Après avoir été successivement décrit comme le job le plus sexy du 21ème siècle puis comme aisément remplaçable par la suite, le data scientist a de quoi souffrir aujourd’hui de sacrés questionnements. Son remplaçant le plus pertinent ? Les solutions d’Auto-Machine Learning, véritables scientifiques artificiels des données, capables de développer seuls des pipelines d’apprentissage automatique pour répondre à des problématiques métier données.
Mais une IA peut-elle prendre en charge la totalité du métier de data scientist ? Peut-elle saisir les nuances et spécificités fonctionnelles d’un métier, distinguer variables statistiquement intéressantes et fonctionnellement pertinentes ? Mais aussi, les considérations d’éthique des algorithmes peuvent-elles être laissées à la main … des mêmes algorithmes ?
Le Data Scientist, vraiment éphémère ?
Le data scientist est une figure centrale de la transformation numérique et data des entreprises. Il est l’un des maîtres d’œuvre de la data au sein de l’organisation. Ses tâches principales impliquent de comprendre, analyser, interpréter, modéliser et restituer les données, avec pour objectifs d’améliorer les performances et processus de l’entreprise ou encore d’aller expérimenter de nouveaux usages.
Toutes les études sur les métiers du numérique depuis 5 ans sont unanimes : le data scientist est l’un des métiers les plus en vogue du moment. Pourtant, il est plus récemment la cible de critiques.
Des observateurs notent une baisse de la « hype » autour de la fonction et une décroissance du ratio offre – demande, qui viendrait même pour certains à s’inverser. Trop de data scientists, pas assez de postes ni de missions.
Deux principales raisons à cela :
La multiplication de formations et bootcamps certifiants pour le poste, résultant en une inondation de profils juniors sur le marché ;
Une rationalisation des organisations autour de l’IA et une (parfois) limitation des cas d’usage – l’époque de l’armée de data scientists délivrant en série des POCs morts dans l’œuf est belle est bien révolue.
Mais également, et c’est cela qui va nous intéresser pour la suite, pour certains experts, le « data scientist » ne serait qu’un buzzword : l’apport de valeur de ce rôle et de ses missions serait surévalué, jusqu’à considérer le poste comme un effet de mode passager voué à disparaître des organisations.
En effet, les mêmes experts affirment qu’il sera facilement remplacé par des algorithmes dans les années à venir. D’ici là, les modèles en question deviendraient de plus en plus performants et seraient capable de réaliser la plupart des tâches incombées mieux que leurs homologues humains.
Mais ces systèmes si menaçants, qui sont-ils ?
L’Auto-ML, qu’est-ce que c’est ?
L’apprentissage automatique automatisé (Auto-ML) est le processus d’automatisation des différentes activités menées dans le cadre du développement d’un système d’intelligence artificielle, et notamment d’un modèle de Machine Learning.
Cette technologie permet d’automatiser la plupart des étapes du procédé de développement d’un modèle de Machine Learning :
Analyse exploratoire : préparation et nettoyage des données, détection de la typologie de problème à adresser ;
Ingénierie et sélection des variables : analyse purement statistique (et non fonctionnelle, c’est l’un des points faibles) des différentes variables, sélection des variables pertinentes, création de nouvelles variables (ces modèles peuvent-ils le faire… ?) ;
Sélection du ou des modèles à tester, entraînement, mise en place de méthodes ensemblistes de modèles, fine tuning des hyper-paramètres, analyse et reporting de la performance ;
Agencement de l’analyse : mise en place du pipeline sous contrainte (coût / durée d’entrainement, complexité du ou des modèles, …) ;
Industrialisation et cycle de vie : restitution à l’utilisateur des résultats sous la forme de graphes ou d’interface, branchement simplifié à un tableau de bord prêt à l’emploi, sauvegarde et versionning des différents modèles.
L’Auto-ML démocratise ainsi l’accès aux modèles d’IA et techniques d’apprentissage automatique. L’automatisation du processus de bout en bout offre l’opportunité de produire des solutions (ou à minima POC ou MVP) plus simplement et plus rapidement. Il est également possible d’obtenir en résultat des modèles pouvant surpasser les modèles conçus « à la main » en matière de performances pures.
En pratique, l’utilisateur fournit au système :
Un jeu de données pour lesquelles il souhaite mettre en place son usage d’intelligence artificielle – par exemple une base de données client et d’indicateurs calculés (chiffre d’affaires total, sur la dernière année, nombre de transactions, panier moyen, propension à abandonner son panier, …)
Une variable cible d’entraînement, qu’il souhaite prédire dans le cadre de l’usage en question – par exemple la probabilité de CHURN du client en question ;
Des contraintes vis-à-vis de la sélection du modèle : quelle typologie de modèle à utiliser / exclure, quelle(s) métrique(s) de performance considérer, quels seuils de performance accepter, quelle durée d’entraînement maximale tolérer, …
Le système va alors entraîner plusieurs modèles – ensemble de modèles et modéliser les résultats de cette tache sous la forme d’un « leaderboard », soit un podium des modèles les plus pertinents dans le cadre de l’usage donné et des contraintes listées par l’utilisateur.
Source : Microsoft Learn
Quelles sont les limites de l’Auto-ML ?
Pour autant, l’Auto-ML n’est pas de la magie et ne vient pas sans son lot de faiblesses.
Tout d’abord, les technologies d’Auto-ML rencontrent encore des difficultés à traiter des données brutes complexes et à optimiser le processus de construction de nouvelles variables. N’ayant qu’une perception statistique d’un jeu de données et (aujourd’hui) étant dénué d’intuition fonctionnelle, il est difficile de faire comprendre à ces modèles les finesses et particularités de tel ou tel métier. La sélection des variables significatives restant l’une des pierres angulaires du processus d’apprentissage du modèle, apparaît ainsi une limite à l’utilisation d’Auto-ML : l’intuition business humaine n’est ainsi pas (encore) remplaçable.
Également, du fait de leur complexité, les modèles développés par les technologies d’Auto-ML sont souvent opaques vis-à-vis de leur architecture et processus de décision (phénomène de boîte noire). Il peut être ainsi complexe de comprendre comment ils sont arrivés à un modèle particulier, malgré les efforts apportés à l’explicabilité par certaines solutions. Cela peut ainsi amoindrir la confiance dans les résultats affichés, limiter la reproductibilité et éloigner l’humain dans le processus de contrôle. Dans une dynamique actuelle de prise de conscience et de premiers travaux autour de l’IA éthique, durable et de confiance, l’utilisation de cette technologie pourrait être remise en question.
Enfin, cette technologie peut aussi être coûteuse à exécuter. Elle nécessite souvent beaucoup de ressources de calcul (entrainement d’une grande volumétrie de modèles en « one-shot », fine tuning multiple des hyperparamètres, choix fréquent de modèles complexes – deep learning, …) ce qui peut rendre son utilisation contraignante pour beaucoup d’organisations. Pour cette même raison, dans une optique de mise en place de bonnes pratiques de numérique durable et responsable, ces technologies seraient naturellement écartées au profit de méthodologies de modélisation et d’entrainement plus sobres (mais potentiellement moins performantes).
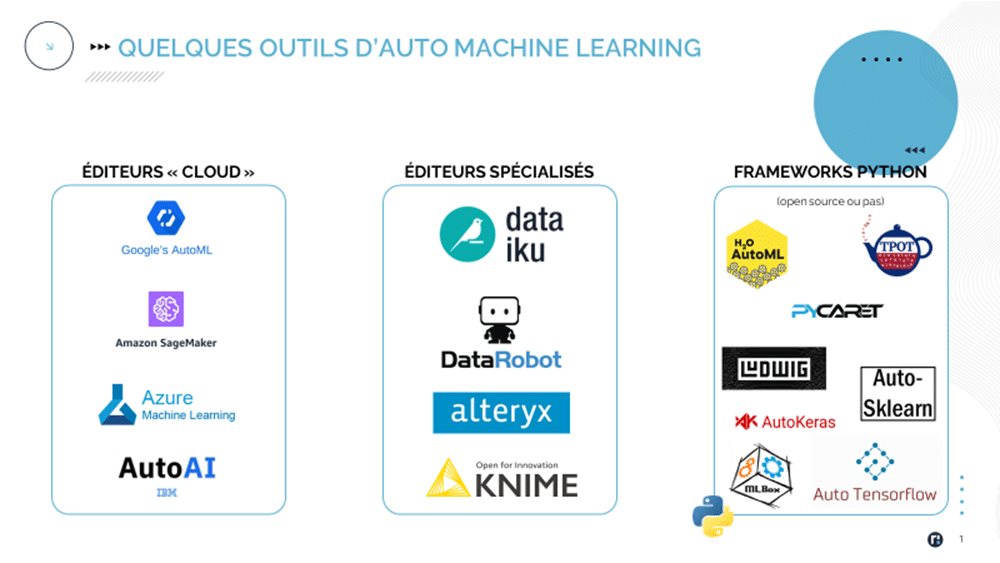
Quelles solutions d’Auto-ML sur le marché ?
On peut noter 3 typologies de solutions sur le marché :
Les solutions des éditeurs de cloud (GCP, AWS, …), pré-packagées dans les offres, permettant de profiter d’infrastructures d’entraînement performantes et de modèles pré-entraînés ;
Les éditeurs spécialisés dans les plateformes de data science, comme la licorne française Dataïku ou le pure-player ML DataRobot ;
Les librairies Python (et leur pendant R, parfois) open-source, certaines se branchant sur des frameworks bien connus de la profession (Auto Sklearn, AutoKeras, …)
H2o Auto-ML en pratique
Jetons un coup d’œil à H2o.ai, librairie Python open source d’Auto-ML développée par l’entreprise éponyme. Nous prendrons comme cas d’usage un problème de classification binaire classique sur des données tabulaires, issu du challenge mensuel Kaggle d’Août dernier.
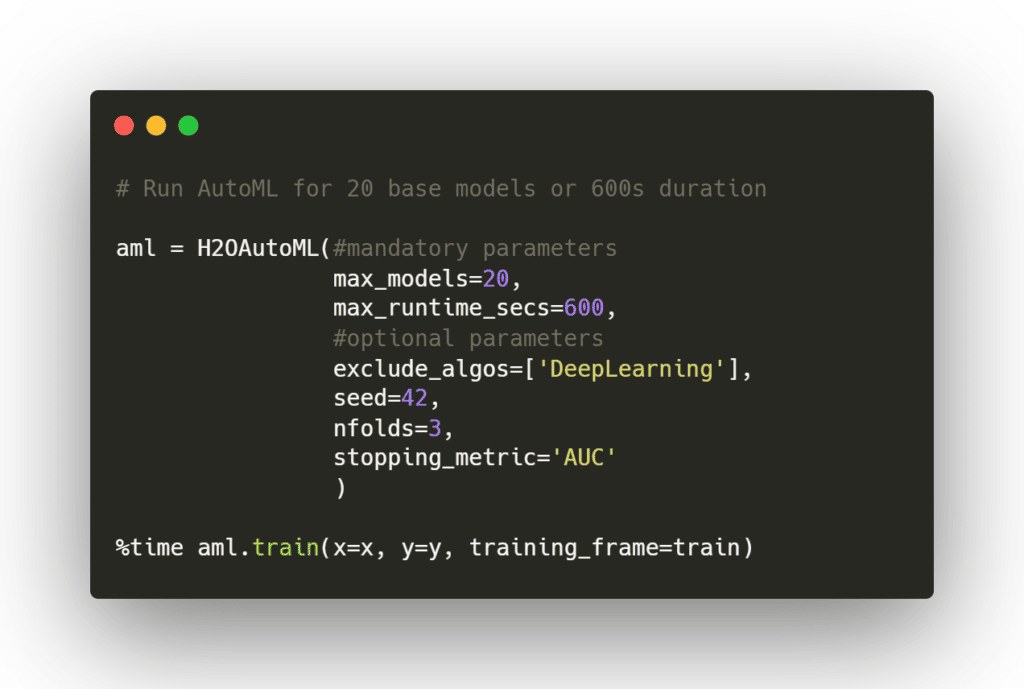
Après un chargement des données et une initialisation de l’instance locale, on va pouvoir lancer le moteur d’AutoML :
Doivent être spécifiés :
La volumétrie maximale de modèles à entraîner (permet d’ajuster les performances et de ne pas aller dans le « toujours plus ») ;
Une durée maximale de temps d’exécution, pratique en phase de prototypage du pipeline ;
Le H2o dataframe d’entraînement en indiquant les variables indépendantes (x) et la variable à prédire (y). A noter qu’il s’agit d’un format de dataframe spécifique mais que la conversion depuis et vers un dataframe pandas « traditionnel » se fait très simplement.
Il est également possible d’ajouter des paramètres tels que :
Les éventuelles typologies de modèles à exclure – ici on retire les modèles de deep learning mais peuvent également être exclus l’empilement (« stacking ») de modèles, les xgboost ou encore les algorithmes de « gradient boosting » ;
Une métrique d’arrêt (ex : logloss, AUC, …) qui permettra, une fois la valeur cible atteinte ou un nombre de rounds d’entrainement sans amélioration dépassé d’arrêter le processus de training ;
Tout un ensemble de paramètres pour gérer la validation croisée (nombre de folds, conservation des modèles non retenus et leurs prédictions, …) ;
Des fonctionnalités de ré-équilibrage des classes, afin d’adresser les problématiques de datasets déséquilibrés (par exemple, dans un problème de classification binaire, une répartition 90-10 sur la variable à prédire dans le jeu d’entraînement) ;
Il est important de noter que H2o AutoML ne propose aujourd’hui qu’une fonctionnalité limitée de préparation des données, se limitant à de l’encodage de variables catégorielles. Mais la société travaille aujourd’hui à enrichir ces fonctionnalités.
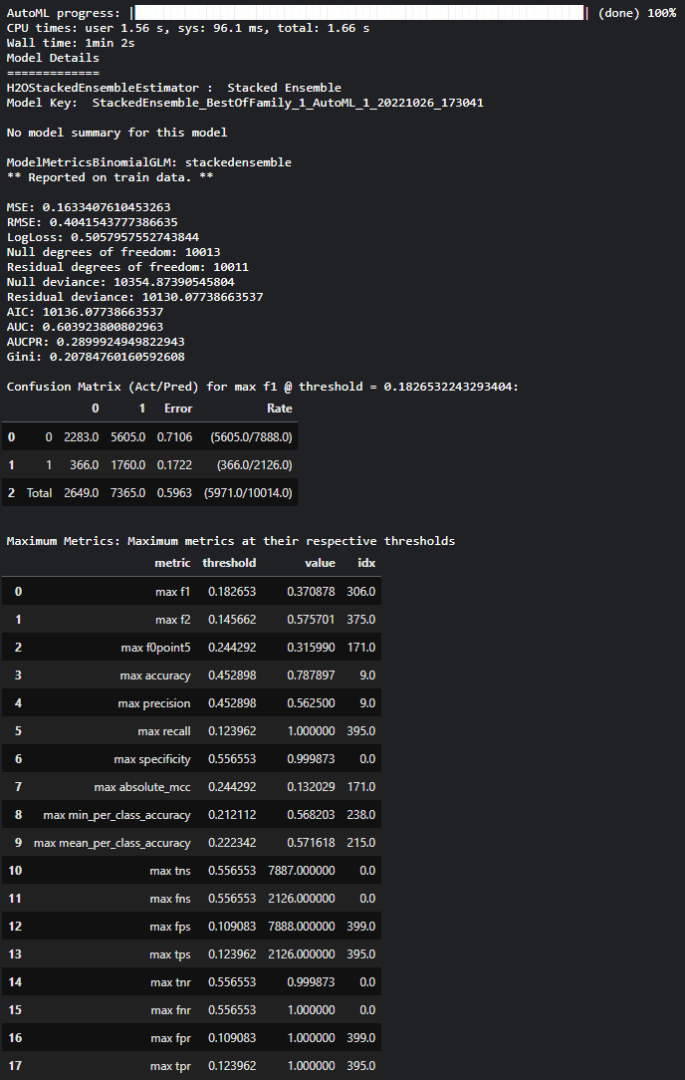
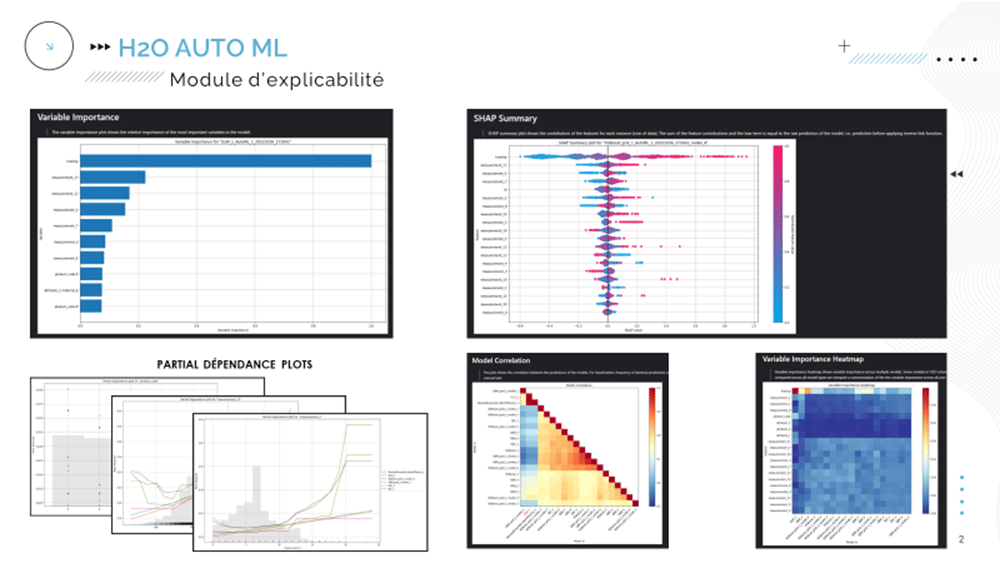
Une fois l’entraînement terminé, des informations sur le modèle vainqueur sont affichées :
Informations de base sur le modèle : nom, typologie, paramètres, … Dans notre cas, il s’agit d’un ensemble de plusieurs modèles et l’ensemble des paramètres n’est pas affiché (disponible via une commande supplémentaire)
Un listing des performances du modèle : matrice de confusion, métriques de classification (voir ci-dessous)
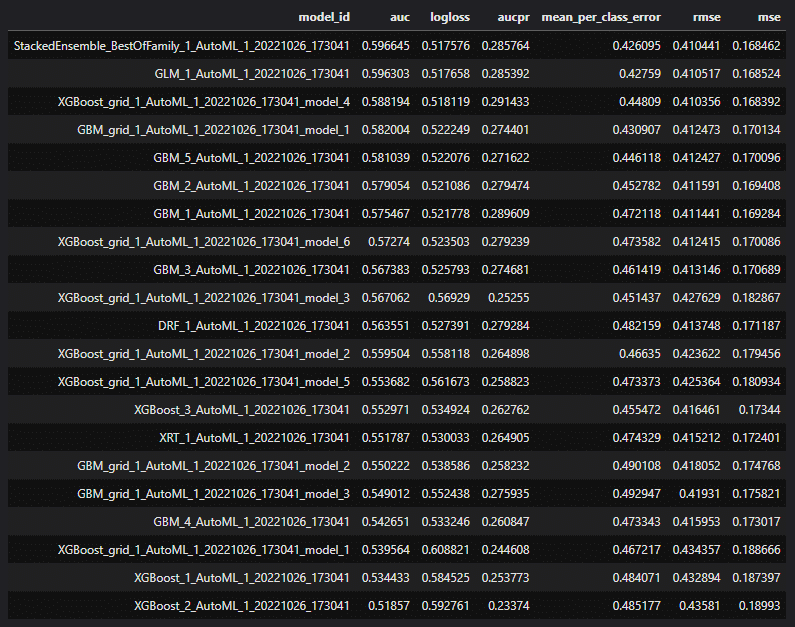
Il est également possible d’avoir accès au « leaderboard » des modèles entrainés et testés : identifiant, performances, temps d’entrainement et de prédiction, typologies des modèles (ensembles, gradient boosting, …) .
Informations modèle leader
Leaderboard
Enfin, le module d’explicabilité (restreinte…) nous permet d’obtenir des informations sur l’importance globale des variables dans les décisions du modèle, ainsi que l’importance globale des variables par modèle entraîné / testé, des graphes de dépendance partielle, une représentation des valeurs de SHAP des variables, … Il est également possible d’obtenir des explications locales sur des prédictions données.
En définitive, H2o AutoML permet d’expérimenter rapidement sur un cas d’usage donné, permettant par exemple de valider l’intérêt d’une approche par Machine Learning. Pour autant, dans notre cas précis, le modèle vainqueur constitue un assemblage complexe de plusieurs modèles non clairement spécifiés (il faut chercher…longtemps !) et cette complexité et ce manque de transparence peuvent en premier lieu rebuter les utilisateurs.
En définitive, l’Auto-ML signe-t-il vraiment la fin du Data Scientist ?
Le succès futur de cette technologie repose aujourd’hui sur les progrès à venir en matière d’apprentissage par renforcement, discipline qui peine aujourd’hui à percer et convaincre dans le monde professionnel. L’explicabilité et la transparence sont également des challenges à relever par cette technologie pour accélérer son adoption.
Mais de toute évidence, l’Auto-ML s’inscrira durablement dans le paysage IA des années à venir.
Quant au data scientist, il est certain que la profession telle que nous la connaissons va être amenée à évoluer. Nouvelle au début des années 2010, comme tous les métiers depuis et selon les organisations, leurs profils et activités vont évoluer.
D’un côté, des profils data scientists plus « business » et moins « tech » vont certainement se dégager se concentrant sur des échanges avec les métiers et la compréhension fine du fonctionnement et des enjeux des organisations. On peut d’ores et déjà voir que ces profils émergent des équipes business elles-mêmes : les fameux citizen data scientists. Ces derniers seront très certainement des fervents utilisateurs des outils d’AutoML.
Également, des profils hybrides data scientist – engineer se multiplient aujourd’hui, ajoutant aux activités classiques de data science la mise en place de pipelines d’alimentation en données et l’exposition des résultats et prédictions sous un format packagé (API, web app, …). L’ère du Machine Learning Engineer a déjà démarré !
Les autres articles qui vont vous intéresser
Cadrer la conformité et répondre aux exigences du RGPD
Cadrer la conformité et répondre aux exigences du RGPD
Mai 2018, l’entrée en application du RGPD a pris plusieurs entreprises de court. Nous accompagnons donc dans cette société de gestion d’actifs afin d’effectuer un cadrage de sa conformité RGPD et d’accompagner les premières actions de mise en règle. Nous intervenons dans cette société pour la Direction de la Conformité et en action conjointe avec la DSI.
Notre valeur
Notre approche par « Produits » nous a permis d’apporter, dès le démarrage de la mission, des contenus prêts à l’emploi tels qu’un flyer de sensibilisation au RGPD, une formation à dispenser à tous les collaborateurs ainsi que des questionnaires et templates permettant l’identification et la description des traitements de données personnelles et des procédures de réponse aux droits des personnes.
Pour ce cadrage RGPD, nous avons accompagné cette société selon trois axes :
Un premier centré sur la gouvernance globale du sujet RGPD dans l’entreprise, en menant plusieurs sessions de formation obligatoires afin de sensibiliser l’ensemble du personnel. Nous avons également défini, en collaboration avec la Direction, un modèle de gouvernance du RGPD.
Le second axe fut de collecter les traitements de données personnelles en place dans l’entreprise. Pour cela, nous avons effectué un premier travail d’identification via un questionnaire diffusé aux différentes entités métier. Nous avons poursuivi par des ateliers spécifiques afin de caractériser plus précisément les traitements collectés, que nous avons répertorié dans un template de registre pré-construit, disposant de mécanismes d’alertes en fonction des caractéristiques déclarées du traitement, facilitant ainsi la mise en conformité. Nous avons conclu l’axe “traitements” en branchant une data-visualisation sur le registre des traitements constitué, servant de reporting pour le top management.
Enfin, nous avons contribué à la définition de procédures normées de réponse à l’exercice de droits des personnes et assisté les services concernés à la rédaction de notices d’information à destination des employés et des candidats au recrutement.
Bénéfices
Nos différents objectifs ont été atteints :
Sensibiliser 100% des effectifs à RGPD afin de faire de chacun un acteur de la conformité de la société,
Outiller un registre permettant une identification, saisie et description aisée des traitements de données personnelles en vigueur dans l’entreprise,
Rendre autonomes les acteurs concernés par l’exercice des procédures RGPD (droit à l’oubli, à la rectification, …)
Les autres success stories qui peuvent vous intéresser
Chaque année, le 28 janvier est la journée européenne de la protection des données. Et chaque année, cela peut rappeler à beaucoup de gestionnaires de plateforme data clients que cette dernière n’est toujours pas totalement conforme aux lois de la RGPD.
La CNIL nous rappelle qu’une non mise en conformité RGPD de vos data clients peut entraîner des sanctions pécuniaires pouvant par ailleurs être rendues publiques.
Si c’est votre cas, rassurez-vous, nous avons formalisé pour vous une vidéo qui vous guidera vers la mise en conformité RGPD de vos plateformes data clients. Par plateforme data clients, nous entendons ici référentiels clients, base CRM ou encore plateformes décisionnelles indépendamment des technologies utilisées.
Ces étapes reposent sur 3 principes clés :
La minimisation de la collecte et sécurisation de l’accès aux données personnelles
Le respect des droits des personnes
La maîtrise des durées de conservation des données
Voici les 5 étapes de mise en conformité de votre plateforme data clients
Etape 1
Il faut effectuer une classification pérenne des données, personnelles ou non, validée par la conformité ou le service s’y apparentant et associée à un stockage logique différent. On peut imaginer ici un système de coffre-fort qui contiendrait les données personnelles en y limitant l’accès.
Etape 2
Il est nécessaire de mettre en place un système d’habilitation robuste et une exposition de ces données personnelles selon des finalités pertinentes et bien définies. Tout cela afin d’en cadrer l’utilisation.
Etape 3
Vous devez poser des procédures de gestion automatisée des droits des personnes. Il faut par exemple être capable d’effectuer de manière rapide et efficace, le traitement d’une demande de droit à l’oubli d’un client. Cela doit être applicable sur la totalité de la chaine de traitement de l’information.
Etape 4
Il vous faut paramétrer l’exécution de purges automatiques permettant de respecter les durées réglementaires de conservation des données personnelles. Ce sujet est toujours délicat puisqu’il n’existe à ce jour pas de référentiel européen ni même national des durées de conservation. Il est donc sujet à interprétation. On recommande toutefois de mettre en place des durées de conservation raisonnables, en phase avec la finalité métier du traitement de données personnelles.
Etape 5
Enfin, cinquième et dernière étape : il faut mettre en place une supervision sur la totalité de la chaine de traitement de la donnée personnelle, afin d’être alerté d’une éventuelle data breach pouvant mener à une perte ou un vol de données personnelles. Dans ce cas là, le client doit être prévenu rapidement.
Renforcez la gouvernance de vos données avec nos Experts Data
Des algorithmes biaisés
Des algorithmes biaisés
Algorithmes racistes, sexistes… les biais algorithmiques sont un risque pour la confiance envers le recours à l’intelligence artificielle. En quoi consistent-ils ?
Le 8 Avril dernier, le ‘High Level Expert Group on AI’, sorte d’Avengers de l’Intelligence Artificielle dépêchés par la commission Européenne, présentait ses recommandations en matière d’éthique de l’IA. Basé sur une consultation publique ayant recueilli plus de 500 commentaires, ce rapport pointe, entre autres, le sujet du biais algorithmique et met en garde les acteurs de l’IA sur les conséquences négatives que ce dernier peut entraîner, de la marginalisation des minorités vulnérables à l’exacerbation des préjugés et des discriminations. Il présente ainsi les systèmes d’IA comme devant être de véritables acteurs de la diversité en impliquant dans leur développement la totalité des parties prenantes.
Des algorithmes racistes ?
Il y a aujourd’hui quelques années, Propublica, média indépendant d’investigation américain, publiait une étude simplement intitulée “Machine Bias”. Son message : C.O.M.P.A.S. (pour Correctional Offender Management Profiling for Alternative Sanctions), un algorithme largement utilisé dans les cours de justice américaines, serait racialement biaisé, avec pour effet de désigner comme potentiels récidivistes un trop grand nombre de personnes noires. Par la suite, l’expérience a démontré que le nombre de faux positifs chez la population noire était bien plus élevé que celui constaté du côté de la population blanche, comme relaté ci-dessous :
Tim Brennan, professeur de statistiques à l’université et co-fondateur de l’algorithme C.O.M.P.A.S., expliquait déjà que le concept de ‘race’ était selon lui difficile à complètement exclure du calcul de score, car également corrélé à des indicateurs indispensables pour l’algorithme tels que le niveau de pauvreté du prévenu, le taux de chômage constaté dans son quartier, … Retirer également ce type de données du calcul de score entraînerait selon lui une chute de la précision du prédicteur, précision alors quantifiée à 68% (précision : nombre de véritables récidivistes / nombre de récidivistes désignés). En aparté, on s’interroge déjà sur cette valeur qui, en pratique, image le fait qu’une personne analysée sur 3 serait désignée comme récidiviste, à tort. Même si les cours pénales américaines n’appliquent pas à la lettre le résultat de l’algorithme, on imagine bien l’influence de ce dernier concernant la décision finale…
Une manière simplifiée d’expliciter un algorithme serait de le décrire comme une liste finie d’instructions s’enchaînant selon des conditions logiques, produisant potentiellement une sortie en fonction d’aucune, une ou plusieurs entrées. Ainsi, peuvent être considérés comme algorithmes une recette de cuisine, un itinéraire GPS ou un ensemble d’instructions médicales. Appliqués au monde informatique, on peut les qualifier d’algorithmes numériques, transformant une ou plusieurs données d’entrée en une ou plusieurs sorties numériques. Ainsi, une simple formule qui, en considérant l’âge, le statut de fumeur, la pression artérielle et quelques autres caractéristiques d’un individu afin de prédire un risque d’AVC est un algorithme.
De manière plus précise, les algorithmes que nous adresserons dans cette suite d’articles sont ceux relatifs au machine learning, littéralement « apprentissage machine ». Soit la capacité pour un programme d’apprendre d’expériences passées pour anticiper des événements futurs. Nous nous focaliserons sur les algorithmes supervisés : ils ont besoin d’un grand nombre d’exemples en entrée pour pouvoir exercer sur une nouvelle situation ou événement à prédire. On retrouve tout un ensemble de situations où l’apprentissage supervisé est utile : reconnaître des personnes sur une photo, filtrer des spams dans une messagerie ou encore prévenir d’un risque de défaut de remboursement de crédit.
Le phénomène de biais, quant à lui, peut prendre plusieurs significations selon le contexte dans lequel il est nommé. Nous nous concentrerons ici sur les définitions englobées dans le spectre “statistiques appliquées”, mais il faut savoir que ce terme, en plus d’être le nom de bourgades du Lot-Et-Garonne et de la Virginie Occidentale, est applicable à de nombreux domaines (électronique, psychologie, …).
De manière non exhaustive, en statistiques appliquées, ce biais peut être de plusieurs types :
biais d’échantillonnage (données en entrée non représentatives de la réalité),
biais de mesure (mesurer un résultat selon tel ou tel indicateur),
biais d’auto-complaisance ou de publication (directement lié au biais cognitifs humains, le fait de ne publier des résultats que s’ils sont en accord avec ses propres croyances personnelles),
et bien d’autres…
Quel rapport avec les systèmes d’IA ? Eh bien ce sont ces biais statistiques qui se trouveront exprimés dans les modèles, du fait de la sélection des données d’entrée, de l’expression plus ou moins marquée de certains features du modèle ou encore de l’interprétation des résultats. C’est ainsi que, fonctionnellement, des algorithmes peuvent “accoucher” de résultats fonctionnellement biaisés : biais raciaux, de genre, d’âge, …
Le risque ?
De plus en plus de décisions sont aujourd’hui prises par des algorithmes. De l’analyse automatique des CV à celle des dossiers de demande de prêts, de l’ordre des publications sur un réseau social à la liste de publicités affichées sur le net, ces algorithmes prennent une place de plus en plus importante dans nos vies quotidiennes. C’est pourquoi y inclure, volontairement ou non, des biais de toute sorte représente un danger important. Il est certain que ces décisions, autrefois prises par des humains, étaient déjà sujettes aux différents biais cognitifs. Mais c’est bien l’industrialisation de ces biais qui pose le problème.
Big data doesn’t eliminate bias, we’re just camouflaging it with technology
Cathy O’ Neil
En considérant un algorithme, régi par des préceptes mathématiques, on pourrait penser que ce dernier est objectif par définition et dénué des biais qui peuvent affecter les décisions humaines. C’est le principe du MATHWASHING, derrière lequel beaucoup de décisions algorithmiques ont été dissimulées.
Mais alors pourquoi cette objectivité algorithmique et mathématique serait-elle une illusion ?
Les algorithmes sont conçus par des humains
Leurs créateurs sont en charge de décisions structurantes telles que le périmètre de données à utiliser, les éventuels poids attribués à ces données, … Et, par définition, les décisions humaines sont biaisées, volontairement ou non. Par exemple, utiliser des données de genre pour déterminer quelles annonces d’emploi mettre en avant sur la page LinkedIn d’un individu a eu pour effet de recommander, en moyenne, des offres moins rémunérées pour les utilisatrices.
Les données en entrée sont également subjectives
Les algorithmes traitent les données qu’on leur présente en entrée. Ni plus, ni moins, sans avoir la possibilité d’évaluer leur caractère biaisé. En effet, les données reflètent toutes sortes de biais sociétaux bien ancrés, en plus d’en perpétrer des anciens. Quid de l’utilisation de données raciales dans un pays qui prônait la ségrégation raciale un demi-siècle plus tôt ? Quid de l’éradication du pay gap quand la plupart des données utilisées pour entraîner les algorithmes reflètent ce problème majeur de société comme une situation normale, ou au moins nominale.
Ainsi, cette amplification du biais peut être accidentelle (utilisation involontaire de données biaisées) mais également réalisée en toute connaissance de cause et d’effet, soit dans un but de manipulation de la décision algorithmique (ex : design de la ‘Gerrymandering map’ optimale), soit encore dans une optique de dé-responsabilisation : l’algorithme encaisse ainsi la responsabilité des décisions biaisées prises par les humains sur son bon conseil.
En résumé,
Ces considérations viennent alimenter un spectre plus large de problématiques relatives à l’éthique de l’IA. Il va sans dire que l’explicabilité de l’IA est un défi pour la suite de l’ère IA dans laquelle nous sommes entrés depuis quelques années. On connaissait le problème classique d’éthique de l’IA imagé par le MIT sur son site ‘Moral Machine’. Celui-ci permet, à l’aide d’une mise en situation, de sensibiliser les utilisateurs aux choix difficiles effectués par les IA embarquées dans les voitures autonomes. Dans le même esprit, myGoodness interroge sur l’attribution de sommes d’argent à des causes humanitaires ou avec objectif d’enrichissement personnel.
L’utilisation d’algorithmes d’intelligence artificielle est une forte opportunité de progrès technologique, et ce de manière très transverse. Toutefois, une perte globale de confiance en leurs résultats pourraient entraîner ce pan important de la recherche dans un nouvel hiver de l’IA si jamais leur caractère objectif venait à être décrié et leurs biais prouvés. Il en va donc de la responsabilité de leurs créateurs d’en faciliter la transparence, de leurs utilisateurs d’en vérifier l’accord avec les lois et de la totalité de la population d’exercer une pensée critique vis à vis des résultats obtenus.
Comprendre la limite des algorithmes aidera à juger leurs recommandations. De par leur définition, données et algorithmes réduisent une réalité complexe à une vision plus simple du monde. Seules les parties mesurables de cette vision devraient être utilisées. Il convient ainsi d’éviter la religion de l’algorithme et la vision réductrice inhérente, en gardant des décideurs humains dans la boucle du choix.
Dans une seconde partie, nous nous concentrerons sur les différentes approches existantes permettant de réduire voire d’éradiquer ces biais algorithmiques, pour des systèmes aux décisions plus justes et peut-être un jour réellement objectives…
Note : l’étude menée par Propublica sera par la suite fortement contestée par une étude gouvernementale. Indépendamment de la véracité des résultats, Propublica aura mis sur la table le sujet du biais algorithmique et l’aura rendu compréhensible (à minima accessible) au plus grand nombre.
Data scientist, data analyst, data cruncher,… ces dernières années, le nombre d’intitulés de postes relatifs au traitement, et plus particulièrement à l’analyse, de données a explosé.
Data scientist, data analyst, data cruncher,… ces dernières années, le nombre d’intitulés de postes relatifs au traitement, et plus particulièrement à l’analyse, de données a explosé. On constate également la popularité croissante des compétences inhérentes à ces postes via divers tops ‘in-demand skills’, publiés annuellement sur LinkedIn. Ces postes ont tous une compétence requise en commun, l’analyse de données, aujourd’hui jugée primordiale dans le monde professionnel par le cabinet Gartner, jusqu’à l’élever au rang de norme.
Mais ne sommes-nous pas déjà entrés dans une nouvelle époque, durant laquelle les composantes basiques de ces compétences vont peu à peu migrer dans le ‘savoir commun’ et devenir des pré-requis pour un scope plus large de métiers ? Ne sommes-nous pas entrés dans l’ère de la ‘data democratization’ ?
Pourquoi une explosion de de la demande relative à ces compétences ?
A l’heure où plus de la moitié de l’Humanité a quotidiennement accès à Internet et où 90% des données disponibles ont été créées dans les deux dernières années, toute entreprise collecte et stocke une quantité importante de ces données. De formats et types variés, ces dernières sont également transversalement issues de la totalité des métiers de l’organisation. Les capacités de traitement (stockage et puissance de calcul, ‘asservis’ à la loi de Moore depuis des décennies) ont elles aussi explosé, passant d’un statut de facteur limitant à celui de non-sujet.
Traditionnellement, ces données étaient propriétés de la DSI. Certes, les décisions des BU métiers et du top management s’appuyaient déjà sur ces données. On ne pouvait toutefois pas se passer d’un intermédiaire pour leur consultation et traitement, augmentant les risques de non compréhension de la donnée ainsi que les temps de traitement des demandes. Aujourd’hui, de plus en plus d’organisations transversalisent leur entité ‘data’, afin de rapprocher les données des métiers, porteurs de la connaissance de la donnée, et des usages, délivreurs de valeur.
Car il est évident que, bien qu’elle soit complexe à déterminer précisément et instantanément, la donnée a une valeur évidente qu’il convient d’exploiter. Pour cela, une capacité d’analyse, plus ou moins poussée, est nécessaire à tous les niveaux de l’entreprise, au plus proche de la donnée et ce pour ne pas en perdre la signification.
Mais il existe encore des freins à cette démocratisation. En entreprise, le nouvel analyste peut se heurter à une mauvaise compréhension de la donnée. Même si la tendance est au partage et à la “transversalisation”, les données sont encore parfois stockées et gérées en silo, rendant difficile l’accès et la transparence de la signification métier de cette donnée.
Mais multiplier les analystes peut aussi représenter un risque de multiplier les analyses…identiques. Aussi, un sujet apparaît lorsque la donnée est rendue accessible plus largement : celui de la protection des données personnelles, récemment encadré par la nouvelle réglementation GDPR. En effet, la finalité d’un traitement de données doit aujourd’hui être systématiquement précisée, tout comme la population de personnes accédant aux données en question. Cette dernière doit par ailleurs être réduite au strict minimum et justifiable.
Cette data democratization est donc porteuse, dans le monde de l’entreprise, d’un message supplémentaire : une gouvernance bien établie agrémentée d’une communication efficace sont nécessaires et catalyseront la démocratisation.
Et concrètement, analyser des données ?
Avant toute chose…
Il existe une règle d’or dans le monde de l’analyse de données et elle s’appliquera également aux nouveaux analystes issus de la data democratization. Cette règle, éprouvée et vérifiée, stipule qu’en moyenne 80% du temps effectif d’un analyste sera consommé par la collecte, le nettoyage l’organisation et la consolidation des données, ne laissant que les 20% restants pour les analyser et en tirer de la valeur. Il faut donc que les nouveaux analystes prennent conscience de cette contrainte et aient une base de connaissances sur les réflexes de vérification à avoir lors de la réception d’une nouvelle source de données.
Visualiser
On peut définir la visualisation de données (ou dataviz) comme une exploration visuelle et interactive de données et leur représentation graphique, indépendamment de leur volumétrie, nature (structurées ou non) ou origine. La visualisation aide à percevoir des choses non évidentes en premier lieu, répondant à deux enjeux majeurs du monde de l’entreprise : la prise de décision et la communication.
Mais attention, un graphique mal utilisé peut faire passer un message erroné, laisser percevoir une tendance peu fiable ou maquiller une réalité. C’est donc pour cela qu’il convient de donner à tous une base méthodologique permettant d’exploiter la puissance de la dataviz tout en évitant les écueils.
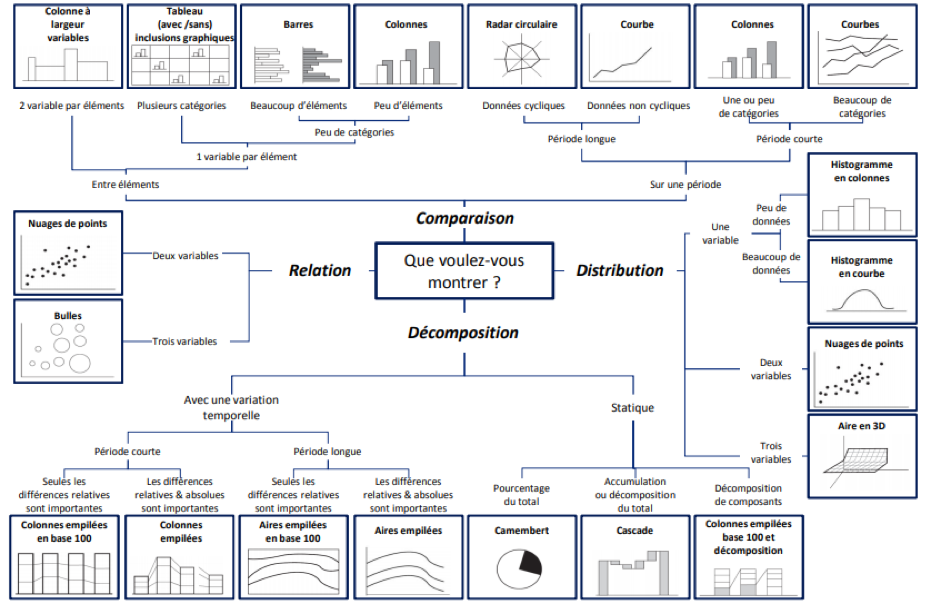
La force de la visualisation réside en l’aperçu instantané qu’elle permet d’avoir sur une large quantité de données, pour peu que son créateur ait fait le bon choix de représentation. Plusieurs paramètres sont à considérer lorsque l’on souhaite choisir une visualisation : quel phénomène je souhaite mettre en évidence ? de combien de variables ai-je affaire ? ma représentation doit-elle être continue ou discrète ? …
Ci-dessous, une cheatsheet sous forme de visualisation, avec pour thème : “Quel type de graphe pour quel usage ?”
Avec quels outils, pour commencer ?
Une des raisons d’occurrence de cette ‘data democratization’ est l’émergence de technologies facilitatrices, permettant à un plus grand nombre d’interagir avec les données, à l’aide de frameworks de code ou d’interfaces graphiques accueillantes pour une expérience guidée et visuelle :
Logiciels de ‘data federation’ et dataviz : des interfaces graphiques simples, guidant la manipulation de l’import des données de formats et de sources différentes jusqu’à leur visualisation, intégration dans des dashboards et publication de rapports. On peut citer les solutions leaders du marché : Tableau Software, QlikView, Microsoft Power BI,…
Solutions “all included” et plateformes : dans une unique application, la possibilité est donnée de mener des analyses automatiques jusqu’à de la modélisation complexe, le tout sans avoir à toucher (ou peu) une ligne de code (exemples de solutions : IBM Watson Analytics, Dataiku, Saagie,…)
Frameworks et librairies : s’adressant à un public plus averti, il s’agit là de fonctions et méthodes prêtes à être ré-utilisées et adressant des problématiques et utilisation bien particulières (exemples : librairies NumPy et Pandas en Python pour faciliter la manipulation de données, librairie D3js en JavaScript pour la dataviz, …)
Mais il est toutefois un outil encore très majoritairement utilisé pour des cas simples de reporting, visualisation, agrégation et modélisation simple. Il s’agit du tableur on-ne-peut-plus-classique : Excel et l’ensemble de sa cour d’alternatives (GSheets, LibreOffice Calc,…). Et il est évident que l’on ne peut pas parler de démocratisation sans citer cet outil.
L’utilisation du tableur est aujourd’hui un pré-requis pour un grand nombre de métiers, dont certains sans aucun rapport à l’informatique. Aussi, le niveau de compétence en la matière n’a fait que s’élever d’années en années et c’est une tendance qu’il convient d’accompagner. De son côté, Microsoft ne cesse d’enrichir les fonctionnalités et, paradoxalement, de simplifier l’utilisation de son outil, en ajoutant des suggestions basées sur une analyse intelligente des contenus.
Notre conviction
Bien que nous n’ayons aujourd’hui pas le recul pour l’affirmer, on peut avoir bon espoir que cette démocratisation révolutionne la prise de décision en entreprise, en permettant aux employés à tous les niveaux de l’organisation d’avoir accès à des données et d’en tirer conclusions, plans d’action et projections.
Et nous pouvons espérer que cette démocratisation ne se cantonne pas au périmètre de l’entreprise traditionnelle : quid du travailleur indépendant, du petit commerçant ou du restaurateur ? Il est évident que ces individus également, dans l’exercice de leur activité, génèrent ou reçoivent des données qu’ils pourraient exploiter et valoriser (optimisation des stocks, analyses de résultats,…). Pour ces professionnels, un minimum de compétence internalisée mènerait à des économies en prestations et en temps passé, mais également à un éventuel ROI issu de l’analyse et de l’exploitation de leurs données.
Forts de ces constats, nous nous sommes aujourd’hui forgé la conviction suivante :