Le MCP visant à faciliter l’accès d’un client via ses LLM à des ressources distantes, il se base sur une architecture client – serveur classique.
Du côté client, deux briques : l’hôte (application ou utilisateur via son application IA de chat, IDE, etc.) et le client (instance spécifique créée par l’hôte en vue de la communication avec le serveur MCP visé). Si l’hôte doit requêter plusieurs serveurs MCP différents, il instancier autant de clients MCP, afin de garder cette relation un-pour-un.
Concepts
Afin d’établir une communication entre client et serveur, il est nécessaire de connaître les capacités offertes par chacun. Dans MCP cela se fait via une notion appelée primitive. Client et serveur s’exposent des primitives l’un à l’autre.
Primitives exposées par le serveur :
Prompt : template à réutiliser par les LLM comme guide de requête pour bien utiliser les capacités du serveur (par exemple donnant des paramètres à inclure dans une future requête) ;
Ressource : données statiques (ou quasi) du serveur exposées, typiquement pour du cache : fichiers, réponses API ;
Tool : fonctions (écrire dans BDD, appel API, écriture fichier) appelées par le LLM.
Ressource et tool semblent assez proches, l’un comme l’autre pouvant retourner de la donnée. La principale différence réside dans la manière de les contrôler : par l’application pour les ressources et par le modèle pour les tools. Autrement dit, les tools peuvent être appelés de manière autonome par le LLM, tandis que les ressources ne sont appelées que via un choix de l’utilisateur/application.
Primitives exposées par le client :
Sampling (échantillonnage) : permet au serveur de demander au client d’utiliser son LLM pour une tâche, avec potentielle intégration d’une validation utilisateur. Le serveur MCP n’a ainsi pas besoin d’avoir un SDK de langage, ni de payer un abonnement à un LLM ;
Elicitation : permet au serveur de demander de façon structurée des informations supplémentaires à l’utilisateur ;
Roots (racines) : permet de préciser au serveur une organisation des dossiers & fichiers du client, une segmentation/structuration par domaine, ou par privilège. Le client précise ce périmètre d’accès afin que le serveur “comprenne” mieux où rechercher des informations du client. Attention, cela n’applique aucun contrôle d’accès, aucune sécurité. Tout cela doit être fait par ailleurs, hors du cadre du MCP ;
Logging : envoi de messages log au client pour déboguer et monitorer.
Protocole
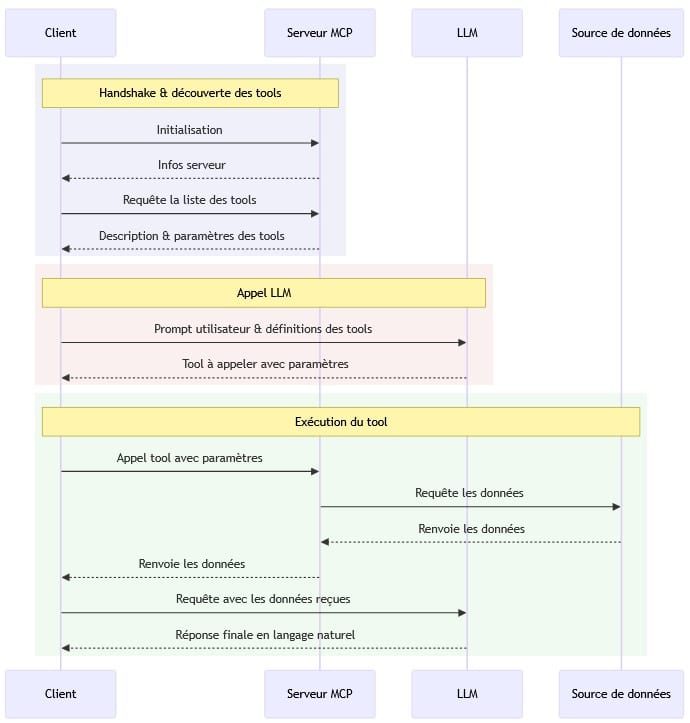
Le MCP utilise du JSON-RPC 2.0. Sans rentrer trop dans le détail de chaque étape du protocole, la connexion commence par un handshake puis une découverte. Y sont échangés la version de protocole, les capacités supportées par le client et le serveur, notamment au travers de l’échange des primitives. Une fois ces primitives supportées connues, on peut les lister.
Par exemple, le serveur dit au client qu’il supporte les primitives type tools. Le client demande alors une liste de ces tools puis il peut faire les appels souhaités. Enfin, le serveur peut aussi envoyer des notifications pour prévenir le client de changements.
Intégration au SI
Le MCP ayant pour but de faciliter un accès à des ressources, il est essentiel de les protéger. Imaginons que notre serveur MCP ait comme outil des appels API sur une base de données. Il convient de gérer ces API de la même manière qu’on le ferait habituellement : plateforme d’API management, application de policies de rate limiting, gestion de l’authentification et de l’autorisation, etc.
Le MCP ne remplace en rien ces sécurités. Le besoin est au contraire accru car les appels issus d’IA sont potentiellement moins contrôlés qu’avec des applications/utilisateurs classiques où l’on choisit normalement mieux les appels générés. C’est pour cela que certains APIs Gateway gèrent aussi le filtrage et le routing de LLM, afin entre autres d’éviter d’envoyer des données critiques à des LLMs publiques.
A2A
Le protocole A2A se base lui aussi sur une notion de client-serveur. Un utilisateur final, qu’il soit humain ou non, fait une requête nécessitant des agents. L’agent client (application, service ou agent IA) vient initier une communication comme client vers un agent distant agissant comme serveur. Ce dernier a une bonne couche d’abstraction, du point de vue de l’agent client, l’agent distant est une boîte noire ayant des capacités d’intérêt.
Concepts
Afin de connaître ces capacités, l’agent expose son Agent Card (fichier JSON), qui va permettre la découverte. Elle contient une description, l’URL de l’endpoint du service, les options supportées, l’authentification nécessaire, …
Les deux agents communiqueront au moyen de Messages, représentant un tour de communication. Ce Message a un rôle : utilisateur ou agent. Surtout il contient une ou plusieurs parts.Une Part est la donnée utile transmise, que ce soit du texte, un fichier, une image, etc.
L’agent client fera une requête qui débouchera sur une Task (tâche) du côté agent distant. Cette tâche débouchera sur un Artefact, le résultat généré par l’agent distant, constitué de une ou plusieurs Parts.
Protocole
A2A utilise HTTPS pour le transport et JSON-RPC2.0 pour le format de payload.
Plusieurs mécanismes de découverte sont envisageables, selon les cas d’usages : exposer l’agent card serveur sur une URI standardisée, la référencer dans un catalogue d’entreprise, ou encore l’inscrire en dur dans le client. Selon le niveau de sensibilité pour l’entreprise des informations présentes sur la carte, il conviendra d’ajuster le niveau de protection nécessaire.
A2A peut donc utiliser des protocoles type OAuth2, OIDC. L’autorisation est gérée par le serveur, l’agent A2A distant, alors que l’authentification est typiquement déléguée à l’IAM de l’entreprise. Pour gérer au mieux la couche de sécurité, la performance et la cohérence entre les agents de l’entreprise, bref pour une meilleure gouvernance, il est conseillé d’intégrer ces serveurs A2A avec les solutions d’intégration type API management.
Si certaines requêtes sont simples, on peut s’attendre à une réponse immédiate, via un objet message. Inversement, si la requête est complexe, le traitement peut être long et donc nécessiter un objet tâche (ou plusieurs en parallèle). Il faut alors éviter de bloquer l’agent client. Donc trouver divers modes permettant d’avoir l’information d’avancement de la tâche et de son résultat. Notamment utiliser de l’asynchrone.
En mode pooling (requête/réponse), le fonctionnement basique, une fois la tâche créée côté agent distant, le client demande régulièrement l’état de la tâche ;
En mode streaming Server Sent Events (SSE), le serveur envoie l’état en temps réel, voire des résultats de manière incrémentale (à la manière d’un texte qui se complète peu à peu) ;
En mode notification push, grâce à une webhook, le serveur communique sur des avancées significatives sur la tâche.
Grâce à ces divers modes, on peut ainsi être au courant qu’une tâche a été créée, de son avancement, qu’un artefact a été généré et enfin que la tâche est terminée.
A noter que même terminée ou rejetée, si besoin de raffiner une réponse, on pourra se référer au contexte d’une tâche précédente, mais toujours via une nouvelle. Pas de redémarrage d’une tâche passée.
MCP & A2A
A première vue, MCP & A2A pourraient se recouper.
En réalité, le MCP s’intéresse à faciliter et standardiser l’accès à des ressources par un agent. Le A2A s’intéresse à faciliter la communication entre agents en vue d’une tâche, la décomposer en sous-tâches mieux réparties.
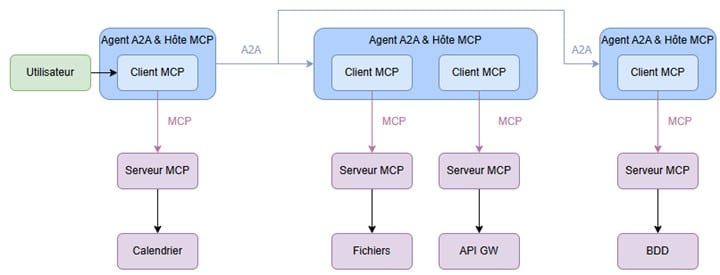
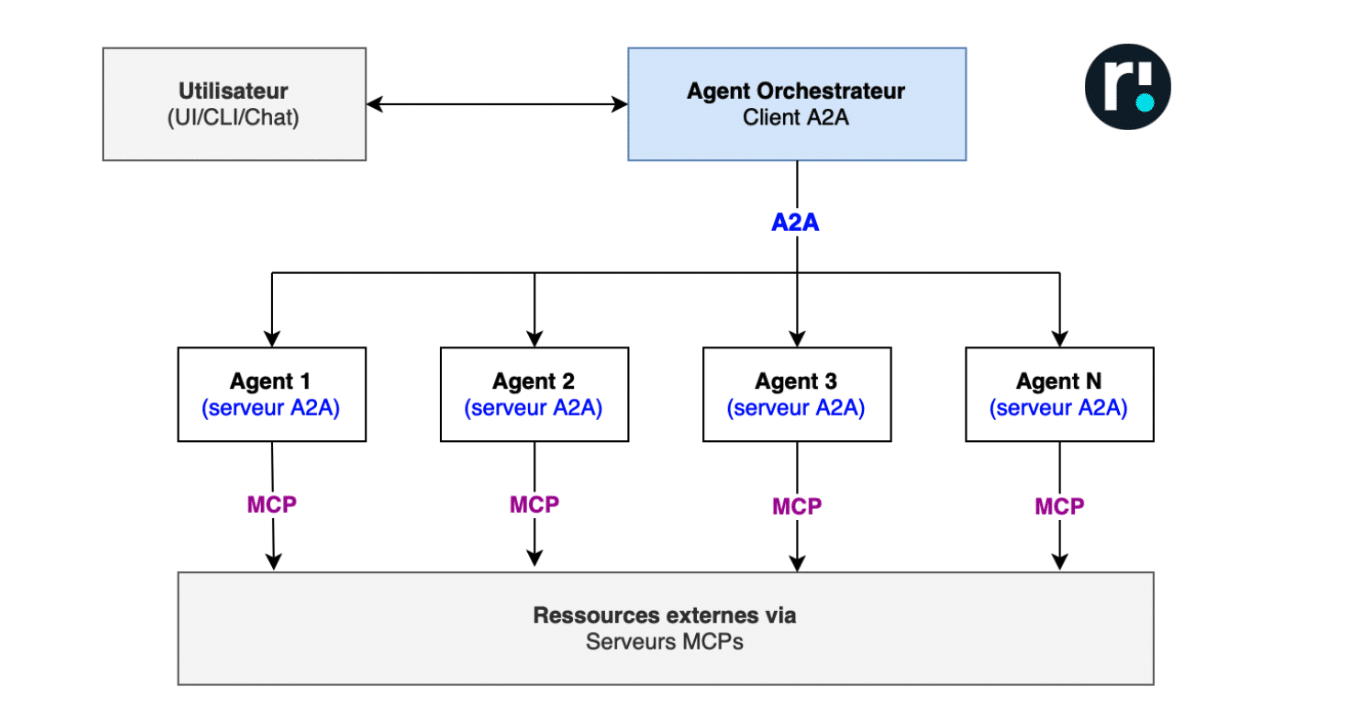
Dès lors MCP et A2A se complètent. Pour résoudre une tâche complexe faisant appel à des données dispersées, on utilisera du A2A pour orchestrer la communication avec des agents spécialisés. Ces agents spécialisés utiliseront du MCP pour requêter les données nécessaires à la résolution du problème.
Un serveur A2A pourrait exposer des capacités en tant que ressources MCP si elles sont bien définies, accessibles avec du stateless, etc.
En combinant MCP et A2A, on passe d’un ensemble d’agents et de ressources isolés à un écosystème cohérent, interopérable et scalable, où l’accès aux données et la coordination des agents sont contrôlés, réutilisables et auditables.
Avant l’utilisation de serveurs MCP, l’accès pour un client IA à des ressources extérieures à son environnement se faisait le plus souvent avec des techniques peu robustes et peu standardisées entre écosystèmes IA différents.
L’entrée en scène des LLM dans les échanges entre systèmes d’information a relevé le fait que l’existant en termes d’échange de données n’est que très peu adapté à ce nouvel acteur. Les premières méthodes permettant à un hôte IA de rechercher des informations auprès de sources extérieures ont permis de mettre en lumière les problèmes structurels de l’approche première.
Contexte Pré-MCP
Le principal problème de l’approche initiale est qu’elle nécessitait un couplage fort entre le framework IA d’une part et d’autre part les APIs et autres ressources externes qui, elles, pouvaient être amenées à évoluer indépendamment. Ce couplage rendait la maintenance des intégrations une préoccupation persistante pour le développeur d’une solution IA.
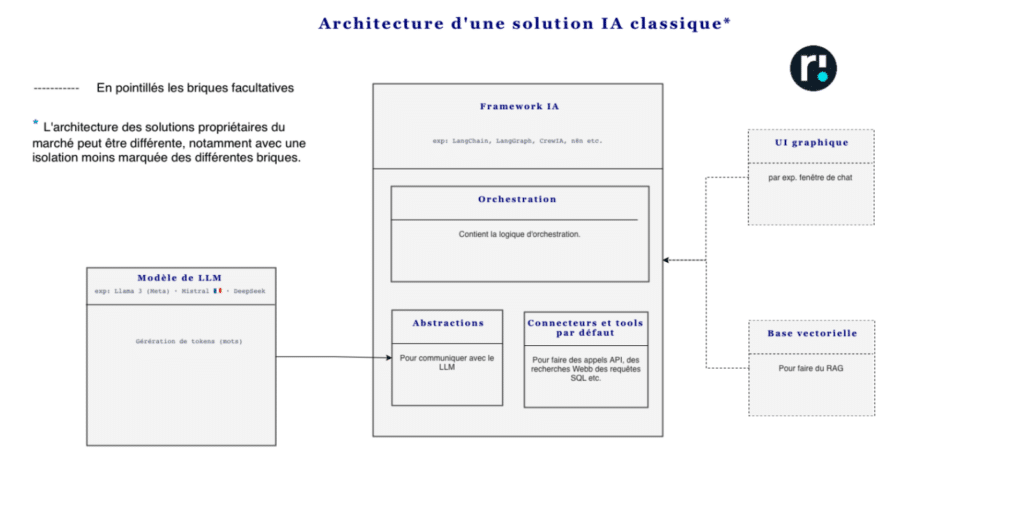
Afin de comprendre comment un hôte ou agent IA communique avec des API externes, il est nécessaire de comprendre la séparation entre la couche LLM (qui émet des tokens) et le framework IA qui permet la logique autour de l’interaction avec le modèle.
La couche LLM est la couche basique de génération de tokens, elle ne comprend qu’une suite de tokens et ne renvoie qu’une autre suite de tokens. Elle n’a accès ni à des API externes, ni aux fonctions qui permettent de les appeler.
C’est le framework IA (langChain, AutoGPT etc.), qui fera le lien entre la “volonté” ou “action” exprimée en langage naturel par le LLM, et l’exécution de cette action.
Pour cela le Framework IA, comprend une bibliothèque interne de tools, qui permettent d’effectuer les appels ou requêtes nécessaires.
Le workflow de récupération de ressources externes par un hôte IA, pré-MCP était le suivant:
La Définition des capacités: La liste des tools disponibles à l’utilisation, ainsi que les exigences sur le format d’instruction attendu est transmise au LLM par le framework via le System Prompt .
L’interception et exécution de la commande: Il existe plusieurs paradigmes pour intercepter une commande émise par un LLM. Celui que nous décrirons ici repose sur le principe suivant : lorsque, au cours de sa génération de texte, le LLM s’apprête à déclencher un appel vers une action externe, il émet une “signal” textuel – différent d’un framework à l’autre, indiquant qu’un tool doit être invoqué.
Ce signal informe l’orchestrateur que la suite de la génération ne correspond plus à du texte libre, mais à une structure attendue, généralement un objet JSON. Le framework peut alors parser le JSON via des regex ou un parseur dédié, identifier le tool à invoquer ainsi que les arguments à rattacher. Il peut alors exécuter l’action en lançant par exemple un script python écrit et stocké dans le framework.
“signal”
{
"name": "send_email",
"arguments": {
"recipient": "bob@example.com",
"subject": "Urgent",
"body": "Bonjour Bob, voici les infos demandées."
}
}
“signal”
Exemple de génération LLM demandant au framework l'envoi d'un email.
Renvoi de la réponse: Une fois le résultat de la requête réceptionnée, le framework envoie le résultat (ex: “Email envoyé avec succès. Heure: 12h34), qu’il le renvoie au comme System prompt ou Contexte supplémentaire au LLM, qui peut alors répondre à l’utilisateur “C’est fait, l’email a été envoyé à Bob.”
Problématiques intrinsèques
Intégration sur mesure pour chaque ressource exploitée: Chaque API ou base (CRM, météo, paiement, DB interne, etc.) nécessite une intégration spécifique, qui plus est doit être faite et maintenue au niveau du framework IA et diffère donc d’un framework à l’autre.
Duplication: L’intégration et les tools ne sont que très peu ou pas réutilisés, et sont repensés pour chaque framework même si la donnée à récupérer est la même
Maintenance explosive: Le moindre changement de contrat d’API imposait de modifier le tool ou même le schéma de function calling, avec risque de régressions silencieuses.
Solution apportée: le MCP
Le MCP (Model Context Protocol) est un protocole ouvert proposé par Anthropic fin 2024 et qui propose une nouvelle façon pour une source de donnée quelconque, d’exposer ses informations de sorte à pouvoir être exploitées de façon plus fluide par un hôte IA.
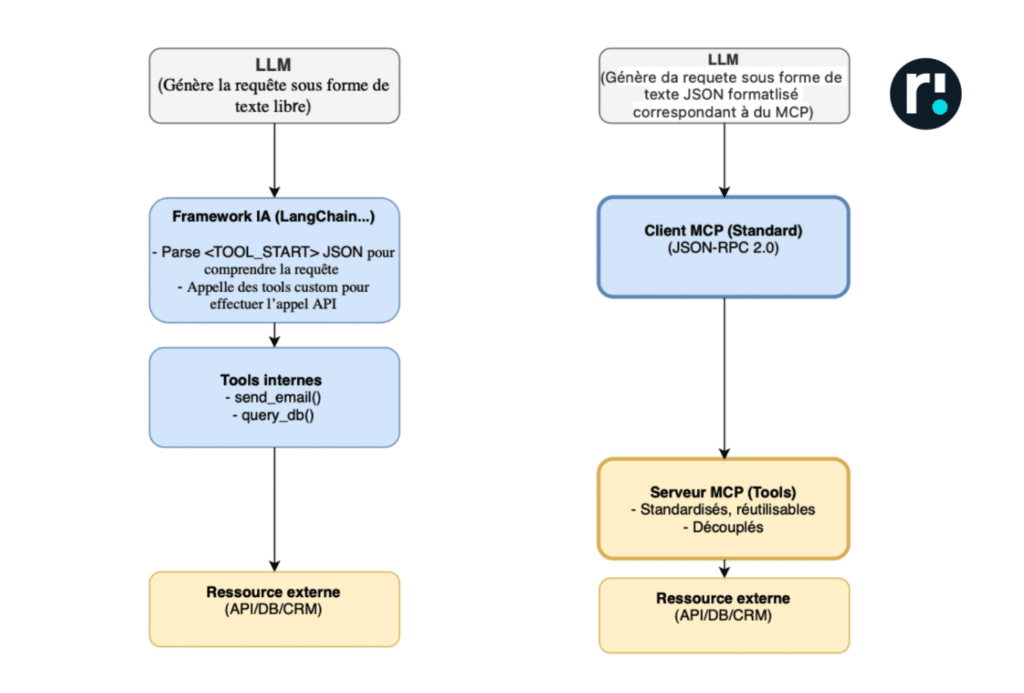
Pour cela il propose plus qu’un langage d’échange différent (le MCP repose sur JSON-RPC, qui est déjà connu et éprouvé). Son apport réel réside dans un changement de paradigme : on passe d’un modèle où l’hôte IA va chercher l’information directement chez chaque source via des intégrations spécifiques, à un modèle où les sources de données exposent leurs capacités et leurs informations via des serveurs MCP standardisés.
Comparatif de l’architecture avant et après MCP – L’exposition de la donnée est faire côté source de donnée, via un serveur MCP qui va exposer de façon compréhensible par tout client utilisant du MCP, les données qu’elle veut exposer.
On observe ici un déplacement de l’effort d’intégration et de maintenance : il passe de l’intérieur des frameworks IA vers l’extérieur, en couplant le point d’entrée MCP directement à la source de données. Une fois instancié et maintenu, le serveur MCP devient alors mutualisable et peut être consommé par autant de clients MCP que nécessaire, qu’il s’agisse d’hôtes IA, d’applications, d’IDE ou de tout autre service compatible avec le format MCP.
Ce changement de paradigme qu’apporte le protocole MCP permet de solutionner une partie des problèmes qui se présentaient avant.
Standardisation de l’intégration: L’intégration, via le serveur MCP est écrite une seule fois, et est utilisée indépendamment du framework ou du modèle utilisé.
Mutualisation et réutilisabilité : Un serveur MCP peut être consommé par plusieurs clients sans réécriture spécifique. La logique d’accès à la donnée n’est plus dupliquée pour chaque framework. On sépare clairement la couche d’orchestration de la couche d’accès aux ressources.
Isolation des évolutions et réduction du couplage : Les changements d’API sont traités dans le serveur MCP. Le contrat client et serveur reste stable et un seul serveur exposant la donnée est à maintenir à jour;
Le A2A: Communiquer entre Agents IA
Comme le MCP la communication entre Agents se faisait via un mode de communication prévu alors pour les échanges entre systèmes déterministes “traditionnels” et non entre LLM.
Le protocole A2A, développé par Google apparaît peu après le MCP et se veut explicitement complémentaire: MCP gère l’accès aux ressources pour un agent et A2A coordonne la communication et la délégation entre réseau d’agents.
Pourquoi le A2A
Si nous prenons l’exemple d’une architecture multi agents centralisée (Orchestrateurs et subordonnés). L’agent principal va vouloir déléguer ses tâches à d’autres agents soit
Spécialisés: pour lui permettre d’acquérir des compétences et expertises supplémentaires.
Génériques: pour lui permettre de paralléliser et déléguer ses tâches
Le protocole A2A va permettre de standardiser cette communication et dynamiser la découverte de capacités, c’est-à-dire permettre à l’agent orchestrateur de savoir quelles sont les capacités des agents à sa disposition afin de filtrer/sélectionner le bon agent pour chaque usage.
Concrètement, il va permettre à chaque agent d’exposer une “Agent Card” qui joue de rôle de fiche descriptive ou carte d’identité listant ce que l’agent sait faire et comment l’utiliser.
Dans cette fiche descriptive, l’agent indique les contraintes et capacités, par exemple les limites d’accès, les scopes autorisés, ou les prérequis pour invoquer une fonction.
Le A2A prévoit notamment la gestion de scopes et permissions, l’authentification envers les agents et un de suivi en temps réel (streaming, notifications) des tâches déléguées, entre autres capacités.
Le A2A comme solution
Le protocole A2A répond à un besoin nouveau : faire communiquer un réseau d’agents, majoritairement pilotés par des LLM, de manière à la fois standardisée et maîtrisée. Concrètement, il permet :
Standardisation et déterminisme : le standard permet une certaine maîtrise des échanges et de l’exposition des agents. Cela malgré le comportement intrinsèquement non déterministe et parfois chaotique des LLMs.
Gouvernance et observabilité : La standardisation des règles et du mode de communication entre agents se complète d’autres mécanismes comme le suivi des échanges grâce à du monitoring ainsi que des audit trails par exemple.
Interopérabilité plug-and-play : Les agents “encapsulés” de façon standard peuvent rejoindre ou quitter un réseau sans nécessiter de réécriture des intégrations.
Scalabilité : La résultante de ces différents mécanismes est une délégation et coordination plus efficaces entre agents, qu’ils soient spécialisés ou génériques, et ce même dans des réseaux complexes.
Ainsi, A2A transforme un ensemble d’agents en un écosystème coopératif, contrôlable et extensible.
Conclusion
En combinant MCP et A2A, on passe d’un ensemble d’agents et de ressources isolés à un écosystème cohérent, interopérable et scalable, où l’accès aux données et la coordination des agents sont contrôlés, réutilisables et auditables. Ces protocoles ouvrent la voie à des architectures multi-agents robustes, capables de gérer des réseaux complexes d’IA tout en garantissant sécurité, standardisation et évolutivité. Les capacités apportées par l’IA générative et encadrées par ces deux protocoles permettent d’élargir encore plus le champ des possibles en envisageant une industrialisation à large échelle de l’IA générative.
Résolution d’identité : pourquoi votre RCU échouera sans elle
Résolution d'identité : pourquoi votre RCU échouera sans elle
La vraie question aujourd’hui, ce n’est plus de savoir si vous devez travailler votre résolution d’identité. C’est de comprendre comment vous allez l’implémenter pour qu’elle serve concrètement votre business, pas juste pour cocher une case « RCU » dans votre roadmap IT.
Vous investissez dans un Référentiel Client Unique. Vous connectez vos systèmes, vous nettoyez vos bases, vous alignez vos équipes. Pourtant, 6 mois après le lancement, vos doublons sont de retour. Vos campagnes ciblent toujours les mêmes clients en triple exemplaire. Votre vision 360° reste fragmentée.
Le problème n’est pas votre technologie. C’est votre stratégie de résolution d’identité.
La résolution d’identité est le cœur battant de votre RCU. Sans elle, vous n’avez qu’une base de données centralisée de plus. Avec elle, vous obtenez enfin ce que vous cherchiez : une source de vérité unique sur vos clients.
Mais toutes les approches ne se valent pas. Et surtout, il n’existe pas de solution miracle.
La vérité inconfortable : vous devrez choisir entre fiabilité et couverture
L’approche déterministe : la rigueur au prix de l’aveuglement
Le principe est simple : vous utilisez un identifiant unique et vérifiable (email, téléphone, numéro de carte) pour reconnaître vos clients à coup sûr.
Un client s’inscrit à la newsletter avec son email, crée un compte e-commerce, télécharge l’app mobile et achète en magasin en donnant ce même email ? Parfait. Toutes ces interactions sont automatiquement rattachées à un profil unique. Fiabilité : 99,9%.
C’est l’approche incontournable pour tout ce qui compte vraiment :
Transactions et paiements
Service après-vente
Gestion de compte et programme de fidélité
Conformité RGPD (consentement traçable)
Mais elle a trois angles morts critiques :
1. Vous êtes aveugle aux visiteurs anonymes
Que se passe-t-il pour les 60 à 80% de visiteurs qui naviguent sans créer de compte ? Pour les clients qui ne souhaitent pas s’identifier avant d’acheter ? Pour le trafic en magasin non rattaché à la fidélité ?
→ Vous perdez toute la phase d’exploration et de considération. Vous ne voyez que la conversion finale, sans comprendre le parcours qui y mène.
2. Un identifiant ≠ toujours une personne
Marie a trois adresses email : perso, pro, et son ancienne adresse Hotmail qu’elle utilise encore pour certains achats. Dans votre système, Marie = 3 profils différents. Paul et Sophie partagent l’email familial pour les achats en ligne. Dans votre système, Paul et Sophie = 1 profil.
→ Vous créez des doublons tout en fusionnant des personnes distinctes. Vos statistiques sont faussées dans les deux sens.
3. C’est une porte ouverte à l’usurpation d’identité
Si votre résolution d’identité repose uniquement sur email + nom/prénom, n’importe qui peut créer un compte à votre place. En magasin, avec quelques informations basiques, un tiers peut accéder au compte de quelqu’un d’autre.
La solution ? Authentification forte (email/SMS de confirmation, 2FA). Le coût ? Friction supplémentaire, taux d’abandon en hausse.
Le verdict : l’approche déterministe est indispensable, mais insuffisante.
L’approche probabiliste : la couverture totale au prix de l’incertitude
Le principe est radicalement différent : vous analysez des dizaines de signaux comportementaux et techniques pour déduire statistiquement qu’il s’agit de la même personne, même sans identifiant commun.
Les signaux utilisés :
Caractéristiques de l’appareil (modèle, OS, navigateur, résolution)
Comportement (produits consultés, temps passé, parcours)
Temporalité (heures et jours de visite, fréquence)
Exemple concret :
Deux sessions partagent la même IP, le même appareil (iPhone 14 Pro, iOS 17), des habitudes de navigation similaires (catégorie « chaussures femme » entre 20h et 22h), et la même géolocalisation (Paris 15ème).
→ Probabilité > 90% qu’il s’agisse de la même personne, même si elle n’est pas connectée.
L’avantage est massif : vous capturez enfin les comportements anonymes, vous reconstituez le parcours complet (de la première visite à l’achat), vous enrichissez vos profils avec des données comportementales précieuses.
Mais le revers de la médaille est réel :
1. Vous restez dans l’inférence statistique
Des erreurs existent toujours :
Faux positifs : vous fusionnez deux personnes différentes (un couple partageant la même IP et les mêmes appareils)
Faux négatifs : vous ne reconnaissez pas la même personne entre deux sessions (changement de réseau, nouvel appareil)
→ Vous ne pouvez pas baser des décisions critiques (paiement, SAV) sur une probabilité de 85%.
2. La complexité technique et les coûts explosent
Il vous faut :
Une infrastructure capable de collecter massivement des données sur tous les canaux
Des capacités de traitement en temps réel sur de gros volumes
Des modèles de machine learning à entraîner, optimiser et maintenir en continu
Une CDP performante ou une plateforme de données custom
→ Budget : plusieurs centaines de milliers d’euros en technologie et compétences.
3. Les défis réglementaires s’accumulent
Consentement RGPD pour le tracking comportemental (plus complexe qu’un simple opt-in email)
Fin des cookies tiers (ITP sur Safari, ETP sur Firefox, Privacy Sandbox sur Chrome)
Obligation de transparence sur les mécanismes d’inférence
→ Vous devez être irréprochable juridiquement, sous peine d’amendes CNIL.
Le verdict : l’approche probabiliste est puissante, mais ne peut pas remplacer le déterministe.
Arrêtons de chercher la solution miracle. La vraie question n’est pas « déterministe OU probabiliste », mais « comment articuler intelligemment les deux ? »
La seule stratégie qui fonctionne : l’approche hybride
Phase 1 : Bâtir le socle déterministe (mois 1-3)
Avant tout, vous devez avoir un système de résolution déterministe solide :
Identifiants maîtres clairement définis (email en priorité, téléphone en backup)
Règles de matching configurées et testées
Processus d’authentification adapté à votre secteur
Gestion des cas limites (changement d’email, comptes multiples)
C’est votre fondation. Tout ce qui suit ne tiendra que si cette base est fiable.
Phase 2 : Ajouter la couche probabiliste (mois 4-9)
Une fois le déterministe maîtrisé, vous pouvez enrichir avec le probabiliste :
Mise en place du tracking cross-device et cross-canal
Implémentation des algorithmes de matching probabiliste
Calibrage des seuils de confiance (à partir de quel score fusionnez-vous ?)
Monitoring continu de la qualité (taux de faux positifs/négatifs)
C’est votre multiplicateur de valeur. Vous capturez maintenant les comportements invisibles.
Phase 3 : Orchestrer la fusion intelligente (en continu)
Le vrai art réside dans la fusion des deux approches :
Exemple de parcours client hybride :
Jour 1 → Un visiteur anonyme navigue sur votre site Tracking probabiliste actif : collecte des signaux
Jour 3 → Le même appareil revient, consulte d’autres produits Le profil probabiliste s’enrichit (produits vus, préférences)
Jour 5 → Le visiteur crée un compte avec son email Résolution déterministe : Golden ID attribué
Fusion automatique → L’historique probabiliste des jours 1-5 est rattaché au profil déterministe créé au jour 5
→ Vous obtenez la vision complète : de la découverte anonyme jusqu’à la conversion identifiée
Les règles d’or pour réussir votre résolution d’identité
1. Séparez clairement les niveaux de confiance
Ne mélangez pas les profils déterministes (certitude > 99%) et probabilistes (confiance 70-90%). Marquez-les explicitement dans votre RCU.
Utilisez le déterministe pour :
Toutes les transactions et opérations sensibles
Les communications officielles (factures, SAV)
Les statistiques officielles (reporting direction)
Utilisez le probabiliste pour :
La personnalisation web et app
L’enrichissement de profils existants
Les analyses exploratoires et segmentations marketing
2. Définissez des seuils de fusion adaptés à vos enjeux
Scoring de confiance :
95-100% : fusion automatique (déterministe)
80-95% : fusion automatique avec traçabilité (probabiliste haute confiance)
60-80% : proposition de fusion pour validation manuelle
< 60% : pas de fusion, simple rapprochement pour enrichissement
Ne cherchez pas la perfection. Préférez 80% de couverture fiable à 100% de couverture douteuse.
3. Investissez dans la gouvernance, pas seulement la technologie
La meilleure technologie du monde échouera sans :
Règles métiers claires : qui arbitre en cas de conflit ? Quelle source est maître ?
Processus de contrôle : revues qualité régulières, correction des erreurs de fusion
Formation des équipes : marketing et service client doivent comprendre les limites de chaque approche
KPIs de pilotage : taux de dédoublonnage, couverture identitaire, taux d’erreur
4. Préparez-vous à l’évolution réglementaire
Le paysage privacy change vite :
Fin des cookies tiers d’ici 2025 (vraiment cette fois ?)
Montée en puissance des solutions first-party (authentification, login universel)
Émergence de standards comme FLoC, Topics API, ou autres alternatives
Votre stratégie de résolution d’identité doit être flexible. Privilégiez les approches first-party et l’authentification volontaire plutôt que le tracking passif.
Ce qu’il faut retenir
La résolution d’identité n’est pas un chantier qu’on termine en trois mois pour passer à autre chose. C’est un sujet qu’il faut piloter dans la durée, ajuster au fil de l’eau, faire évoluer avec vos besoins métiers.
Notre recommandation si vous démarrez :
Commencez par le déterministe. C’est moins spectaculaire que le probabiliste avec du machine learning, mais c’est ce qui va tenir dans le temps. Une fois cette base propre et fiable, vous pourrez envisager d’ajouter une couche probabiliste — mais seulement si vous avez les équipes et le budget pour la maintenir correctement.
Ensuite, définissez des seuils de confiance clairs pour vos fusions automatiques. Mettez en place des règles métiers, des points de contrôle réguliers, et des KPIs qui vous permettent de détecter rapidement les dérives. Et gardez en tête que les règles du jeu vont continuer à évoluer — cookies, RGPD, nouvelles régulations — donc construisez quelque chose de flexible dès le départ.
La vraie question aujourd’hui, ce n’est plus de savoir si vous devez travailler votre résolution d’identité. C’est de comprendre comment vous allez l’implémenter pour qu’elle serve concrètement votre business, pas juste pour cocher une case « RCU » dans votre roadmap IT.
Sans cela, votre Référentiel Client Unique restera une promesse non tenue de plus. Avec cela, vous aurez enfin les moyens de personnaliser véritablement la relation client, sur tous les canaux.
Dans cette période charnière pour notre souveraineté numérique, il nous est apparu important chez Rhapsodies Conseil de mettre en avant les solutions PaaS françaises existantes. Important, car un certain nombre de solutions existent, et sont tout à fait Production Ready pour une majorité de cas d’usage d’entreprises. Mais aussi car on voit émerger des acteurs français. Des acteurs innovants soucieux de leurs clients, qui chérissent leurs indépendances. Et qui par conséquent sont finalement des pierres angulaires de notre souveraineté numérique.
De très bonnes solutions qui sont totalement imperméables aux lois d’espionnage comme la FISA américaine, ne pratiquant pas le Sovereign Washing, et qui par leur existence même permet de garantir une chaîne industrielle de l’IT présente en France. Et qui sont très certainement plus prompte à payer leurs impôts en France au même taux que les autres entreprises françaises.
La souveraineté numérique est sur toutes les lèvres, mais est-elle vraiment dans toutes les stratégies ? Si le dernier baromètre du CRIP souligne une prise de conscience salutaire des organisations, il révèle aussi l’ampleur du chemin qu’il reste à parcourir pour sortir d’une dépendance souvent subie, parfois inconsciente.
Chez Rhapsodies Conseil, nous sommes convaincus que la souveraineté n’est pas un luxe idéologique, mais le socle de votre liberté de décision future. Il ne s’agit plus de cocher des cases réglementaires, mais de reprendre les commandes de nos trajectoires technologiques face à des enjeux qui dépassent le simple cadre du Cloud.
Pour transformer ces indicateurs en un véritable levier de performance, nous avons passé les résultats au crible de nos convictions : voici les six ruptures nécessaires pour passer de la posture à l’autonomie réelle.
1. Vision et priorisation stratégique : sortir du suivisme
Il est impératif de changer de focale technique et réglementaire. Nous avons trop tendance à nous arrêter au Cloud Act, alors que le danger majeur réside dans le FISA-702, bien plus offensif. En effet, la section 702 du FISA impose une juridiction extraterritoriale sur l’ensemble des services et infrastructures numériques (cloud, SaaS, logiciels, télécoms, centres de données, etc..) ayant accès aux communications, permettant aux agences US de transformer les outils technologiques mondiaux en vecteurs de surveillance unilatérale au mépris de la souveraineté des autres États.
Ensuite, le scénario « Kill switch » n’est pas une fiction ; il a été étudié et le véhicule législatif existe.
En effet, en s’appuyant sur l’IEEPA (International Emergency Economic Powers Act) ou sur des contrôles à l’exportation, Washington pourrait contraindre légalement les entreprises américaines à suspendre instantanément l’accès aux services cloud, aux mises à jour logicielles et aux certificats numériques, transformant la dépendance technologique de l’Europe en une arme de paralysie économique massive.
La souveraineté se joue à la source de la stack technique : elle appartient à celui qui produit la technologie et possède le pouvoir d’arrêter l’envoi des mises à jour, et non à celui qui la distribue.
Dans cette optique, suivre aveuglément le Magic Quadrant de Gartner n’est pas une stratégie, c’est du « suivisme », une difficulté à décider pour soi-même ce qui nous est le plus adapté. Payer des cabinets américains qui vont toujours dire de manière biaisée et/ou intéressée d’acheter américain ne peut pas aider à avancer sur la souveraineté. Enfin, nous devons intégrer la notion de durabilité (autonomie énergétique et environnementale) comme un pilier indissociable de notre souveraineté à long terme. Les acteurs de l’IA l’ont bien compris.
2. Gouvernance et organisation : maîtriser ses risques
Une gouvernance souveraine repose sur des actions concrètes :
Mettre en place une veille réglementaire, technologique et géopolitique.
Former les achats, les décideurs métiers et les équipes IT aux enjeux de dépendance.
Réaliser des analyses de risques argumentées qui évaluent la dépendance technologique et économique.
Déterminer précisément les besoins de sécurité et utiliser un indice de souveraineté couvrant l’ensemble des enjeux.
Identifier tous les fournisseurs cloud et logiciels pour maîtriser sa supply chain, tout en restant vigilant face aux enjeux de dépendance contractuelle et réglementaire extra-territoriale.
3. Politique d’achat et Sourcing : briser les mythes
La solution « facile » et rentable à court terme d’un clouder US n’est pas nécessairement optimale à long terme face aux incertitudes réglementaires. Acheter souverain, c’est aussi se donner la capacité de se vendre comme tel. Nous avons en effet chez Rhapsodies Conseil des clients qui font de leur propre souveraineté un argument commercial.
Il faut également cesser de se rassurer avec l’uniformité : avoir la même architecture que tout le monde n’est pas un avantage compétitif, c’est une dépendance généralisée. À l’inverse, choisir un fournisseur européen ou français offre une sécurité juridique supplémentaire quant au cadre applicable. Contrairement aux idées reçues, le surcoût des solutions françaises est souvent un mythe. Voire une erreur contradictoire avec la réalité.
Nous notons également trois points de vigilance sur le sourcing :
L’illusion de l’Open Source en solution générique : Une solution gérée par un éditeur open-source reste soumise aux risques liés à cet éditeur. Il est préférable de supporter financièrement des projets ou de contribuer aux communs numériques européens pour mutualiser l’effort. Un projet américain reste soumissible aux désirs du gouvernement américain. Le projet Linux, sous statut américain, a ainsi rejeté les développeurs russes, suite à la pression américaine.
Le déséquilibre commercial : La relation est structurellement asymétrique face à des hyperscalers gros comme des États, contrairement aux acteurs souverains. Et la capacité de négociation aussi.
La réversibilité : La vraie souveraineté se mesure à la facilité de changer de fournisseur (interopérabilité, frais de sortie et de rupture avantageux).
4. Architecture, Data et Cybersécurité
Il faut marteler que Souveraineté ≠ Localisation : la simple présence des données en Europe ne garantit en rien la souveraineté juridique. L’excellence opérationnelle consiste à choisir l’outil que l’on maîtrise réellement, et non à acheter le leader d’un quadrant pour se rassurer.
Les solutions souveraines sont aujourd’hui qualitatives et optimisées. Si le catalogue des hyperscalers est plus fourni, les besoins réels des clients touchent rarement plus de 30 services, un périmètre parfaitement couvert par les acteurs européens. Pour sécuriser nos actifs, nous devons :
Auditer la Supply Chain au-delà du rang 1 pour détecter les compromissions applicatives.
Inclure systématiquement des solutions souveraines dans les études de projets.
Chiffrer systématiquement les frais de sortie et les dépendances dès la phase d’étude pour garantir une décision équitable.
5. Compétences et Acculturation : le facteur humain
La souveraineté sans compétence interne relève du « wishful thinking ». Nous avons le mauvais réflexe de ne penser au souverain que pour les ressources sensibles. Pour changer de paradigme, il faut intégrer la souveraineté dès les applications simples pour habituer les équipes. Quelle justification à mettre l’application de menu de la cantine chez un HyperScaler?
Le rôle des experts est central : les RSSI alertent, le métier décide, mais c’est l’incident qui tranche. Il est dangereux de voir les clouders comme des standards ; ce sont des technologies propriétaires qui imposent une dépendance technique. Nous perdons nos compétences agnostiques au profit de certifications propriétaires. Il est donc urgent de :
Prévoir des plans de formation agnostiques basés sur l’open source.
Encourager les certifications sur les solutions souveraines.
Rester vigilant face aux ESN dont l’indépendance est limitée par leurs partenariats avec les géants US (rémunérations, crédits cloud, certifications).
6. Feuille de route et Investissements
Le cloud est une infrastructure vitale, au même titre qu’EDF ou Orange. Accepterions-nous un EDF Russe, un Orange Chinois et un ENGIE Américain ?
Travailler avec des acteurs souverains permet de peser sur les feuilles de route produits, contrairement aux hyperscalers où l’on subit les priorités du marché américain. Nous devons aussi transformer les contraintes réglementaires (NIS2, DORA, DMA) en opportunités de souveraineté.
Enfin, soyons lucides sur l’asymétrie entre un accès facile aux clouders US et une sortie complexe et coûteuse (frais de rapatriement abusifs). Une stratégie hybride est possible : réserver les hyperscalers aux POC innovants de courte durée et à faible volumétrie, tout en sécurisant le reste sur des infrastructures souveraines, souvent moins chères pour les services courants.
La souveraineté numérique n’est pas un repli, mais une exigence de lucidité. En rééquilibrant nos investissements vers des compétences agnostiques et des solutions européennes, nous ne faisons pas qu’acheter de la technologie : nous achetons notre liberté de décision future. Le baromètre nous montre le chemin ; il ne tient qu’à nous de transformer ces indicateurs en une véritable trajectoire d’indépendance.
Le Référentiel Client Unique (RCU) : la réponse à la fragmentation de vos données clients
Le Référentiel Client Unique (RCU) : la réponse à la fragmentation de vos données clients
Reconnaître le client instantanément, comprendre ses comportements, personnaliser les interactions et piloter la performance sur l’ensemble du cycle de vie.
51 % des utilisateurs de CRM considèrent que la synchronisation des données est le problème majeur de leur solution actuelle (Stratenet).
Dans un monde où l’expérience client omnicanale est devenue l’avantage concurrentiel majeur, la fragmentation des données clients représente le principal angle mort des directions marketing. Selon une étude Gartner de 2024, 82% des organisations ne peuvent pas calculer avec précision la Customer Lifetime Value (CLV) de leurs clients en raison de données dispersées entre multiples systèmes. Cette fragmentation n’est pas simplement un problème technique : elle compromet fondamentalement la résolution d’identité client, c’est-à-dire la capacité à reconnaître qu’une même personne physique interagit avec la marque sur plusieurs canaux.
Sans la résolution d’identité, impossible de construire une véritable connaissance client. Le profil créé lors d’un achat en ligne reste déconnecté de l’achat en boutique du lendemain. Les préférences déclarées sur l’application mobile ne sont pas exploitées lors d’un échange avec le service client. Le parcours qui débute sur Instagram et se termine en point de vente reste invisible, rendant toute attribution marketing illusoire. Et pourtant, dans un monde où des données sont dispersées dans des systèmes hétérogènes incapables de dialoguer entre eux, les directions marketing, commerciales, relation client, retail et data sont tout de même attendues sur un même terrain : reconnaître le client instantanément, comprendre ses comportements, personnaliser les interactions et piloter la performance sur l’ensemble du cycle de vie.
Les défis et les impacts par direction métier
Marketing
Défis clés
• Attribution multi-touch impossible : les conversions boutique après exposition digitale ne sont jamais créditées aux campagnes online
• Segmentation RFM faussée : une cliente dépensant 1 200€/an apparaît comme deux profils « moyens » à 600€ et ne reçoit jamais les invitations VIP
• Gaspillage direct : emails envoyés en double, catalogues dupliqués, offres inadaptées
Impact chiffré
• 56% des CMO ne peuvent pas mesurer le ROI cross-canal (Gartner 2024)
• 15-20% des clients VIP non identifiés = 2-5M€ de manque à gagner/an pour une enseigne de 500M€ (Forrester)
• 21% du budget marketing gaspillé sur doublons (SiriusDecisions)
Ventes & Retail
Défis clés
• ROPO invisible : 73% des acheteurs en magasin ont recherché en ligne, mais le vendeur démarre à zéro
• Clients omnicanaux non identifiés : impossible de savoir qui achète sur plusieurs canaux
• Click & Collect mal exécuté : recherche manuelle de 8 min, pas d’accès à l’historique, vente additionnelle ratée
Impact chiffré
• Conversion boutique -15 à -25% sans contexte web (McKinsey 2023)
• Panier moyen -20 à -30% quand le vendeur ignore la recherche online
• Taux de vente additionnelle C&C : 35% avec vue 360° vs 12% sans = 23 points perdus (Accenture 2023)
Relation Client
Défis clés
• Répétition frustrante : le client doit répéter son problème à chaque interlocuteur (email, chat, téléphone)
• Incident critique sur 1er achat : traité en routine alors qu’il nécessite priorisation et compensation
• Retour cross-canal impossible : pas de retour web en boutique, retour postal obligatoire
Impact chiffré
• 72% des clients doivent se répéter (Zendesk 2024) • Temps de résolution x2,3 sans vue 360° (Gartner 2024)
• 60-80% des nouveaux clients avec incident mal géré ne rachètent jamais (Bain & Company 2023)
• Taux de récupération : 40% sans RCU vs 75% avec contextualisation (Accenture 2024)
Data
Défis clés
• 70-80% du temps passé à nettoyer au lieu d’analyser : réconciliation manuelle, déduplication, normalisation
• Absence de Golden Record : 3 réponses différentes à « Combien de clients actifs ? »
• Conformité RGPD compromise : plusieurs jours pour traiter un droit à l’oubli au lieu de 30 jours légaux
Impact chiffré
• Décisions sur données inexactes = 1,5% du CA perdu (Gartner 2024)
• Coût traitement demande RGPD : 1 400€ sans RCU vs 150€ avec
Direction Générale
Défis clés
• CLV inaccessible : 82% des organisations ne peuvent pas calculer la vraie valeur client
• Décisions stratégiques sur intuitions : impossible de définir rationnellement les seuils VIP, d’estimer le ROI fidélité
• Angle mort sur clients à haute valeur
Impact chiffré
• 82% ne calculent pas la CLV précisément (Gartner 2024) • Entreprises pilotées par CLV : croissance x2,4 supérieure (Bain & Company 2023)
• Coût total fragmentation : 12-25M€/an pour 500M€
LE RCU : BIEN PLUS QU’UN PROJET TECHNIQUE
Le Référentiel Client Unique (RCU) constitue la « single source of truth » pour l’ensemble des données clients d’une organisation. Contrairement à une approche traditionnelle où les données sont dispersées entre multiples systèmes (CRM, POS, e-commerce, loyalty, marketing automation), le RCU centralise et unifie ces informations autour d’une identité unique par client physique. Cette unification transforme radicalement la connaissance client : là où une entreprise voyait cinq profils déconnectés pour une même personne, elle dispose désormais d’une vue 360° complète et actionnable.
Le RCU repose sur trois piliers fonctionnels interdépendants qui, ensemble, créent un effet de levier sur la performance business.
Premier pilier : unifier les identités clients via un Global ID.
Le RCU attribue un identifiant unique et universel à chaque client physique, quel que soit le canal d’interaction. Ce Global ID devient la clé de voûte permettant de reconstituer l’intégralité du parcours client : la cliente qui s’inscrit à la newsletter sur le site web, visite une boutique le lendemain, télécharge l’application mobile, puis achète en ligne est immédiatement reconnue comme une seule et même personne sur les quatre points de contact. Cette résolution d’identité s’appuie sur des modèles de matching sophistiqués combinant données déterministes (email, téléphone, identifiants externes) et probabilistes (nom, prénom, adresse, comportement d’achat).
Deuxième pilier : garantir la qualité des données par des contrôles systématiques et une déduplication continue.
Le RCU implémente des règles de validation à la création (formats email et téléphone, champs obligatoires, normalisation des adresses) et détecte automatiquement les doublons potentiels via des algorithmes de similarité. Selon l’étude « The State of Customer Data Quality » de Forrester Research publiée en 2023, les entreprises ayant déployé un RCU avec moteur de déduplication actif réduisent leur taux de doublons de 25% (moyenne secteur retail) à moins de 3%, soit une amélioration de 88% de la qualité des données.
Troisième pilier : orchestrer les flux omnicanaux d’acquisition et de propagation des données
Le RCU capture les données clients depuis tous les canaux (flux d’acquisition) et les redistribue automatiquement vers tous les systèmes qui en ont besoin (flux de propagation), en temps réel ou near real-time selon la criticité. Cette orchestration élimine les intégrations point-à-point coûteuses et sources d’erreurs : au lieu de maintenir 15 à 20 connexions bilatérales entre systèmes, l’architecture se simplifie en 5 à 8 intégrations centralisées via le RCU.
Conclusion
Plus fondamentalement, le RCU démocratise la connaissance client à l’échelle de l’organisation. Chaque fonction dispose enfin d’une vue complète, fiable et actualisée : le Marketing peut segmenter avec précision, les Ventes reconnaissent les clients VIP sur tous les canaux, le Service Client accède à l’historique complet, la Data analyse sans passer 80% du temps à nettoyer, la Direction Générale pilote sur des KPIs fiables. Cette connaissance client unifiée devient l’actif stratégique différenciant dans un monde où l’expérience client constitue le principal avantage concurrentiel.