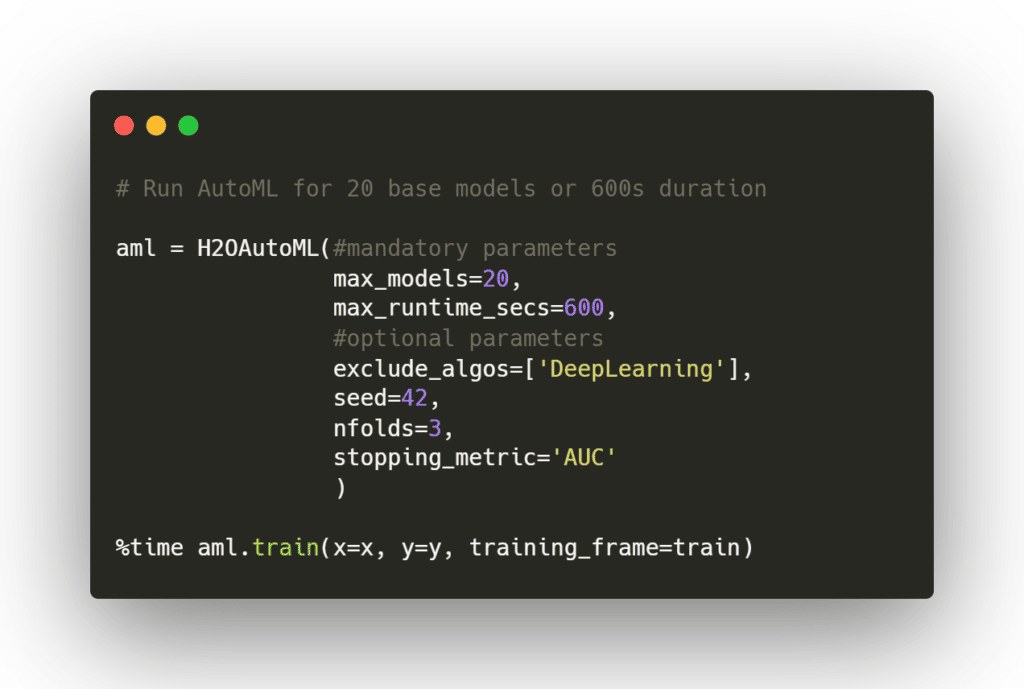
Après un chargement des données et une initialisation de l’instance locale, on va pouvoir lancer le moteur d’AutoML :
Doivent être spécifiés :
La volumétrie maximale de modèles à entraîner (permet d’ajuster les performances et de ne pas aller dans le « toujours plus ») ;
Une durée maximale de temps d’exécution, pratique en phase de prototypage du pipeline ;
Le H2o dataframe d’entraînement en indiquant les variables indépendantes (x) et la variable à prédire (y). A noter qu’il s’agit d’un format de dataframe spécifique mais que la conversion depuis et vers un dataframe pandas « traditionnel » se fait très simplement.
Il est également possible d’ajouter des paramètres tels que :
Les éventuelles typologies de modèles à exclure – ici on retire les modèles de deep learning mais peuvent également être exclus l’empilement (« stacking ») de modèles, les xgboost ou encore les algorithmes de « gradient boosting » ;
Une métrique d’arrêt (ex : logloss, AUC, …) qui permettra, une fois la valeur cible atteinte ou un nombre de rounds d’entrainement sans amélioration dépassé d’arrêter le processus de training ;
Tout un ensemble de paramètres pour gérer la validation croisée (nombre de folds, conservation des modèles non retenus et leurs prédictions, …) ;
Des fonctionnalités de ré-équilibrage des classes, afin d’adresser les problématiques de datasets déséquilibrés (par exemple, dans un problème de classification binaire, une répartition 90-10 sur la variable à prédire dans le jeu d’entraînement) ;
Il est important de noter que H2o AutoML ne propose aujourd’hui qu’une fonctionnalité limitée de préparation des données, se limitant à de l’encodage de variables catégorielles. Mais la société travaille aujourd’hui à enrichir ces fonctionnalités.
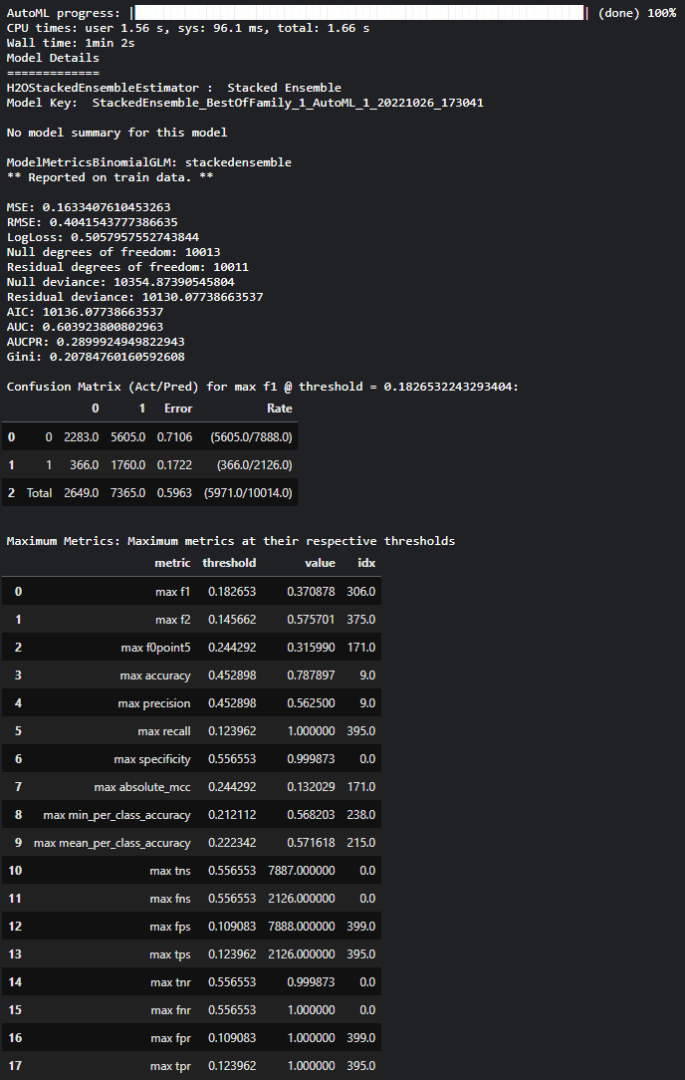
Une fois l’entraînement terminé, des informations sur le modèle vainqueur sont affichées :
Informations de base sur le modèle : nom, typologie, paramètres, … Dans notre cas, il s’agit d’un ensemble de plusieurs modèles et l’ensemble des paramètres n’est pas affiché (disponible via une commande supplémentaire)
Un listing des performances du modèle : matrice de confusion, métriques de classification (voir ci-dessous)
Il est également possible d’avoir accès au « leaderboard » des modèles entrainés et testés : identifiant, performances, temps d’entrainement et de prédiction, typologies des modèles (ensembles, gradient boosting, …) .
Informations modèle leader
Leaderboard
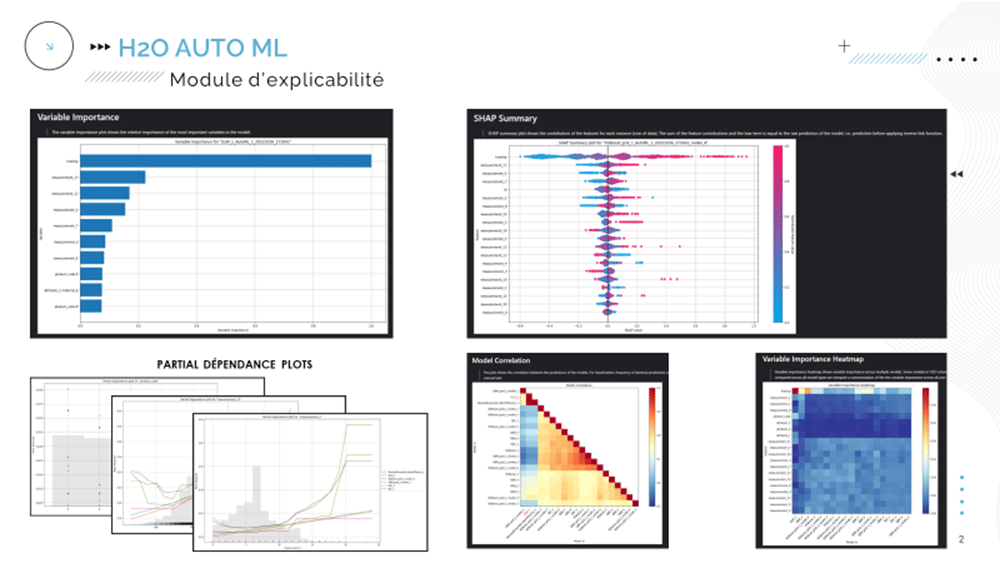
Enfin, le module d’explicabilité (restreinte…) nous permet d’obtenir des informations sur l’importance globale des variables dans les décisions du modèle, ainsi que l’importance globale des variables par modèle entraîné / testé, des graphes de dépendance partielle, une représentation des valeurs de SHAP des variables, … Il est également possible d’obtenir des explications locales sur des prédictions données.
En définitive, H2o AutoML permet d’expérimenter rapidement sur un cas d’usage donné, permettant par exemple de valider l’intérêt d’une approche par Machine Learning. Pour autant, dans notre cas précis, le modèle vainqueur constitue un assemblage complexe de plusieurs modèles non clairement spécifiés (il faut chercher…longtemps !) et cette complexité et ce manque de transparence peuvent en premier lieu rebuter les utilisateurs.
En définitive, l’Auto-ML signe-t-il vraiment la fin du Data Scientist ?
Le succès futur de cette technologie repose aujourd’hui sur les progrès à venir en matière d’apprentissage par renforcement, discipline qui peine aujourd’hui à percer et convaincre dans le monde professionnel. L’explicabilité et la transparence sont également des challenges à relever par cette technologie pour accélérer son adoption.
Mais de toute évidence, l’Auto-ML s’inscrira durablement dans le paysage IA des années à venir.
Quant au data scientist, il est certain que la profession telle que nous la connaissons va être amenée à évoluer. Nouvelle au début des années 2010, comme tous les métiers depuis et selon les organisations, leurs profils et activités vont évoluer.
D’un côté, des profils data scientists plus « business » et moins « tech » vont certainement se dégager se concentrant sur des échanges avec les métiers et la compréhension fine du fonctionnement et des enjeux des organisations. On peut d’ores et déjà voir que ces profils émergent des équipes business elles-mêmes : les fameux citizen data scientists. Ces derniers seront très certainement des fervents utilisateurs des outils d’AutoML.
Également, des profils hybrides data scientist – engineer se multiplient aujourd’hui, ajoutant aux activités classiques de data science la mise en place de pipelines d’alimentation en données et l’exposition des résultats et prédictions sous un format packagé (API, web app, …). L’ère du Machine Learning Engineer a déjà démarré !
Les autres articles qui vont vous intéresser
La matrice sociodynamique appliquée aux Avengers
La matrice sociodynamique appliquée aux Avengers
Dans un projet de transformation, nous étudions quelquefois l’environnement avant de pouvoir proposer une stratégie de conduite du changement.
Cet outil, issu de la Socio-dynamique, permet d’identifier le niveau d’adhésion des partenaires (collaborateurs impactés) d’un projet. Elle est très pertinente pour évaluer les impacts d’une transformation et d’envisager une démarche d’accompagnement au changement. Simple à appréhender, mais pas si simple à exploiter, nous l’avons appliqué aux Avengers pour illustrer de manière ludique son utilisation.
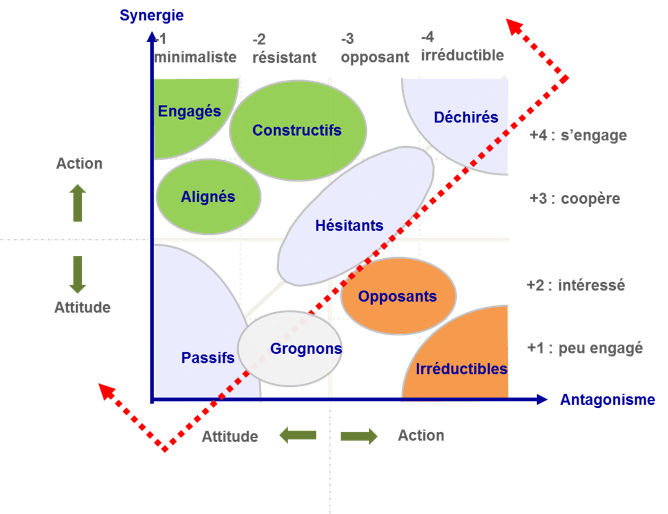
Dans un projet de transformation, nous étudions quelquefois l’environnement avant de pouvoir proposer une stratégie de conduite du changement. Nous disposons de plusieurs outils pour identifier les potentiels contributeurs du projet de changement et assurer la réussite de ce dernier. Dans l’un de ces outils, nous retrouvons la matrice socio dynamique des acteurs :
Mais qu’est ce que c’est ? Comment procéder avec cette matrice ?
Et si nous tentions d’appliquer cette matrice à un sujet culturel, pouvant intéresser les plus grands comme les plus petits, je veux bien sûr parler des super-héros ! Marvel nous procure depuis des années la quantité nécessaire d’informations pour pouvoir mettre en œuvre cette matrice ; je vous propose donc de faire une analyse socio dynamique d’acteurs Marvel lors du projet de Thanos.
Quel est le projet ? Qui le porte ?
Pour rappel, quel est donc ce projet en 1 phrase ? Thanos désire recueillir les six pierres d’infinité (ayant le plus de pouvoir dans l’univers) pour exaucer son vœu, qui plus est, supprimer la moitié de l’univers pour rétablir l’équilibre, en un claquement de doigts. Le projet des super-héros est donc d’arrêter Thanos.
[SPOILER ALERT] Les super-héros tentent par le combat d’arrêter Thanos mais il est déjà doté d’une puissance inimaginable. Dr Strange constate, grâce à la pierre d’infinité du temps, que les Avengers n’ont qu’une seule chance sur plusieurs millions de l’emporter. Cependant, Thanos parvient à réunir les pierres et élimine la moitié de l’univers. Les super héros, plus de 4 ans après le claquement de doigt de Thanos, parviennent à remonter dans le temps pour réunir les 6 pierres d’infinité. Durant le combat final, Dr Strange rappelle à Iron Man qu’ils n’ont qu’une seule chance de l’emporter, le conduisant à accepter son sacrifice en utilisant lui-même les pierres d’infinité pour détruire Thanos.
Passons maintenant en revue l’ensemble des acteurs concernés par notre matrice :
Maintenant que nous avons identifié notre population, nous allons passer à l’étape suivante : la récolte d’informations.
Comment procéder à l’analyse sociodynamique ?
Généralement, nous débutons par des entretiens avec des personnes ciblées en rapport avec le projet final (les populations impactées, les différents métiers, statuts, les localisations différentes). Dans ce contexte cinématographique, nous avons re-visionné la saga Marvel pour cerner chacun des personnages et identifier leurs comportements, vis-à-vis du projet d’arrêter Thanos pour sauver l’univers.
Nous identifions donc les profils et postures de chacun des personnages en rapport avec l’objectif du projet ; ses tâches, ses réactions, ses collaborations. L’objectif de la matrice sociodynamique n’étant pas de mettre les personnes dans des cases, mais bien de répartir les populations par ambition afin de construire nos actions de changement ensuite (formation, communication, co-construction, coaching éventuels). Ce livrable est donc à prendre avec des pincettes et à ne faire circuler qu’à une population très restreinte et engagée dans l’accompagnement du changement en cours, pour la simple et bonne raison que nous nous basons principalement sur du ressenti et que la matrice peut être interprétée de plusieurs manières.
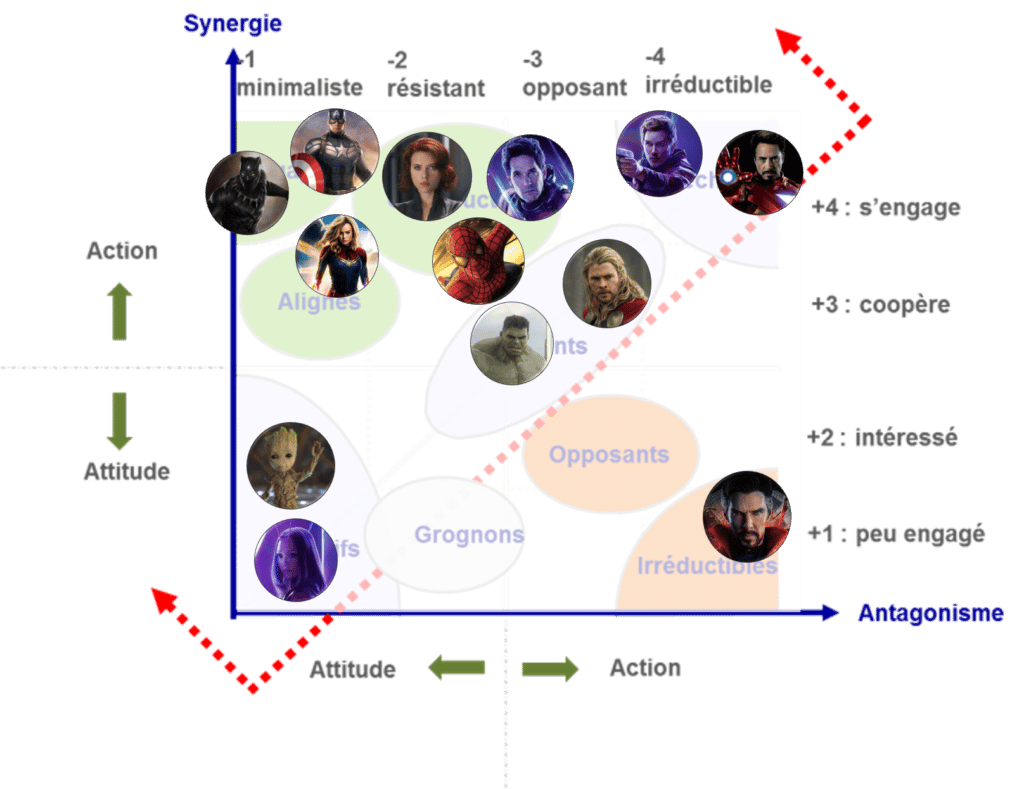
Voici le résultat de notre analyse dans le cas des Avengers :
Captain America (Steve Rogers) : Leader charismatique doté d’une force surhumaine, fin stratège militaire ayant le sens du sacrifice. Il se prend la tête avec Iron man car il a tendance à faire passer son équipe avant le collectif. Il n’oublie pas la mission mais il ne laissera personne derrière, même si ça compromet les objectifs principaux de la mission (cf. son ami Bucky, le soldat de l’hiver, cf. Wanda). C’est donc un “engagé”.
Iron Man (Tony Stark) : Génie électron-libre et égocentrique, ingérable, leader dans ses idées. Quand il a un projet en tête, il le met en œuvre peu importe l’avis des autres, et les risques du projet. Gros sens du sacrifice. Bourreau du travail. C’est un « déchiré ».
Black Widow (Natasha Romanoff) : Soldat redoutable, elle suit principalement les ordres, qui plus est, ceux de sa hiérarchie. Elle fait partie d’une « équipe », pour autant elle n’hésitera pas à avoir recours à son libre arbitre pour suivre une cause qu’elle estime juste. Elle est “constructive”.
Thor : Dieu du tonnerre doté d’un brushing incroyable, il a l’âme d’un leader mais ne veut pas l’être. Il a une grosse voix mais reste un “hésitant”. Il suit le groupe.
Hulk (Bruce Banner) : Génie se battant avec lui-même. Bruce Banner serait plutôt un suiveur, un intellectuel qui apporte des solutions à l’équipe alors que Hulk, quasiment immortel, reste un suiveur par rapport à un collectif afin de mettre ses capacités physiques au service des autres. Il est plus ingérable quand il est Hulk. C’est un “hésitant”.
Dr Strange : Focalisé sur la mission à long terme (protéger le monde et la pierre du temps qu’il détient) uniquement. Il n’hésite pas à faire passer au second plan tout autre priorité (la sécurité de son équipe) et à enfreindre des règles qu’il revendique par ailleurs s’il considère que cela peut mener à la réussite de son objectif à long terme. Il ne dévoile pas sa stratégie par peur de la faire échouer. Il se fiche de toute validation du groupe. C’est lui qui amène le projet à sa réussite de façon “dirty”. C’est un « irréductible ».
Captain Marvel : Pouvoir cosmique au service des autres. Elle est occupée par les autres problématiques galactiques et n’est pas très présente. C’est un “aligné”.
Starlord (Peter Quill) : Mi humain, mi celeste. Il est bien dans un groupe et se sent porteur à l’intérieur. Il cherche l’approbation des autres tout le temps et devient un élément “déchiré” quand il tombe amoureux de Gamora. Il va mettre à risque tout le plan pour tuer Thanos pour Gamora.
Groot :“Passif”, il collabore.
Mantis :“Passive”, elle collabore.
Ant-man (Scott Lang) : Il a de très bonnes idées mais ne sait pas comment les mettre en œuvre. Il est fan de Steve Rogers et suit les ordres du collectif. C’est un “constructif”.
Spider man (Peter Parker) : Pris sous l’aile d’Iron Man, ce jeune garçon est prêt à tout pour qu’on soit fier de lui. Il s’engage dans le collectif et a un sens du sacrifice. Il est un “constructif” car il n’écoute pas tout le temps les demandes qu’on lui fait.
Black Panther (t’challa) :“Engagé” pour sa nation et pour le projet !
Visualisation de l’analyse sur la matrice sociodynamique :
Le livrable : la matrice sociodynamique
La matrice n’est pas le genre de livrable à envoyer par mail sans voix off. Une présentation de toute la démarche et des réflexions menant à ces résultats sont nécessaires pour la compréhension du chef de projet ou du sponsor.
Toutes les théories de conduite du changement et de gestion de projet nous amènent très souvent, selon le contexte, à nous concentrer sur les “engagés” dans le projet et le ventre mou (nous y retrouvons les passifs, les hésitants notamment). Toutefois, d’autres pratiques d’accompagnement amèneraient à se concentrer sur les « irréductibles » et les “déchirés” pour la simple et bonne raison qu’ils tiennent un pouvoir. Ils ne sont pas d’accord et ils sont leaders là-dedans. Ils voient les changements sous un autre prisme et il est dommage de laisser de côté des éléments de réflexion pouvant mener à une réussite collective. Ils détiennent souvent la clé de la réussite du projet (au lieu de seulement réduire leurs postures à du sabotage).
Il est intéressant de constater que c’est ce qu’il se passe dans cette matrice Marvel : le projet de Thanos échoue grâce au sacrifice d’Iron man et d’une information si fortement retenue par Dr Strange. Etonnant non ? Ils étaient pourtant aux antipodes de la collaboration “classique”, pour autant, ils communiquent. L’ensemble des Avengers participent et ont une place très importante dans le projet, comme chacun des salariés d’une entreprise. La réussite finale du projet est la connivence de tous ces acteurs, humains, avec leurs propres problématiques et leurs propres manières de fonctionner. Avons-nous quelques pratiques et idées reçues à ruminer lors de nos prochaines missions ? Bien sûr, nous sommes sur l’exemple d’un contexte cinématographique, mais pensez-vous que cela s’éloigne vraiment de la réalité ?
L’objectif premier est d’attiser la réflexion de fond sur la gestion d’un changement ou d’un projet afin d’accompagner nos clients de la manière la plus pertinente possible. Tout l’environnement et chaque individu détient une force qu’il peut mettre à disposition du projet.
L’exercice tend à avoir une vue plus systémique et plus humaine, bien que la récolte d’informations reste très subjective.
Il en est de même en application aux Avengers, chaque fan des Marvel pourraient avoir une perception différente et ne pas être d’accord avec le positionnement des Avengers dans la matrice qui vient d’être effectuée. Etes-vous toutefois d’accord avec l’analyse finale ? Débattre et se concentrer sur l’environnement systémique d’un projet mène à des actions plus ciblées. Le deuil, les erreurs, les changements de dernière minute, les imprévus font partie d’un projet, c’est ce que nous pouvons remarquer également sur plusieurs films Marvel en rapport avec le projet d’arrêter Thanos. Facile à dire, difficile à mettre en place, la matrice sociodynamique est une aide à la prise de recul et c’est pour cela que nous accompagnons nos clients si bien, nous veillons à tous les éléments d’un projet, son histoire comprise.
En tout cas, j’espère que ça vous a plu, clap !
Les autres articles qui vont vous intéresser
Parlons de votre projet !
Connaissez-vous vraiment vos clients ?
Connaissez-vous vraiment vos clients ?
Disposer d’une bonne connaissance client est la pierre angulaire d’une expérience client réussie. Il s’agit du premier facteur clé de succès de l’omnicanalité que nous avions évoqué dans un précédent article.
Disposer d’une bonne connaissance client est la pierre angulaire d’une expérience client réussie. Il s’agit du premier facteur clé de succès de l’omnicanalitéque nous avions évoqué dans un précédent article.
L’omnicanalité place le client et ses points de contacts au centre de la stratégie d’expérience client. C’est à partir de la connaissance du client que se définit l’ambition de marque d’une entreprise orientée client. Les points de contact offerts sont alors conçus pour répondre à cette promesse de marque. L’orientation produit n’est aujourd’hui plus d’actualité ; l’orientation client remet le client au centre des premières préoccupations de l’entreprise. En outre, l’orientation client suppose naturellement de bien connaître son client.
Nous comprenons ainsi l’enjeu de disposer d’une connaissance client pertinente et complète.
Mais que signifie bien connaître son client ? Comment se construit cette connaissance client ?
La connaissance client est un vaste domaine que nous vous proposons d’explorer dans cet article.
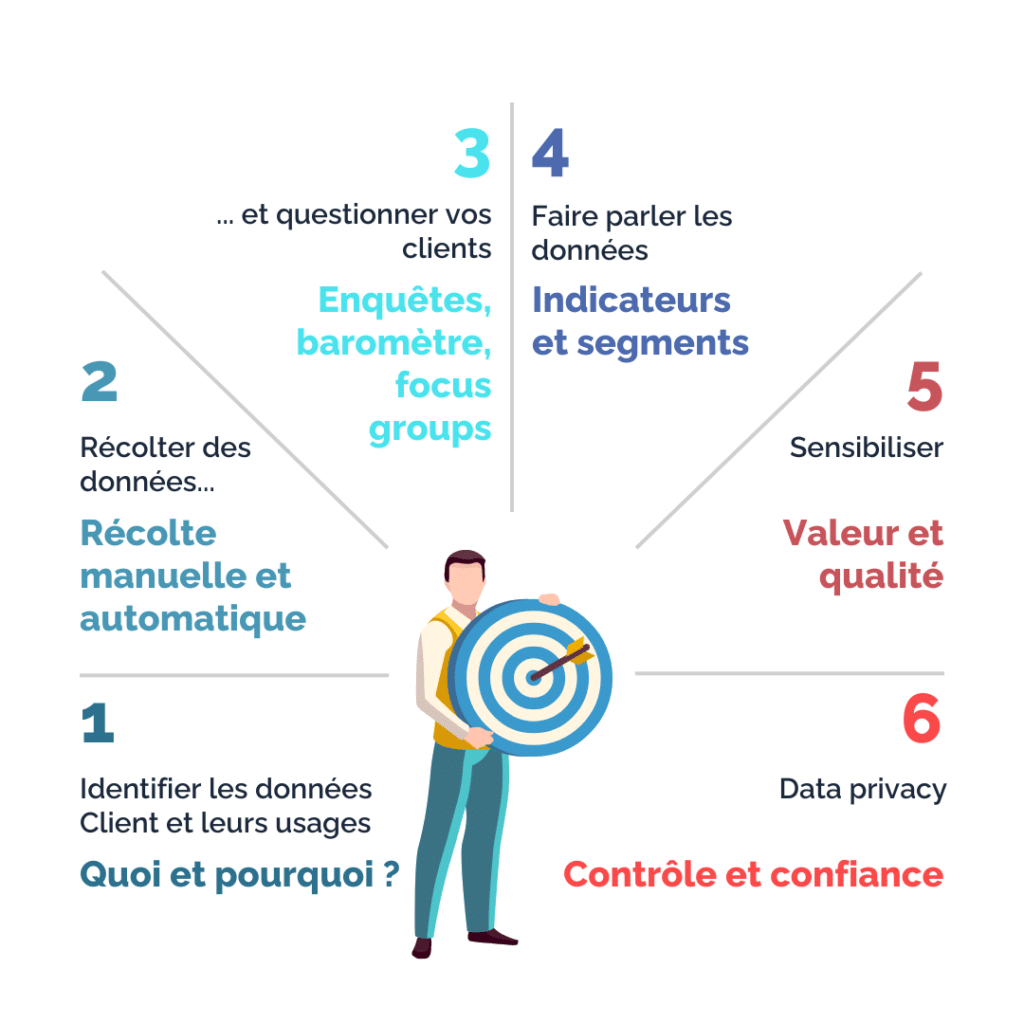
1. Identifier les données utiles et mettre en place des mesures de collecte ciblées
Les données client identifiées comme utiles peuvent couvrir un large éventail : données démographiques, de qualification, de consommation, de navigation, de sollicitation, de retours aux sollicitations, etc. Selon le secteur d’activité et la dimension du parc clients, ces données peuvent occuper un volume plus ou moins important. Dans l’ère du numérique durable et dans un souci d’efficacité opérationnelle, il devient aujourd’hui essentiel de bien sélectionner les données utiles qui permettent de répondre aux problématiques métier définies du marketing et du commerce. L’objectif est effectivement de cibler la « good Data », à la différence de la « full Data ».
Des mesures de collecte doivent ensuite être mises en place pour récupérer cette « good Data ». Ces données sont récupérées de deux manières : manuellement ou automatiquement. Les mesures de collecte manuelles adressent les collaborateurs amenés à interagir avec les clients. L’interaction avec le client est une opportunité à ne pas rater pour recueillir de l’information pertinente sur votre client : ses données de contact, ses centres d’intérêts, ses préférences de canal, etc. Les mesures de collecte automatique concernent les systèmes du front ou d’applications tierces, qui récupèrent automatiquement des données. Ces données sont par exemple issues du tunnel d’achat web ou d’une connexion d’un client sur son espace. Il peut s’agir de cookies (récoltés bien entendu avec consentement, à noter que l’utilisation des cookies tiers ne sera bientôt plus autorisée). Dans ce cas, les parcours doivent être réfléchis en amont pour identifier quelles données sont à récupérer et permettre par la suite cette récupération.
2. Demander directement à vos clients ce qu’ils souhaitent !
Si vous souhaitez connaître ce que pensent vos clients, leurs impressions, ou leurs attentes (en termes de produit, mais aussi d’expérience), il suffit parfois de leur demander ! Pour cela, plusieurs techniques existent.Au niveau du client, il est par exemple possible d’insérer sur son parcours web des questions bien choisies qui permettent ainsi de lui proposer les pages, les offres ou produits répondant à son besoin. Les réponses à ces questions sont par ailleurs enregistrées et pourront servir pour la prochaine visite. Attention bien entendu à ne pas alourdir le parcours. C’est une technique à utiliser avec parcimonie. Il est également recommandé d’envoyer un questionnaire de satisfaction après chaque interaction afin de récupérer le retour du client sur son expérience. Ce type d’enquête peut être qualifié de transactionnelle, car elle fait suite à une transaction entre le client et l’entreprise.
Au niveau de votre base de clients, une bonne pratique consiste à régulièrement la sonder, avec des enquêtes ou des baromètres. Ces enquêtes permettent d’avoir un avis général sur la marque et non sur un cas d’usage précis. Elles ne sont en outre pas nominatives. Il s’agit là d’enquêtes relationnelles. Les résultats sont globaux, ils donnent une température générale d’appréciation de votre marque. Les indicateurs les plus classiques issus de ce type d’enquête sont les taux de satisfaction et le NPS (Net Promoter Score). Ce type de données, marqueurs de la perception de vos clients, sont appelées des « Insights ».
Pour affiner vos produits ou parcours ou trouver des solutions à vos points de douleur, il reste enfin la possibilité de convier un échantillon représentatif de votre base clients pour un ou plusieurs ateliers de travail. Il s’agit là de Focus Groups. Les travaux en direct avec des clients sont très bénéfiques, car ils permettent de mettre en évidence des impressions ou intuitions faussées, parfois nourries au sein de l’entreprise en raison d’un manque de prise de recul.
3. Faire parler vos données client : calculs et rapprochements
Les nouvelles technologies ont évolué extrêmement vite ces dernières années, pour permettre aux entreprises de stocker et d’analyser des données dont le volume croît de manière exponentielle. C’est ainsi qu’est apparue la notion de « Big Data ». Les nouveaux usages, dont la digitalisation de parcours, sont entre autres à l’origine de ce volume grandissant. Ces données sont souvent éparpillées dans plusieurs systèmes (DMP, CRM, ERP, ITSM,…), ce qui nécessite un travail de centralisation et de traitement pour les rendre exploitables. Bien entendu, les modalités de stockage et de purge de ces données doivent être réfléchies pour répondre aux enjeux du numérique durable et aux contraintes RGDP qui sont abordées plus bas dans cet article. Ces données (bien choisies en amont) constituent tout de même une vraie mine d’or pour qui sait les faire parler.
Faire parler les données, c’est construire de nouvelles données à partir de données dites « brutes ». Il peut s’agir d’indicateurs (ex : panier moyen), de segments (ex : RFM – Récence, Fréquence, Montant), ou de simples calculs (ex : nombre de mois depuis le dernier achat). Le calcul de ce type de données fait suite à la réflexion des équipes du marketing client. Ce type de données vient ainsi soutenir leur stratégie client. L’analyse poussée de ces données de masse, opérée par des spécialistes tels que des Data Scientists, permet aussi d’identifier des rapprochements qui peuvent parfois être surprenants. Le cas d’école le plus connu est la mise en évidence du lien entre l’achat de couches pour bébé et de bières par les jeunes papas dans une grande surface américaine. L’analyse poussée de gros volumes de données permet donc de décrypter finement les comportements client, et déceler des clés de compréhension pour favoriser le cross-selling, l’up-selling ou simplement améliorer l’expérience client, et ainsi fidéliser.
4. Bien visualiser et communiquer vos données pour mieux décider
La mise en visualisation des données est une étape cruciale à ne pas négliger. Une fois les données client récoltées et travaillées pour mieux comprendre le comportement de vos clients et leurs attentes, il est nécessaire de pouvoir visualiser ces données régulièrement pour identifier les évolutions et ajuster votre stratégie de relation client. Pour cela, deux éléments clés sont à déterminer en amont : les indicateurs à afficher et les modalités de mise à disposition. Le suivi de ces indicateurs sera facilité par la simplicité d’accès et de lecture de ceux-ci.
Le suivi des données client est primordial pour l’aide à la décision sur les sujets orientés client. D’une part, il permet d’identifier l’impact des actions marketing sur la base clients et d’en évaluer les performances. D’autre part, il permet d’identifier les ajustements à réaliser dans le calcul des indicateurs, comme une évolution devenue nécessaire de la segmentation comportementale. Enfin, il est important de diffuser régulièrement certains indicateurs orientés client au sein de l’entreprise, afin de sensibiliser les collaborateurs sur la valeur de la donnée et son rôle dans l’amélioration de l’expérience client.
5. Sensibiliser l’ensemble des collaborateurs sur la valeur des données client
L’acculturation à la valeur des données client est nécessaire pour sécuriser, d’une part la récolte des données, et d’autre part le bon usage de ces données.
Les collaborateurs en interaction avec les clients doivent comprendre les enjeux de la récolte des données et de leur qualité. Comprendre ces enjeux favorise leur engagement et leur implication dans cette récolte dont ils sont les premiers acteurs. Ceci est d’autant plus vrai s’ils bénéficient eux-mêmes dans leur quotidien de l’utilisation de ces données pour optimiser leur interaction avec le client. Ainsi la compréhension des enjeux fait partie intégrante de ce processus d’acculturation à la valeur des données. Ce processus doit bien entendu comporter un volet sur la qualité des données, pour des raisons évidentes d’utilisabilité.
La sensibilisation au bon usage de la donnée est également un facteur clé essentiel d’une entreprise orientée client. Comme évoqué plus haut, l’orientation client place le client au centre de sa stratégie. Cela suppose de bien le connaître pour planifier les bonnes actions : il s’agit alors d’être « data-driven ». La direction joue bien entendu un rôle prépondérant dans cette acculturation. Elle doit insuffler au sein de son organisation cet état d’esprit au travers de principes établis qui permettent de poser le cadre, mais également au travers d’une organisation décloisonnée et de formations spécifiques.
6. Prendre en compte les contraintes réglementaires et en faire une force !
Cet article évoque toutes les mesures nécessaires pour disposer d’une connaissance client complète et pertinente sur la base de données client. Mais qu’en est-il des contraintes réglementaires sur l’utilisation de ces données ?
Le RGPD (Règlement Général sur la Protection des Données), appliqué depuis 2018 en Union Européenne, pose un cadre sur la récolte et l’utilisation des données client. Ce règlement a vocation à permettre au citoyen européen de contrôler l’utilisation de ses données personnelles. Le RGPD entre ainsi en jeu dès la récolte des données client, puisque celle-ci est soumise au consentement du client. Le RGPD encadre par la suite l’utilisation de ces données et les finalités associées, ainsi que les modalités de conservation, de sécurité et les droits des personnes sur leurs données (ex : accès, rectification, suppression, portabilité). Ce règlement a donné naissance à une activité encore relativement récente au sein de l’entreprise : la Data Privacy.
Souvent perçus comme une contrainte par les acteurs du marketing client, les enjeux de la Data Privacy visent cependant la transparence sur les actions menées par les entreprises sur la base des données client. Le client est donc rassuré et la Data Privacy est ainsi transformé en véritable vecteur de confiance ! Pour cela, il est essentiel de maîtriser l’ensemble des modalités relatives à la Data Privacy, pour limiter les contraintes et interagir pertinemment avec les clients dont le consentement a été obtenu.
Vous avez maintenant toutes les clés pour bien connaître vos clients ! Vous l’aurez compris, bien connaître vos clients implique aussi d’une part de bien maîtriser votre portefeuille de données, et d’autre part de mettre en place une architecture qui optimise son usage. Pour en savoir plus sur le sujet, nous vous invitons à consulter nos expertises Transformation Data et Architectures.
Savez-vous que lancer les développements d’une solution sans modélisation de données, c’est comme construire une maison sans en avoir fait les plans ?
Si vous voulez avoir des solutions performantes et pérennes pour vos projets de transformation de vos SI, utilisez la modélisation de données, et en particulier la modélisation de données conceptuelle, comme un levier de performance.
Stocker des données n’est pas modéliser des données
Très souvent après avoir validé vos projets de transformation des SI pour atteindre les enjeux métier d’entreprise, l’objectif est de rapidement importer les premières données pour pouvoir les rendre ‘visibles’ et avoir des premiers résultats ‘concrets’.
Des développements sont donc lancés, sans l’étude préalable des données et des concepts nécessaires pour faire le lien avec le métier de l’entreprise. Ces développements conduisent à définir des tables et des jointures avec pour objectif de stocker des données. C’est la modélisation de données dite physique. L’objectif n’est pas le bon à ce stade. C’est une vision de solution court-termiste.
Une notion importante à appréhender est que le stockage des données et la structure de la base de données impactent directement la restitution, et donc l’usage des données. Cette structure est développée au travers du modèle de données physique.
Si vous mélangez les notions de modèle de données physique et de modèle de données conceptuel, et si vous ne comprenez pas bien les concepts fonctionnels manipulés, alors le modèle de données physiques ne répondra pas à tous les besoins adressés.
Toutes ces questions sont adressées au travers de la modélisation de données et en particulier la modélisation de données conceptuelle.
Dès lors, quels sont les objectifs de la modélisation de données ?
Nous avons vu que lorsque nous pensons modélisation de données, nous pensons tables, jointures, clefs étrangères. En réalité, cela revient à penser, tuyaux en PVC ou en cuivre, briques ou parpaings, avant même de savoir si nous souhaitons une maison de plain-pied ou à étages. La modélisation de données conceptuelle est donc une obligation.
Le modèle de données conceptuel conceptuel permet de définir des concepts (étonnant, non ?) transverses à l’entreprise, clairement définis entre les parties prenantes. Ces concepts sont liés pour répondre à un ensemble d’usages, qui lorsqu’ils sont regroupés dans des fonctions (définies au travers de l’architecture fonctionnelle), constitueront la solution informatique répondant aux besoins.
Le modèle de données conceptuel doit d’abord répondre à des usages propres au métier de l’entreprise. Prenons un modèle de données client par exemple. Il sera différent pour un assureur ou pour un industriel. Il sera également différent entre deux assureurs du fait de leur positionnement sur le marché. Le modèle conceptuel est donc basé sur l’utilisation des données qu’il contient : les usages valident le modèle.
La modélisation de données : une démarche à valeur ajoutée pour la DSI et surtout pour le métier
Le modèle de données conceptuel décrit les données stockées dans la solution de manière compréhensible par les métiers. D’autre part, il impose une démarche rigoureuse de conception concourant à la réussite du projet.
La modélisation de données doit ainsi commencer par lister les usages et les données sous-jacentes ou associées. S’entourer à la fois d’experts des données et d’experts métier est donc la clé. En effet, nous avons mis en évidence plus haut que le modèle de données conceptuel doit répondre aux deux enjeux à la fois :
Les experts des données sont responsables de découvrir et connaître les données, leur qualité réelle et leur utilisation réelle.
Les experts métiers sont responsables eux de décrire les usages actuels et cibles de ces données. Les usages étant les processus métiers de l’entreprise dans lesquels vont être utilisées ces données, mais aussi les contraintes liées à la mise à disposition de ces données (réglementaires, sécurité, etc.).
Construire et valider le modèle de données conceptuel est donc une démarche itérative afin d’échanger très régulièrement entre le métier, les experts de la donnée et la DSI.
Un modèle de données conceptuel performant est avant tout un modèle métier qui traduit des besoins métiers : on ne peut modéliser sans avoir une expression de besoin décrivant les usages.
La modélisation conceptuelle s’inscrit également dans une démarche de gouvernance des données. En effet, les premières questions posées naturellement quand le modèle de données se construit sont par exemple : quelle est la définition de ce concept ? dans quel cycle de vie s’inscrit-il ? etc. Les métiers définissent les concepts, les périmètres et les responsabilités avec le modèle de données conceptuel.
Avec cette démarche, en tant que DSI, vous minimisez les risques de choix court-termistes et de complexité de la solution développée. Vous bénéficierez ainsi d’une solution évolutive, maintenable, documentée et qui minimise également le shadow IT.
En tant que métier, cela vous permet d’être au plus proche des développements et vous comprenez grâce au modèle de données conceptuel, les données manipulées dans la solution. Vous minimisez ainsi les risques d’inadéquation avec les attentes métier.
En tant que responsable projet, product owner, ou responsable SI, imposez donc d’avoir une démarche de modélisation de données qui commence par un modèle conceptuel dans tous vos projets SI. Il est un facteur clef de réussite !
La modélisation de données : une compétence clé
La gestion du cycle de vie du modèle de données conceptuel et des impacts sur le stockage des données (base de données), doivent être suivis et validés par une personne experte en modélisation de données. Le cycle de vie du modèle de données est un processus lent dont les évolutions ne se voient pas forcément.
Une modélisation de données performante doit garantir une cohérence, une intégrité et une interopérabilité des données et des solutions. Une mauvaise modélisation de données crée ainsi lentement des blocages SI pour de futurs usages. Une illustration simple de cette mauvaise modélisation de données, est de laisser en attributs des données qui ont des cycles de vie différents de l’objet auquel ils sont rattachés. Multipliés par le nombre de données à l’échelle de l’entreprise et ajoutés à la complexité d’un modèle, ces problèmes de modélisation de données rendent le SI rigide.
La modélisation de données est donc une compétence spécifique. C’est une expertise qui s’acquiert au fur et à mesure des projets. Elle est nécessaire aux équipes de conception telles que les Business Analysts et les Architectes de données.
La modélisation de données, un facteur clef de succès de la transformation des SI
La modélisation des données est donc indispensable à un projet de développement de solution informatique. Comme évoqué précédemment, avec le modèle de données conceptuel, elle manipule des concepts métier de l’entreprise. Elle doit donc se projeter et anticiper les nouveaux concepts nécessaires aux nouvelles demandes client. Elle garantit ainsi l’agilité et l’évolutivité de votre solution face à la diversité des usages à adresser pour répondre aux demandes client en perpétuelle évolution.
Une question reste alors : la modélisation de données dépendant de la qualité des données des concepts métier, est-ce que les processus métier actuels de l’entreprise peuvent être modifiés pour fournir la qualité des données nécessaires aux nouvelles demandes client ?
Les projets d’API Management sont fondamentalement simples. Il s’agit de faire échanger des données d’un système A vers un système B. Mais c’est sans compter sur le fait qu’un projet d’API Management fait intervenir un grand nombre d’acteurs, ce qui engendre de la complexité.
Les acteurs de la gestion des API
Pour commencer, nous pouvons énumérer les acteurs typiques impliqués :
Le CxO qui a décidé que les API faisaient partie de la stratégie de l’entreprise, mais qui ne vous donne pas un parrainage très fort ;
Les autres CxOs qui ont d’autres priorités que les APIs ;
L’équipe A qui veut accéder à des données, mais qui n’a pas le temps de s’occuper de vous ;
L’équipe B qui est responsable de données exposées, mais qui n’a pas de temps à vous consacrer ;
Les développeurs de la solution qui veulent accéder aux données ;
Les développeurs de la solution qui exposent les données ;
Les membres de l’équipe de gestion de l’API ;
Et au moins un architecte, bien évidemment !
On voit bien qu’il y a une multiplicité d’acteurs, qui vont tous pousser dans leur propre direction. Et on perd rapidement toute forme de coordination si :
L’équipe de gestion de l’API ne joue pas un rôle de coordination constructif ;
Il n’y a pas de parrainage des membres du CxO.
Le défi de la complexité
Il est donc nécessaire de maîtriser la complexité de l’entreprise et la complexité due à ses interactions et à ses acteurs. En effet, selon la théorie des systèmes complexes, la complexité du système « entreprise » réside dans le nombre élevé d’acteurs et le nombre élevé d’interactions entre eux !
Ce qui est complexe, ce n’est pas de faire une API avec un acteur, mais de faire une API avec, par et pour de multiples acteurs.
Il est donc fondamental de :
Chercher à aligner tous les acteurs dans la même direction par une très bonne communication, des explications sur les bonnes pratiques, etc. ;
Faire de l’équipe de gestion des API un point d’échange central pour toute conversation sur les API ;
Infuser les connaissances dans toutes les équipes autant que possible.
A partir de là, on peut déduire deux prérequis :
Une gouvernance claire, simple et efficace est essentielle ;
Un sponsorship solide doit garantir l’alignement de l’entreprise sur un projet d’API.
Le mode d’organisation le plus souvent utilisé est le mode de gouvernance que j’appelle open source. L’équipe API encadre, guide, aide, soutient, mais surtout permet à chacun de contribuer facilement et efficacement.
De ces activités et défis ainsi énumérés, nous pouvons ainsi déduire deux types d’activités.
Deux typologies d’activités de l’équipe API
On peut ainsi diviser les activités d’une équipe API en deux types d’activités : les activités régaliennes et les activités étendues. En effet, la gouvernance d’une équipe de gestion d’API doit fixer un cadre dans lequel tous les acteurs impliqués dans les API doivent s’inscrire, afin que tous les acteurs puissent pleinement travailler.
Les activités régaliennes
Nous pouvons appeler activités régaliennes les activités pour lesquelles l’équipe de gestion des API a toute l’autorité et ne peut être supprimée. Dans ces activités, nous pouvons mettre :
La mise en œuvre et l’administration technique de la plateforme API Management.
La définition des meilleures pratiques de gestion d’API.
Les formats des ateliers de définition des API – pour passer de réunions interminables et contre-productives à des réunions efficaces et productives. J’ai personnellement réduit par 4 le nombre d’ateliers, juste en repensant la façon dont nous les animons !
L’organisation des ateliers API – Pour être le moteur des sujets API, mais libre à l’équipe API Management de laisser les équipes concernées s’organiser elles-mêmes si elles sont suffisamment autonomes.
La gestion de la formation et de la communication – Pour assurer l’adhésion des équipes, et pour démontrer la valeur ajoutée des équipes d’API Management.
Les activités étendues
Certaines activités doivent cependant être menées non pas sur un mode purement régalien mais sur un modèle beaucoup plus collaboratif, car après tout, il s’agit d’organiser les échanges entre au moins deux systèmes :
Définir et gérer le cycle de vie des API avec les projets et les architectes fonctionnels – Même si l’équipe API a le dernier mot, elle reste au service des projets et du métier ! Ne l’oubliez jamais !
Travailler avec les architectes sur l’alignement des besoins en API dans une feuille de route claire – Les architectes sont censés avoir une vision à moyen et long terme des besoins futurs, les équipes API sont censées s’aligner sur eux !
Outiller pour les développeurs afin d’apporter les bons outils et cadres de travail – Dire à un projet « allez-y et faites l’API » n’est pas suffisant ! Dites-le à un projet Legacy ! C’est aux équipes API de travailler avec les projets pour moderniser la base technique, la distribuer et la partager avec d’autres équipes de développement.
Contribuer à l’idéation avec les métiers pour trouver de nouvelles idées d’API – Le but étant de tirer le maximum de valeur des actifs de l’entreprise.
2 typologies de gouvernance, ou plutôt 2 “curseurs” de gouvernance
Enumérer une liste de tâches n’est pas pour autant équivalent à définir une gouvernance API.
De ces deux typologies d’activités, on remarque que le pattern “décentralisée” revient forcément.
En effet, le mode de gouvernance qu’on pourrait appeler “décentralisée” revient très souvent. Dans ce mode de gouvernance, l’équipe d’API Management a comme but principal de permettre à tout à chacun de contribuer facilement et efficacement. Ainsi, charge à l’équipe API Management de cadrer, orienter, aider, d’apporter du support, mais pas nécessairement d’implémenter et définir les APIs. C’est une logique de gouvernance qui cherche avant tout à permettre aux autres équipes de travailler de manière autonome.
Dans une logique totalement inverse, l’autre mode de gouvernance que l’on rencontre régulièrement est une gouvernance centralisée. Le centre de compétence d’API regroupe alors toutes les compétences nécessaires, et travaille de manière auto-suffisante.
Pour autant, rares sont les entreprises qui mettent en place une gouvernance aussi “marquée” par une de ces deux logiques. Toute la question est de pouvoir s’adapter à l’organisation de l’entreprise et de son SI, mais aussi de s’adapter à la maturité et à l’autonomie des équipes en place. Il faut toutefois bien chercher à autonomiser les équipes, sans quoi il vous sera impossible de “scaler” votre organisation autour des APIs, sans compter les effets de bord d’une logique de tour d’ivoire…