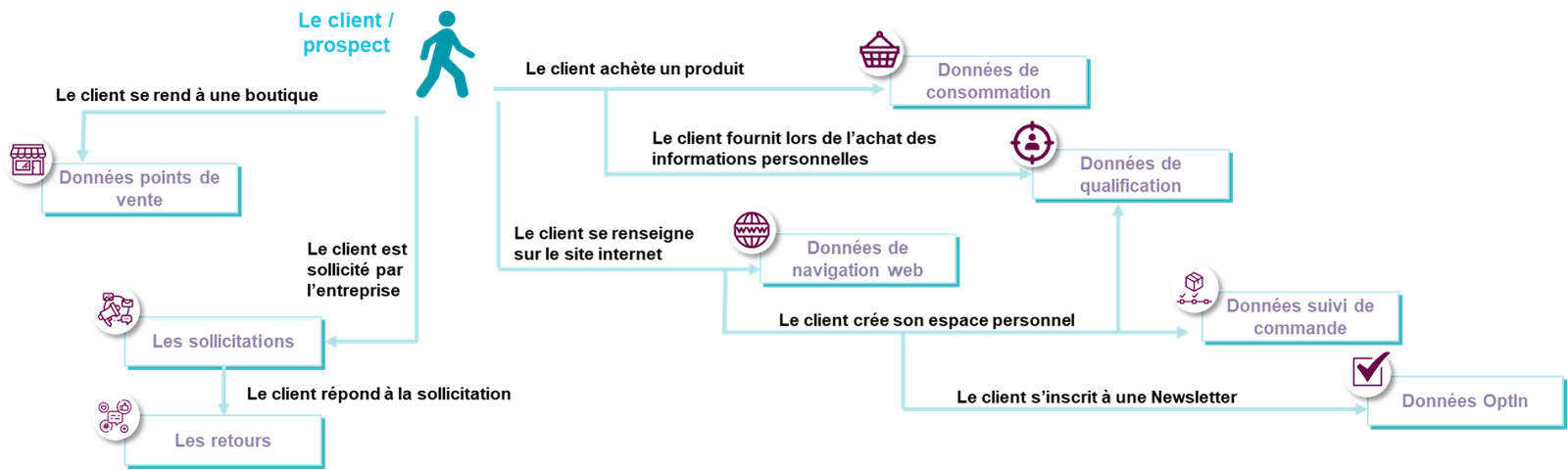
L’Open Data est un concept qui repose sur la mise à disposition libre et gratuite de données. Cela va permettre leur consultation, leur réutilisation, leur partage. C’est aujourd’hui un enjeu majeur pour la transparence gouvernementale, l’innovation et le développement économique.
Nous allons explorer ce qu’est l’Open Data, son contexte légal et son obligation pour certains acteurs publics. Mais aussi les pratiques de mutualisation de données hybrides telles que le data sharing et les plateformes data.
Enfin, nous aborderons les enjeux organisationnels et techniques nécessaires à prendre en compte avant de se lancer dans une telle démarche.
Qu’est-ce que l’Open Data ?
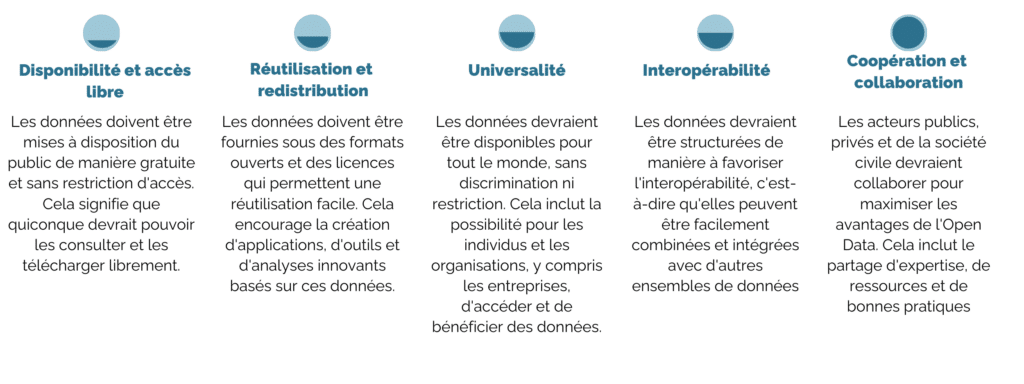
Tout d’abord, l’Open Data se caractérise, entre autres, par les principes suivants :
L’Open Data et la loi
Image générée automatiquement / Midjourney: A judge in a tribunal, surrounded by datas in assembly.
En France, l’Open Data a été promu par la Loi pour une République Numérique, adoptée en octobre 2016. Cette loi impose aux administrations publiques de publier certaines catégories de données de manière ouverte, à moins que des exceptions ne s’appliquent. Ces données incluent les données relatives aux marchés publics, aux prestations et services publics, aux résultats électoraux, et bien d’autres.
Cette loi a modifié le paradigme de publication de l’Open Data. Avant, la publication était souvent conditionnée à une demande d’accès à l’administration, avec des modalités de refus spécifiques à chaque demande qui étaient encadrées par la Commission d’Accès aux Documents Administratifs (CADA). Dorénavant, la publication en Open Data devient la norme, et doit anticiper une éventuelle demande par un citoyen, une association.
Les administrations peuvent toujours choisir de ne pas publier certaines données, en justifiant par exemple que leur publication porterait atteinte à la sureté de l’Etat. Ou bien encore qu’une anonymisation des données personnelles serait un effort disproportionné ou qu’elle dénaturerait le sens des données. Il convient de préciser que la publication des documents est obligatoire uniquement pour les documents dits « achevés» (a atteint sa version finale, à date : les brouillons, documents de travail, notes préalables ne sont pas considérés comme des documents achevés), c’est à dire validés et n’ayant plus objet à évoluer.
Il est également important de noter que les articles L. 300-2 et L. 300-3 du CRPA précisent que les acteurs privés investis d’une mission de service publique sont également soumis à ces obligations de publication.
Quels usages de l’Open Data
Image générée automatiquement / MidJourney: An anthropomorphic computer ingesting data and creating charts and plots.
Un des principes de l’Open Data est de permettre le “re-use” des données, à des fins d’analyses simples ou croisées, à titre non lucratif ou commerciales.
Le site datagouv.fr permet d’inventorier toutes les réutilisations des données liées à un data set, par exemple pour le data set des parcelles et agricultures biologiques :
Sur la page « Parcelles en Agriculture Biologique (AB) déclarées à la PAC » comprenant les données issues des demandes d’aides de la Politique Agricole Commune entre 2019 et 2021, on peut trouver des utilisations de ces données par l’agence bio elle-même, par l’Institut Technique et Scientifique de l’Abeille et de la Pollinisation ou par des sociétés privées de cartographies.
Ces exemples montrent la diversité des réutilisations de données, aussi bien en termes de cas d’usage, que d’acteurs impliqués.
Autres pratiques de Mutualisation de Données
Outre l’Open Data dans le sens “Obligation légale” auprès des acteurs publics, on trouve aujourd’hui des formes hybrides qui font du partage de la donnée un sujet transverse :
Le Data Sharing
Le data sharing, ou partage de données, implique la collaboration entre différentes organisations pour partager leurs données. Par exemple, des acteurs économiques ayant un domaine d’activité similaire mais n’étant pas en concurrence directe (Verticalité de l’offre, Disparité géographique) peuvent mutualiser des donner afin d’optimiser leur R&D, ou leurs études commerciales.
Les Plateformes Data
Les plateformes data sont des infrastructures qui facilitent le stockage, la gestion et le partage de données. On les retrouve au sein de structures, qui souhaitent mutualiser le patrimoine de leurs services, voire de leurs filiales. Il s’agit souvent de créer un point de référence unique, standardisé et facilement accessible des données pour toutes les parties intéressées. Cette plateforme n’est applicable que dans certain cas de figure (plusieurs filiales d’un même groupe par exemple).
L’Open Data s’adresse donc à la fois à la sphère publique et aux acteurs privés de par les obligations légales. Mais aussi par adoption volontaire du principe, ou par exploitation de données mises en open data. Et avec les pratiques liées (plateformes de données, data sharing), on retrouve des enjeux et des risques communs.
Image générée automatiquement / MidJourney: Three books on a table, one of them is open, the two others are closed
Cet article est le premier d’une trilogie consacrée à l’Open Data, qui se conclura par les modes opératoires et les prérequis de réalisation. D’ici-là, le second tome fera office de prequel, en s’intéressant aux origines culturelles de l’Open Data, notamment l’Open Source.
Comme présenté dans la 1ère partie de la genèse du Mobile Money, depuis plus d’une décennie (voire 15 ans !), les populations africaines diversifient l’utilisation du téléphone portable en le faisant passer d’un outil de communication classique a un moyen de paiement digital.
Comme me l’a rappelé une collègue à la suite de mon premier article, nous continuons sans cesse d’assister à de véritables bonds technologiques sur le continent. Pourquoi ? Car les innovations apportent des réponses pragmatiques et orientées utilisateurs finaux dès leurs conceptions.
L’accès aux comptes bancaires n’étant pas aussi simple qu’en Occident, l’adage « Cash Is King » prend une autre dimension sur le continent Africain. A votre avis, comment un(e) client(e) paie son Attiéké sur le marché de Dantokpa (Cotonou, Benin) ?
Certainement pas en carte bancaire ! En cash… ou en Mobile Money !
Mais…
Comment ouvrir un compte ?
Comment faire une transaction ?
Quels types de services sont disponibles ?
STORY TIME – Asseyez-vous confortablement !
Pour mieux comprendre la suite, je vais vous demander de vous mettre dans les chaussures d’un Burkinabé (par exemple) vivant dans un village à plus de deux heures de Ouagadougou. Nous sommes en 2015…
Note : Je vous demande de penser ainsi pour vous faire changer votre point de vue et comprendre les enjeux auxquels les populations rurales (et urbaines) peuvent faire face. Sans ce changement de perspective, comprendre les besoins et les solutions innovantes africaines restera vain…
Chapitre 1 : Comment ouvrir un compte Mobile Money ?
Nombre de Comptes Mobile Money enregistrésGSMA, State Of The Industry 2022
Un compte Mobile Money est le plus souvent lié à un opérateur de téléphonie mobile (Orange, MTN, Airtel, Vodacom…). Ce dernier doit avoir obtenu un statut d’Opérateur de Mobile Money ou d’Émetteur de Monnaie Électronique (EME).
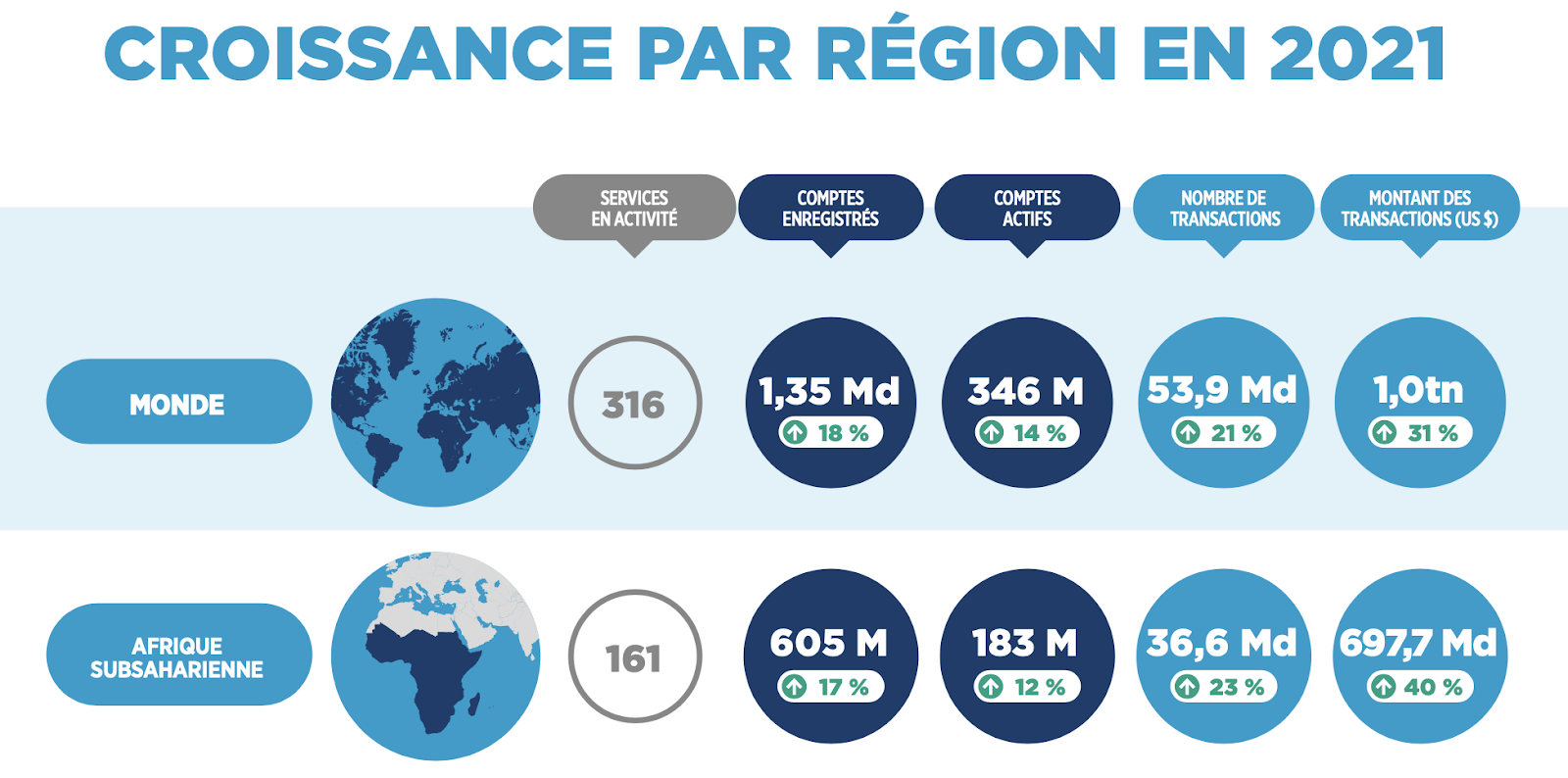
En tant que détenteur d’une ligne téléphonique, c’est grâce à mon numéro de téléphone que je deviens éligible à l’ouverture d’un (ou plusieurs) compte. En Afrique sub-saharienne, ce sont 605 millions de comptes enregistrés en 2022, soit +17% par rapport à 2021. Mais le plus incroyable, c’est que ces comptes représentent près de la moitié de ceux enregistrés dans le monde !
Pour l’ouverture de mon compte, je devrai remplir un formulaire papier ou, suivre une procédure plus digitale :
Dans une agence de mon opérateur téléphonique,
Auprès d’un promoteur terrain de mon opérateur,
Chez un distributeur agréé.
Arrêtons-nous là deux secondes. Un formulaire digital ? OUI ! Car pour ouvrir des comptes plus rapidement, une procédure dématérialisée existe. Soit par USSD, soit par application mobile (avec quelqu’un ou en totale autonomie). Nous parlions de bonds technologiques n’est ce pas ?
L’enregistrement est une étape clé dans la création d’un compte Mobile Money car durant cette phase, une procédure d’identification est réalisée (Know Your Customer ou, KYC). Or, qui dit moyen de paiement, dit identification client. Une identification obligatoire, suivie et contrôlée par la banque centrale du pays (ou de l’union monétaire et/ou économique dont le pays fait partie).
Banque Centrale des Etats de l’Afrique de l’Ouest (BCEAO) dans l’Afrique de l’Ouest
Central Bank of Nigeria (CBN) au Nigeria…
Le détenteur d’un compte se doit de justifier autant que possible son identité. Sans quoi, il ne pourra pas bénéficier pleinement des fonctionnalités du service.
Quelques exemples de restrictions :
Plafond sur le solde du compte (ex. impossible de détenir plus de X milliers de F CFA)
Restriction quant aux transferts de type personne-à-personne (#P2P ou #A2A)
Autre conséquence potentielle: la clôture du compte…
Une fois un compte ouvert, deux éléments seront demandées :
Définir un code secret pour sécuriser TOUTES les opérations Mobile Money;
Approvisionner le compte (ie. Avoir un solde me permettant de réaliser des opérations / transactions)
Nous pourrions parler longtemps de l’ouverture d’un compte Mobile Money. Mais, afin de ne pas vous perdre, je reviendrai dessus dans un article annexe. J’y aborderai les différents enjeux pour l’opérateur, pour le client et pour les marchands.
Chapitre 2 : comment faire une transaction mobile Money ?
Réponse : Depuis le menu USSD ou depuis mon application Mobile Money.
Le principe est simple, si vous n’avez pas d’argent sur votre compte (solde = 0) alors la transaction ne passera pas. C’est un point extrêmement important : la maison ne fait pas (ou peu) crédit.
Petit aparté en parlant “Crédit” : De plus en plus d’opérateurs de Mobile Money proposent des services de crédit mais ce n’est pas encore une norme. Cela demande un agrément bancaire particulier (type Établissement Bancaire (EB) ou encore Établissement de Crédit (EC)) plutôt long et coûteux à obtenir ! Sans évoquer les nombreux contrôles à réaliser une fois en activité. C’est d’ailleurs pour cela que les opérateurs préfèrent se lancer dans des partenariats plutôt que d’obtenir les agréments pour !
Revenons en aux transactions Mobile Money:
Si je n’ai pas de smartphone mais un FeaturePhone, cela signifie que je ne peux pas avoir accès à internet et donc pas d’application mobile. La transaction pourra donc être réalisée via un menu USSD et la validation de ma transaction se fera par code secret ;
Si j’ai un smartphone, j’aurai le choix d’utiliser le canal USSD ou une application mobile. La validation de ma transaction pourra se faire soit par code secret, soit par biométrie si mon téléphone propose ce type de fonctionnalités.
Les transactions Mobile Money sont comme des transactions bancaires : TOUTES ET TOUJOURS sécurisées ! Le débit du compte est quant à lui instantané.
Quels sont les différents types de transactions ?
Vous êtes toujours là ? A moitié n’est ce pas … mais continuons ensemble encore un petit peu. Aucune géographie ne voit ses services Mobile Money exploser de la même manière. Pourquoi ? Car « One size does not fit all » vous vous souvenez ?
Par exemple, en Guinée Conakry, c’est notamment la digitalisation du système de paiement des vignettes automobiles qui a aidé. Sur d’autres géographies, cela a pu être le paiement de facture d’électricité ou celui des certificats de naissance / mariage.
Opérations Mobile Money traitées en 2022 GSMA, State Of The Industry 2022
Mais, un bloc de services « clés » se distingue tout de même !
Le transfert d’argent de personne à personne (P2P ou A2A) > National et/ou Inter-régional
Le Dépôt et le Retrait d’argent (#CashIn / #CashOut)
L’Achat de crédit de communication pour soi ou pour un tiers (Crédit téléphonique ou data internet)
Ces trois types de service sont souvent considérés comme les « CoreServices » du Mobile Money car ils viennent répondre à des besoins de tous les jours. Enjeux qui reprennent 3 notions clés : Valeur Ajoutée, Facilité vs. Pénibilité & Gain de temps.
Plus besoin de donner de l’argent à un taxi ou à mon voisin qui repart à la capital > Je peux envoyer de l’argent ;
Je ne veux pas dormir sur mon argent (littéralement) > Je peux le déposer sur mon compte Mobile Money ;
Il est 2H du matin et tout est fermé autour de chez moi > Je peux payer mon abonnement Canal+ depuis mon canapé.
Vous êtes désormais au courant de comment les utilisateurs finaux peuvent ouvrir et utiliser leurs comptes Mobile Money. Il est temps pour nous de fermer cette – brève – genèse et de nous concentrer sur comment le Mobile Money peut aider les marchands nationaux et internationaux.
J’ai pu constater régulièrement que beaucoup de gens s’emmêlent les pinceaux quand il est question de définir et d’expliquer les différences entre Service Mesh, Event Mesh et Data Mesh.
Ces trois concepts, au-delà de l’utilisation du mot “Mesh”, n’ont pas grand chose de semblable. Quand d’un côté, nous avons :
Le Service Mesh qui est un pattern technique pour les microservices, qui se matérialise par la mise en place d’une plateforme qui aide les applications en ligne à mieux communiquer entre elles de manière fiable, sécurisée et efficace
L’Event Mesh, qui est un pattern technique d’échanges, afin de désiloter les différentes technologies de messaging
Et le Data Mesh qui lui, est un pattern général d’architecture de données, qui se matérialise par toute une série d’outils à mettre en place, et qui pousse le sujet de la productification de la donnée
On se dit déjà que comparer ces trois patterns ne fait pas sens ! Néanmoins, il y a peut-être un petit quelque chose, une évidence naturelle, qui peut découler de la comparaison.
Mais commençons donc d’abord par présenter nos trois protagonistes !
Le Service Mesh, ou la re-centralisation des fonctions régaliennes des microservices
Historiquement, l’approche microservice a été motivée, entre autres, par cette passion que nous autres informaticiens avons souvent, pour la décentralisation. Adieu horrible monolithe qui centralise tout, avec autant d’impacts que de nouvelles lignes de code, impossible à scaler en fonction des besoins fonctionnels réels. Sans compter qu’on peut quasiment avoir autant d’équipes de développement que de microservices ! A nous la scalabilité organisationnelle !
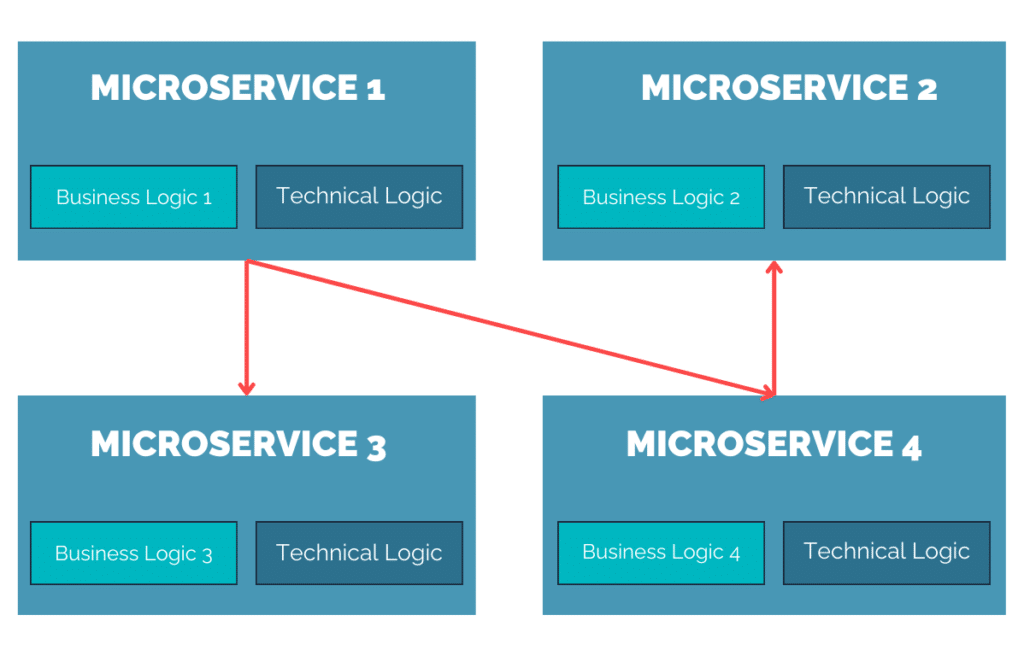
Cela a abouti, de manière simplifiée bien sûr, au schéma suivant :
Chaque microservice discute avec le micro service de son choix, indépendamment de toute considération. La liberté en somme ! Mais en y regardant de plus près, on voit bien une sous-brique qui est TRÈS commune à tous les microservices, ce que j’appelle ici la “Technical Logic”. Cette partie commune s’occupe des points suivants :
La découverte de services
La gestion du trafic
La gestion de tolérance aux pannes
La sécurité
Or quel intérêt à “exploser” cette partie en autant de microservices développés? Ne serait-ce pas plutôt une horreur à gérer en cas de mise à jour de cette partie? Et nous, les microserviciens (désolé pour le néologisme…), ne serions nous pas contradictoire dans nos souhaits de décentralisation? Oui! Car autant avoir une/des équipes dédiées à cette partie, qui travaillerait un peu de manière décentralisée, mais tout en centralisant sur elle-même ce point?
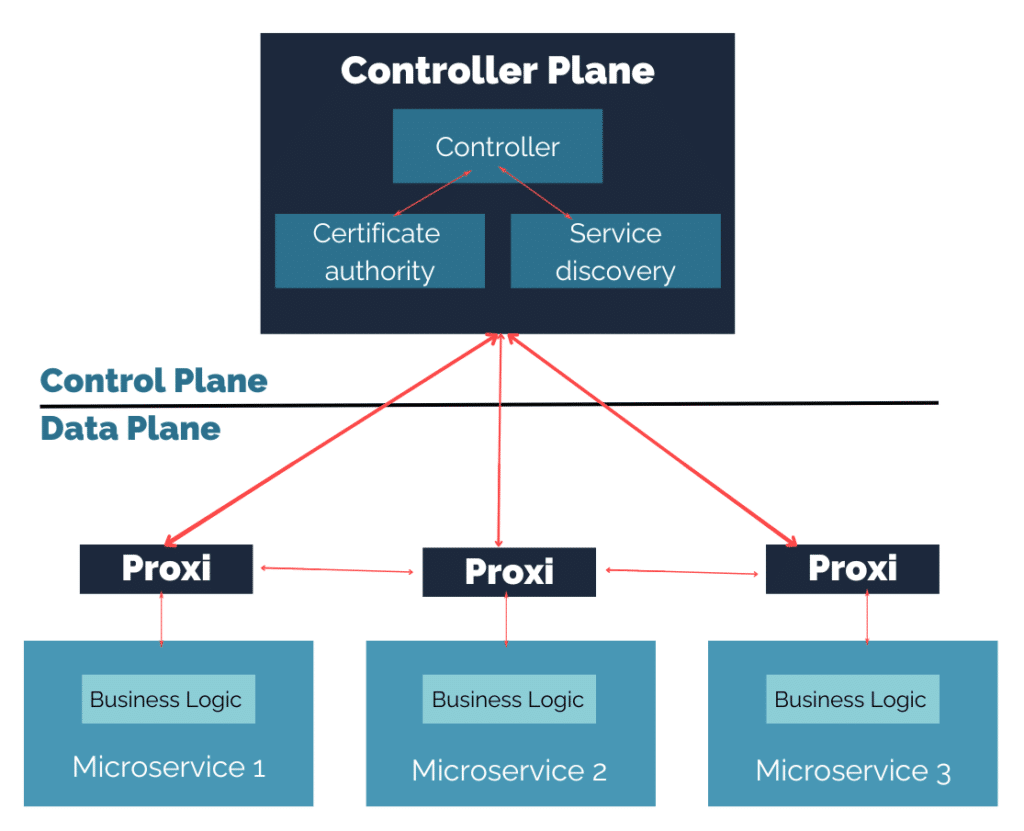
C’est ainsi qu’est apparu le pattern de Service Mesh, décrit dans le schéma suivant :
Dans ce pattern, les fonctions techniques sont définies de manière centralisée (Control Plane), mais déployées de manière décentralisée (Data Plane) afin de toujours plus découpler au final son architecture. Et cela se matérialise par des plateformes comme Consul ou Istio, mais aussi tout un tas d’autres plus ou moins compatibles avec votre clouder, voire propres à votre clouder.
Maintenant que nous avons apporté un premier niveau de définition pour le service mesh, allons donc voir du côté de l’Event Mesh !
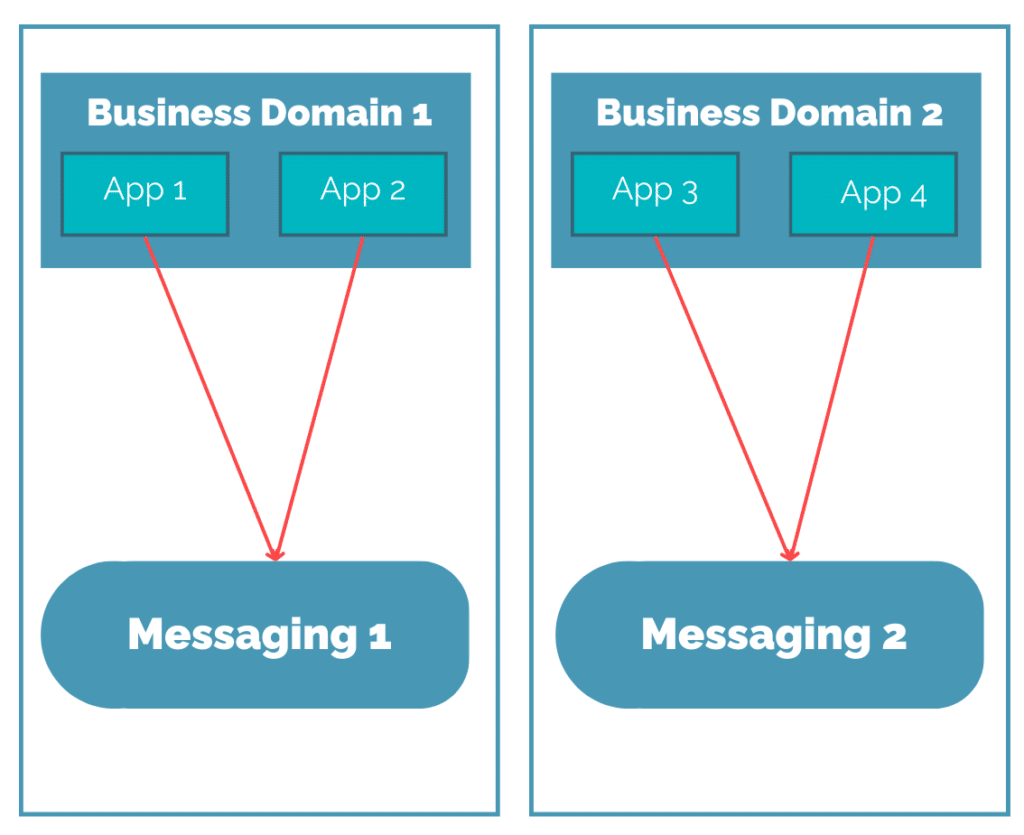
L’Event Mesh, ou la re-centralisation pour désiloter
L’histoire informatique a eu l’occasion de voir tout un ensemble de solutions de messaging différentes, avec des origines différentes. Qu’on retourne à l’époque des mainframes, ou qu’on regarde de côté des technologies comme Kafka qui ont “nourri” les plateformes Big Data, les solutions se sont multipliées. Et c’est sans compter le fait de faire du messaging par dessus du http!
On obtient donc assez facilement des silos applicatifs qui sont freinés dans leur capacité à échanger, comme montré sur le schéma suivant :
Certes, les solutions de bridge existaient, mais elles permettaient souvent de faire le pont entre seulement deux technologies en même temps, le tout avec des difficultés à la configuration et l’exploitation.
Et si on rajoute le fait qu’un certain nombre d’entreprises se sont dit qu’il serait intéressant d’utiliser les technologies propriétaires de chacun de leurs clouders, on imagine bien les difficultés auxquelles elles font face.
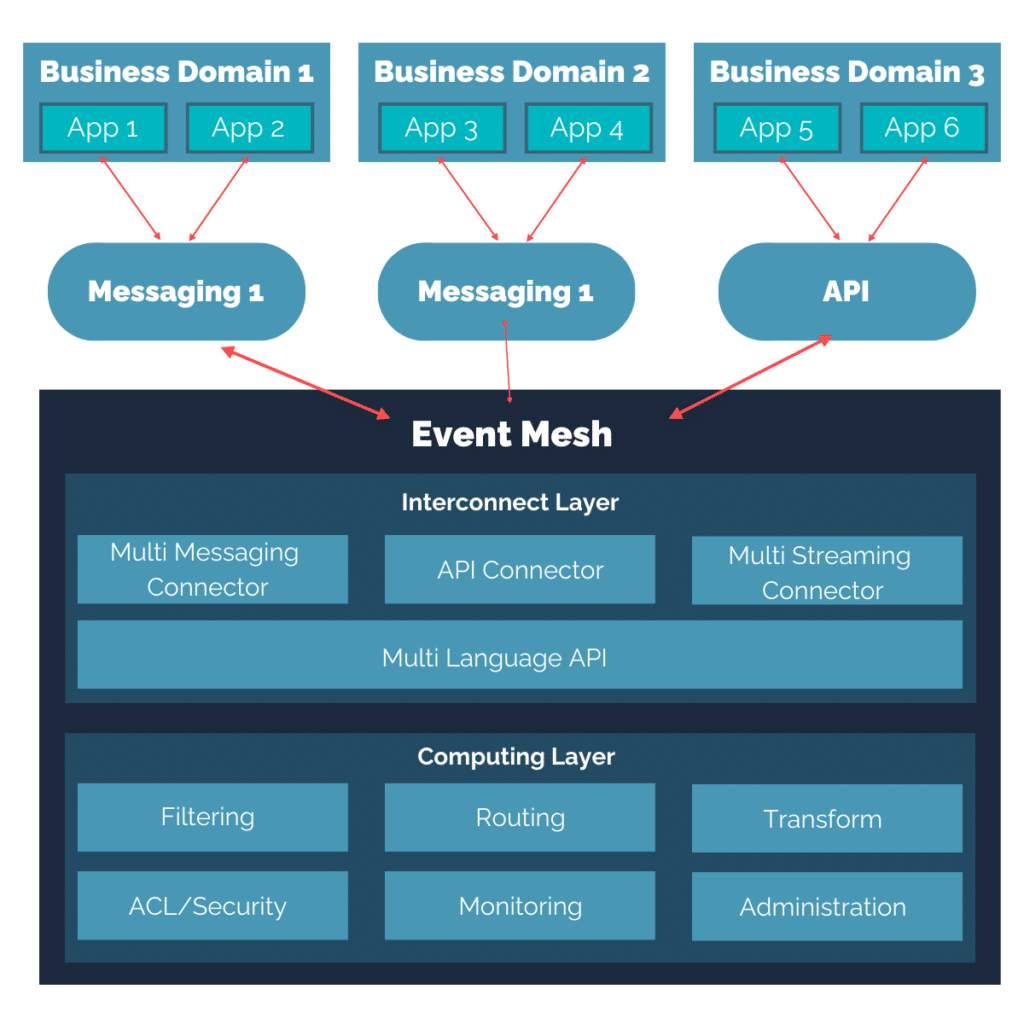
Est donc apparu le pattern Event Mesh, imaginé entre autre, implémenté et popularisé par l’éditeur Solace, qui permet de centraliser sur une solution unique, capable entre autres d’avoir des “agents” locaux aux SI (selon la zone réseau, le datacenter, le clouder, le domaine métier, etc…). Digression mise à part, on notera que le terme Event Mesh a été repris aussi bien par le Gartner que par des solutions open-source.
Indépendamment des architectures de déploiement, cela nous donne l’architecture simplifiée suivante :
Son intérêt vient qu’on peut ainsi relier tout le monde, y compris du Kafka avec du JMS, ou avec des API.
Le Data Mesh, décentralisation ou relocalisation des compétences ?
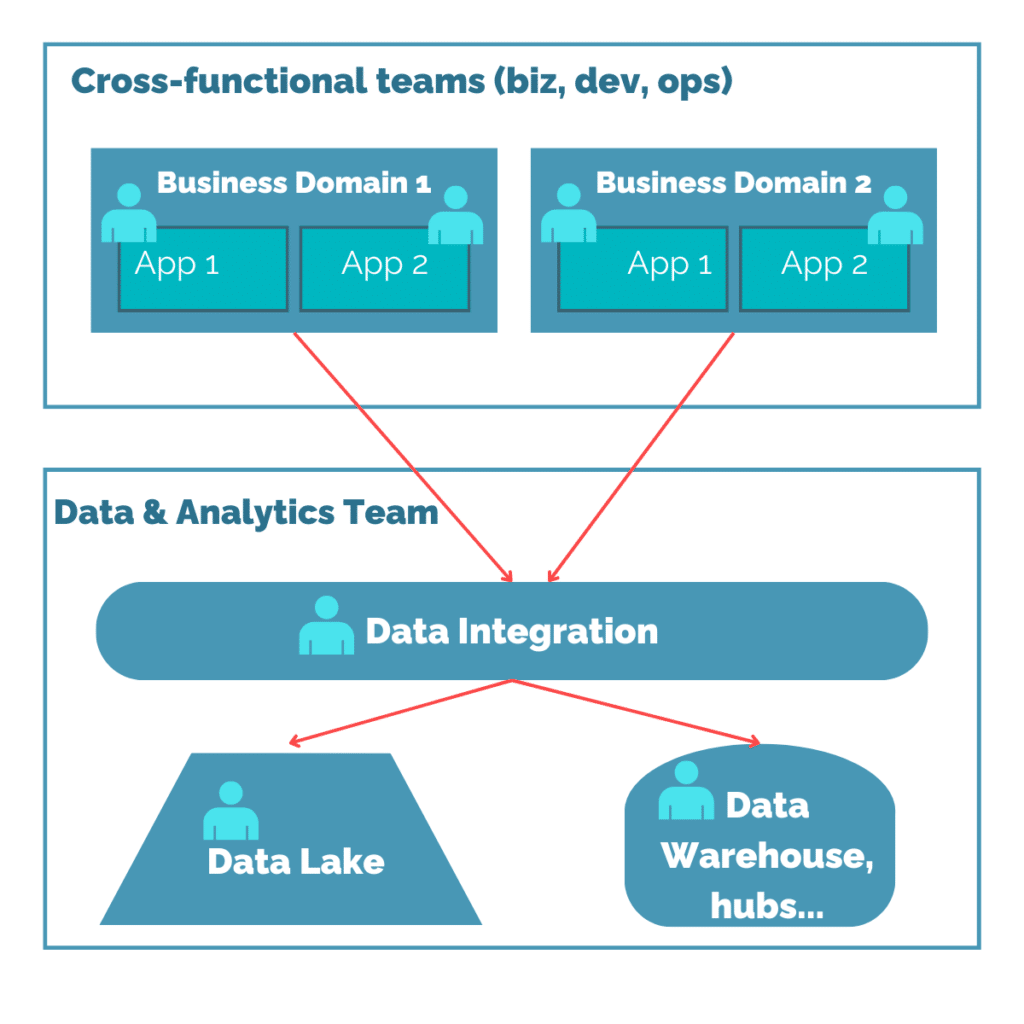
Le Data Mesh, de son côté, vient de son côté en réaction d’une précédente architecture très centralisée, faite de Data Lake, de Datawarehouse, de compétences BI, d’intégration via ETL ou messaging, le tout géré de manière très centralisée.
En effet, il était coutume de dire que c’est à une même équipe de gérer tous ces points, faisant d’eux des spécialistes de la data certes, mais surtout des grands généralistes de la connaissance de la data. Comment faire pour être un expert de la donnée client, de la donnée RH, de la donnée logistique, tout en étant un expert aussi en BI et en intégration de la donnée?
Ce paradigme d’une culture centralisatrice, a du coup amené un certain nombre de grosses équipes Data à splitter leur compétences, créant toujours plus de silos de compétences. De l’autre côté, les petites équipes pouvaient devenir très tributaires des connaissances des sachants métiers. Si cela vous rappelle les affres de la bureaucratie, ce serait évidemment pur hasard!
Ci-joint une représentation simplifiée de l’architecture dont nous avons pu hériter :
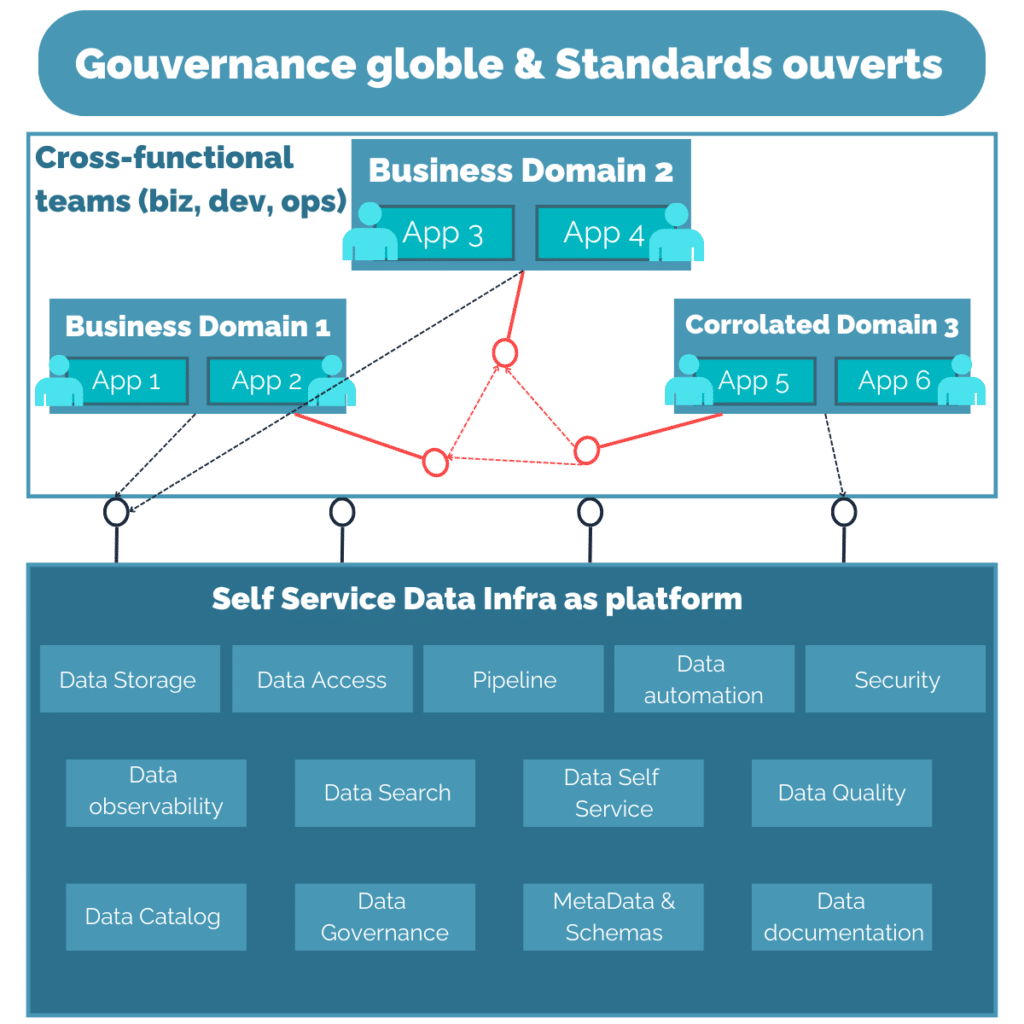
C’est ainsi qu’est apparu le pattern Data Mesh. Dans ce pattern, ce sont aux équipes Domaine de :
Collecter, stocker, qualifier et distribuer les données
Productifier la donnée pour qu’elle ait du sens à tous
Fédérer les données
Exposer des données de manière normée
Ce qui impose en l’occurrence de :
Mettre en place un self-service de données
Participer activement à la gouvernance globale
Et d’avoir un nouveau rôle de Data Engineer, qui doit mettre en place la plateforme de données pour justement faciliter techniquement, et proposer des outils.
Nous avons donc en schéma d’architecture le suivant :
Mais alors quid des points communs ?
Et en réalité, le gros point commun de ces trois patterns, c’est leur histoire !
Les trois proviennent de cette même logique centralisatrice, et les trois cherchent à éviter les affres d’une décentralisation dogmatique. A quoi cela sert de décentraliser ce que tout le monde doit faire, qui est compliqué, et qui en vrai n’intéresse pas tout le monde?
Et à quoi cela sert de forcément tout vouloir centraliser, alors même que les compétences/appétences/expertises/spécialisations sont elles-même “explosées” en plusieurs personnes ?
Certes, la centralisation peut avoir comme intérêt de mettre tout le monde autour de la même table, ce qui peut être intéressant pour de gros projets qui ne vivront pas, ou quand on est dans des phases d’une maturité exploratoire…
Et cela pousse tout un ensemble de principes, dont entre autre (liste non exhaustive):
Découvrabilité : Il faut pouvoir retrouver les services et les données simplement, en les exposants via des « registry » dédiés simples d’accès
Flexibilité et évolutivité : Il faut qu’une modification dans l’infrastructure ou dans un domaine puisse être accueilli sans douleur
Sécurité : Les politiques de sécurité sont propres aux champs d’actions de ces patterns, et sont donc inclus dans ces patterns
Distribution et autonomie : On distribue les responsabilités, les droits et les devoirs, afin de construire un système robuste organisationnellement
Alors oui, je vous entend marmonner “Et oui, c’est toujours la même chose! C’est comme ça”.
Mais en fait pas forcément ! En ayant en tête :
Ces éternels mouvements de yoyo,
Le Domain Driven Design qui est aussi un point commun au Data Mesh et à l’Event Mesh,
La professionnalisation du marketing comportemental a entièrement changé la façon dont les entreprises interagissent avec leurs clients. Nous assistons aujourd’hui à l’avènement de l’hyper-personnalisation, voire de l’individualisation de l’expérience client.
Le champ des possibles est encore repoussé par les nouvelles technologies émergentes qui viennent booster les techniques de marketing comportemental. Celles-ci reposent sur une compréhension en profondeur du profil et des habitudes du client pour lui offrir une expérience unique avec la marque et ainsi le rendre fidèle.
Le marketing comportemental, qu’est-ce que c’est ?
Avant de définir lemarketing comportemental, intéressons-nous d’abord à la définition du marketing classique : “ Ensemble des actions qui ont pour objet de connaître, de prévoir et, éventuellement, de stimuler les besoins des clients à l’égard des biens et des services et d’adapter la production et la commercialisation aux besoins ainsi précisés.” (Merci Le Larousse 📖).
Nous pouvons ensuite l’appliquer et l’adapter pour notre définition du marketing comportemental : “Ensemble des actions reposant sur l’analyse poussée des comportements clients (online et offline), pour connaître et anticiper ses besoins et lui offrir une expérience hyper-personnalisée”. (Merci Rhapsodies 🙏)
Beaucoup de similitudes entre les deux non ? Finalement le marketing comportemental a toujours été partie intégrante du marketing. Mais aujourd’hui, le développement de solutions marketing orientées client permet de le mettre en application de manière toujours plus efficace.
La collecte des données client
La collecte des données client est bien entendu à la base du marketing comportemental. Les données collectées sont de tous types : données client sur les comportements online et offline, comme le comportement utilisateur sur le site web, les historiques d’achats en ligne et en magasin, les commentaires sur les réseaux, et bien d’autres.
L’analyse des données client
Après la collecte, s’ensuit l’analyse des données, qui permet notamment d’identifier et d’affiner les profils clients.
Des analyses telles que :
Descriptives : analyse des données existantes pour établir des tendances et des modèles comportementaux
Prédictives : prévoir les comportements clients en se basant sur des techniques de modélisation en fonction des actions passées
Aujourd’hui, l’Intelligence Artificielle vient rendre ces analyses de plus en plus pointues et pertinentes. Les algorithmes d’apprentissage automatique permettent d’identifier des tendances cachées et de prédire de manière de plus en plus précise les comportements clients.
L’activation des données client
Les analyses permettent ensuite de mettre en place des actions marketing différenciées en fonction des profils définis. Il s’agit « d’activer le client », c’est-à-dire de susciter une action engageante de sa part (ex : un achat, un abonnement, un clic, …). Voici quelques exemples d’actions ou de parcours construits grâce aux techniques de marketing comportemental :
Parcours omnicanal spécifique “churner” ou intentionniste
Personnalisation de site web (ex : personnalisation de bannière, bandeau, page)
Recommandation de produits en fonction des affinités client en omnicanal
Anticipation des demandes au SAV
Sollicitation sur le canal préféré du client et au meilleur moment
Pour aller plus loin, différentes stratégies de marketing relationnel telles que le lancement de programmes de fidélité sont envisageables. Pour mettre en place ces stratégies, il est nécessaire d’étudier les différents scénarios de générosités possibles (générosité réelle, maximum, faciale, etc.) et de formuler plusieurs hypothèses sur des KPIs clés tels que le taux de réachat, le taux d’acquisition ou encore le taux de fidélité. Grâce à cela, il est possible d’avoir une idée des différents bénéfices d’un programme de fidélité d’un point de vue budgétaire et fidélisation. Mais nous en parlerons une autre fois…
Quels sont les avantages et défis du marketing comportemental pour les entreprises ?
Puissant moteur de fidélisation, le marketing comportemental est aujourd’hui capital pour transformer ses clients en “fans fidèles”. Plus un client est ancien, plus le nombre de données sur son comportement sera important, plus il sera possible d’hyper-personnaliser son contenu et donc de le rendre fidèle. Le ciblage des campagnes de marketing direct est rendu plus fin, les recommandations d’offres plus pertinentes ou le traitement des demandes SAV plus efficace. C’est donc là tout l’intérêt du marketing comportemental : faire entrer le client dans un cercle vertueux de fidélité. Le marketing comportemental devient ainsi un élément clé pour développer son activité en améliorant son taux de rétention.
Quels sont les avantages RSE du marketing comportemental ?
Une fidélisation qui peut être renforcée par les aspects durables du marketing comportemental. Celui-ci favorise une approche RSE des activités marketing de l’entreprise. Les communications vers les clients sont réduites, car plus efficaces et envoyées aux bonnes personnes, au bon moment, avec le contenu le plus pertinent. Si nous prenons l’exemple des emails, ceux-ci seront adressés avec un ciblage optimisé et donc avec un volume moindre.
En emprunte carbone qu’est-ce que cela donne ?
Un email envoyé équivaut à 0,3g de CO2. Si sur 1 année vous parvenez à réduire d’1 million le nombre d’envois, alors c’est 300 tonnes de CO2 qui ne seront pas produites.
Et 300 tonnes de CO2, qu’est-ce que c’est ?
1 554 300 km en voiture (38 fois le tour de la terre)
662 400 litres d’eau en bouteille (Consommations moyenne d’eau de 1200 français sur 1 an)
16 200 jours de chauffage au gaz (Consommation moyenne de gaz pour 44 français sur 1 an)
Une autre bonne raison d’implanter une stratégie de marketing comportemental dans votre entreprise !
Quels sont les défis du marketing comportemental ?
L’hyper-personnalisation, atout incontestable de l’expérience client, s’accompagne également de ses défis.
Chaque client se voit de plus en plus préoccupé par la protection de sa vie privée. Il est capital de pouvoir offrir des expériences personnalisées à ses clients tout en respectant les réglementations en vigueur.
On ne vous le présente plus, mais nous allons bien parler du RGPD. Cette réglementation impose des restrictions strictes sur la collecte et le stockage des données. Une réglementation à respecter sous peine d’une sanction financière. Ce règlement vise à donner aux citoyens européens le contrôle sur leurs données personnelles. Il exige le consentement du client lors de la collecte des données client. Le RGPD réglemente également l’utilisation, la conservation, la sécurité des données, ainsi que les droits des individus sur leurs données, tels que l’accès, la correction, la suppression et la portabilité.
De plus, si le marketing comportemental contribue à fidéliser un client, il peut aussi l’effrayer. L’hyper-personnalisation peut inquiéter au vu de la masse d’informations qu’une entreprise peut détenir sur ses comportements. Aussi, un client peut vite se retrouver face à une surcharge d’informations et son expérience s’en retrouvera impactée.
Il est alors capital d’être transparent quant à la collecte des données et de garantir la sécurité de celles-ci, tout en surveillant de près la pression marketing imposée à ses clients.
Illustration d’une expérience client rendue possible par le marketing comportemental
Plus haut, nous avons listé quelques exemples concrets rendus possibles par le marketing comportemental. Ces exemples illustrent comment le marketing comportemental peut être utilisé sur l’ensemble des étapes du cycle de vie du client, de la découverte d’un produit, à son achat, au SAV, jusqu’à la rétention et à la fidélisation du client.
Alors pour illustrer ceci, suivons l’histoire d’Eric :
Eric est un père de famille et client régulier depuis 3 ans d’une entreprise d’électroménager. Pendant ces 3 années, l’entreprise a pu récolter différentes données sur Eric et les a analysées. Elle en a pu tirer les informations suivantes :
Sa segmentation RFM : Eric est identifié comme “à réactiver” par l’entreprise. Il a effectué des achats d’une somme importante il y a plusieurs mois, mais rien depuis.
Canal de communication favori : SMS en 1 & Emails en 2
Catégorie de produit favori : Cuisine, rayon pâtisserie
Tendance d’achat : En promotion
Avis laissés : note moyenne de 4,8 étoiles
Membre du programme de fidélité : Oui
Taux de participation : moyen (2 à 3 sollicitations maximum selon les réactions du client)
L’objectif de l’entreprise est donc ici de réactiver Eric en lui proposant des offres qui répondront à ses besoins. Pour cela, elle va utiliser les techniques de marketing comportemental, en se basant sur les données récoltées. Nous allons donc voir au travers du parcours d’Eric, comment une entreprise peut employer le marketing comportemental à différents niveaux du parcours d’achat.
Comment une entreprise peut employer le marketing comportemental à différents niveaux du parcours d’achat d’Éric.
Et c’est ainsi que se termine l’histoire d’Eric.
Chacune des actions était pertinente avec son profil. Chacun des messages était en cohérence avec les attentes du client et les sollicitations ont été justement dosées afin que le client ne se sente pas oppressé. Les préférences ont toutes été respectées, du choix de support de communication jusqu’à la recommandation de produits ou de contenu. Grâce à cela, l’entreprise parvient à maintenir son engagement. Eric et l’entreprise trouvent donc tous les deux leur bonheur dans cette stratégie de marketing comportemental.
Comment le mettre en place chez vous ?
Une stratégie de marketing comportemental doit être finement réfléchie et suivre quelques étapes incontournables :
Définir ses ambitions en termes d’expérience client : ce que nous souhaitons que nos clients vivent, en fonction de leurs profils, de leurs besoins (ex : autonomie, disponibilité, …) et de la promesse de marque
Définir les parcours cibles : quel canal, pour quel cas d’usage, pour quel type de client
Construire une feuille de route portant sur : l’enrichissement de la connaissance client, le dispositif de marketing relationnel et digital, l’omnicanalité
Mettre en place une organisation propice à l’omnicanalité : pas de barrière entre les canaux, les passerelles doivent être facilitées et fluides
Se doter des bons outils et les intégrer de manière pertinente dans son paysage IT
Comme évoqué plus haut, les solutions de marketing orienté client répondent aujourd’hui à des besoins toujours plus pointus pour optimiser l’expérience client. Outre les outils classiques que nous connaissons en support à la relation client (CRM, Marketing automation, DMP), nous assistons aujourd’hui à l’avènement d’un nouvel outil, la Customer Data Platform (CDP). La CDP présente l’avantage de réconcilier les données online et offline sur des volumes qui peuvent être très importants. Elle analyse ces données finement pour activer efficacement le client en fonction de son comportement. Pour en savoir plus, vous pouvez télécharger notre livre blanc sur les Customer Data Platform.
Maintenant que nous avons fait un tour d’horizon du marketing comportemental, ses défis, ses opportunités et ses bénéfices, il ne reste qu’une seule question à résoudre : comment l’implémenter dans votre entreprise ?
Une telle stratégie demande des interventions à différents niveaux. Utopique sur le papier, mais complexe à implanter, le marketing comportemental permet de se réinventer et d’exploiter les données pour une meilleure expérience client. Que cela soit sur les outils employés, la digitalisation du SI ou la digitalisation de l’expérience client globale, chacun de ces éléments doit être pensé et organisé en harmonie les uns avec les autres. C’est pour cela que nous accompagnons nos clients sur l’implémentation de stratégies digitales de fidélisation en veillant à toujours se positionner dans une vision client.
Il y a quelques jours de cela, nous avons abordé le préambule du Mobile Money en Afrique. Dans ce nouvel article, nous allons désormais nous consacrer au second volet: la genèse de ce moyen de paiement très répandu en Afrique Sub-saharienne.
Un cercle vertueux pourrait se définir comme « une boucle de rétroaction positive dont l’effet est jugé souhaitable ».
En des termes plus simples : un opérateur Mobile Money à pour objectif de
Développer des services financiers,
Rendre accessible ces services depuis un téléphone portable,
Et, simplifier les opérations quotidiennes d’achat et de paiement des utilisateurs finaux.
Bill Price & David Jaffe, abordent la notion clé de la « Valeur Ajoutée » finale dans leur ouvrage « Objectif Client » (2015). Et si vous ne l’avez pas déjà lu, permettez-moi de vous conseiller de vous attarder sur le concept du #Me2B.
En Occident, l’ère du « penser client à chaque étape de la conception d’un produit ou d’un service » continue de gagner en importance.
Sur le continent africain, les réalités économiques, technologiques et business demandent des actions pragmatiques depuis toujours. Sacré challenge, n’est-ce-pas ?
Pour l’image, si vous cherchez à vous documenter sur l’adoption des NTIC en Afrique Sub Saharienne, vous tomberez sans doute sur des anecdotes autour du téléphone portable, des taxi-phones, des fraudes au crédit de communication …
Mais comment le Mobile Money a-t-il trouvé sa place dans tout cela ?
Premièrement, il est clé de souligner qu’en SSA, le Mobile Money repose sur un triptyque qui me semble crucial. C’est un service accessible depuis un téléphone portable développé
Pour les populations africaines (principales rurales mais aussi urbaines),
Par des entreprises africaines,
Sur le continent africain.
Pour le comprendre, il faut donc changer d’optique et plutôt essayer de comprendre les codes de ce continent.
Deuxièmement, le terreau du Mobile Money se trouvait dans ce qu’était les quotidiens de beaucoup de populations africaines :
L’absence de confiance dans le système bancaire : où va mon argent ? Comment le récupérer ?…
Le manque d’explication de la valeur ajoutée amenée par le système bancaire : épargner ? Pour quoi faire si j’ai besoin de mon argent chaque jour et à chaque instant sur le marché ? Pour payer mon gardien ? Pour payer mon taxi-moto ?
La qualité de l’éducation financière : l’accès à l’éducation scolaire tend à se démocratiser mais n’est malheureusement pas encore généralisée. Alors comment l’éducation financière pourrait-elle l’être ?
Le maillage terrain des établissements bancaires : savez vous combien cela coûte de construire, administrer et entretenir une agence ? Cher ! Alors comment ouvrir un compte sans agence bancaire de proximité à moins de 3h de route de chez moi ?
La complexité des formalités administratives : savez vous combien il était cher et compliqué d’obtenir des papiers d’identité ?
Mobile Money, une opportunité ?
Face à tout cela, une opportunité s’est créée : le Mobile Money. Finie la paperasse administrative et bonjour une procédure simplifiée d’ouverture de compte. Un formulaire rempli et signé + une pièce d’identité + un numéro de téléphone donnent désormais accès à une galaxie de services financiers.
⚠️ Pour info : #MonKalpé au Sénégal ou #mPesa au Kenya sont les dénominations marketing et/ou commerciales données aux services de Mobile Money. Ce, pour parler aux populations, leur expliquer et les rassurer ! Depuis un #FeaturePhone (ex: #Nokia 3310 ou #Tecno) ou, via les premiers #Smartphones (#iPhone, #Infinix…), tant que le terminal capte un réseau téléphonique en EDGE, le Mobile Money est accessible, utilisable et sécurisé.
EDGE ? Cela veut dire qu’internet n’est pas nécessaire ! Si vous pouvez appeler et/ou envoyer un SMS, alors le service Mobile Money est accessible ! Pas besoin de #3G ni de #4G ou de #9G.
Pourquoi le réseau téléphonique ? Car pour accéder à son porte-monnaie électronique, un utilisateur devra saisir sur son clavier de téléphone une séquence. Un menu s’affiche alors sur son écran : il s’agit d’un menu #USSD (Unstructured Supplementary Service Data).
Pour les plus de 30 ans arrivés jusqu’ici, je vous demanderai de vous rappeler l’époque de la Mobicarte Orange ! Vous vous souvenez de ce que vous deviez faire après avoir gratté votre carte ? Appeler un numéro ou taper un code USSD !
ET OUI : en occident aussi nous utilisions (et utilisons parfois encore !) la technologie USSD.
Deux éléments ont aidé (et aident encore !) le Mobile Money à se développer :
Le réseau téléphonique : sa qualité et la couverture d’une géographie étant les composantes nécessaires au bon fonctionnement de l’USSD
Le réseau de distribution : à la différence des comptes bancaires, ouvrir un compte Mobile Money peut se faire n’importe où (via une agence ou un point de vente agréé – via formulaire papier ou depuis un téléphone portable!). Un processus qui prend moins de 3 minutes !
Une technologie fascinante et pragmatique au service des besoins quotidiens. Outre la perception de ce système, des chiffres concrets viennent appuyer son développement et son importance dans la sous région.
Dans le prochain article (Part 2 de la Genèse Mobile Money) nous reviendrons sur quelques-uns de ces KPIs et commencerons à étalonner les services clés !
La dataviz périodique est une publication qui a pour objectif de mettre en évidence les bonnes pratiques et les écueils à éviter en matière de data visualisation (aussi appelée dataviz). A chaque publication, nous vous proposons de décrypter un nouveau sujet et un exemple de dataviz pour comprendre les ficelles de la réussite en datavisualisation.
Dans cette édition, nous aborderons le thème des biais de perception en dataviz et nous verrons comment les limiter en prenant exemple sur une publication du Monde : lien vers la dataviz.
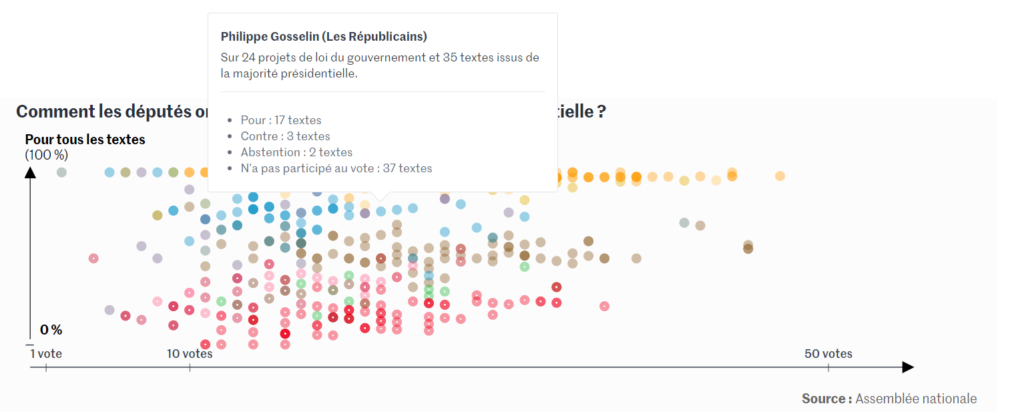
Visuel extrait de l’article du Monde présenté en introduction (lien vers l’article)
Si vous souhaitez aborder un sujet complexe, comme celui du Monde qui s’attache à expliquer le positionnement des députés par rapport à la majorité de l’Assemblée nationale, il est nécessaire de porter une attention particulière au type de graphique utilisé.
Une pratique courante est de proposer une vision moyennée d’un phénomène mesurable sur un groupe (e.g. individus, produits) séparé en catégories (e.g. taille, lieu) en utilisant un graphique en barre. Ce type de visuel a l’avantage de comparer les sujets simplement et de donner l’impression de pouvoir appréhender la réalité d’un coup d’œil.
Or ce n’est qu’une impression. La plupart du temps, nous ne nous rendons pas compte du biais de perception qu’induisent les graphiques en barre en gommant les disparités présentes au sein de chaque catégorie (ou barre du graphique).
Dans son article publié sur Data Visualisation Society, Eli Holder explique l’importance de réintroduire de la dispersion dans la dataviz afin de ne pas créer ou confirmer des stéréotypes. [1]
Le stéréotype est une tendance naturelle, souvent inconsciente, qui consiste à penser aux individus en termes d’appartenance à leur groupe social. C’est une façon pratique et utile de réduire la complexité du monde qui nous entoure. Par exemple, au moment de visiter une ville que nous ne connaissons pas, nous pouvons nous adresser à un officier de police ou à un chauffeur de taxi pour demander notre direction, en partant du présupposé que ces personnes seront à même de détenir l’information. [2]
Cependant, il n’est pas opportun d’encourager cette tendance naturelle quand nous concevons des dataviz, en particulier quand le sujet est complexe et appelle une prise de décision éclairée et réfléchie.
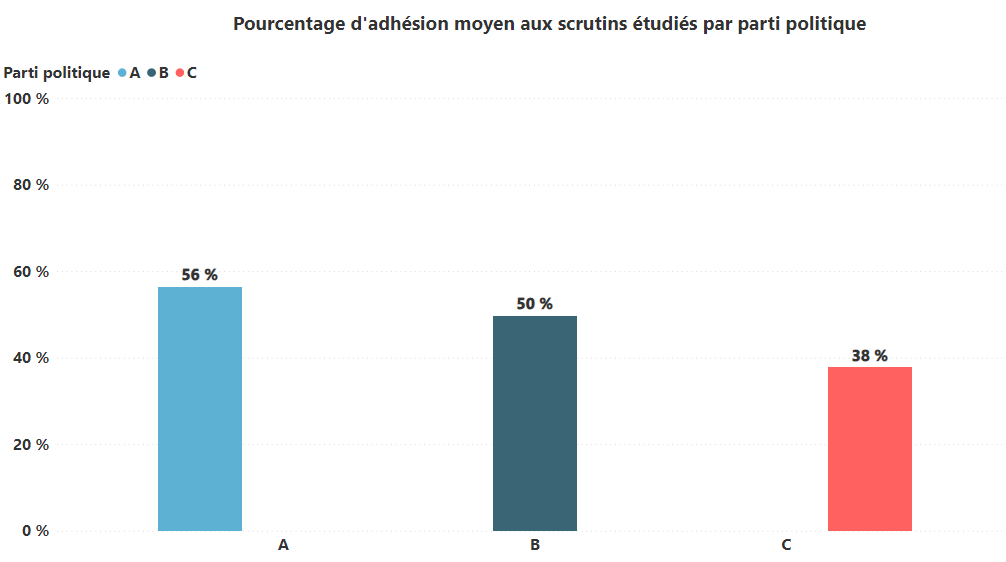
Dans le cas du sujet traité par le Monde, il aurait été possible de représenter l’adhésion au texte de la majorité non pas par député mais par parti politique. Or une représentation en graphique en barre du taux d’adhésion moyen des parlementaires par parti politique aurait renvoyé une illusion de similarité au sein des différents partis et aurait amené mécaniquement le lecteur à penser (cf schéma ci-dessous) : « Le parti politique A vote davantage en faveur des textes portés par la majorité que le parti politique C. Donc tous les députés du parti politique A sont plus proches de la majorité que tous les députés du parti politique C. »
Schéma illustratif réalisé à partir de données fictives (toute ressemblance avec des éléments réels serait fortuite)
Pour casser ces biais de perception, il est possible d’introduire de la dispersion dans nos dataviz et ainsi mieux refléter la complexité de la réalité. Des visuels tels que le nuage de point (Scatter Plot) ou le Jitter Plot sont de bonnes alternatives aux graphiques en barre ou histogrammes.
Dans la dataviz du Monde, le nuage de points a été judicieusement choisi pour montrer le positionnement de chaque député. Cette représentation permet par ailleurs de croiser le taux d’adhésion des députés avec leur niveau de participation aux scrutins étudiés. Cela permet de calculer un indice de proximité plus complet et d’éclairer le sujet avec un nouvel axe d’analyse.
Le lecteur est alors moins tenté de confondre le positionnement des députés avec celui des partis politiques pour le comprendre, et donc moins enclins à faire des préjugés.
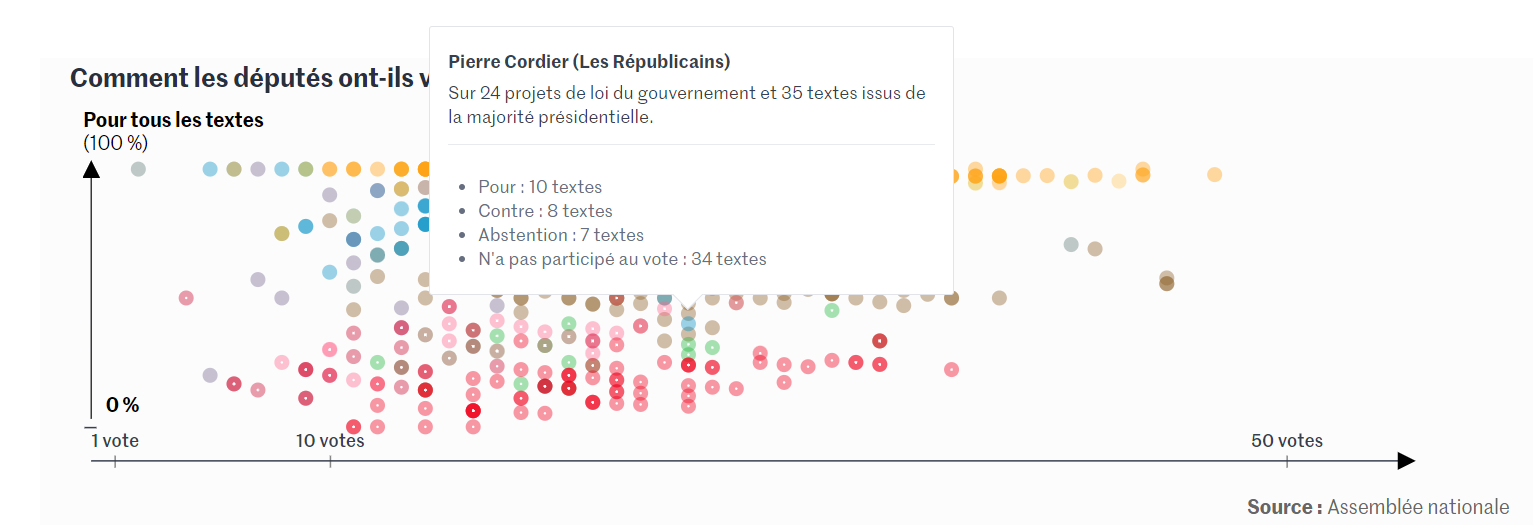
Visuel extrait de l’article du Monde présenté en introduction (lien vers l’article)
En définitive, nous observons à travers l’exemple du Monde, qu’il est parfois nécessaire d’introduire de la dispersion dans les représentations visuelles pour traiter un sujet complexe.
Les nuages de points et autres diagrammes de dispersion, permettent au lecteur d’appréhender un phénomène à la maille la plus fine et de limiter la création ou l’entretien de stéréotypes. Le lecteur est alors plus à-même de prendre du recul par rapport au sujet traité et de développer un point de vue éclairé quant au phénomène étudié.
De manière plus générale, Eli Holder propose d’élargir notre conception de la “bonne dataviz” et d’aller au-delà de la représentation claire, accessible et esthétique. Il est nécessaire de prendre en compte sa responsabilité, en tant que créateur de dataviz, vis-à-vis de son public et du sujet traité. Il est essentiel de porter une attention particulière aux visuels choisis pour minimiser les interprétations inexactes, et par extension, la création de stéréotypes.