Dans un monde de plus en plus complexe, la capacité des organisations à intégrer rapidement les changements et à s’adapter en permanence devient un critère prépondérant de développement, voire de survie.
Pour gagner en souplesse et arrêter les processus lourds et complexes, accélérer l’innovation, rester compétitives, certaines entreprises comme Spotify, Michelin ou encore Favi ont sauté le pas de l’Entreprise Agile.
Cette transformation implique de repenser la culture d’entreprise pour favoriser la prise d’initiative et de réinventer l’organisation du travail autour du client avec des équipes auto-organisées et cross-fonctionnelles.
Découvrez un très bon exemple (mais pas un modèle) de ce type d’organisation : l’organisation Spotify.
Cet exemple de transformation a réussi parce qu’il était adapté à l’organisation Spotify et tenait compte de sa culture, ses valeurs et de ses pratiques.
Une gouvernance des données pragmatique est guidée par les usages métiers
Une gouvernance des données pragmatique est guidée par les usages métiers
La gouvernance des données est avant tout un sujet métier. Vous ne le traiteriez pas correctement en restant dans votre étage DSI… Cela peut paraître évident. Mais même quand certains le savent, ils choisissent la facilité : Rester à la maison…
« Gouvernance », le mot fait souvent peur. Si vous êtes consultant, vos clients les plus opérationnels vous font certainement un sourire poli quand vous évoquez le sujet, alors qu’ils pensent « Mais qu’est ce qu’il veut encore me vendre celui-là. Une machine à gaz qui va prendre beaucoup de temps, beaucoup de slides, et ne servir à rien ! » ; « Vous savez, nous avons déjà bien d’autres sujets à traiter ».
« Gouvernance des données », vous amenez l’expression avec habileté, en rappelant le volume considérable des données qui deviennent de plus en plus complexes à maintenir, sécuriser, exploiter, BLA, BLA, BLA. Et votre client le plus pragmatique vous dira « C’est bien gentil, mais ça ne m’aide pas à répondre à la demande de ce matin de l’équipe Marketing qui veut que je lui propose une solution pour cibler plus intelligemment les opérations / campagnes marketing… ou celle de l’autre jour de l’équipe Finance, qui n’en peut plus de faire à la main tous ses rapports sur Excel… »
Toute gouvernance, la gouvernance de données incluse, doit être une solution pour répondre à des usages et des points d’attention du métier (la DSI étant un métier parmi les autres).
Évitez la gouvernance de données pour la gouvernance de données !
Il existe une démarche qui a depuis longtemps trouvé sa place dans de nombreuses entreprises, mais qui a très vite montré ses limites, la voici (cela va vous parler si vous avez déjà challengé vos consultants sur le sujet) :
On va modéliser toutes les données existantes dans votre système d’informations
On va identifier les sources applicatives associées à ces différentes données
On va désigner des responsables pour chaque objet de données (des data owners, data stewards, …)
On va écrire des processus de gouvernances des données (validation, workflow, …)
On va mettre en place une instance de gouvernance sur la donnée
On fait tout ça d’abord avec notre vision DSI, on ira voir les métiers une fois qu’on aura une démarche déjà bien en place…
Alors, cela vous rappelle quelque chose ? Cette démarche : c’est faire de la gouvernance pour… SE FAIRE PLAISIR !
Une fois à l’étape 6, je vous défie de répondre précisément à la question suivante : « Alors, à quoi sert-elle cette nouvelle gouvernance ? Que va-t-elle améliorer précisément pour le marketing ? pour l’équipe financière ? pour l’équipe communication ? etc. ». N’ayez aucun doute là-dessus, la question vous sera posée !
La gouvernance des données doit être une solution pour mieux répondre aux usages :
Vos métiers utilisent les données. Ils savent ce qui doit être amélioré, ce qui leur manque comme données pour mieux travailler, tout ce qu’ils doivent faire aujourd’hui pour parer aux problématiques de qualité des données, le nombre de mails qu’ils doivent faire pour trouver la bonne donnée, parfois en urgence, pour leurs usages courants … Ils savent tout cela. Alors plutôt que d’inventorier toutes les données de vos systèmes, partez des usages des métiers et de leur point de vue et formalisez ces usages existants et les usages de demain
Concentrez vos efforts de gouvernance pour améliorer ou permettre les usages à plus forts enjeux ou risques pour l’entreprise
Cherchez à maîtriser l’ensemble de la chaîne de valeur, usage par usage (de la collecte à l’utilisation effective de la donnée pour l’usage) : organisation, responsabilités, outillages/SI
Faites évoluer votre gouvernance par itération, en partant toujours des usages.
Comprenez la stratégie de votre entreprise. Votre direction générale doit être sponsor. Donnez-lui les éléments pour la faire se prononcer sur une question simple : Sur quel pied doit danser en priorité la gouvernance Data, 40% sur le pied offensif (Aide au développement de nouveaux usages innovants), 60% sur le pied défensif ? (Gestion des risques GDPR, maîtrise de la qualité des données concernant les usages identifiés les plus critiques, …) ? 50/50 ? Elle doit vous donner les clés pour prioriser et itérer en adéquation avec la stratégie de l’entreprise.
La gouvernance des données est avant tout un sujet métier. Vous ne le traiteriez pas correctement en restant dans votre étage DSI… Cela peut paraître évident. Mais même quand certains le savent, ils choisissent la facilité : Rester à la maison…
Sortez, rencontrez tous les métiers, et vous formerez une base solide pour votre gouvernance. Ne sortez pas, et vous perdrez beaucoup de temps et d’argent…
Dans les métiers du digital (et presque partout ailleurs), nous sommes tous un peu accros à nos emails.
65% des salariés consultent leurs emails toutes les 5 minutes.
Les salariés consacrent en moyenne 28% de leur temps à traiter leurs emails … et 19% supplémentaires à chercher et rassembler l’information pour traiter leurs emails. Cela représente 28h par semaine pour les travailleurs de la connaissance.
L’impact sur l’économie américaine est estimé à 588 milliards de $ par an (source : Trésor Américain), et à 1 milliard de $ pour Intel.
Cette addiction aux emails est nourrie par :
Le principe de réciprocité qui veut que nous ayons tendance à répondre à quelqu’un qui nous sollicite,
L’attrait de l’immédiateté et l’adrénaline qui est libérée lorsque nous recevons un message (avec des sentiments de tension, d’exaltation, de nouveauté et de stimulation),
La valorisation sociale afférente : si je reçois un message c’est que je suis important,
Et enfin la décharge cognitive de l’émetteur vers le récepteur (le « bonheur » de renvoyer la patate chaude).
Les toilettes sont la cause n°1 de perte de smartphone.
Apple
Quelques conseils pour reprendre le contrôle et maîtriser cette addiction ?
Supprimer les « pushs » et autres notifications sonores et visuelles, pour ne pas être interrompu et décider du moment où nous aurons envie de voir ces informations,
Le matin, ne pas relever ses emails avant 10h30 et se mettre à un travail de fond dans les 30 secondes qui suivent l’arrivée au bureau, car cela permet d’avoir un niveau de concentration plus élevé sur la journée entière. Pas avant 10h30 car il est important de traiter en premier NOS priorités plutôt que celles des autres
Se tenir à trois créneaux maximum de traitement d’emails en dehors desquels la messagerie restera fermée
Mettre son smartphone en mode avion pendant les réunions et éviter de relever ses emails quand on ne peut pas agir (pendant un hackathon, WE en rafting, pause restaurant…)
Se préserver des temps longs (2x2h30 par semaine) et travailler de manière séquentielle et mono-tâche, ce qui signifie avoir UN SEUL logiciel ouvert
Aller à l’essentiel : aurions-nous cherché cette information si on ne nous l’avait pas transmise ? Non ? Alors supprimez cet email !
Pratiquer la minute consciente : visualiser le visage du ou des destinataires avant d’envoyer un email. Cela permet de challenger si le contenu et les destinataires sont les bons. A noter que ce conseil est valable aussi sur les réseaux sociaux
Éteindre tout avant le dîner et séparer matériellement le pro et le perso : téléphone, PC, agenda, liste de tâches
Se déconnecter complètement à intervalle régulier pour se « rafraichir » le cerveau (24 heures par semaine et 2 semaines par an).
Alors à la veille des vacances, pourquoi ne pas se fixer un challenge « 0 connexion » pendant 2 semaines ?
Et pour la rentrée, mettre en pratique quelques-uns de ces conseils. C’est à vous de décider vos moyens d’interactions avec vos appareils, pas l’inverse.
Saviez-vous qu’il faut 2000 essais avant qu’un enfant soit capable de marcher sur ses deux pieds ?
Pourtant à l’âge adulte et en particulier dans le monde professionnel, l’échec est trop souvent stigmatisé et tabou. Comment inverser cette perception en voyant ses échecs comme le premier pas d’une future réussite ?
Cette démystification de l’échec passe par trois phases : l’observation & la captation des signaux faibles sur le terrain, l’expérimentation sur des cycles relativement courts, et pour finir la capitalisation afin de garantir de meilleurs résultats la fois d’après.
Oui, la Donnée est bien un Actif comme les autres !
Oui, la Donnée est bien un Actif comme les autres !
Vous avez peut-être souvent entendu ces mots « Data is an Asset ». Mais la personne qui les prononce va rarement au bout de l’idée. Et pour cause, l’exercice est plus complexe qu’il n’en a l’air. Cet article a pour ambition d’éclairer le domaine et, pour cela, procédons par étape :
1 – Qu’est-ce qu’un Asset ?
Nous n’allons pas l’inventer, il existe une très bonne définition sur ce site : https://www.investopedia.com/ask/answers/12/what-is-an-asset.asp)
« An asset is anything of value that can be converted into cash. Assets are owned by individuals, businesses and governments »
« Un asset est quelque chose qui peut être converti en monnaie sonnante et trébuchante ».
Avec une maison, cela marche bien en effet. Une expertise suffira à vous donner une bonne idée de la valeur euro de votre maison. Mais pour vos données, ça ne paraît pas si simple.
Le défi aujourd’hui est d’être en mesure de valoriser une donnée, ce qui signifie :
Pouvoir par exemple très formellement comparer deux actifs Data entre eux, deux jeux de données (par exemple sur la base de critères bien définis)
Mettre une valeur « euro » sur un jeu de données (monétisation, prise en compte de l’actif Data sur des opérations d’acquisition / fusion, etc.)
Gérer nos données comme des Actifs, pour maintenir ou développer leur valeur dans le temps
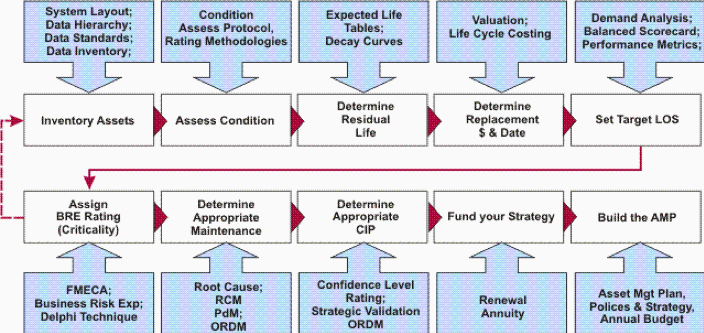
Sur ce dernier point, faisons l’exercice rapide ensemble. Prenons un processus d’asset management standard, appliquons-le à la donnée.
2 – Appliquons un Processus d’Asset management à la Data
Alors allons y ! Appliquons ce processus sur les données pour voir si elle peut être gérée comme un Asset ?
« Inventory » :Inventorier les assets Data. Jusque-là tout va bien.
« Asset Condition Assessment » :Évaluer l’état des biens: Est-ce que la donnée est de qualité, est-ce qu’elle il y a souvent des erreurs qui apparaissent ? Comment les gère-t-on ?
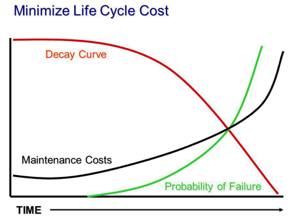
« Determine residual Life / Decay curve » : Il s’agit d’évaluer l’évolution potentielle de différents critères de valeur dans le temps. Par exemple est-ce que la donnée risque de perdre en rareté ? Les usages vont-ils être moins importants ? etc. En général cette notion porte sur le vieillissement d’un bien physique :
« Valuation » : Pour valoriser la donnée, on sent qu’il nous faut poser clairement un cadre de valorisation sur base d’un ensemble de critères. Au même titre que l’expert par exemple en Asset commercial connaît parfaitement les critères qui permettent da valoriser un commerce (surface du commerce, chiffre d’affaire, situation géographique, etc…). Notre conviction est qu’il faut aujourd’hui développer ce cadre pour l’actif « Data ».
« Life Cycle Costing » : C’est le processus qui permet d’identifier tous les coûts impliqués dans le cycle de vie de l’actif (coût d’une erreur, coût de la réparation / correction, coût de la perte de production éventuelle, coût de la maintenance corrective, ….)
« Determine replacements» : Est-ce qu’il faut revoir la manière de gérer certains asset Data ? Faut-il en abandonner/purger certains, non rentables ?
« Set target LOS » : Quel est le niveau de service attendu sur chaque asset Data ? A quels besoins faut-il répondre pour que l’asset ait de la valeur, soit viable ? Quels critères de valorisation veut-on améliorer ? (rareté, qualité, …)
« Assign BRE rating » = Business Risk Evaluation : Et quels sont les risques ? (GDPR, perte de données, …) : « Comment est-ce que des problèmes / incidents peuvent apparaître ? Quelle probabilité d’apparition ? Qu’est cela coûterait si le problème apparaissait ? Quelles en seraient les différentes conséquences ? »
« Determine Appropriate Maintenance » : Si l’on veut maintenir la qualité d’une donnée par exemple, par exemple 3 stratégies de maintenance existent dans le monde physique, elles sont applicables à l’actif Data (Use Base Maintenance : revue à une fréquence donnée, Fail based maintenance : correction sur incident/erreur, Condition Bases Maintenance : Maintenance plus préventive)
« Determine Appropriate CIP » (Capital Investment Program) : Initier (ou mettre à jour) notre programme d’investissement (Projet d’extension du capital d’assets Data, de renouvellement/modification de la gestion de certains Assets, mise en place de nouveaux processus de maintenance = gouvernance…)
« Fund your strategy » : On obtient le financement pour tout cela
« Build the Asset Management Plan » : Enfin on construit, ou on met à jour notre plan de gestion et de valorisation de nos assets Data
La méthode a l’air adaptée. Mais elle soulève des questions clés, auxquelles il va nous falloir répondre, notamment concernant les critères de valorisation. A titre d’exemple, le CIGREF a travaillé sur un cadre d’appréciation de la valeur économique des projets de transformation numérique. Il est intéressant d’avoir une approche comparable pour l’actif « Data ».
3 – Et après ?
Nous venons de voir que la data est effectivement un actif, d’un type bien particulier. Pour aller plus loin, il va falloir identifier des critères objectifs de valorisation des données, et faire des usages de ces données un vecteur clé de sa valorisation.
Dans cet optique, nous pensons qu’un cadre méthodologique de valorisation des données est nécessaire.
Rhapsodies Conseil construit une approche méthodologique pour mesurer la valeur des données, en mettant les usages métiers des données au cœur de la méthodologie, approche que nous vous invitons à découvrir prochainement. En parallèle, nous vous recommandons les travaux initiés sur ces sujets par Doug Laney pour Gartner Inc., en particulier à travers son ouvrage « Infonomics » aux éditions Routledge.
Les nouvelles réformes engagées sous l’appellation « finalisation de Bâle III », que l’industrie financière nomme déjà « Bâle IV », soumettent les méthodes de calcul des RWA, notamment en ce qui concerne le risque de crédit, à d’importantes modifications.
En effet, en matière de ratio de capital, les apports de Bâle III, applicable depuis 2013, ont porté sur son numérateur (renforcement quantitatif et qualitatif des fonds propres), alors que très peu de modifications ont été apportées à son dénominateur (RWA). L’actuelle méthode de calcul de ce dernier est principalement héritée de Bâle II (2004).
Pourquoi la méthode standard ?
Depuis décembre 2017, le Comité affiche une volonté de faire évoluer le traitement des RWA. Pour ce faire, il prévoit, entre autres, une profonde refonte de la méthode standard du risque de crédit.
L’importance de cette mesure tient avant tout à l’importance de la méthode standard elle-même dans l’usage bancaire. En France, en Europe et à l’échelle mondiale[1], cette méthode est la plus utilisée. Par conséquent, la plupart des acteurs bancaires sont concernés par la mise en œuvre de la nouvelle méthode et devraient s’y préparer.
Les nouveautés
Le texte du Comité de Bâle de Décembre 2017 fixe, avec un important niveau de détail, les nouvelles réformes de la méthode standard. Sans vouloir restituer ici toute la complexité du dispositif, nous abordons ses deux apports les plus novateurs, à savoir :
Même si ces deux éléments ont pour motivation commune le renforcement de la sensibilité au risque, la démarche du comité soulève quelques interrogations sur l’atteinte de l’objectif.
1- Plus de granularité pour plus de sensibilité au risque ?
Le manque de sensibilité au risque est l’une des critiques adressées par le Comité de Bâle lui-même au dispositif actuel. L’objectif des nouvelles réformes est justement de surmonter cette faiblesse.
Tenir compte de la sensibilité au risque sans pour autant complexifier la méthode standard, voilà le défi auquel le Comité a fait face. Pour le relever, il a choisi l’option de la granularité. Concrètement, le Comité estime que la méthode actuelle (héritée de Bâle II) n’associe pas un nombre suffisant de pondérations à certaines expositions, ce qui réduit la sensibilité au risque. La nouvelle méthode, quant à elle, augmente le nombre de pondérations pour beaucoup d’expositions (clientèle de détail, immobilier résidentiel, immobilier commercial…).
Si nous prenons le cas de la clientèle de détail (hors immobilier) nous constatons un niveau de granularité nettement plus important dans la nouvelle réforme (figure 1.2) comparée à la méthode actuelle (figure 1.1) :
Figure 1.1 : Méthode actuelle
Expositions sur la clientèle de détail (hors immobilier)
Pondération
75%
Source : BRI, 2006
Figure 1.2 :
Expositions sur la clientèle de détail (hors immobilier)
Clientèle de détail réglementaire (non renouvelable)
Clientèle de détail réglementaire (renouvelable)
Autres expositions sur la clientèle de détail
« Transactors »
« Revolvers »
Pondération
75%
45%
75%
100%
Source : BRI, 2017
Jusque-là, la granularité évolue bien vers un renforcement de la sensibilité au risque. Cependant, le secteur de l’immobilier, fortement mis en avant par le Comité, soulève question : le Comité introduit le ratio LTV[3] comme critère de pondération. Ce choix est questionnable étant donné son caractère procyclique qui va à l’opposé du renforcement de la sensibilité au risque recherché par le Comité.
Il semble que les leçons de la crise de 2007 n’ont pas été entièrement tirées. Il ne faudrait pas oublier que le marché immobilier américain se trouvait au cœur de cette crise et que le financement d’une partie de ce marché reposait davantage sur la valeur des biens acquis que sur la capacité de leurs acquéreurs à rembourser leurs prêts. Le LTV renforce cette même logique. Quelle est alors la cohérence d’introduire un dispositif comme le LTV dans un cadre prudentiel visant le renforcement de la sensibilité au risque ?
2 – SCRA, autorisation explicite à moins de granularité !
Cette approche est prévue pour les juridictions n’autorisant pas le recours aux notations externes à des fins réglementaires (notamment les Etats-Unis jusqu’à présent) et pour les expositions non notées dans les juridictions permettant le recours aux notations externes. A la différence de l’approche ECRA[4], dont la granularité a bien été renforcée, l’approche SCRA est composée de trois tranches de risque seulement : A, B et C. La figure 3 illustre cela dans le cas des expositions sur les banques.
Figure 2 : Pondération des risques afférents aux banques (ECRA vs SCRA)
Figure 2.1 : Approche externe de l’évaluation du risque de crédit (ECRA)
Note externe de la contrepartie
AAA à AA-
A+ à A-
BBB+ à BBB-
BB+ à B6
Inférieur à B-
Coefficient standard
20%
30%
50%
100%
150%
Pondération des risques afférents aux expositions à court terme
20%
20%
20%
50%
150%
Figure 2.2 : Approche standard de l’évaluation du risque de crédit (SCRA)
Evaluation du risque de crédit de la contrepartie
Tranche A
Tranche B
Tranche C
Coefficient standard
40%
75%
150%
Pondération des risques afférents aux expositions à court terme
20%
50%
150%
En attendant Bâle V ?
Dans le cadre de négociations internationales ayant pour but de bâtir un consensus mondial sur la régulation du système bancaire, il est concevable que les parties fassent des concessions. Néanmoins, les concessions faites dans la version actuelle (probablement finale) de Bâle IV limitent la portée de l’objectif même de la réforme, à savoir le renforcement de la cohérence et de la crédibilité de la mesure des RWA, pour au moins deux raisons :
Le renforcement de la sensibilité au risque afin de rétablir la crédibilité du calcul des RWA et l’introduction pour la première fois du LTV susceptible de décrédibiliser le dispositif.
L’introduction de davantage de granularité avec l’approche ECRA et dans le même temps l’admission du recours à l’approche SCRA qui est moins granulaire !
Ces interrogations seront-elles soulevées lors de la transposition des recommandations du Comité dans le droit européen, afin d’éviter un nouvel accord, probablement Bâle V ? Ou seront-elles ajournées aux prochaines négociations ?
[1] Comité de Bâle sur le contrôle bancaire : Note récapitulative sur les réformes de Bâle III, Décembre 2017. [2] Standardised Credit Risk Assessment Approach. [3] Loan to Value. Ce ratio est égal à : montant de l’emprunt/valeur du bien. [4] External Credit Risk Assessment Approach.