Le 27 novembre, à l’hôtel Peninsula, plus de 50 participants de tous les secteurs d’activité ont assisté à notre événement « Maîtriser et Augmenter la valeur des données ».
Cette table ronde était l’occasion de faire un 360° sur les usages faisant des données un actif majeur pour les organisations. Rythmée par les témoignages exceptionnels de Lydia Bertelle de Paris La Défense, Laurent Drouin de la RATP, Isaac Look de Malakoff Médéric et l’artiste Filipe Vilas-Boas, nos intervenants ont pris le temps de, partager leur vision, présenter leurs cas d’usage et détailler les leviers et les freins afin de structurer une approche pragmatique pour augmenter la valeur des données.
4 temps forts ont rythmés cette matinée:
Le regard Artistique et Numérique porté par Filipe Vilas-Boas, un artiste citoyen qui a installé un Casino permettant à tout un chacun de réfléchir et comprendre l’impact des données sur nos vies.
Les choix et investissements de Malakoff Médéric en temps et en ressources sur le sujet de la Gouvernance des Données porté par Isaac Look
Les Usages comme les vecteurs de la valeur de données, éclairés par des exemples de la RATP, portée par Laurent Drouin
L’approche choisie par Paris La Défense et Lydia Bertelle pour augmenter la valeur des données illustrant la feuille de route, le fonctionnement, les difficultés et les résultats concrets atteints.
Rhapsodies Conseil a pu, à cette occasion, présenter et remettre aux participants un exemplaire de son Livre-Blanc « Augmentez la valeur de vos données ! » détaillant sa méthodologie de mesure et d’identification des actions permettant d’augmenter la valeur des données.
Revivez les moments forts de l’évènement sur nos médias:
Vidéo
Podcast
Photos
Accueil de l’Hôtel Peninsula
Introduction de la Table Ronde
Casino Las Datas
Evénement DATA – Témoignage Isaac Look de Malakoff Médéric
« Gouvernance », le mot fait souvent peur. Si vous êtes consultant, vos clients les plus opérationnels vous font certainement un sourire poli quand vous évoquez le sujet, alors qu’ils pensent « Mais qu’est ce qu’il veut encore me vendre celui-là. Une machine à gaz qui va prendre beaucoup de temps, beaucoup de slides, et ne servir à rien ! » ; « Vous savez, nous avons déjà bien d’autres sujets à traiter ».
« Gouvernance des données », vous amenez l’expression avec habileté, en rappelant le volume considérable des données qui deviennent de plus en plus complexes à maintenir, sécuriser, exploiter, BLA, BLA, BLA. Et votre client le plus pragmatique vous dira « C’est bien gentil, mais ça ne m’aide pas à répondre à la demande de ce matin de l’équipe Marketing qui veut que je lui propose une solution pour cibler plus intelligemment les opérations / campagnes marketing… ou celle de l’autre jour de l’équipe Finance, qui n’en peut plus de faire à la main tous ses rapports sur Excel… »
Toute gouvernance, la gouvernance de données incluse, doit être une solution pour répondre à des usages et des points d’attention du métier (la DSI étant un métier parmi les autres).
Évitez la gouvernance de données pour la gouvernance de données !
Il existe une démarche qui a depuis longtemps trouvé sa place dans de nombreuses entreprises, mais qui a très vite montré ses limites, la voici (cela va vous parler si vous avez déjà challengé vos consultants sur le sujet) :
On va modéliser toutes les données existantes dans votre système d’informations
On va identifier les sources applicatives associées à ces différentes données
On va désigner des responsables pour chaque objet de données (des data owners, data stewards, …)
On va écrire des processus de gouvernances des données (validation, workflow, …)
On va mettre en place une instance de gouvernance sur la donnée
On fait tout ça d’abord avec notre vision DSI, on ira voir les métiers une fois qu’on aura une démarche déjà bien en place…
Alors, cela vous rappelle quelque chose ? Cette démarche : c’est faire de la gouvernance pour… SE FAIRE PLAISIR !
Une fois à l’étape 6, je vous défie de répondre précisément à la question suivante : « Alors, à quoi sert-elle cette nouvelle gouvernance ? Que va-t-elle améliorer précisément pour le marketing ? pour l’équipe financière ? pour l’équipe communication ? etc. ». N’ayez aucun doute là-dessus, la question vous sera posée !
La gouvernance des données doit être une solution pour mieux répondre aux usages :
Vos métiers utilisent les données. Ils savent ce qui doit être amélioré, ce qui leur manque comme données pour mieux travailler, tout ce qu’ils doivent faire aujourd’hui pour parer aux problématiques de qualité des données, le nombre de mails qu’ils doivent faire pour trouver la bonne donnée, parfois en urgence, pour leurs usages courants … Ils savent tout cela. Alors plutôt que d’inventorier toutes les données de vos systèmes, partez des usages des métiers et de leur point de vue et formalisez ces usages existants et les usages de demain
Concentrez vos efforts de gouvernance pour améliorer ou permettre les usages à plus forts enjeux ou risques pour l’entreprise
Cherchez à maîtriser l’ensemble de la chaîne de valeur, usage par usage (de la collecte à l’utilisation effective de la donnée pour l’usage) : organisation, responsabilités, outillages/SI
Faites évoluer votre gouvernance par itération, en partant toujours des usages.
Comprenez la stratégie de votre entreprise. Votre direction générale doit être sponsor. Donnez-lui les éléments pour la faire se prononcer sur une question simple : Sur quel pied doit danser en priorité la gouvernance Data, 40% sur le pied offensif (Aide au développement de nouveaux usages innovants), 60% sur le pied défensif ? (Gestion des risques GDPR, maîtrise de la qualité des données concernant les usages identifiés les plus critiques, …) ? 50/50 ? Elle doit vous donner les clés pour prioriser et itérer en adéquation avec la stratégie de l’entreprise.
La gouvernance des données est avant tout un sujet métier. Vous ne le traiteriez pas correctement en restant dans votre étage DSI… Cela peut paraître évident. Mais même quand certains le savent, ils choisissent la facilité : Rester à la maison…
Sortez, rencontrez tous les métiers, et vous formerez une base solide pour votre gouvernance. Ne sortez pas, et vous perdrez beaucoup de temps et d’argent…
Vous avez peut-être souvent entendu ces mots « Data is an Asset ». Mais la personne qui les prononce va rarement au bout de l’idée. Et pour cause, l’exercice est plus complexe qu’il n’en a l’air. Cet article a pour ambition d’éclairer le domaine et, pour cela, procédons par étape :
1 – Qu’est-ce qu’un Asset ?
Nous n’allons pas l’inventer, il existe une très bonne définition sur ce site : https://www.investopedia.com/ask/answers/12/what-is-an-asset.asp)
« An asset is anything of value that can be converted into cash. Assets are owned by individuals, businesses and governments »
« Un asset est quelque chose qui peut être converti en monnaie sonnante et trébuchante ».
Avec une maison, cela marche bien en effet. Une expertise suffira à vous donner une bonne idée de la valeur euro de votre maison. Mais pour vos données, ça ne paraît pas si simple.
Le défi aujourd’hui est d’être en mesure de valoriser une donnée, ce qui signifie :
Pouvoir par exemple très formellement comparer deux actifs Data entre eux, deux jeux de données (par exemple sur la base de critères bien définis)
Mettre une valeur « euro » sur un jeu de données (monétisation, prise en compte de l’actif Data sur des opérations d’acquisition / fusion, etc.)
Gérer nos données comme des Actifs, pour maintenir ou développer leur valeur dans le temps
Sur ce dernier point, faisons l’exercice rapide ensemble. Prenons un processus d’asset management standard, appliquons-le à la donnée.
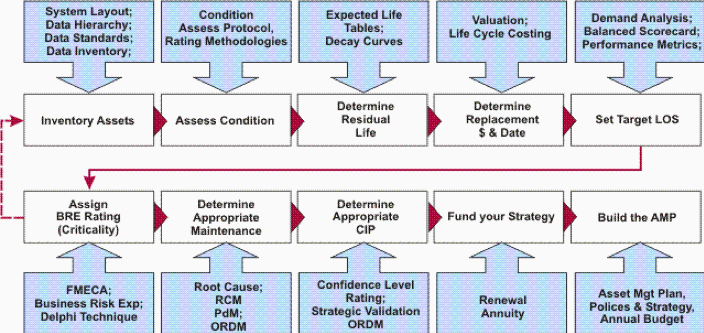
2 – Appliquons un Processus d’Asset management à la Data
Alors allons y ! Appliquons ce processus sur les données pour voir si elle peut être gérée comme un Asset ?
« Inventory » :Inventorier les assets Data. Jusque-là tout va bien.
« Asset Condition Assessment » :Évaluer l’état des biens: Est-ce que la donnée est de qualité, est-ce qu’elle il y a souvent des erreurs qui apparaissent ? Comment les gère-t-on ?
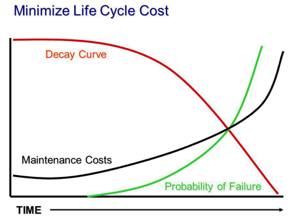
« Determine residual Life / Decay curve » : Il s’agit d’évaluer l’évolution potentielle de différents critères de valeur dans le temps. Par exemple est-ce que la donnée risque de perdre en rareté ? Les usages vont-ils être moins importants ? etc. En général cette notion porte sur le vieillissement d’un bien physique :
« Valuation » : Pour valoriser la donnée, on sent qu’il nous faut poser clairement un cadre de valorisation sur base d’un ensemble de critères. Au même titre que l’expert par exemple en Asset commercial connaît parfaitement les critères qui permettent da valoriser un commerce (surface du commerce, chiffre d’affaire, situation géographique, etc…). Notre conviction est qu’il faut aujourd’hui développer ce cadre pour l’actif « Data ».
« Life Cycle Costing » : C’est le processus qui permet d’identifier tous les coûts impliqués dans le cycle de vie de l’actif (coût d’une erreur, coût de la réparation / correction, coût de la perte de production éventuelle, coût de la maintenance corrective, ….)
« Determine replacements» : Est-ce qu’il faut revoir la manière de gérer certains asset Data ? Faut-il en abandonner/purger certains, non rentables ?
« Set target LOS » : Quel est le niveau de service attendu sur chaque asset Data ? A quels besoins faut-il répondre pour que l’asset ait de la valeur, soit viable ? Quels critères de valorisation veut-on améliorer ? (rareté, qualité, …)
« Assign BRE rating » = Business Risk Evaluation : Et quels sont les risques ? (GDPR, perte de données, …) : « Comment est-ce que des problèmes / incidents peuvent apparaître ? Quelle probabilité d’apparition ? Qu’est cela coûterait si le problème apparaissait ? Quelles en seraient les différentes conséquences ? »
« Determine Appropriate Maintenance » : Si l’on veut maintenir la qualité d’une donnée par exemple, par exemple 3 stratégies de maintenance existent dans le monde physique, elles sont applicables à l’actif Data (Use Base Maintenance : revue à une fréquence donnée, Fail based maintenance : correction sur incident/erreur, Condition Bases Maintenance : Maintenance plus préventive)
« Determine Appropriate CIP » (Capital Investment Program) : Initier (ou mettre à jour) notre programme d’investissement (Projet d’extension du capital d’assets Data, de renouvellement/modification de la gestion de certains Assets, mise en place de nouveaux processus de maintenance = gouvernance…)
« Fund your strategy » : On obtient le financement pour tout cela
« Build the Asset Management Plan » : Enfin on construit, ou on met à jour notre plan de gestion et de valorisation de nos assets Data
La méthode a l’air adaptée. Mais elle soulève des questions clés, auxquelles il va nous falloir répondre, notamment concernant les critères de valorisation. A titre d’exemple, le CIGREF a travaillé sur un cadre d’appréciation de la valeur économique des projets de transformation numérique. Il est intéressant d’avoir une approche comparable pour l’actif « Data ».
3 – Et après ?
Nous venons de voir que la data est effectivement un actif, d’un type bien particulier. Pour aller plus loin, il va falloir identifier des critères objectifs de valorisation des données, et faire des usages de ces données un vecteur clé de sa valorisation.
Dans cet optique, nous pensons qu’un cadre méthodologique de valorisation des données est nécessaire.
Rhapsodies Conseil construit une approche méthodologique pour mesurer la valeur des données, en mettant les usages métiers des données au cœur de la méthodologie, approche que nous vous invitons à découvrir prochainement. En parallèle, nous vous recommandons les travaux initiés sur ces sujets par Doug Laney pour Gartner Inc., en particulier à travers son ouvrage « Infonomics » aux éditions Routledge.
Plusieurs questions se posent aujourd’hui, alors que de nombreux environnements Hadoop sont en production depuis quelques mois / années :
Le Data Lake est-il aussi utile/utilisé que prévu ? et ne l’utilise-t-on pas, à défaut d’avoir trouvé un usage pertinent, à des fins qui n’étaient pas prévues au départ ( exemple courant … GPP : Gros Passe Plat ou encore EDDC : Extracteur De Données Centralisé … )
Comment structurer les données dans le Data Lake ? Si c’est pour mettre un Hadoop chez soi et structurer sa donnée dans quelques parquets et des tables hive, mais avec la même logique que nos bonnes vieilles tables SQL normalisés 3NF, à part de dire « Youhou, hadoop on l’a fait, on en a une belle maintenant ! » Quel intérêt ? C’est comme s’acheter une console Switch en ne la décrochant jamais de son socle (pardon pour l’image pour ceux qui ne connaîtraient pas la dernière console de Nintendo…).
Comment on rend la valeur de l’outil palpable par l’utilisateur final ? Que ce soit pour du reporting quasi temps-réel / journalier / mensuel, de la Data Viz ou de l’analyse de données avancée (un super Random Forest, un neural Network au top en production…) qu’est ce qui fera la différence pour l’utilisateur final ? Par rapport à ce qu’on lui donnait déjà avant…
J’essaie de donner des éléments de réponses ci-dessous et ce n’est que mon humble avis. Si vous avez vos expériences à partager n’hésitez pas.
1 – Le data lake est-il aussi utile/utilisé que prévu ?
Les environnements distribués naissent un peu partout au moment ou j’écris ces lignes. 2 cas caractéristiques existent qui peuvent être problématiques :
Cas 1 – Etre gourmand, trop gourmand : De nombreuses entreprises se sont ruées vers la tendance sans même vraiment avoir eu une réflexion de fond sur la valeur que devraient leur apporter ces nouvelles capacités dans leur contexte, elles se retrouvent aujourd’hui avec des téras stockées qui ne leur apportent pas autant qu’elles l’auraient espérées. On a voulu en mettre beaucoup, on n’a pas pris le temps de travailler sur la description de ce qu’on y a mis (meta data), et peu de gens comprennent vraiment ce qu’on peut y trouver et si c’est vraiment fiable.
Leur Data Lake devient petit à petit un passe-plat facilitant préparations et fournitures de certaines données bien spécialisées, même sur des volumes qui ne justifient en rien son usage, opérant quelques croisements ici et là entre sources originales qui n’étaient pas avant dans le même environnement technique. Elles font face à des bi-modes Hadoop VS Entrepôt Oracle/SAS (pour ne donner qu’un exemple). Certaines données sont dans les deux types de système et l’utilisateur Analyste ne sait pas vraiment lequel utiliser. Alors les Data Scientist, statisticiens – vieux de la vieille continuent à bosser dans SAS parce qu’ils n’ont pas le temps d’apprendre Python, et les petits jeunes qui sortent d’écoles pensent pouvoir changer le monde avec leur modèle de churn codé en Python / Spark mais qui a en réalité déjà été implémenté il y a 10 ans par un Data Miner expert SAS avec une méthode et des résultats similaires… Ce n’est qu’un rien caricaturale.
Pour prouver sa valeur et justifier son coût, ce Data Lake là va devoir se recentrer sur des usages clés porteur de valeur (et de gain euros…) pour l’entreprise, qui justifie son existence, ou mourir de désillusion ou rester un gros GPP (gros passe plat…).
Cas 2 – Etre timide, trop timide : D’autres entreprises plus prudentes, fonctionnent en petites itérations, à base de POC Big Data sous Microsoft AZURE, AWS et autres google cloud, en sélectionnant des cas d’usages qui justifient l’utilisation de telles plateformes. Parfois, le risque est d’être dans l’excès inverse du premier cas, en priorisant trop et en ne montrant rien.
Trouver 3 usages coeur de métier pour commencer est une excellente chose, mais les cas d’usages doivent être assez complets pour montrer l’étendue des possibilités que peut apporter un environnement comme hadoop et tous ses petits (la multitude d’outils d’intégrations, d’analyses, de traitements qui se basent sur hadoop).
Toutefois, faire un vrai POC métier est la clé pour les entreprises qui en sont à ce stade, montrer que Hadoop traite très très très vite un très très très gros volume de données, n’apporte rien au métier. Faire une démo d’un outil métier qui illustre un vrai cas métier en mettant en valeur :
La performance ressentie par l’utilisateur (des jolis diagrammes qui s’affiche rapidement quand l’utilisateur clique sur la carte 🙂 « C’est beau, ca va vite, c’est utile ! ouaouh ! »
La valeur/connaissance apportée en plus en allant au bout de l’usage : On sait détecter un problème, une fraude, etc…et ça génère une alerte en temps réel dans l’outil de l’opérateur qui lui recommande l’action à faire ! Ouaouh merci c’est ce qui fallait ! c’était possible alors ? dingue…)
Dans tous les cas, encore une fois allez au bout de l’usage ! On a tendance à s’arrêter juste un peu avant ce qu’il faudrait (par manque de temps, de connaissance métier, de courage). Ne faites pas un POC IT, ayez le courage de faire un vrai POC business pas juste à moitié parce que vous ne connaissez pas assez le métier, allez jusqu’au bout de la démonstration, jusqu’à la jolie petite interface interactive qui fera la différence. Sinon vous n’aurez pas votre Waouh. Faites collaborer les Data Scientist avec les développeurs des appli métiers pour avoir un vrai résultat.
Si vous ne faites pas cela, les gens comprendrons peut être la théorie « D’accord vous faites une grosse boîte où vous mettez toutes les données et puis ça tourne vite comme une machine à laver, c’est ça ? 🙂 ».
Non ! vous voulez un : « Ah, mon opérateur ne va plus devoir scruter toutes les logs à la mano pour essayer de trouver les problèmes, et je vais multiplier par 10 ma productivité donc…En fait…Ai-je toujours besoin d’un opérateur ? » OUI, là on est bon.
2 – Quelques principes pour structurer le data lake
Ne traitez pas votre Data Lake comme une poubelle à données qu’on recyclera peut être un jour en cas de besoin (le fameux « on prend, on sait jamais » du Data Lake, anti GDPR par dessus le marché). Mais traitez le bien comme un lac nourrissant, abreuvant et vital ! Moins de quantité, plus de qualité.
Structurer vos Données intelligemment. Ce n’est pas parce que vous avez beaucoup de place que vous pouvez en mettre de partout et n’importe comment (que dirait votre mère franchement?). Votre Data Lake doit normalement séparer :
Les données sources (Raw Data)à l’image des données du système sources
Les données sources (Raw Data) retraitées uniquement par applications de règles purement techniques (votre format de date standard, types de données, etc…). Pas de règles métiers ! Pas ici, le but est juste de récupérer la donnée brute ! C’est d’ailleurs un sage principe que vous trouvez aussi dans la philosophie DataVault de Dan Linstedt. Vous n’appliquez des règles métier qu’au moment de la construction de vues métiers qui répondent à un usage donné. C’est aussi surtout du bon sens…Cela apportera bien plus d’agilité à l’ensemble du système.
Une Historisation structurée et intelligentedes données du Data Lake. « OH Non ! Il a dit « structuré » et « Data Lake » dans la même phrase le monsieur, c’est pas joli ». Malheureusement, beaucoup d’entreprises oublient cette étape. Mais pourquoi donc ? Suivez par exemple ici (encore désolé…) la modélisation Data Vault 2.0, je parle principalement des concepts de Hubs, Links, Satellites, ou au moins la philosophie pour cette partie. Vous pouvez éventuellement exclure de cette phase certaines données exceptionnelles (par exemple si ce sont des données vraiment peu utilisées très spécialisées, que vous savez ponctuelles comme des données externes one shot (que vous n’achetez pas tous les mois…).
!!! Attention je ne dis pas qu’il faut faire un Data Warehouse d’entreprise dans le Data Lake (je ne rentrerai pas dans ce débat). Le Data Lake doit couvrir un certain nombre de cas d’usage spécifiques, qui nécessitent d’historiser (avec agilité !) un certain périmètre de données, qui tend à grandir au fur à mesure que les nouveaux cas d’usages apparaissent.
Si vous vous arrêtez aux Raw Data et aux business View et que vous ne mettez rien entre les deux, que vous ne faites pas ce travail de structuration fonctionnelle, au bout d’un moment vous aurez un gros sac de données applicatives, et les Data Scientists et autres utilisateurs devront eux même comprendre la logique de recoupement de toutes les sources (notamment le grain, la définition des clés techniques/métiers, etc.). Faites ce travail de structuration de l’historisation (DataVault 2.0 recèle de bonnes idées).
Les données préparées pour être prêtes à l’Usage (Business View), requêtables rapidement pour usages business. C’est dans la consolidation de chacun de ces socles que les règles métiers sont appliquées ! Ici, On ramène les données au plus proche de l’usage et structurées pour l’usage en question. Et n’hésitez pas à dé-normaliser vos Business View! Vous n’êtes pas dans mysql… Plein de lignes et plein de colonnes ? C’est fait pour ! Vous pouvez même aller (dans certains cas) jusqu’à pré-calculer dans une grosse table adaptée tous les indicateurs sur toutes les combinaison de segments (dimensions), de périodes, de dates… (attention, intérêt à mesurer par rapport à votre propre usage de consommation de la donnée), mais ça se fait : « ouahou ! comme les graphiques s’affiche vite… »
Les métadonnées : leur intégration peut se faire de diverses manières, mais faites en sorte que les gens ait confiance aux données qu’ils utilisent (C’est quoi cette donnée ? d’où vient la donnée ? quelle application, quel fichier source ? Qui l’a saisie ? Quand l’a-t-on intégré au Data Lake ? quelle fréquence de mise à jour ? etc.)
3 – Comment on rend la valeur de l’outil palpable par l’utilisateur final ?
Ne croyez pas (et je suis sûr que vous ne le croyez pas) que votre Data Lake se suffit à lui même
S’il est déjà bien structuré (c’est déjà un gros avantage), il a quand même besoin de belles décorations :
je ne vous apprendrai rien : un outil de Data Viz/report qui plaît au métier (parce qu’il a été impliqué dans son choix…). Je ne ferai pas de pubs ici…
Une bonne intégration avec les systèmes opérationnels et dans les deux sens (un savoir faire sur le sujet), pas qu’en collecte. Par exemple : Lancer des simulations directement depuis mon application de gestion qui va lancer un job spark sur la business view associée qui elle va renvoyer des résultats en un rien de temps sur l’application de gestion : L’utilisateur est heureux, il ne connaît pas Hadoop ou Spark, il ne veut rien en savoir, mais vous avez amélioré significativement sa façon de travailler. C’est ce qu’il faut viser. C’est cela aller au bout de l’usage.
Un environnement complet d’analyse pour vos Data Scientist (Data Viz, développement IDE, collaboration/gestion de version, notebooks, les bonnes librairies de dev !) parce qu’ils en ont besoin. Impliquez réellement les principales personnes concernées dans ce choix !
Pour conclure, les idées clés :
Les usages doivent toujours driver la construction itérative de votre Data Lake
Ne cherchez pas à refaire un/des Data Warehouse 2 sans vraiment savoir par qui, pour quoi ce sera utilisé, ne cherchez pas à manger un maximum de données pour devenir le plus vite possible la plus grosse base de données et justifier le nom de votre équipe, BIG Data, j’imagine…
Si on vous pousse un usage auquel on pourrait répondre sur une base mysql, redirigez gentiment le destinateur…A moins que vous soyez force de proposition pour faire évoluer son usage pour justifier l’utilisation d’une telle plateforme.
Si vous êtes assez matures, ne voyez plus votre Data Lake comme un Lab collecteur qui se suffit à lui-même, si vous allez au bout des usages, vous serez obligés de l’intégrer avec des applications métier (vous savez, l’utilisateur qui clique dans son appli et ça lui sort toute sa simulation en 0.5 secondes…).
Inspirez-vous de la philosophie de monsieur Data Vault 2.0 (Dan linstedt) (je ne dis pas qu’il faut tout prendre, mais au moins inspirez vous des concepts de Hub / Links / Satellites qu’un enfant de 4 ans peut comprendre pour une structuration agile de l’historique de vos données). Cela évitera bien des noeuds au cerveau à vos utilisateurs, Data Engineer et Data Scientist, et cela apportera de l’agilité au bout du compte.
Dé-normaliser vos vues métiers ! Dénormalisez vos étoiles, vos 3NF, ça ira bien plus vite !
Le Data Scientist « Stateu » doit ouvrir les yeux au Data Scientist « Informaticien » sur ce qu’il est vraiment en train de faire tourner. Le Data Scientist « informaticien » doit apprendre au Data Scientist trop « stateu » à produire du code industrialisable et réutilisable. Recrutez les deux types de profils (Ecoles de stats, et école d’ingé informatique)
Si vous faites collaborer vos Data Scientist avec les équipes de développements des applications métiers, alors c’est que vous êtes sur les bons usages…