Le site internet est une vitrine de l’entreprise, celui qui vous permet de vous présenter à vos partenaires, candidats, clients, prospects… bref, à tout votre écosystème. Il est donc primordial qu’il donne confiance quant à la gestion des données de vos visiteurs, et qu’il soit conforme à la réglementation en vigueur. Un site conforme au RGPD, transparent sur l’utilisation qu’il fait des données que le visiteur lui fournit, offre une bonne première impression et évite de devoir expliquer à vos clients que vous n’êtes pas conforme RGPD si la CNIL décide d’auditer votre entreprise.
Le RGPD n’est pas l’unique règle qu’il faille appliquer pour considérer son site internet comme absolument conforme (règle EPrivacy, régle de régulation des mentions légales, …). Nous nous sommes principalement focalisés ici sur le RGPD.
Il n’est toutefois pas toujours aisé de démêler concrètement les impacts de la réglementation sur votre site et de savoir s’il est bien en phase avec celle-ci. Chez Rhapsodies Conseil, nous vous avons donc préparé une synthèse des quelques points clefs auxquels vous devez vous intéresser.
1. Les cookies
Première action du visiteur sur le site : le bandeau cookie
Un bandeau cookie, doit répondre à 3 obligations indispensables :
Acceptation, refus, paramétrage
Les boutons accepter tous les cookies et refuser tous les cookies sont obligatoires. L’interface ne doit pas avantager un choix plus qu’un autre, les deux boutons doivent, entre autre, avoir la même taille, la même forme et la même couleur.
Le bouton paramètrage n’a pas l’obligation d’être identique aux deux autres, et doit permettre de choisir quel type de cookie j’accepte et quel type de cookie je refuse.
Lors du paramètrage, lesopt-in doivent obligatoirement être désactivés par défaut. Accepter tel ou tel type de cookie doit résulter d’une action du visiteur.
Chaque type de cookie (Fonctionnel, Performance, Analytique, …) doit être décrit afin d’éclairer le visiteur dans son choix. Chaque choix doit se faire par finalité, c’est-à-dire que le visiteur peut refuser les cookies de Performance et de Publicité et accepter tous les autres sans que son parcours sur le site ne soit différent.
Tant que le visiteur n’a pas donné son accord explicite de dépôt de cookies (autre qu’obligatoire), aucun cookie ne doit être déposé.
L’utilisateur doit pouvoir revenir sur son choix dès qu’il le souhaite, il doit donc y avoir un moyen pour le visiteur de revenir sur le paramétrage des cookies afin de refuser/accepter les cookies.
Le bon fonctionnement du paramétrage des cookies & preuve de consentement
Il arrive souvent que, bien que le bandeau cookie permette de refuser le dépôt de certains cookies, celui-ci ne soit pas totalement fonctionnel. Il est donc primordial de vérifier régulièrement que l’outil de paramétrage est bien opérationnel.
Enfin, il est indispensable de pouvoir conserver la preuve du consentement (article 7 du RGPD).
Lien vers la charte des données ou charte des cookies
Le visiteur doit pouvoir accéder à la politique d’utilisation des cookies, rapidement et avant de faire son choix. Un lien vers la politique d’utilisation des cookies doit donc être présent sur le bandeau.
Cette Politique des cookies doit comprendre : une description de ce qu’est un cookie, une description de comment supprimer les cookies par navigateur, la finalité et la durée de conservation des cookies, le type de cookies et préciser (dans le cas d’un cookie tiers) le tiers en question et le lien vers sa propre politique de confidentialité ou de cookies. Contrairement aux idées reçues, la liste exhaustive des cookies n’est pas obligatoire.
ATTENTION : les cookies collectent des données personnelles, ils ne peuvent donc pas être transférés vers des pays où la réglementation sur la protection des données personnelles n’est pas conforme au RGPD. Les Etats-Unis, par exemple, ne donnent pas une protection sur les données personnelles suffisante pour que les données y soient envoyées. L’utilisation des Cookies Google Analytics (_ga, _gat, …) n’est donc pas acceptée.
2. Les mentions d’informations et la charte des données personnelles
Les mentions d’informations sont les petits textes se trouvant sous les « points de collecte de données » (Newsletter, point de contact, inscription, …). Afin de pouvoir faciliter la compréhension, j’aime décrire les mentions d’informations comme une « charte des données personnelles spécifique au point de collecte »
Une mention d’information doit notamment contenir certaines informations que sont :
Un rappel des données personnelles qui sont collectées suivi par l’utilisation qui en est faite ;
Un lien vers la charte des données personnelles ;
La base légale sur lequel s’appuie le traitement ;
Le destinataire des données (préciser si un transfert des données hors de l’UE est effectué) ;
La durée de conservation des données (non-obligatoire si celles-ci sont présentes dans la charte des données personnelles) ;
Le rappel des droits ;
Le point de contact (DPO).
Toutes les informations peuvent se trouver dans un texte sous le point de collecte, il est possible de créer une page spécifique à la mention d’information accessible via un lien (cf. exemple ci-dessus). L’important est de respecter le principe de transparence qui implique que les informations soient présentées d’une forme claire. Il est conseillé que cela soit ludique et adapté aux interlocuteurs concernés.
La charte des données personnelles quant à elle est indispensable dès qu’une donnée personnelle est collectée sur le site. Cette charte doit comprendre les informations suivantes :
Le nom du responsable de traitement ;
Les finalités de traitement ;
Les bases légales sur lesquelles reposent les traitements (si un traitement repose sur le consentement, il faut préciser que celui-ci peut être retiré) ;
Les destinataires des données (avec précision si les données sont transférées hors de l’UE et les garantis quant au respect des règles de sécurités imposées par le RGPD (anonymisation, pseudonymisation, …)) ;
La durée de conservation des données personnelles ;
Le rappel des droits des personnes (accès, limitation, suppression, opposition, rectification et portabilité) ;
Le contact pour faire valoir ses droits (DPO) ;
Le droit de déposer une réclamation auprès de la CNIL ;
L’existence (ou non) d’une prise de décision automatisée ;
La source des données s’il existe une collecte indirecte.
La charte doit être mise à jour dès qu’un nouveau traitement est créé.
Il est possible que vous n’ayez pas besoin de créer de charte des données personnelles. C’est le cas si les mentions d’informations de tous les points de collecte de votre site internet contiennent des mentions d’informations spécifiques et complètes comprenant les informations obligatoires. Si vous répondez à ce cas de figure, il vous faudra cependant une charte des cookies.
3. CGU, CGV, mentions légales
Les CGU ne sont pas obligatoires mais apportent un cadre d’utilisation du site internet (droits et obligations respectives à l’éditeur et au visiteur). Si votre site internet n’est qu’une vitrine et qu’il ne permet pas la création d’un compte, un achat, le dépôt d’un commentaire, … il n’est pas obligatoire d’avoir des CGU.
Cependant, celles-ci sont indispensables dans les cas contraires. En effet, les CGU peuvent être considérées comme le “règlement intérieur du site”. Elles donnent les droits de l’utilisateur, ses responsabilités et également celles en cas de non-respect.
Les droits de l’utilisateur doivent être précisés, par exemple dans le cas de la création d’un espace personnel. Ces dispositions des conditions générales d’utilisation permettent d’engager la responsabilité de l’utilisateur en cas de dommage résultant du non-respect desdites obligations.
Francenum.gouv.fr
L’utilisateur du site doit accepter explicitement les CGU pour qu’elles puissent être considérées comme légales.
Contrairement aux CGU, les CGV sont obligatoires dès que le site propose un service de paiement, vente, livraison en ligne. Les CGV correspondent à la politique commerciale du site internet (modalité de paiement, délais de livraison, rétractation, …). Elles sont particulièrement utiles en cas de contentieux. Cependant, il n’est pas obligatoire de les avoir disponibles directement sur votre site internet, si vos clients sont professionnels (B2B). Elles le sont si vos clients sont des particuliers (obligation précontractuelle d’information du vendeur). Pour chaque vente, les CGV doivent être acceptées par le particulier (B2C).
Les mentions légales sont les informations permettant d’identifier facilement les responsables du site. Pour une personne physique, il faut inclure :
Le nom et le prénom ;
L’adresse du domicile ;
Le numéros de téléphone et l’adresse mail.
Pour une personne morale (une société), il faut inclure :
Le nom de l’entreprise et le numéro SIRET ;
La forme juridique de la société ;
Le montant de son capital social ;
L’adresse du siège social.
Il est aussi impératif de préciser les mentions relatives à la propriété intellectuelle :
La propriété intellectuelle des photos, images, illustrations, textes qui ne sont pas les vôtre (à minima la source des tactes).
En complément de ces informations, il est indispensable d’inclure :
Le nom de l’hébergeur et sa raison sociale ;
L’adresse de l’hébergeur ;
Le numéros de SIRET de l’hébergeur ;
Le numéro de téléphone de l’hébergeur.
Certaines activités impliquent d’ajouter certaines informations :
le numéro d’inscription au registre du commerce et des sociétés (RCS) (et numéro de TVA intercommunautaire, si vous en avez un) ;
le numéro d’immatriculation au répertoire des métiers (RM) ;
le nom du directeur/codirecteur ou responsable de la publication (si vous proposez des articles, des blogs, des informations, …) ;
le nom et l’adresse de l’autorité vous ayant délivré l’autorisation d’exercer (si votre activité est soumise à un régime d’autorisation).
4. Le principe de minimisation
Très souvent, on a tendance à vouloir collecter le plus de données possibles « au cas où », sans finalité précise. Cependant, depuis le RGPD, le principe de minimisation limite cette tendance.
Le principe de minimisation prévoit que les données à caractère personnel doivent être adéquates, pertinentes et limitées à ce qui est nécessaire au regard des finalités pour lesquelles elles sont traitées.
CNIL
Ainsi, il n’est plus possible de collecter des données ne pouvant pas être justifiées par la finalité de traitement. Par exemple, demander le genre de la personne pour une inscription à une Newsletter n’est pas possible, sauf si on le justifie (par ex. le contenu de la Newsletter est différent selon que l’on est un homme ou une femme).
Ces quelques points vous donnent une première approche à avoir pour vérifier que votre site est bien conforme. La revue du site est aussi un bon moyen de faire une passe sur les données collectées et lancer une véritable mise en conformité de vos traitements de données (bases de données, contrats, CRM, …).
Chez Rhapsodies Conseil, nous nous appuyons sur des outils internes et externes qui ont fait leurs preuves et sur l’expertise de consultants expérimentés pour analyser la conformité de vos sites internet.
Il y a encore aujourd’hui de nombreuses entreprises qui ne misent pas encore sur les API et qui se demandent encore comment faire. Elles se retrouvent souvent bloquées par le grand nombre de questions qui se posent à elles, ne sachant pas comment aborder ce genre de projets. Elles se retrouvent rapidement bloquées. C’est pourquoi je préconise une démarche MVP.
L’approche MVP pour un projet d’API Management
Parler d’approche MVP pour d’aussi gros projets peut surprendre. En effet, les points à soulever sont nombreux, que l’on parle de sécurité, des solutions techniques, de l’organisation, de la roadmap API ou encore de la définition de bonnes pratiques.
Mais les avantages d’une démarche MVP pour un projet d’API Management sont nombreux :
Démontrer la valeur :
En mettant en place la première API en mode MVP, il est possible de communiquer plus rapidement aux métiers ce que l’on peut désormais faire grâce aux API.
Démontrer la faisabilité :
Dans le cas de systèmes Legacy complexes, encore plus s’ils sont cloisonnés, les raisons sont nombreuses de penser qu’il sera long et compliqué de mettre en place des API. Grâce à l’existence de nombreux modèles d’architecture d’intégration (comme le CQRS), il est plus facile qu’on ne le pense de faire sauter les verrous !
Obtenir des retours d’expérience :
Plutôt que les audits SI et autres audits de maturité, qui sont longs et pas toujours pertinents, rien de tel que des REX réguliers pour faire avancer un projet d’API Management.
Prioriser les initiatives :
Grâce aux premiers retours d’expérience, il est possible de savoir quelle initiative prioriser. La gouvernance doit-elle être étudiée ? La stratégie d’intégration ? La communication interne ?
Réduire les risques :
La démarche MVP permet d’adopter une approche totalement intégrée, avec des décisions de type Go/NoGo à chaque étape. Vous courrez donc un risque réduit à sa portion la plus congrue.
Cette approche MVP peut rapidement aboutir à une première API en un mois, certes imparfaite, mais utilisable. Est-ce qu’il y aura encore des questionnements après un mois ? La réponse est évidente : c’est oui ! Et vous serez même en mesure de classer ces questionnements par ordre de priorité !
Approche MVP et grandes étapes
Une approche MVP étalée sur quatre semaines est clairement réalisable, pour peu qu’on suive les grandes étapes suivantes :
Définition du périmètre (première semaine) :
Choix d’une API candidate :
Vous allez d’abord choisir une première API en fonction de sa facilité à être instanciée et de la valeur qu’elle apportera. Visez le gain rapide !
Lister les attendus :
Plusieurs contraintes techniques, fonctionnelles et autres sont susceptibles d’être émises par les parties prenantes, qu’ils soient métier ou IT. Collectez-les !
Visioning (deuxième semaine) :
Définition de l’architecture :
Vous devez ensuite définir l’architecture cible de votre gestionnaire d’API. Une solution sur site ? dans le nuage ? L’important est de le faire rapidement. Ce n’est pas compliqué de changer le gestionnaire d’API, vous aurez le temps de le changer plus tard. Visez vite et pas cher ! Et n’oubliez pas les sujets d’authentification.
Définition de l’API :
Il vous faut ensuite définir l’API. Un travail à faire de concert avec les métiers, les développeurs et les architectes.
Validation :
Partagez enfin votre API et votre architecture avec tout le monde, pour la valider.
Construction (troisième semaine) :
Installation des composants :
Il est donc temps d’installer votre gestionnaire d’API ! N’oubliez pas, dans le cas de solution cloud, de vérifier s’il n’y a pas de contraintes de sécurité à gérer !
Développements :
Rien n’est plus simple que d’instancier une API, avec son interface. Et n’oubliez pas les sujets d’authentification (bis repetita).
L’intégration et les tests avec les systèmes consommateurs :
Bien sûr vous devez tester. Avec toutes les parties prenantes disponibles, idéalement en même temps…
Rétrospective (quatrième semaine) :
REX technique et métier :
Faites des démonstrations de votre API, avec présentation de la plateforme d’API Management. Ce faisant, vous obtiendrez des retours techniques et métiers.
Initiatives à venir à prioriser :
C’est le bon moment pour lister les prochaines initiatives. Comme les retours d’expérience viennent d’être faits, il n’est pas question de tout arrêter. Continuez !
En respectant ces étapes, vous serez en mesure de poursuivre votre programme API grâce au travail des initiatives priorisées, mais surtout, de pouvoir continuer sur votre lancée ! Et n’oubliez pas que les projets d’API Management nécessitent beaucoup de communication et d’évangélisation !
Après la multicanalité* et la cross-canalité*, l’omnicanalité* s’est imposée comme le principe de référence de l’expérience client ces dernières années. L’accélération de la digitalisation et de l’évolution des usages n’a fait qu’amplifier l’importance de cette tendance.
L’omnicanalité est ainsi devenue un enjeu majeur pour les acteurs de l’expérience client.
Pour quelle raison ce concept s’est imposé ? Que se cache-t-il derrière cette notion d’omnicanalité ? Est-ce une utopie ou un idéal atteignable ?
L’omnicanalité s’est imposée suite à une prise de conscience simple : un client satisfait de son expérience avec une entreprise, aura plus tendance à rester fidèle à cette entreprise. En outre, la fidélisation est beaucoup moins coûteuse que l’acquisition de nouveaux clients. Il devient donc essentiel de répondre au plus près aux attentes des clients sur l’ensemble de ses interactions avec l’entreprise.
L’omnicanalité place le client et les points de contact au centre de la stratégie de relation client. Elle consiste à offrir une expérience client optimale, qui met en œuvre plusieurs canaux fonctionnant en synergie. Elle permet de déployer des parcours fluides et sans couture, répondant aux attentes du client.
Et concrètement, comment mettre cela en musique ?
Nous vous donnons les facteurs clés de succès pour faire de l’omnicanalité une réalité dans votre entreprise.
1. Travailler sur la connaissance client et clarifier vos ambitions sur chaque profil
Les éléments permettant de mieux connaître le client sont multiples : analyse des données client récoltées, enquêtes de satisfaction, recueil d’insights, d’informations ou construction de persona. Ils permettent d’enrichir la connaissance client et de construire la vision client 360. Cette vision unifiée doit être partagée avec l’ensemble des collaborateurs de l’entreprise. Différents profils peuvent être identifiés, parce qu’ils sont adressés différemment. Les ambitions en termes d’expérience doivent être clarifiées pour chaque profil par les directions marketing et expérience client. Ces ambitions répondent aux besoins de chaque profil (exemple : autonomie vs disponibilité).
2. Définir les parcours cibles à partir de votre client et non du canal à déployer
Un parcours cible correspond à la combinaison optimale : profil client / cas d’usage / canal / expérience client. Les travaux sur ces combinaisons ont vocation à aligner les parcours sur les ambitions définies pour chaque profil de client. Il s’agit d’aller là où le client se trouve. Une attention particulière doit être apportée aux points d’interaction entre le client et l’entreprise. Les parcours doivent être simples, intuitifs et doivent nécessiter un minimum d’effort pour le client. Les touch points deviennent ainsi des vecteurs fondamentaux de la promesse de marque de l’entreprise.
3. D’une organisation en silo vers une organisation unifiée et Customer Centric
Les directions Expérience Client ont émergé ces dernières années pour répondre aux enjeux de l’omnicanalité. Terminée la concurrence entre les canaux, l’expérience client doit être traitée dans sa globalité, sur l’ensemble des canaux. Pour exceller dans l’expérience client et l’omnicanalité, la culture Client doit infuser dans l’entreprise : satisfaire le client, notamment en supprimant les points de douleur (ou “pain points”), devient l’objectif prioritaire de l’entreprise. L’entreprise évolue ainsi pour prendre en compte ses attentes de manière continue. Cette évolution s’accompagne souvent d’une restructuration des modes de fonctionnement pour permettre le ruissellement des retours client dans l’entreprise. Il ne s’agit pas d’impliquer uniquement les collaborateurs en interface avec le client, mais d’impliquer tout un écosystème qui contribue de près ou de loin à optimiser l’expérience client. Une entreprise Customer Centric place le client au centre de ses enjeux et se différencie de ses concurrents en orientant ses décisions en regard des attentes des clients. Elle crée de la valeur en rendant le client fidèle et promoteur de la marque.
4. Se doter des bons outils pour répondre à vos enjeux sur l’ensemble des leviers de la relation client
CRM ventes / service client, marketing automation, plateformes conversationnelles, gestion des réseaux sociaux, gestion des sites internet, chatbot, etc : les outils permettant de mettre en place des parcours omnicanaux sont multiples. Ils adressent tout le cycle de vie du client : acquisition, fidélisation, rétention et reconquête. A ces outils s’ajoutent ceux qui permettent de gérer et structurer en amont les données client : Référentiel Client, Customer Data Platform, Data Quality Management, Référentiel des consentements, etc.
Avant de décider de la mise en place d’un outil orienté Client, il est nécessaire d’avoir une vision claire sur les ambitions et les objectifs fixés. L’élaboration d’une stratégie Client claire simplifie le choix des outils et plus généralement de l’architecture à mettre en place. Ce choix nécessite une bonne connaissance de ces outils et de leurs finalités. Tous les leviers de la relation client et les outils associés concourent à la mise en place de l’omnicanalité !
5. Tester et mesurer pour s’améliorer en continue et maintenir une veille
Il n’existe pas un modèle unique d’omnicanalité. De ce fait, une démarche pas à pas est à privilégier pour réussir son projet d’évolution vers l’omnicanalité. Un déploiement progressif permet de s’assurer de la pertinence des choix faits en amont. Réaliser des tests est également nécessaire pour s’assurer de la bonne direction des évolutions. Plus spécifiquement, la technique d’A/B testing est intéressante pour évaluer différentes variantes et choisir la meilleure. Ces expérimentations ne doivent pas être limitées aux canaux digitaux. Il est également possible de tester de nouvelles approches sur les canaux “traditionnels”. Pour cela faites preuve de créativité et d’innovation !
Il est enfin indispensable d’opérer une veille pour rester aligné sur les attentes des clients, voire les anticiper. De nouveaux usages émergent régulièrement, notamment grâce à de nouvelles technologies. Les nouvelles tendances s’accélèrent et il est important de rapidement prendre le train en marche pour s’adapter aux nouvelles pratiques. Analyser et s’inspirer de ce que font les champions de l’expérience client, quel que soit le secteur d’activité, est aussi nécessaire pour s’améliorer en continue et exceller à son tour.
A ces cinq facteurs clés de succès, s’ajoute bien entendu l’aspect architecture de vos systèmes qui doit permettre la mise en œuvre de l’omnicanalité. Pour en savoir plus sur le sujet, nous vous invitons à consulter l’expertise Architectures innovantes proposée par Rhapsodies Conseil.
Pour concrétiser votre projet et en savoir plus sur chacune de ces clés de réussite, nos experts de la Transformation Digitale et de l’Expérience Client vous accompagnent sur une démarche bout en bout, de la stratégie à la mise en œuvre. Contactez-nous !
*Multicanalité : variété des canaux de contact, indépendants les uns des autres. *Cross-canalité : variété des canaux de contacts, parfois complémentaires les uns des autres. *Omnicanalité : synergie entre les canaux de contact, au service d’une expérience client optimale.
J’ai analysé Pro Santé Connect, un service fort intéressant avec plein de potentiels, réalisé dans les règles de l’art et qui suit les standards actuels du domaine de l’authentification. Mon retour : j’adore ! (oui bon laissez-moi mes kiffes hein…).
Pro Santé Connect, c’est quoi ?
Il s’agit d’un service d’authentification et d’identification des professionnels de santé.
Ce service est construit sur les bases des standards du marché actuel : OAUTH2 pour l’authentification et, cerise sur le gâteau, de l’OpenID Connect pour avoir le complément d’information d’identification qui va bien : que pouvons-nous demander de plus ?
À quoi sert Pro Santé Connect ?
Ce service permet qu’un organisme d’état certifie :
La personne qui est en train de s’authentifier est bien celle qu’elle dit être, avec des preuves à l’appui ;
La personne qui accède à mon site dispose bien de certaines caractéristiques qui ne viennent pas d’une auto-déclaration mais d’informations recensées et vérifiées au niveau des organismes d’État ;
Ces informations sont transmises de façon sécurisée et non corruptibles (jetons JWT signés).
Pour être clair, il fonctionne un peu comme France Connect, mais son caractère médical, associé aux caractéristiques spécifiques de la profession, sécurisé et complété par l’OiDC, ouvre la possibilité d’exploiter beaucoup plus d’informations : quel est son lieu de travail ? dans quel établissement ? quelle spécialisation médicale le professionnel pratique ? et d’autres encore…
Pour finir, ces informations peuvent être propagées à des applications tierces, avec un simple transfert de jeton sécurisé, ce qui permet d’éviter les surcoûts et les efforts d’authentification à plusieurs niveaux.
Et alors, on en pense quoi de ce service d’authentification ?
J’adore. Je n’aurais pas fait mieux, ni pire… Techniquement ça a l’air de tenir la route et même plus.
L’utilisation de standards reconnus et plébiscités par le marché, alors que personnellement j’en ai ch…, pardon bavé… Veuillez m’excuser, j’ai eu un peu de mal dans le passé avec des standards d’interconnexion mal documentés, incompréhensibles… Ils étaient pondus par des organismes publics qui, dans un souci de sécurisation, avaient rédigé des documents illisibles et impossibles à utiliser. Bref, je pense qu’ils n’ont jamais rencontré de problèmes de sécurité, vu que personne n’a dû réussir à les implémenter…
Dans le cas de Pro Santé Connect, ceux qui ont déjà implémenté de l’OAUTH2 ou de l’OiDC, se retrouvent dans un cadre familier, clair, bien documenté, enfin un vrai plaisir (bon au moins de mon point de vue hein… laissez moi ce plaisir…). Pour les autres, ces standards sont tellement bien documentés que, avec un peu d’effort de lecture, on peut vite en comprendre les concepts.
Des informations certifiées, complètes, simples à lire ? Il est où le pépin ?
C’est beau tout ça, magnifique, dans ce monde parfait nous n’avons plus rien à craindre ! Plus de questions à se poser ! Nah…
Bon ce n’est pas forcément le cas, une alerte reste d’actualité et se base sur un concept cher à pas mal de DSI : la qualité des données traitées et leur fraîcheur.
Si le service a une chance de marcher tel qu’il est présenté, la collecte des informations devra se faire :
Dans des délais très courts, à partir du changement de situation du professionnel de santé ;
Avec une qualité irréprochable.
Or, la fusion de plusieurs référentiels dans un seul (le RPPS), en cours, plus l’effort que l’ANS semble mettre dans cette initiative, laissent présager des bons résultats.
En conclusion
La voie est la bonne, techniquement pas de surprise, une implémentation reconnue et éprouvée, un service qui nous plaît !
Et maintenant nous attendons le même service pour les personnes physiques, en lien avec Mon Espace Santé et les domaines associés !
Le 23 juin 2022, l’équipe Architecture a animé un événement dédié aux fondations digitales et data. C’était l’occasion de partager avec les participants les témoignages exceptionnels de Catherine Gapaillard (Groupama) et de Yannick Brahy (STIME – DSI du Groupement Les Mousquetaires).
Retour sur notre petit déjeuner événement
Nos intervenants ont pris le temps de partager leur contexte, leur expérience, les spécificités de leurs directions , ainsi que les leviers : organisation, gouvernance et outils mis en place pour soutenir leurs systèmes d’information
3 Temps forts ont rythmé cette matinée:
Comment Groupama se met en route vers une Entreprise Data Driven avec les socles data référentiels et data hub qui supportent la construction de leur domaine data par Catherine Gapaillard, Responsable de la division Urbanisme et Architecture.
Le partage de la Stime – DSI du groupement Les Mousquetaires, de la mise en place d’une stratégie de Data Intégration grâce à son Hybrid Integration Platform (HIP) par Yannick Brahy, Directeur de l’Architecture et de l’Urbanisme.
Les architectures de référence, qui associées à des principes directeurs de constructions du SI permettent de structurer des fondations digitales / data et définir une vision cible du SI et les trajectoires de transformation associées, par Damien Blandin, Directeur Associé de Rhapsodies Conseil
Téléchargez notre livre blanc Architecture SI – Nos modèles de référence
Revivez l’évènement en photo :
A propos de Rhapsodies Conseil
Créé en 2006, Rhapsodies Conseil est un cabinet indépendant de conseil en management. Sa vocation : accompagner les programmes de transformation de ses clients, depuis le cadrage jusqu’à leur mise en œuvre opérationnelle, sur 4 grands domaines d’expertise : Architecture & Transformation Data/ Digitale, Sourcing & Performance de la DSI, Paiements & Cash Management et enfin Agilité, Projets & Produits. Fort d’une centaine de consultants et d’une longue expérience de la transformation des processus et du SI, Rhapsodies Conseil intervient auprès des Grands Comptes et ETI de secteurs d’activité variés (Banque, Assurance, Services, Industrie, Luxe, e-commerce,…). Expertise, Indépendance, Engagement, Agilité, Partage, Innovation et Responsabilité sont les valeurs fondatrices du cainet et guident l’action de ses consultants au quotidien.
Dans un récent post de blog, le Gartner prévoit que d’ici 2030, 60% des données d’entrainement des modèles d’apprentissage seront générées artificiellement. Souvent considérées comme substituts de qualité moindre et uniquement utiles dans des contextes réglementaires forts ou en cas de volumétrie réduite ou déséquilibrée des datasets, les données synthétiques ont aujourd’hui un rôle fort à jouer dans les systèmes d’IA.
Nous dresserons donc dans cet article un portrait des données synthétiques, les différents usages gravitant autour de leur utilisation, leur histoire, les méthodologies et technologies de génération ainsi qu’un rapide overview des acteurs du marché.
Les données synthétiques, outil de performance et de confidentialité des modèles de machine learning
Vous avez dit données synthétiques ?
Le travail sur les données d’entrainement lors du développement d’un modèle de Machine Learning est une étape d’amélioration de ses performances parfois négligée, au profit d’un fine-tuning itératif et laborieux des hyperparamètres. Volumétrie trop faible, déséquilibre des classes, échantillons biaisés, sous-représentativité ou encore mauvaise qualité sont tout autant de problématiques à adresser. Cette attention portée aux données comme unique outil d’amélioration des performances a d’ailleurs été mis à l’honneur dans une récente compétition organisée par Andrew Ng, la Data-centric AI competition.
Également, le renforcement des différentes réglementations sur les données personnelles et la prise de conscience des particuliers sur la valeur de leurs données et la nécessité de les protéger imposent aujourd’hui aux entreprises de faire évoluer leurs pratiques analytiques. Fini « l’open bar » et les partages et transferts bruts, il est aujourd’hui indispensable de mettre en place des protections de l’asset données personnelles.
C’est ainsi qu’entre en jeu un outil bien pratique quand il s’agit d’adresser de front ces deux contraintes : les données synthétiques.
Par opposition aux données « traditionnelles » générées par des événements concrets et retranscrivant le fonctionnement de systèmes de la vie réelle, elles sont générées artificiellement par des algorithmes qui ingèrent des données réelles, s’entraînent sur les modèles de comportement, puis produisent des données entièrement artificielles qui conservent les caractéristiques statistiques de l’ensemble de données d’origine.
D’un point de vue utilisabilité data on peut alors adresser des situations où :
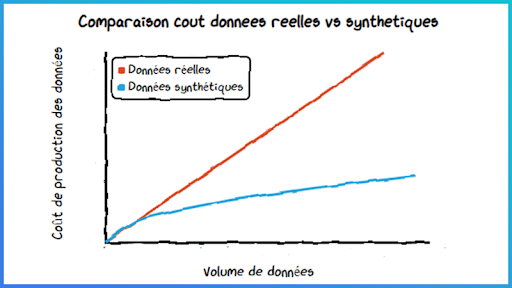
La donnée est coûteuse à collecter ou à produire – certains usages nécessitent par exemple l’acquisition de jeux de données auprès de data brokers. Ici, la génération et l’utilisation de données synthétiques permettent de diminuer les coûts d’acquisition et favorisent ainsi une économie d’échelle pour l’usage data considéré.
Le volume de données existant n’est pas suffisant pour l’application souhaitée – on peut citer les cas d’usage de détection de fraude ou de classification d’imagerie médicale, où les situations « d’anomalie » sont souvent bien moins représentées dans les jeux d’apprentissage. Dans certains cas, la donnée n’existe simplement pas et le phénomène que l’on souhaite modéliser n’est pas présent dans les datasets collectés. Dans ce cas d’usage, la génération de données synthétiques est toutefois à différencier des méthodes de « data augmentation », technique consistant à altérer une donnée existante pour en créer une nouvelle. Dans le cas d’une base d’images par exemple, ce processus d’augmentation pourra passer par des rotations, des colorisations, l’ajout de bruits… l’objectif étant d’aboutir à différentes versions de l’image de départ.
Il n’est pas nécessaire d’utiliser des données réelles, comme lors du développement d’un pipeline d’alimentation en données. Dans ces situations, un dataset synthétique peut être largement suffisant pour pouvoir itérer rapidement sur la mise en place de l’usage, sans se préoccuper de l’alimentation en données réelles en amont.
Mais comme vu précédemment, ces données synthétiques permettent aussi d’adresser certaines problématiques de confidentialité des données personnelles. En raison de leur nature synthétique, elles ne sont pas régies par les mêmes réglementations puisque non représentatives d’individus réels. Les data scientists peuvent donc utiliser en toute confiance ces données synthétiques pour leurs analyses et modélisations, sachant qu’elles se comporteront de la même manière que les données réelles. Cela protège simultanément la confidentialité des clients et atténue les risques (sécuritaires, concurrentiels, …) pour les entreprises qui en tirent parti, tout en levant les barrières de conformité imposées par le RGPD…
Parmi les bénéfices réglementaires de cette pratique :
Les cyber-attaques par techniques de ré-identification sont, par essence, inefficaces sur des jeux de données synthétiques, à la différence de datasets anonymisés : les données synthétiques n’étant pas issues du monde réel, le risque de ré-identification est ainsi nul.
La réglementation limite la durée pendant laquelle une entreprise peut conserver des données personnelles, ce qui peut rendre difficile la réalisation d’analyses à plus long terme, comme lorsqu’il s’agit de détecter une saisonnalité sur plusieurs années. Ici, les données synthétiques s’avèrent pratiques puisque non identifiantes : les entreprises ont ainsi le droit de conserver leurs données synthétiques aussi longtemps qu’elles le souhaitent. Ces données pourront être réutilisées à tout moment dans le futur pour effectuer de nouvelles analyses qui n’étaient pas menées auparavant ou même technologiquement irréalisables au moment de la collecte des données.
L’utilisation de services tiers (ex : ressources de stockage / calcul dans le cloud) nécessitent la transmission de données (parfois personnelles et sensibles) vers ce service. Il en va de même pour le partage de données avec des tiers pour réalisation d’analyses externes. En plus du casse-tête habituel de la conformité, cela peut (et devrait) être une préoccupation importante pour les entreprises, car une faille de sécurité peut rendre vulnérables à la fois leurs clients et leur réputation. Dans ce cas, utiliser des données synthétiques permet de réduire les risques liés aux transferts de données (vers des tiers, des fournisseurs de cloud, des prestataires ou encore des entités hors UE pour les entreprises européennes).
Un peu d’histoire…
L’idée de mettre en place des techniques de préservation de la confidentialité des données via les données synthétiques date d’une trentaine d’années, période à laquelle le US Census Bureau (organisme de recensement américain) décida de partager plus largement les données collectées dans le cadre de son activité. A l’époque, Donald B. Rubin, professeur de statistiques à Harvard, aide le gouvernement américain à régler des problèmes tels que le sous-dénombrement, en particulier des pauvres, dans un recensement, lorsqu’il a eu une idée, décrite dans un article de 1993 .
« J’ai utilisé le terme ‘données synthétiques’ dans cet article en référence à plusieurs ensembles de données simulées. Chacun semble avoir pu être créé par le même processus qui a créé l’ensemble de données réel, mais aucun des ensembles de données ne révèle de données réelles – cela présente un énorme avantage lors de l’étude d’ensembles de données personnels et confidentiels. »
Les données synthétiques sont nées.
Par la suite, on retrouvera des données synthétiques dans le concours ImageNet de 2012 et, en 2018, elles font l’objet d’un défi d’innovation lancé par le National Institute of Standards and Technology des États-Unis sur la thématique des techniques de confidentialité. En 2019, Deloitte et l’équipe du Forum économique mondial ont publié une étude soulignant le potentiel des technologies améliorant la confidentialité, y compris les données synthétiques, dans l’avenir des services financiers. Depuis, ces données artificielles ont infiltré le monde professionnel et servent aujourd’hui des usages analytiques multiples.
Méthodologies de génération de données synthétiques
Pour un dataset réel donné, on peut distinguer 3 types d’approche quant à la génération et l’utilisation de données synthétiques :
Données entièrement synthétiques – Ces données sont purement synthétiques et ne contiennent rien des données d’origine.
Données partiellement synthétiques – Ces données remplacent uniquement les valeurs de certaines caractéristiques sensibles sélectionnées par les valeurs synthétiques. Les valeurs réelles, dans ce cas, ne sont remplacées que si elles comportent un risque élevé de divulgation. Ceci est fait pour préserver la confidentialité des données nouvellement générées. Il est également possible d’utiliser des données synthétiques pour adresser les valeurs manquantes de certaines lignes pour une colonne donnée, soit par méthode déterministe (exemple : compléter un âge manquant avec la moyenne des âges du dataset) ou statistique (exemple : entraîner un modèle qui déterminerait l’âge de la personne en fonction d’autres données – niveau d’emploi, statut marital, …).
Données synthétiques hybrides – Ces données sont générées à l’aide de données réelles et synthétiques. Pour chaque enregistrement aléatoire de données réelles, un enregistrement proche dans les données synthétiques est choisi, puis les deux sont combinés pour former des données hybrides. Il est prisé pour fournir une bonne préservation de la vie privée avec une grande utilité par rapport aux deux autres, mais avec un inconvénient de plus de mémoire et de temps de traitement.
GAN ?
Certaines des solutions de génération de données synthétiques utilisent des réseaux de neurones dits « GAN » pour « Generative Adversarial Networks » (ou Réseaux Antagonistes Génératifs).
Vous connaissez le jeu du menteur ? Cette technologie combine deux joueurs, les « antagonistes » : un générateur (le menteur) et un discriminant (le « devineur »). Ils interagissent selon la dynamique suivante :
Le générateur ment : il essaie de créer une observation de dataset censée ressembler à une observation du dataset réel, qui peut être une image, du texte ou simplement des données tabulaires.
Le discriminateur – devineur essaie de distinguer l’observation générée de l’observation réelle.
Le menteur marque un point si le devineur n’est pas capable de faire la distinction entre le contenu réel et généré. Le devineur marque un point s’il détecte le mensonge.
Plus le jeu avance, plus le menteur devient performant et marquera de points. Ces « points » gagnés se retrouveront modélisés sous la forme de poids dans un réseau de neurones génératif.
L’objectif final est que le générateur soit capable de produire des données qui semblent si proches des données réelles que le discriminateur ne puisse plus éviter la tromperie.
Pour une lecture plus approfondie sur le sujet des GANs, il en existe une excellente et détaillée dans un article du blog Google Developers.
Un marché dynamique pour les solutions de génération de données synthétiques
Plusieurs approches sont aujourd’hui envisageables, selon que l’on souhaite s’équiper d’une solution dédiée ou bien prendre soi-même en charge la génération de ces jeux de données artificielles.
Parmi les solutions Open Source, on peut citer les quelques librairies Python suivantes :
Mais des éditeurs ont également mis sur le marché des solutions packagées de génération de données artificielles. Aux Etats-Unis, notamment, les éditeurs spécialisés se multiplient. Parmi eux figurent Tonic.ai, Mostly AI, Latice ou encore Gretel.ai, qui affichent de fortes croissances et qui ont toutes récemment bouclé d’importantes levées de fond
Un outil puissant, mais…
Même si l’on doit être optimiste et confiant quant à l’avenir des données synthétiques pour, entre autres, les projets de Machine Learning, il existe quelques limites, techniques ou business, à cette technologie.
De nombreux utilisateurs peuvent ne pas accepter que des données synthétiques, « artificielles », non issues du monde réel, … soient valides et permettent des applications analytiques pertinentes. Il convient alors de mener des initiatives de sensibilisation auprès des parties prenantes business afin de les rassurer sur les avantages à utiliser de telles données et d’instaurer une confiance en la pertinence de l’usage. Pour asseoir cette confiance :
Bien que de nombreux progrès soient réalisés dans ce domaine, un défi qui persiste est de garantir l’exactitude des données synthétiques. Il faut s’assurer que les propriétés statistiques des données synthétiques correspondent aux propriétés des données d’origine et mettre en place une supervision sur le long terme de ce matching. Mais ce qui fait également la complexité d’un jeu de données réelles, c’est qu’il capture les micro-spécificités et les cas hyper particuliers d’un cas d’usage donné, et ces « outliers » sont parfois autant voire plus important que les données plus traditionnelles. La génération de données synthétiques ne permettra pas d’adresser ni de générer ce genre de cas particuliers à valeur.
Également, une attention particulière est à porter sur les performances des modèles entrainés, partiellement ou complètement, avec des données synthétiques. Si un modèle performe moins bien en utilisant des données synthétiques, il convient de mettre cette sous-performance en regard du gain de confidentialité et d’arbitrer la perte de performance que l’on peut accepter. Dans le cas contraire où un modèle venait à mieux performer quand entrainé avec des données synthétiques, cela peut lever des inquiétudes quand à sa généralisation future sur des vraies données : un monitoring est donc nécessaire pour suivre les performances dans le temps et empêcher toute dérive du modèle, qu’elle soit de concept ou de données.
Aussi, si les données synthétiques permettent d’adresser des problématiques de confidentialité, elles ne protègent naturellement pas des biais présents dans les jeux de données initiaux et ils seront statistiquement répliqués si une attention n’y est pas portée. Elles sont cependant un outil puissant pour les réduire, en permettant par exemple de « peupler » d’observations synthétiques des classes sous-représentées dans un jeu de données déséquilibré. Un moteur de classification des CV des candidats développé chez Amazon est un exemple de modèle comportant un biais sexiste du fait de la sous représentativité des individus de sexe féminin dans le dataset d’apprentissage. Il aurait pu être corrigé via l’injection de données synthétiques représentant des CV féminins.
On conclura sur un triptyque synthétique imageant bien la puissance des sus-cités réseaux GAN, utilisés dans ce cas là pour générer des visages humains synthétiques, d’un réalisme frappant.
Il est à noter que c’est également cette technologie qui est à l’origine des deepfakes, vidéos mettant en scène des personnalités publiques ou politiques tenant des propos qu’ils n’ont en réalité jamais déclarés (un exemple récent est celui de Volodymyr Zelensky, président Ukrainien, victime d’un deepfake diffusé sur une chaine de télévision d’information).