Rhapsodies Conseil accompagne les Chiefs Data Officer ou toute personne ayant une responsabilité sur les données à tirer parti de cet actif stratégique.
Les dimensions et les activités à traiter pour augmenter la valeur des données sont nombreuses : usages, culture data, maîtrise et gouvernance des données, amélioration des compétences, technologies data… Indispensable pour une organisation qui veut gérer ses données comme des actifs stratégiques, le rôle de CDO est encore récent dans de nombreuses organisations, où il faut trouver la meilleure articulation avec les Métiers, la DSI, mais aussi la Direction Générale.
Nos collaborations avec différents CDO ont motivé la formalisation d’un cadre complet et opérationnel au service de la transformation data : “Le Framework du CDO”. Les fiches pratiques de notre Framework pose le cadre qui structure la mise en œuvre de la transformation data d’une organisation avec l’ambition d’être un guide et un accélérateur de cette transformation au quotidien.
Celui, ou celle, que l’on appelait avant Architecte Fonctionnel et que l’on appelle à présent Architecte d’Entreprise (AE), a vu son domaine d’intervention être siloté avec une approche qui a privilégié les processus souvent au détriment des données.
La notion d’Architecte Data a donc vu le jour sur le marché, ou même Data Architect pour lui donner une aura internationale. A la manière des architectes SI ou techniques qui sont complémentaires aux AE, Est-ce la cas pour l’Architecte Data ? L’est-il ou fait-il exactement la même chose que l’AE sur les données ?
Mais pourquoi tout le monde veut ma place ?
De mon point de vue, l’architecte d’entreprise subit les conséquences d’une posture qui a fini par lui porter préjudice. Le fameux « architecte dans sa tour qui ne comprend pas les contraintes des gens qui font vraiment de l’informatique », réputation contre laquelle nous luttons tous les jours mais qui, nous devons bien nous l’avouer, existe encore parfois.
Un autre problème est lié au vocabulaire que nous utilisons. Un but de notre métier consiste à savoir si tel ou tel développement doit être fait dans telle ou telle application, et pour cela nous travaillons avec les fonctions. Alors une fonction, tout le monde pense savoir de quoi il s’agit mais ce n’est souvent pas le cas, et cela est moins parlant qu’une « Donnée ». De plus, les justifications pour regrouper des fonctions sont floues : cohérents, logiques,… sont des mots à bannir de notre vocabulaire.
Pour commencer : qu’est-ce qu’une fonction ?
Si on demande à Larousse, la définition d’une fonction est la suivante : « Ensemble d’instructions constituant un sous-programme identifié par un nom, qui se trouve implanté en mémoire morte ou dans un programme ». Personnellement, j’en ai une autre : une fonction est une instruction visant à modifier une caractéristique d’un objet.
La raison pour laquelle je préfère ma définition est que le mot objet permet de faire le lien avec un des éléments qui permettent de construire l’architecture fonctionnelle de votre SI.
Comment construisez-vous votre plan fonctionnel ?
Lorsque notre ami architecte d’entreprise définit un plan d’urbanisme fonctionnelde son système d’information, c’est qu’il veut mettre en évidence les fonctions nécessaires aux métiers. Mais quels sont les critères de regroupement ?
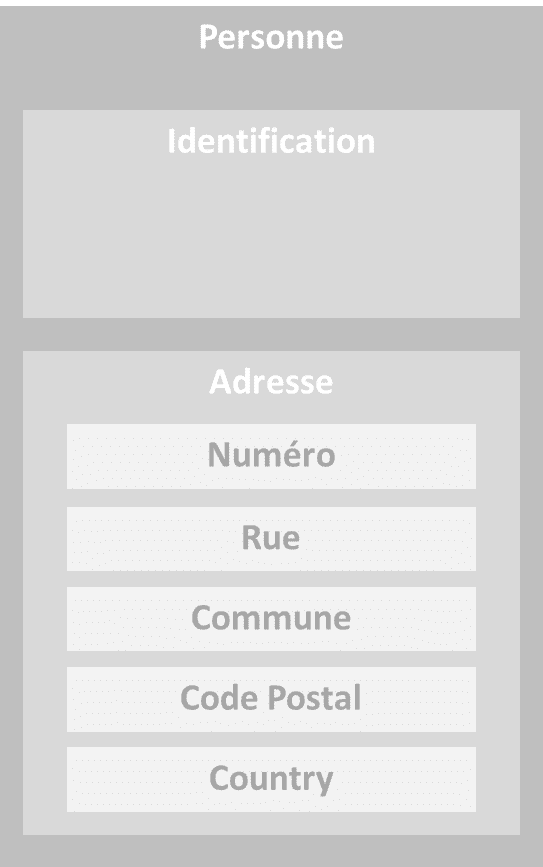
Le principal critère de regroupement, c’est la donnée. Pour bien comprendre, prenons l’exemple de l’objet, et donc de la donnée, « Personne » dans le cadre simplifié d’un site de distribution. Toutes les fonctions de l’objet « Personne » sont donc rangées dans le bloc Personne. Prenons ensuite les fonctions rangées dans le quartier Adresse. Ce sont des fonctions qui sont appelées, et donc des données qui sont modifiées, dans un même cas d’usage. Quand une personne déménage, les données liées aux fonctions dans le quartier Adresse sont modifiées. Enfin dans un ilot, vous allez retrouver toutes les fonctions qui peuvent modifier une information particulière : Modifier la rue, modifier le numéro, modifier la ville.
Cet exemple est concentré sur l’objet « Personne » mais cela est vrai pour la globalité de l’entreprise. Le modèle de donnée de l’entreprise est donc nécessaire pour construire un plan fonctionnel global de l’entreprise.
Mais comment parler avec les projets ?
Il faut arrêter de parler de fonctions avec vos projets, ne dites pas « quelles sont les fonctions que vous voulez ajouter » mais « quelles sont les données que vous allez impacter ». Charge à l’architecte d’identifier ensuite les fonctions. Il faut parler le même langage que lui, lui faire comprendre la valeur qu’on lui apporte et ce sera gagné.
L’Architecte Data est un architecte comme les autres. C’est son approche par les données qui met en avant les problèmes de gouvernance auxquels l’architecte fonctionnel était déjà confronté auparavant, alors « Reprenons notre dû, reprenons les data ! »
Lorsque l’on recherche sur Linkedin des experts en micro-services, les résultats sont nombreux… Y a-t-il une explosion des pratiques micro-services au sein des entreprises ou est-ce une surévaluation des expériences professionnelles ? Qu’est-ce qui nous rend pertinents sur le sujet ?
Qui fait réellement des micro-services ?
Ceux qui n’ont en fait pas compris ce que c’est…
Un micro-service est un service qui embarque des composants applicatifs et des données : nous entendons souvent parler de « frontal découpé en micros-services » ou « code applicatif découpé en micro-services » ou « j’ai créé un container Docker, j’ai produit un micro-service ».
Sans vouloir rentrer dans le débat de la pertinence de ces pratiques, nous pouvons affirmer qu’elles ne suffisent pas pour déclarer adhérer à une démarche micro-services.
Ceux qui font des micro-applications…
Il s’agit là de micro-services que nous n’avons pas besoin d’appeler micro-services.
Il s’agit d’une application, créée pour un besoin très spécifique.
Le découpage autour d’une seule API, liée à un domaine bien spécifique, pour un cas d’usage très précis, avec une base de données dédiée, est logiquement associable à un micro-service. Néanmoins, bien que l’appellation soit correcte, avoir contribué à ce type de réalisation ne nous rend pas forcément éligibles à des projets micro-services d’envergure…
Ceux qui font réellement des micro-services…
Seuls ceux qui y ont réellement contribué connaissent les vrais enjeux : sachez les identifier. Nous parlons ici d’une vraie approche micro-services qui suppose une réflexion data, mais également de l’orchestration et de la gestion de la cohérence.
Nous allons donc amorcer une première analyse de ces enjeux majeurs en nous focalisant surtout sur un des points clés de complexité : la gestion des adhérences entre micro-services (nous n’allons pas aborder les sujets de sécurité et gouvernance au sein de cet article, ils seront abordés dans une publication à venir).
Un micro-service, comme décrit dans le précédent article, doit être indépendant et isolé. Ces caractéristiques sont difficiles à obtenir quand le micro-service est créé et utilisé au sein d’un processus complexe demandant des orchestrations complexes.
Quels enjeux pour l’orchestration et la gestion de la cohérence des micro-services ?
L’orchestration des micro-services
Les micro-services, par leur nature, peuvent ne pas entièrement satisfaire à un processus ou à une étape de ce processus.
Pour pallier à ce besoin, une orchestration peut être réalisée en se basant sur des architectures de référence, selon le degré de complexité. Pour les cas les moins complexes, nous pouvons utiliser les backends des frontaux (avec par exemple une application BFF, Back For Front). Cette orchestration restera très spécifique à un cas d’usage. Il s’agit ici de l’enchaînement par exemple des appels vers deux micro-services, en lecture, car un seul ne suffit pas à garantir une expérience utilisateur complète (je retrouve les contrats d’un client et pour chaque contrat je lui montre les commandes associées).
Dans des cas plus complexes, ou hautement réutilisables, nous pouvons baser notre démarche sur d’autres outils. L’orchestration pourra alors être réalisée :
Par un moteur d’orchestration maison, spécialement conçu et dédié
Par des outils de BPM, qui peuvent y voir une seconde jeunesse après les promesses de la période SOA
Ces cas de figure permettent comme dit auparavant, également de mieux gérer le second point, la cohérence des données.
La gestion de la cohérence des micro-services
La cohérence canalise le sujet sur l’aspect données. Nous allons le résumer aux questions suivantes :
Comment assurer la cohérence si on travaille sur plusieurs bases de données ?
Rollback ? On se complique la vie avec les micro-services ?
On oublie l’ACID et on perd donc tous ses avantages ?
Probablement, ce qui va résoudre la moitié de ces cas de figure est le pragmatisme. Voici quelques exemples :
Un axe de simplification est porté par le découpage des micro-services : un découpage trop fin implique forcément une complexité croissante, donc attention à ne pas scinder là où on n’en a pas besoin.
Un autre est de s’assurer de la bonne conception fonctionnelle maximisant les couplages lâches entre les objets, les taches et les processus, pour qu’on ait le moins de rollback à faire si une des opérations orchestrées n’aboutit pas.
Un troisième est une analyse de la rigueur / la sécurisation demandée pour chaque cas d’usage. N’oublions pas que chaque information traitée demande une attention différente. Les données de tracking des utilisateurs sur mon site internet peuvent avoir un niveau de certitude inférieur par rapport à la gestion des transactions bancaires liées aux achats sur le même site.
C’est à partir de ces réflexions qu’on balaie une partie des interrogations et qu’on peut se focaliser sur les sujets complexes d’intégration et gestion des micro-services, demandant la mise en place de pratiques d’orchestration visant à pallier à ces sujets de cohérence.
Les exemples discutés dans cet article n’ont pas vocation à être exhaustifs mais aident dans l’élaboration et la mise en application d’une démarche micro-services.
Les contraintes imposées par une démarche micro-services obligent à une réflexion très structurée dès la conception. D’où l’importance, comme nous avons pu le dire auparavant, de ne pas se focaliser uniquement sur du découpage fin mais de bien mener la réflexion autour des données, des interactions, des orchestrations et de la spécificité de chaque micro-service.
NB : nous n’avons pas distingué l’orchestration et la chorégraphie des micro-services dans cet article, ce sera le sujet d’une publication à venir !
Dessiner une cible, bien sûr, mais à quel horizon ? Sous quel angle ?
Sur ces sujets, nous devons différencier plusieurs points de vue.
Formaliser la cible à long terme : l’idéal
Récemment, nous avons animé pour un client la définition d’une cible à environ 5 ans qui permettait de donner les grandes directions et surtout de mettre en avant ce qui devrait être (ou non) couvert par l’ERP central.
Cette cible a permis de partager une vision d’ensemble des projets d’étude et des grands pans applicatifs qui allaient évoluer. Et donc aussi de définir ceux qui ne feraient pas l’objet d’investissements conséquents dans les prochaines années.
A l’inverse, sur certains pans du SI, cette cible ne pouvait pas être mise en application de suite car elle était parfois trop éloignée de la réalité. Plusieurs étapes peuvent alors être nécessaires pour atteindre cette cible. Ce genre de cible étant vue comme « inatteignable ». Pourtant 5 ans cela peut être court au regard de certains autres investissements lourds (construction d’usines de production, construction d’un data center…) mais au vu de la vitesse exponentielle de l’évolution de l’IT, cela peut paraître très long.
Formaliser la cible à plus court terme : dans quel cas ?
Une cible a 2-3 ans peut à l’inverse paraître très courte car certains projets peuvent mettre du temps à se lancer. Ensuite, le temps d’organiser les équipes, de comprendre le sujet, etc., il peut déjà se passer facilement 1 an ou 2 dans certains cas. Pour un de mes clients, une grande banque, nous avons passé 6 mois à construire une cible macro, définir les principaux besoins, ce qui devait évoluer et les principales briques du systèmes (à acheter ou à développer). Puis au moment de se lancer et vu l’importance des sujets à traiter, il a fallu passer par une étape « politique » qui consistait à décider d’une structure pour ce programme (et à qui elle devait être rattachée) : nommer de nouveaux responsables ; les faire venir de leurs anciens postes ; procéder au recrutement en cascade qui va bien, aussi bien avec des internes et compléter par des consultants (pour des raisons de charge de travail, d’expertise, etc.).
Une cible à plus court terme peut permettre de faire comprendre les premières étapes de la transformation.
Comme dans tous nos travaux nous devons donc trouver le juste équilibre entre le court, moyen et le long terme. Suivant les cas, il n’y a pas une cible à décrire mais plusieurs ! Certains domaines sont à court terme car ils risquent de devoir évoluer rapidement et on parlera davantage de plateformes. Certains autres sujets doivent être pris sur le long terme (ERP) au vu des coûts et des changements qu’ils impliquent.
Cette période délicate du confinement par bien des égards a mis en exergue un certain nombre de constats irréfutables :
Les séniors représentent une part importante de notre population,
Les maladies chroniques sont galopantes de part nos nouveaux modes de vie et requièrent des soins fréquents et sur le long terme,
Les économies réalisées à tous les étages du système de santé fragilisent ce dernier, à commencer par le personnel soignant.
La population prend connaissance de ces faits à l’heure où :
sa mobilité est temporairement entravée (au même titre que pour certaines populations à mobilité réduite),
se rendre à l’hôpital fait courir un potentiel risque de contamination malgré les filières d’admission distinctes,
le personnel soignant a lui même peur d’être infecté et doit sans cesse optimiser son temps ainsi que le matériel médical utilisé.
La téléconsultation est une réponse du digital sur le début du parcours de santé.
Elle permet une optimisation à un instant T pour tenter de poser un diagnostic à distance. Elle sera pertinente dans bien des cas de figure mais trouvera ses limites dans certaines situations, la médecine ayant toujours eu besoin de contact physique, d’auscultation pour identifier des marqueurs, des réponses corporelles à un problème donné.
Quelle suite donner une fois le diagnostic posé ?
Dans le cas où l’état de santé permet un suivi à domicile, soit :
un(e) infirmier(e) libéral(e) passera plusieurs fois par jour pour prendre les mesures physiologiques (température, saturation en oxygène, tension artérielle, …), réaliser des soins et remplacer éventuellement les consommables médicaux (perfusions, bouteilles d’oxygène, …). Toujours en courant le risque d’être personnellement infecté, de contaminer sa patientèle non atteinte, et de multiplier les heures et les déplacements.
il conviendra de refaire des téléconsultations pour suivre ponctuellement l’évolution de l’état de santé de la personne malade au risque de surcharger les médecins en téléconsultation ou de louper l’étape charnière avant l’aggravation de la maladie.
C’est à ce moment précis que les objets connectés peuvent être d’une grande utilité !
De plus en plus accessibles via des dispositifs grands publics :
thermomètre connecté,
oxymètre connecté,
tensiomètre connecté,
bouteille d’oxygène connectée,
et bien évidemment montre connectée avec ElectroCardioGramme (ECG), saturation en oxygène, …
Ces objets connectés permettent en toute autonomie de prendre régulièrement (et sur une période de temps étendu) des mesures physiologiques personnelles fiables et de les télétransmettre à une plateforme médicale qui pourra automatiquement et très rapidement réaliser des interprétations médicales pertinentes (via des algorithmes d’intelligence artificielle notamment).
Les médecins pourront ainsi consulter les monitoring réalisés mais surtout être alertés automatiquement par la plateforme en cas de risques prédits ou décelés pour intervenir au plus tôt et sauver des vies.
Les avantages sont nombreux :
Autonomie de la personne à domicile,
Désengorgement des hôpitaux (en particulier les services d’urgence) pour le suivi simple,
Libération du personnel soignant pour qu’il se consacre aux situations plus complexes,
Optimisation des moyens matériels médicaux,
Réduction des déplacements inutiles et donc des risques de propagation,
…
La situation délicate dans laquelle nous nous trouvons actuellement met en relief tout le potentiel que peuvent nous apporter l’ensemble de ces nouvelles technologies.
Bien des questions (respect des données personnelles, confidentialité, secret médical, …) restent à instruire en périphérie des débats technologiques, mais à l’heure du Dossier Patient Informatisé, de la téléconsultation, nul doute que la télémédecine prennent de l’ampleur, bien aidé par le développement croissant de l’Internet Of Things.
Le Big Data est maintenant passé au stade industriel pour beaucoup de moyennes et grandes entreprises. Les objectifs qui doivent être atteints pour ce type d’initiatives étant de dé-siloter les données de l’entreprise et d’en favoriser l’accès.
Ceci a donc donné lieu à toutes sortes de projets de plateformes Data Centric : Data Lab, Data Hub, Data Lake, … Certains de ces projets ont échoué, d’autres ont réussi. Nous avons regroupé dans cet article les astuces et principes qui nous semblent clés pour réussir votre projet de Data Hub.
Tout d’abord qu’est-ce qu’un Data Hub ?
Auparavant les traditionnels entrepôts de données ne traitaient que des données structurées ayant préalablement subi une transformation technique avec une logique métier particulière. Ceci rendait complexe toute intégration d’une nouvelle source de données ou projet d’évolution de cet entrepôt de données. Le Data Hub permet de répondre aux critères ci-dessous :
Découpez votre projet de Data Hub en 4 grandes étapes
Le Data Hub ne se résume pas à une plateforme technique pour sauvegarder un historique de vos données d’entreprise. Les architectes ont un vrai rôle à jouer dans le projet afin de définir le positionnement de cette plateforme dans le paysage SI de votre entreprise et par rapport au cycle de vie de vos données comme nous l’indiquions dans cet article : un data lake sans architecture est un vrai saut dans le vide.
Vous pourrez ensuite lancer votre projet de Data Hub au travers de ces 4 grandes étapes :
1 . Identifier vos principaux usages
Comment faire pour sélectionner les sources de données qui alimentent votre Data Hub ? Faut-il chercher à tout historiser et trouver les usages ensuite ? Faut-il d’abord définir un langage commun avec tous les métiers et définir les concepts associés avant de pouvoir les valoriser ? Pour ce faire, nous vous proposons une démarche pragmatique en partant des cas d’usages métier auxquels vous souhaitez répondre. Ceci vous permettra d’identifier rapidement les sources de données pertinentes pour votre Data Hub, qu’elles soient internes/externes à l’entreprise, déjà existantes et accessibles ou à acquérir/enrichir depuis différentes sources.
2 . Cadrer l’architecture,
Quand viendra le temps de définir l’architecture de votre futur Data Hub, il conviendra à minima d’adresser les principaux domaines fonctionnels suivants et d’identifier ensuite les technologies les plus appropriées en fonction des catégories de cas d’usages que vous avez choisies de traiter :
Avant de mettre en production la ou les briques de stockage, il faudra définir et convenir d’une politique et de règles d’urbanisation afin d’organiser les espaces :
Exemples de besoins qu’il faudra gérer:
3 . Démarrer l’industrialisation et la gouvernance de vos données
La gouvernance de vos données dans le Data Hub doit commencer dès le début de l’ingestion en créant une fiche d’identité de cette source de données que vous compléterez par des métadonnées. Ceci devrait permettre d’avoir une classification de cette donnée et lui associer les responsables.
Exemples de métadonnées pouvant y être associés :
techniques (description du format et des colonnes) via un dictionnaire de données,
métiers (à quel terme ou objet métier fait référence cette donnée) via un glossaire métier,
responsables métiers et IT.
tout autres métadonnées servant à qualifier vos données: confidentialité, type de donnée (référentiel, opérationnel, etc), application source, …
les politiques et règles associés à vos données lié à la qualité, à une réglementation où à la sécurité.
Ces informations devront ensuite être centralisées et partagées au sein d’un Data Catalog. Celui-ci deviendra ensuite la pierre angulaire qui permettra d’opérer et piloter votre gouvernance de données que ce soit en terme de qualité, de partage, de conformité ou de son cycle de vie via du Data Lineage.
Malheureusement plusieurs organisations font le choix d’adresser cette problématique plus tard pour différentes raisons. Le risque de ne pas adresser dès le départ cette gouvernance est de vous retrouver dans un marécage de données (Data Swamp) où il vous sera très difficile d’identifier les données qui ont de la valeur pour vos usages ou tout simplement de déployer les mesures de sécurité conformément à leur niveau de sensibilité. Prenez le temps d’urbaniser et structurer votre Data lake (lac de données).
4 . Qualifiez vos données et déployer vos usages
Un autre défi qu’il vous faudra relever est de bien qualifier la qualité d’une source de données par rapport à vos usages. Le monitoring de cette qualité pouvant se faire au travers plusieurs dimensions :
Les propriétés de vos données :
Est-ce que le schéma de vos données est stable ou sera amené à évoluer ?
Est-ce qu’il y a des patterns de format à harmoniser pour certains attributs comme les dates par exemple ?
Quel est le volume attendu ?
Quel est le niveau de performance attendu par les usages métiers ?
Les patterns d’ingestion et consommation
Comment sera alimenté le Data lake ? Par API, message, fichier plat ?
Quel format d’exposition sera le plus pertinent ?
Disponibilité, complétude et intégrité
A quelle fréquence seront rafraîchies les données ? Quelles sont les règles techniques et métiers à mettre en place afin de s’assurer de la bonne qualité de vos données pour vos usages?
En conclusion, vous trouverez ci-dessous le récapitulatif des grands principes à respecter pour réussir votre projet de Data Hub :