Dans un monde où l’innovation est un facteur clef de Création et de développement des entreprises, reviennent deux questions : « Comment innover ? », et « Quelle sera la prochaine innovation ? ». Les sujets tels que le machine learning ou les plateformes data sont des incontournables de la décennie, mais des entreprises se lançant sur ces sujets sont parfois confrontées à des freins fondamentaux, faute de s’être posées la question suivante : « Quels sont les prérequis à l’innovation ? ».
Si l’innovation s’entend aujourd’hui quasi-exclusivement dans le cadre du numérique, il est important de se rappeler qu’elle existe depuis que l’humanité a commencé à développer des concepts technologiques, et ce, dans tous les domaines. Et dans ces 6000 ans d’Histoire, on peut trouver des exemples aux résonances contemporaines : des sociétés sont passées à côté d’innovations majeures pourtant à leur portée. Les freins innovatifs fondamentaux ne sont pas récents…
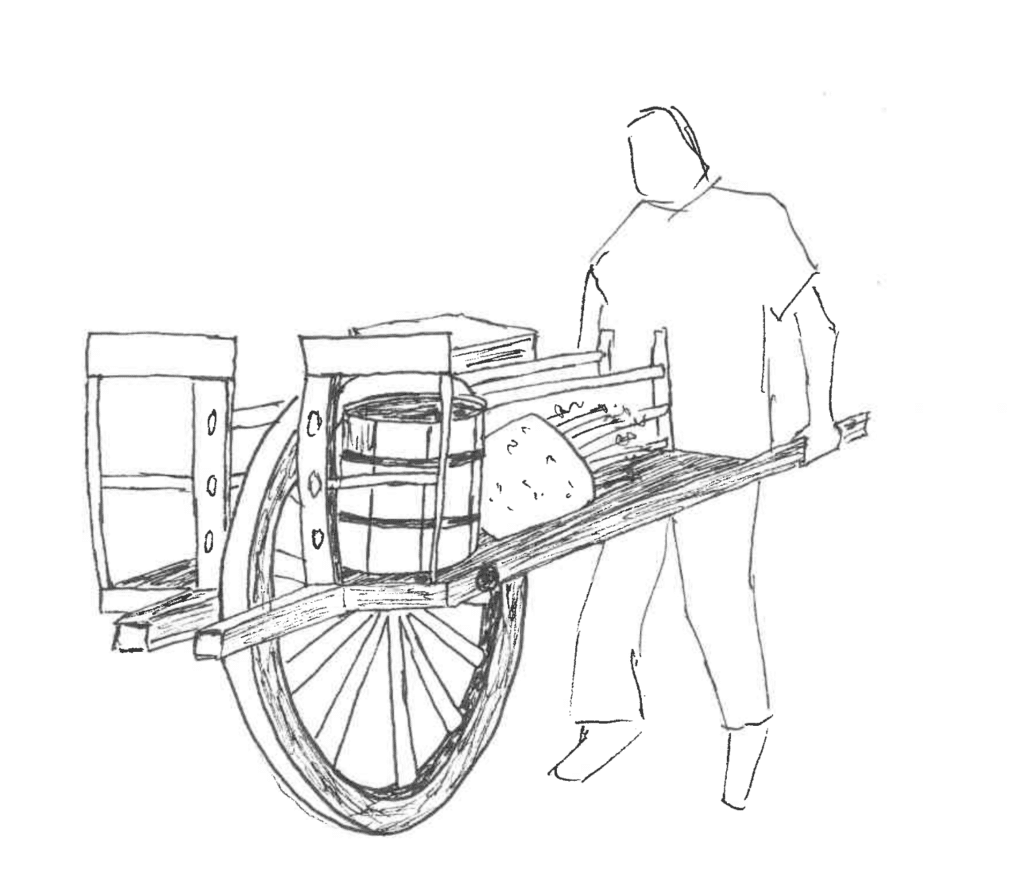
L’histoire de la brouette chinoise
Quoi de plus banal qu’une brouette : ce n’est qu’une plateforme avec des roues, permettant de transporter des charges d’un point A à un point B. C’est encore utilisé de nos jours, que ce soit dans le BTP, ou pour faire son potager. L’évidence de son usage, et sa simplicité de conception nous feraient croire que les brouettes ont toujours existé.
En Europe, les premières traces écrites relevant l’utilisation de brouettes datent d’il y a mille ans. Et, matériaux et détails de proportions mis à part, elles sont en tous points semblables à nos brouettes contemporaines.
En Chine, les choses sont différentes. Les brouettes apparaissent bien plus tôt, et elles ont rapidement évoluées (IIIème siècle après JC) vers une conception différente, bien plus efficace : la roue est placée de manière centrale sous la plateforme de charge. 1
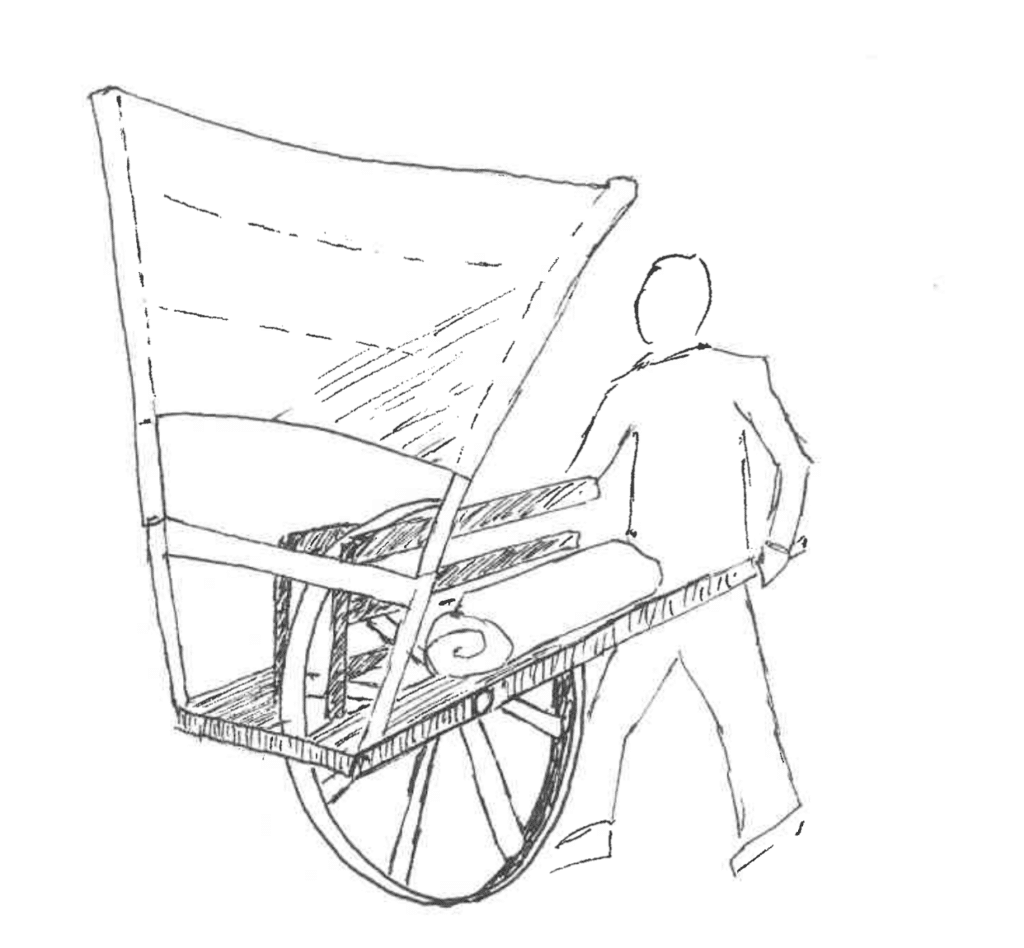
Le poids est bien mieux réparti, et à charge égale, l’opérateur dépense bien moins d’énergie. Compte tenu de la fréquence d’utilisation de cet objet, sur une période aussi longue qu’un millénaire, le gain collectif en productivité est incalculable mais doit être phénoménal. Mais ils ne se sont pas arrêtés là ! Dès le XVIème siècle, des explorateurs et marchands européens rapportent, stupéfaits, la description de brouettes à voile2. L’énergie éolienne est utilisée pour faciliter le transport terrestre, les Chinois sont donc capables de transporter, sur de longues distances et à faible effort, des charges importantes.
Brouette chinoise vs Brouette européenne, pourquoi un tel écart d’innovation ?
Une question semble évidente : pourquoi les Européens, également en recherche d’efficacité, et par ailleurs capables théoriquement d’appréhender ce concept (comme les trébuchets, inventés au XIIème siècle, sont bien plus complexes que ces brouettes en termes de compréhension et d’application de la physique), ne sont pas arrivés aux mêmes conclusions technologiques que les Chinois ?
L’hypothèse seule de la force des habitudes semble trop générique et supporte mal l’effort du temps. Ce frein culturel est réel, mais des dizaines de générations successives auraient dû en venir à bout. On peut proposer, parmi d’autres (modèle agraire, rapport culturel aux déplacements…), une hypothèse portée par le concept de « Dette d’infrastructure« .
L’innovation requiert autant l’intelligence et la capacité de réalisation que le contexte lui permettant d’exister. Cet exemple de la brouette chinoise met en lumière un défaut fondamental d’infrastructure de l’Europe médiévale par rapport à la Chine. Le gain en masse déplaçable (grâce à l’emplacement central de la roue), puis en distance parcourable (grâce à la voile) nécessite d’avoir des routes suffisamment solides pour accepter ce surplus de charge, et suffisamment longues pour que la volonté de parcourir de longues distances ait du sens. Or, jusqu’à la révolution industrielle, le point culminant du réseau routier européen a été atteint lors de l’Empire Romain. Réseau caractérisé par deux aspects : peu de dessertes “locales” et une infrastructure très lourde, potentiellement plus durable mais nécessitant des travaux d’entretiens massifs. Or, la chute de l’empire a marqué la fin des programmes d’entretiens, et de constructions de nouvelles routes. Le réseau chinois se basait, lui, sur un maillage local plus dense, et sur des infrastructures plus légères, et les dynasties continentales successives ont permis la pérennité d’une administration capable de garantir un entretien au long cours. 3
On se rend alors compte, qu’avant même d’avoir l’idée nécessaire pour développer une brouette performante, il eut été nécessaire de maintenir l’infrastructure routière en bon état, et qu’une amélioration potentielle des brouettes seule ne peut être un motif raisonnable et suffisant pour remettre à niveau l’infrastructure.
Les conclusions modernes liées à la gouvernance des données
Cet exemple historique peut sûrement être extrapolé par chacun dans son appréhension du secteur du numérique. Qu’il s’agisse d’infrastructure technique, logicielle, ou également de capital humain (Formation, culture d’entreprise), maintenir un haut niveau sur ce « fond » permet de saisir les progrès ponctuels que constituent les ruptures technologiques et innovantes.
Une entreprise peut rencontrer des difficultés à créer des modèles de machine learning pertinents, de la BI qualitative, ou encore une plateforme data ne se transformant pas en capharnaüm désorganisé, sans que cela soit du à des manques de compétences sur le projet, mais à cause des défauts structurels du patrimoine de données et d’une gouvernance défaillante ou inexistante. La temporalité longue de cet exemple nous renvoie aussi à l’approche de l’acquisition des compétences et des bonnes pratiques : préférer des formations et des acquis durables, réguliers, plutôt que des actions « coup de poing » permettant de répondre à un besoin dans la précipitation. Ou encore, privilégier l’agilité et la durabilité dans les infrastructures.
Plutôt que d’être réactive aux tendances, l’entreprise profondément innovante saura maintenir un haut niveau d’infrastructure, afin de pouvoir accueillir le plus facilement possible la prochaine brique innovante. Tout comme les brouettes, les applicatifs finaux que sont les modèles de ML, la BI, ne sont que des appendices portés par une infrastructure dont la qualité est déterminante, qu’il s’agisse d’un réseau routier, ou d’un patrimoine de données. Et pour garantir la vision stratégique de cette infrastructure, une autorité transverse durable est nécessaire, qu’il s’agisse d’un empire ou d’un Data Office.
2 van Braam Houckgeest, A.E. (1797). Voyage de l’ambassade de la Compagnie des Indes Orientales hollandaises vers l’empereur de la Chine, dans les années 1794 et 1795.3 https://www.landesgeschichte.uni-goettingen.de/roads/viabundus/the-dark-ages-of-the-roman-roads/
La question peut paraître saugrenue, car nous sommes habitués à dire que ce sont les chinois qui nous copient, et qu’en termes de libertés individuelles la Chine n’est pas nécessairement un modèle souhaité en France. Néanmoins, la Chine pense sur le temps long, avec une accumulation de plans quinquennaux qui au final peuvent s’étaler sur plus de 10 ans. Et le sujet de leur souveraineté numérique au sens large en fait clairement partie.
Pour revenir au sujet du cloud souverain, il est clairement d’actualité, avec l’amendement du député Philippe Latombe qui a été accepté, obligeant les opérateurs d’importance vitale pour la France à utiliser du cloud souverain plutôt que non souverain.
Mais avant de se comparer à la Chine, revenons aux basiques en retournant à l’étymologie du mot « souveraineté ».
Source : Pexels – Kevin Paster
La souveraineté, une proposition de définition.
Étymologiquement, et dans son sens premier, est souverain celui qui est au-dessus, qui est d’une autorité suprême.
Cela s’applique ainsi logiquement à un État, qui lui-même est chargé de défendre les intérêts français, que l’on parle de citoyens mais aussi d’entreprises. Citoyens, qui expriment leur souveraineté populaire (au sens rousseauiste du terme) dans le cadre d’élections.
Mais appliquons cela à ce qu’on entend alors par “cloud souverain”.
Ainsi, en déclinant cette idée de souveraineté au cloud, dont les clients potentiels sont l’état, les entreprises, les individus, il s’agit de placer l’état en garant des intérêts des citoyens et des entreprises, qui se mettent sous la coupe des lois françaises, lois assumés par tous par le mécanisme de souveraineté populaire.
Source : Pixabay – The DigitalArtist
Le cloud souverain, une proposition de liste de principes.
Dis comme ça, cela reste flou. Alors soyons plus pratico-pratiques :
Ni l’état, ni les entreprises, ni les citoyens ne souhaitent se faire espionner par une force étrangère, ou par des intérêts privés. Bonjour Edward Snowden.
Tout le monde souhaite que ses données privées, le restent. Bonjour les GAFAM. Bonjour Edward Snowden.
L’état, les citoyens, les entreprises souhaitent que les comportements délictueux exercés en France soient jugés en France. Bonjour les GAFAM. Bonjour Edward Snowden. Bonjour l’état de droit.
L’état, les citoyens, les entreprises souhaitent pouvoir avoir un accès sans soucis à un cloud sécurisé. Bonjour la liberté.
Une réalité éloignée de ces principes
Or, un certain nombre de points ne correspondent pas avec les acteurs étrangers.
Espionnage : Le Patriot act et le FISA, sont très clairs à ce sujet. Si votre clouder est américain, le piratage est légal et assumé. J’omets le Cloud Act, qui à mes yeux relève du « blanchiment » juridique.
Confidentialité : De même, les données considérées comme “privées” peuvent ainsi être récupérées. Sans compter les cookies traceurs et https://www.lebigdata.fr/donnees-anonymes-cnil-data-brokers). Et si vous ajoutez le fait que les protocoles “Internet” qui n’ont pas été créés comme sécurisés. Des palliatifs existent comme par exemple pour le protocole DNS (Protocoles DOH et DOT, DnsCrypt). Néanmoins, l’utilisation de HTTPS ne vous cache pas. Si vous allez sur https://siteinavouable.com, l’information que vous vous y connecter passe en clair, lors du handshake SSL. Il faudrait pour éviter cela que l’extension TLS d’”Encrypted Client Hello” soit généralisée.
Souveraineté aux yeux de la loi : L’extra territorialité des lois américaines n’est plus à prouver. Demandez à Frédéric Pierucci son avis.
Sécurisation : Et si nous passons tous par des routeurs fabriqués par des entreprises américaines, avec des ordinateurs utilisant des processeurs américains, avec un bios contenant des binaires américains pour les craintes, et pour un premier aperçu des possibilités, et le tout sur un système d’exploitation américain, la probabilité que des failles et autres backdoors “connues” seulement des américains existent n’est pas nulle. Et passons sur le simple fait que le trafic internet de votre tante vivant à Nice, se connectant à un site web hébergé à Strasbourg, ne va pas nécessairement longer les frontières françaises tel le nuage de Tchernobyl, laissant ainsi des « portes » d’écoute.
Alors quelle est la réponse de la Chine face à ces enjeux?
Espionnage : Mise en place d’un Great Firewall, perfectible par rapport à ses objectifs mais qui ne facilite pas le travail d’un espion étranger. Ecosystème “Chinese Only”, où aucune société américaine n’opère directement en chine (Voir Salesforce, Azure, Aws), mais par des intermédiaires 100% chinois.
Confidentialité : Pas le soucis majeur des chinois. Vous n’avez rien à cacher à l’état chinois, pas même vos secrets intimes.
Souveraineté aux yeux de la loi : Le fait de devoir passer par un intermédiaire chinois bloque les lois extra-territoriales américaines. Par exemple la société chinoise 21Vianet achète les “logiciels Azure” de Microsoft, pour après revendre de l’Azure en chine. Et comme dans la pratique l’état chinois a accès à tous les serveurs, c’est tout de suite plus pratique pour faire appliquerdes lois, et un “REX” extra-territorial sur TikTok : REX que votre serviteur avait précédemment pressenti.
Sécurisation : Le great firewall aide, transforme l’Internet Chinois en un quasi Intranet, mais n’est pas le seul vecteur de sécurisation. Comme énuméré précédemment, les vecteurs d’attaques sont :
Système d’exploitation : Diverses distributions linux chinoises, existence d’un linux fait par alibaba cloud
Serveur : Lenovo qu’on ne présente plus. De toute manière les fabricants étrangers ne sont pas les bienvenus.
Une utopie réaliste
Par rapport à cette liste à la Prévert, je n’invite pas à restreindre les libertés publiques mais à avoir une politique numérique très ambitieuse. Impossible n’est pas français comme je l’entendais dire dans ma jeunesse, et oui, un autre modèle est imaginable :
Espionnage : Renforcement très fort de l’ANSSI, pour aider encore plus les entreprises à se sécuriser, mais aussi pour sensibiliser. Promotion voir obligation d’utilisation de protocoles et de systèmes sécurisés, Travaux de recherche pour une sécurisation pour tous. Sécurisation des réseaux, y compris télécom afin d’éviter d’être géo-localisable par n’importe quelle agence étatique
Confidentialité : Interdiction des cookies traceurs. Généralisation des protocoles sécurisés. Amendes plus fortes et prisons en cas de négligence de confidentialité, voir de sécurité
Souveraineté aux yeux de la loi : Promotion du SecNumCloud et challenge perpétuelle de sa définition (ce qui est déjà le cas au vu des versions). Aides aux entreprises souhaitant passer la certification. Obligation pour l’état et les organismes d’importance vitales de passer par des clouders de droit et d’actionnariat français (bonjour les OIV)
Sécurisation :
Réseau : Promotion des acteurs français comme Stormshield, certifications de sécurité pour les acteurs qui communiquent leurs codes sources qui seront audités
Processeurs :
Fabrication dans un premier temps de processeurs sous license ARM (contenant quand même des brevets américains https://www.phonandroid.com/huawei-annonce-son-independance-aux-technologies-americaines-pour-2021.html) par une entreprise de droit français ou européen (ST MicroElectronics)
Travaux de recherche sur les plateformes Open Source RISC-V et Open Power et fonds d’investissement pour des startups
Système d’exploitation : Promotion et investissement sur la distribution linux française CLIP-OS, développé par l’ANSSI
Serveur : En soit un serveur consiste en une simple intégration de composants, qu’OVH fait lui même. Concernant le bios, avec un processeur français le problème sera directement résolu. Enfin concevoir des cartes mères n’est pas la chose la plus complexe (Si un ingénieur est capable d’en concevoir en solo…
Plus qu’un cloud souverain, un Internet de la confiance
Comme on peut le voir, je prends le contre pied de la Chine sur la vie privée et la confidentialité, et je cherche à démontrer que l’effort technologique n’est pas un mur infranchissable.
L’effort pour les DSI, RSSI, architectes, consiste à sensibiliser, mais aussi à promouvoir l’usage de solutions et de clouders certifiés secNumCloud, qui soient bien de droit français. La liste est régulièrement mise à jour.
Et oui, il faut « franciser » son SI. Et/où l' »open-sourcer ».
Sur le sujet de la sécurisation pour tous, être contre c’est être pour que n’importe qui dans la vie réelle puisse écouter ce que vous dites. On me rétorquera que la collecte d’adresse IP est nécessaire pour la lutte contre le harcèlement en ligne par exemple… Alors renforçons les pouvoirs et les moyens de la CNIL. Exigeons de nouvelles certifications plus sévères et plus contraignantes. Ce sujet de collecte d’ip pour des crimes graves (https://twitter.com/laquadrature/status/1658012087447085056) peut être la limite acceptable et contrôlable de notre vie privée et de notre sécurité. Car être contre notre sécurité et notre vie privée c’est être contre la protection de nos intérêts vitaux et économiques (https://twitter.com/amnestyfrance/status/1658449051296186369). La liberté individuelle et la liberté d’entreprendre sont ici parfaitement compatibles, elles vont même de pair. Croire l’inverse, c’est laisser la porte ouverte à tous vents, aux inconnus, aux belligérants. Et nous devons tous comprendre qu’il en va de l’intérêt général.
Qu’en est-il aujourd’hui, le GraphQL est-il réellement une alternative concrète aux APIs standard ?
Mais déjà, qu’est-ce que le GraphQL ?
Le GraphQL se définit par la mise à disposition d’une interface de “requêtage” qui s’appuie sur les mêmes technologies d’intégration / les mêmes protocoles utilisée par les API REST.
Ici, nous restons sur le protocole HTTP et par un payload de retour (préférablement au format JSON) mais la différence principale du GraphQL, pour le client, repose sur le contrat d’interface.
Le contrat d’interface façon GraphQL devient variable, tout comme la réponse. En effet, dans la requête nous pouvons spécifier ce que nous souhaitons recevoir exactement dans la réponse.
Nous mettons ainsi le doigt sur un gros avantage de cette interface GraphQL qui, par essence, va grandement diminuer le “overfetching et le “underfetching” (comprendre ici le fait de récupérer trop peu ou au contraire trop d’informations jugées inutiles dans le contexte) d’API
Autre avantage, ce besoin en données spécifiques pourra être différent à chaque appel et donc permettre une grande flexibilité d’usages à moindre effort.
Le GraphQL s’est fait sa place !
A l’époque de l’écriture de notre premier article, le GraphQL commençait à s’introduire dans certains cas d’usage, très souvent en mode POC et découverte, avec un concept attrayant mais sans preuve réelle de plus value.
Aujourd’hui nous observons une vraie adhésion à ce nouveau mode d’interfaçage, bien que nous en constatons encore des points d’amélioration.
Ce qui est intéressant à remarquer est qu’il se développe sur des métiers très variés. Non seulement au niveau des éditeurs de logiciels mais également dans le cadre de développements spécifiques, de plateformes dédiées.
Les usages à date : quelques exemples
Netflix, qui utilise le GraphQL pour unifier les accès aux différentes APIs.
Dans le retail, Zalando, pour récupérer les informations sur les différents produits et pour gérer les consentements.
MonEspaceSanté, le service lancé par l’ANS en début d’année, et qui effectue de requêtes GraphQL à partir du navigateur.
Le GraphQL comme réponse à un besoin d’uniformisation ?
Avant la naissance du GraphQL, le besoin d’uniformisation de ce type d’interaction était dans la ligne de mire de certains acteurs. Aujourd’hui le GraphQL peut apporter une réponse concrète et standardisée à ces problématiques.
Deux exemples d’envergure :
Microsoft : Microsoft a par le passé essayé de fournir des APIs “flexibles” pour adresser certains cas d’usage. Cette tentative s’est matérialisée par la création de l’OData et de l’API Microsoft Graph.
Ne vous trompez pas, l’objectif reste similaire mais l’approche est, à ce stade, différente. Dans une logique d’uniformisation et standardisation, nous voyons difficilement Microsoft s’affranchir d’une réflexion autour du GraphQL pour atteindre ces objectifs.
Salesforce : Salesforce propose également depuis plusieurs années, une API bas niveau qui pourrait, par ses caractéristiques et son besoin de flexibilité, être adaptée à la technologie GraphQL.
Constat actuel sur les usages du GraphQL
Quand nous regardons les cas d’utilisation de GraphQL, nous pouvons constater qu’il est majoritairement utilisé côté Front-end.
En lien avec ce cas d’utilisation, nous observons également que le GraphQL est souvent vu comme un agrégateur d’API, et pas comme un moyen de requêtage directement lié à une vision pure données.
Mais pourquoi ce type d’usage ?
Nous listons trois arguments principaux pour expliquer la prédominance de ce type de cas d’usage.
La restitution de format est très adaptée au monde du web : une réponse simple, toujours vraie et personnalisable ; le protocole HTTP et des concepts proches des APIs REST, le GraphQL s’adapte très bien aux couches front.
Chaque API derrière GraphQL gère son propre périmètre, si nous faisons la correspondance avec les architectures DDD (Domain-Driven Design), nous pouvons affirmer que l’API bas niveau adresse un domaine particulier, alors que le GraphQL est là pour pouvoir “mixer” ces différents concepts et donner une vision un peu plus flexible et adaptée à chaque cas d’usage. Dans ce cas nous allons faire de l’overfetching sur les couches bas niveaux, et faire un focus utilisation au niveau de la partie frontale.
Le cache, éternelle question autour du GraphQL. Dans ce cas d’usage le cache reste possible au niveau des APIs de bas niveau, qui iront donc moins solliciter les bases de données, alors que sur la couche GraphQL, de par sa variabilité de réponse, nous en avons peut-être moins besoin. Pour rappel, le cache sur une requête GraphQL, bien que possible, devient naturellement plus complexe à gérer et donc perd un peu de son intérêt.
Pourquoi ne faut-il pas limiter le GraphQL à ces usages ?
Pour nous, c’est notre conviction, le GraphQL a de nombreux atouts et doit se développer sur ces usages de prédilection, mais pas que !
UN ARGUMENTAIRE FORT : L’ACCÉLÉRATION DE LA CONCEPTION !
Un des grands atouts de la mise en place d’une API GraphQL reste le côté, si vous m’autorisez le terme, “parfois pénible” de la définition des API Rest : des discussions infinies entre le métier et l’informatique pour définir ce dont nous avons besoin, le découpage, etc.
Une API GraphQL par définition n’a pas une structure ou un périmètre de données définis, mais s’adapte à son utilisateur.
Le GraphQL comme moyen d’accélérer les développements ?
Une évolution de l’API bas niveau n’est plus nécessaire pour satisfaire le front
Un accès unifié aux données par un seul endpoint, sans forcément aller chercher dans les différentes APIs / applications
Tout en exploitant la logique de cache car le front end ne change pas
Et en plus des évolutions dans la gestion des caches permettent aujourd’hui de mettre en cache les données GraphQL
UNE DISTINCTION CLAIRE : ATTENTION AUX CAS D’USAGE !
Nous ne visons certainement pas tous les cas d’usages, mais l’objectif ici est de casser un peu certains mythes.
Si utiliser des mutations (en gros l’équivalent de l’écriture) intriquées, nous l’avouons, peut être très complexe, dans les cas de requêtage de bases de données ayant comme objectif principal l’exposition en consultation, nous disons “pourquoi pas !”.
Vous auriez probablement reconnu le pattern CQRS, avec, par exemple, une Vision 360 Client qui expose les informations avec une API GraphQL.
CÔTÉ TECHNIQUE
Les améliorations dans la gestion des caches, ces dernières années, permettent de gérer ce sujet, tout en restant plus complexe qu’avec une API REST standard.
Attention aux autorisations
Nous n’allons pas nous attarder sur ce sujet, que nous avons déjà traité dans notre précédent article (que nous vous invitons à parcourir ici), mais nous souhaitons le rappeler car il est crucial et extrêmement critique.
Si nous souhaitons traiter les sujets d’accès à la donnée avec une API GraphQL, une logique RBAC avec rôles et droits définis au niveau de la donnée (matrice d’habilitations rôles / droits proche de la donnée elle même) nous semble à ce stade la meilleure solution : N’AUTORISONS PAS L’ACCÈS UNIQUEMENT AU NIVEAU DE L’API, MAIS ALLONS AU NIVEAU DATA !
Conclusion
La technologie continue de s’affirmer, un standard semble se définir et s’étoffe de plus en plus. Dans un monde API qui se complexifie de jour en jour, les enjeux autour de la rationalisation et de l’optimisation des usages API restent au cœur des débats sans pour autant trouver de solution directe et efficace via la technologie REST. Et c’est encore plus vrai quand le besoin de base n’est pas clairement défini…
Le dynamisme apporté par le GraphQL, dans certains cas de figure, permet de simplifier ces discussions en apportant des réponses cohérentes avec le besoin.
Ce n’est pas une solution magique faite pour tous les usages, mais une réelle alternative à considérer dans les conceptions API.
Et vous ? Avez-vous pris en considération cette alternative pour vos réflexions API ?
Ne vous en faites pas, il n’est pas trop tard, parlons-en, ce qui ressortira de nos discussions pourrait vous surprendre.
Quoi de nouveau dans la version 6 de SAFe pour l’architecte solution?
Quoi de nouveau dans la version 6 de SAFe pour l’architecte solution?
25 juillet 2023
– 4 minutes de lecture
Architecture
Thomas Jardinet
Manager Architecture
Salomé Culis
Consultante Architecture
Cet article est le deuxième d’une série présentant les évolutions des rôles des différents architectes dans la nouvelle version du framework SAFe.
Après avoir étudié le System Architect, nous allons donc voir en détail les différences pour le Solution Architect avec la précédente version de SAFe.
Une position de “pivot” de l’architecture
Le Solution Architect, positionné entre l’Entreprise Architect et le System Architect, a cela de de particulier qu’il est un réel pivot d’architecture :
De l’Entreprise Architect, il doit prendre en considération les directions stratégiques de l’entreprise.
Du System Architect, il doit prendre en compte les remontées “terrain” des Trains Safe.
Il n’est pas pour autant un simple passe-plat, et encore moins une boîte mail générique, mais un acteur qui doit insuffler une direction technologique à l’ensemble du SI.
Il définit ainsi une vision technique, qu’il définit, cadre, met en place et partage. C’est par exemple à lui d’identifier les futures technologies à mettre en place, et à les instancier en les industrialisant.
Mais revenons un peu à ce rôle de pivot. Il est en effet extrêmement marquant pour moi de voir une citation du livre de Donella H. Meadows “Thinking in Systems”:
“You think that because you understand ‘one’ that you must therefore understand ‘two’ because one and one make two. But you forget that you must also understand ‘and.’ “
Cela ne vous parle peut-être pas, mais cette phrase est une très bonne synthèse (certes très raccourcie) de la théorie des Systèmes développée par l’autrice et son mari. Pensée systémique qui influença l’émergence de l’agilité, en expliquant que la complexité des systèmes se mesure dans le nombre d’acteurs et de leurs interactions.
Théorie des systèmes qui m’est personnellement très chère, considérant à titre personnel comme faisant partie de ma liste de livres à lire absolument. Cette théorie apporte en effet une grille de lecture très intéressante de l’environnement qui nous entoure, en cela qu’elle explique que nous sommes tous liés à ce qui nous entoure, et que nous réagissons par rapport à ce qui nous entoure. N’ayant pas toute la sagacité de ses penseurs, je vous laisserais creuser vous-même cette théorie qui inspire fortement entre autres les travaux du GIEC.
Et cerise sur le gâteau pour moi, certe déjà présente dans la version 5 du framework Safe, nous retrouvons l’idée de “démarche inverse de Conway”, qui consiste à calquer l’organisation sur l’architecture souhaitée, et non l’inverse. Démarche qui ferait de l’Architecte Solution un Architecte d’Entreprise qui s’ignore? Néanmoins, on retiendra que cette démarche inverse de conway fonctionne de manière plus fluide dans une organisation réellement agile et se voulant fluide, comme le recherche le framework Safe.
Et comme cette position d’architecte pivot de solution mais aussi de l’organisation ne provient pas non plus de nulle part, nous allons nous entâcher d’abord à réexpliciter son rôle.
Les responsabilités clés de l’architecte solution
Si nous devions chercher à être synthétique, nous pourrions dire que l’architecte solution est l’architecte “support” de l’Entreprise Architect en définissant avec lui la roadmap solution.
Roadmap solution qui est aussi défini en support avec le System Architect, mais lui en apportant des facilitations, des enablers, et le déchargeant des contingences techniques transverses.
Ainsi les différentes responsabilités du Solution Architect sont les suivantes :
Implementing Lean Systems Engineering :
Mise en place non seulement d’une démarche Devops, transverse aux différents projets, en définissant une architecture toujours prête à évoluer (le fameux Design to Change).
Establishing Solution Intent and Context :
Nouveauté par rapport à la version 5 du framework Safe. Cela consiste d’une certaine manière à un travail de cadrage et de veille. Quelles technologies pour quels nouveaux besoins métier? Et inversement quelles technologies peuvent créer quels besoins métier? Il définit également les différents besoins non fonctionnels et les besoins en termes de respect de la réglementation, mais aussi les “intentions” d’architecture, qui représentent la vision d’architecture souhaitée.
Defining and Communicating Architecture Vision :
Définition de la roadmap solution et de la vision d’architecture, participation aux pré pi-planning et pi-planning, gestion de la charge de ses sujets. Evidemment avec toutes les parties prenantes de l’architecture…
Evolving Solution Architecture with ARTs and Suppliers :
Qu’on pourrait résumer par “support aux développeurs et fournisseurs”, que ce soit sur les aspects d’exploration et d’expérimentation, de modélisation, de revue d’incrément, mais aussi bien évidemment de support à la définition de l’architecture du System avec le System Architect.
Fostering Built-in Quality and the Continuous Delivery Pipeline :
Qui représente la pleine partie DevOps de son travail.. Du développement jusqu’aux infrastructures, en passant par les tests, et bien évidemment la définition de la chaîne CI/CD.
Evolving Live Solutions :
C’est là une nouveauté par rapport à la version 5 du framework Safe. Cela consiste à dire que le Solution Architect doit continuer à suivre la solution passé la mise en production, en s’assurant du respect des besoins non fonctionnels, des contraintes réglementaires, mais aussi de son adaptabilité à de futurs besoins.
Les nouvelles relations du Solution Architect
Le rôle du Solution Architect dans la version 5 était peut-être réductrice. En effet il était auparavant quasiment aggloméré avec les architectes systèmes (vision assez réductrice à mes yeux, comme si un architecte solution ou un architecte system était la même chose). Il n’avait ainsi que des échanges avec l’équipe de Solution Management.
De cette modélisation bi-latérale du rôle du solution architect, la version 6 du framework Safe jette cela par la fenêtre pour le remplacer par un rôle de pivot de 4 équipes distinctes :
L’architecte d’entreprise qui apparaît dans la version 6, pour aligner ensemble l’architecture d’entreprise.
Le STE et les équipes de Solution Management pour piloter les trains de solution, comme précédemment.
Les systems architectes qui sont enfin distingués du “magma d’architectes” pour faire évoluer l’architecture solution.
Et enfin les équipes systèmes (pour faire simple les DevOps) apparaissent elles aussi, qui après tout sont ceux qui instancient l’architecture de solution.
,
Le tout bien évidemment dans une logique de collaboration, et non d’une simple logique purement top-down ou bottom-up.
Si ces sujets vous intéressent…
Pour plus d’informations sur ces sujets et sur le rôle d’architecte dans un environnement agile, n’hésitez pas à aller voir notre série d’articles sur l’architecture et l’agilité.
Les articles 1 et 2 peuvent en particulier se révéler utiles :
Article 1 : c’est quoi l’Agilité ? Cet article introduit notamment l’agilité à l’échelle et le framework SAFe. Des ateliers favorisant la co-construction de l’architecture sont également évoqués et pourraient se révéler très utiles pour faire participer les différentes parties prenantes avec lesquelles l’architecte collabore. https://www.rhapsodiesconseil.fr/architecture-dentreprise-et-agilite-chapitre-1-cest-quoi-lagilite/
Dans l’article 2, intitulé “ Détournement de valeur(s) en cours.”, nous avions évoqué dans le paragraphe “Les architectes font des plannings sur 5 ans qui sont irréalisables” le besoin de travailler sur des visions à plus court terme, et qui soient réalistes, conformément aux besoins de roadmap technologique des architectes solutions. https://www.rhapsodiesconseil.fr/articles/architecture-et-agilite-chapitre-2-detournement-de-valeurs-en-cours
Et évidemment, je ne peux que vous conseiller la lecture du livre mis en référence par le framework safe 6
Les 5 étapes pour réussir son projet de Data Visualisation
Vous êtes en charge d’un projet de Data Visualisation mais vous ne savez pas par où commencer ?
Nous avons formalisé pour vous les 5 étapes clés à suivre :
Poser le problème et les besoins métiers
Maquetter les Data Visualisations
Concevoir la solution technique Data
Déployer, industrialiser
Améliorer en continu
Ces différentes étapes sont décrites et accompagnées de fiches pratiques dans notre livre blanc
Principes et Méthodes pour maîtriser vos projets de data visualisation
Cet article est le premier d’une série présentant les évolutions des rôles des différents architectes dans la nouvelle version du framework SAFe.
Nous allons donc voir en détail les différences pour le System Architect, en particulier sur les sujets d’interactions avec les autres parties prenantes et les responsabilités du System Architect.
Changement de nom pour un nouvel architecte
Un premier point qu’il est important de souligner est le changement de nom de cet acteur lors du passage à la version 6 du framework. Celui-ci passe de “System Architect / Engineering” à “System Architect”, tout simplement.
Cela permet d’éviter une éventuelle confusion avec le Release Train Engineer ou même avec certains concepteurs fonctionnels qui sont plus proches d’un rôle de PO.
Mais ce changement de nom cache un changement beaucoup plus profond du rôle et de la posture de l’architecte système.
La compétence clé de l’architecte système, la collaboration
Dans cette nouvelle version du framework, la notion de collaboration est mise en exergue comme une compétence clé de l’architecte.
En effet, l’architecte système collabore avec différents groupes de parties prenantes :
Le PM et le RTE pour orienter les travaux du Train et contribuer au développement de la vision,
L’architecte solution et l’architecte d’entreprise afin de construire une architecture cohérente aux différents niveaux du framework et de l’entreprise,
Les équipes agiles pour les accompagner dans la mise en place de l’architecture,
D’autres équipes telles que la System Team ou des équipes Shared Services, notamment pour mettre en place des processus d’intégration et de tests automatisés.
Ainsi, l’architecte système doit être capable de travailler avec des acteurs très variés, de les aider à remplir leur rôle et de partager sa vision de l’architecture afin que le Train avance dans la bonne direction.
Nous voyons ici apparaître une notion de base de l’agilité, présente dans le manifeste agile (que vous avez tous sur votre table de nuit ou encadré au-dessus de votre bureau, j’en suis certaine !).
Cette nouvelle version du framework positionne très clairement l’architecte système comme un acteur qui sort de la tour de verre de l’architecture et va s’intégrer au quotidien dans les équipes.
La proximité favorise la collaboration
A titre personnel, en tant qu’architecte sur un programme de refonte de la relation client, j’avais fait le choix d’aller m’installer dans l’open space avec les équipes agiles. Cela permettait de :
Faciliter la collaboration avec elles,
D’être plus facilement impliquée dans des échanges avec le Programme Management et de mieux connaître les priorités pour pouvoir concentrer mes efforts sur les bons sujets,
D’avoir un vrai lien avec les équipes et qu’elles n’hésitent pas à venir me voir pour échanger sur l’architecture.
Au-delà des aspects cités précédemment, je me suis ainsi sentie comme faisant partie du projet à part entière. Je m’étais bien sûr assurée de garder une proximité forte avec mes collègues architectes (nécessaire pour s’aligner aux différents niveaux si vous avez bien suivi !).
Les responsabilités clés de l’architecte système
Vous vous dites peut-être que l’architecte système échange avec beaucoup d’acteurs. Et vous vous demandez peut-être en quoi consiste véritablement son rôle.
En effet, son rôle évolue pour assumer les responsabilités ci-dessous :
Aligner l’architecture avec les priorités Business (grâce à ses échanges avec le PM et les autres architectes),
Définir et communiquer la Vision d’Architecture (notamment auprès des équipes agiles),
Faire évoluer le système avec les équipes,
Favoriser la qualité au fur et à mesure de la construction du système et permettre la mise en place des NFRs (ou exigences non fonctionnelles). L’architecte s’assure qu’ils soient pris en compte dans le backlog et accompagne leur développement par les équipes,
Permettre la mise en place du DevOps et du Continuous Delivery Pipeline (par la collaboration avec la System Team par exemple).
Les deux derniers points notamment impliquent un véritable changement d’état d’esprit. Le travail de l’architecte ne s’arrête pas au moment de la présentation de la Vision d’Architecture, il doit continuer à accompagner le Train opérationnellement au quotidien pour pouvoir remplir l’ensemble de ces responsabilités.
Auparavant définies sous la forme d’une liste à la prévert, les tâches du System Architect deviennent à présent un nombre limité de responsabilités clés.
C’est un vrai shift pour la position de System Architect.
D’un architecte système qui s’assoit sur les “fauteuils pré-positionnés” par ceux qui ont défini le cadre de gouvernance SAFe, nous passons à un vrai acteur et “modeleur” de l’itération locale du framework SAFe.
Il n’est pas cantonné à des tâches définies de manière top-down, mais devient un acteur/décideur/influenceur du système.
Si ces sujets vous intéressent…
Pour plus d’informations sur ces sujets et sur le rôle d’architecte dans un environnement agile, n’hésitez pas à aller voir notre série d’articles sur l’architecture et l’agilité.
Les articles 1 et 4 peuvent en particulier se révéler utiles :
Article 1 : c’est quoi l’Agilité ? Cet article introduit notamment l’agilité à l’échelle et le framework SAFe. Des ateliers favorisant la co-construction de l’architecture sont également évoqués et pourront se révéler très utiles pour faire participer les différentes parties prenantes avec lesquelles l’architecte collabore.
Dans l’article 4, intitulé “Comment les architectes peuvent interagir avec l’agilité ?”, nous avions évoqué le fait d’aller vers des modes de travail plus collaboratifs et d’être véritablement partie prenante de la transformation de l’entreprise.