Le pôle data accompagne une direction métier souhaitant s’équiper à courte échéance d’outils de BI dans l’intention de piloter son activité. Une équipe de 8 personnes est mobilisée. Différents profils constituent l’équipe (Project Manager, Business Data Analyst, Analytic Engineer) dont les niveaux d’expérience varient (apprentis, personnes en changement de poste récent, profils seniors et juniors).
La qualité des livrables attendue est élevée : l’ensemble de produits doivent être cohérents, en termes de design technique et design d’interface, et soutenus par une chaîne de valeur data robuste et réemployable par d’autres projets.
Qui plus est, les enjeux du projet sont centraux pour la stratégie de la direction métier.
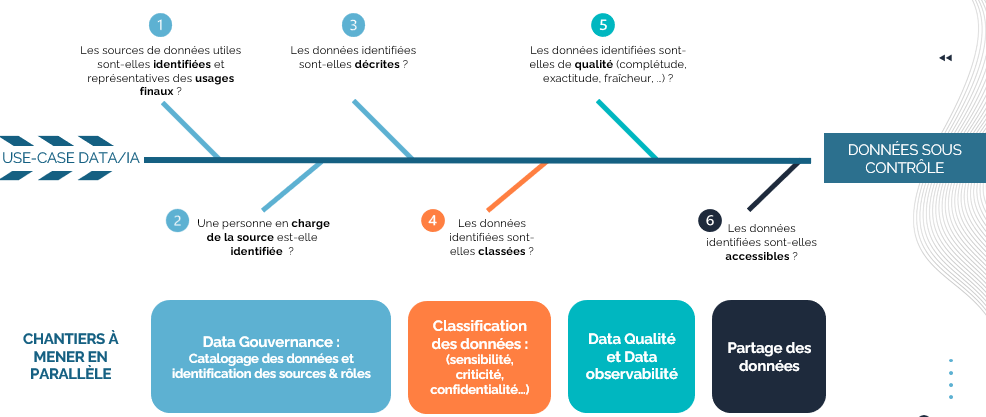
Le Framework du projet BI&A élaboré par l’équipe Transformation Data a fourni une base de travail adaptable au contexte de ce projet. Les incontournables d’un projet de Business Intelligence y sont listés par ordre chronologique :
Analyse du besoin métier
Maquettage de la solution de datavisualisation
Conception de la solution data
Déploiement et Industrialisation de la solution
Amélioration continue
Une fois les grands principes du framework énoncés, nous avons déployé chez notre client une panoplie de pratiques et d’outils pour assurer la coordination de l’équipe projet aux compétences et expériences hétérogènes:
1. Un point d’équipe pour favoriser la circulation d’information, le partage de bonnes pratiques et la montée en compétence :
Une revue de espace de développement en séance
Une communication des data engineers
Un rappel et réajustement des objectifs de développement à moyen terme
Un suivi d’action transverse
La présentation d’un modèle de donnée par un des développeurs
La présentation par un membre volontaire d’un sujet au choix (technique de visualisation, culture informatique, organisation du travail, …)
2. Des communications internes projet et externes via des canaux dédiés pour impliquer les partenaires du projet (sponsors et utilisateurs)
via une landing page Sharepoint avec lien vers les contenus de ref (EB, Note de cadrage, …) pour les sponsors et parties prenantes métiers
via des Canal teams dédiés en fonction des types de communications (incidents et succès, mise à jour de rapports, questions à la communauté utilisateur)
3. Des supports pédagogiques pour vulgariser l’environnement technique et diffuser les bonnes pratiques de datavisualisation à tous les membres de l’équipe
4. Un stockage de la documentation projet avec des arborescences de dossier imposées et une nomenclature projet pour le nommage de fichier
Bénéfices
Le projet aboutit à la mise en production d’outils de pilotage de l’activité de la direction métier, et ce en respectant les délais et le budget annoncés pendant la phase de cadrage.
Les pratiques mises en place et adoptées au sein de l’équipe ont fortement contribué au succès de ce projet, et profitent au-delà de celui-ci. En effet, la communication projet interne et externe, ainsi que la structuration de la documentation ont permis de :
Faire foisonner les idées et ainsi proposer des produits complémentaires qui répondaient à d’autres besoins de la direction métier;
Accélérer le développement et d’améliorer la qualité des produits;
Assurer la transmission de l’ensemble des responsabilités de maintenance des outils en production sur un membre interne à l’organisation, et ce de manière naturelle ;
Garantir l’insertion des produits dans les processus existants.
De plus, on peut noter que les produits data et les documents projet ont pu être exploités par d’autres projets alors même que le projet n’était pas terminé.
Finalement, en fin de projet les alternants membres de l’équipe étaient autonomes pour interpréter un besoin métier et le retranscrire en un développement dans l’outil de datavisualisation.
Autres Success Stories qui pourraient vous intéresser
💡 Dette Data : ne bridez pas vos usages Data & IA !
Dans un univers toujours en expansion de l’exploitation des données, la notion de Dette Data est de plus en plus saillante. Similaire à la dette technique en développement logiciel, la Dette Data se réfère à l’accumulation de problèmes non résolus dans la gestion des données d’une entreprise, qui, si elle n’est pas traitée, peut entraver de manière significative les initiatives liées à la data : Analyses, algorithmes, modèles….
📊 Ce carrousel vous présente les impacts de la Dette Data ainsi que des approches pour la réduire, afin que vous puissiez amplifier l’utilisation de vos données.
Les autres sujets d’expertise qui pourraient vous intéresser
10 février 2025
Pilotage & Performance Opérationnelle et Contractuelle
Contrairement à une idée reçue, la réglementation de l’IA à vocation à favoriser son développement et son partage dans les projets des organisations.
Chez Rhapsodies Conseil, nous considérons que les bonnes pratiques Data sont indispensables à la réussite des projets IA (intégration d’un outil ou développement interne). Nous abordons le sujet de l’IA par les usages raisonnés de ces technologies. Pour assurer le succès de l’intégration de l’IA dans notre quotidien, nous mettons l’accent sur la gouvernance et la mise en qualité des données. En effet la maîtrise des données est pour nous un incontournable de la réussite d’un projet IA, au même titre que les questions éthiques et réglementaires que nous avons dû nous poser pour définir notre charte d’IA qui intègre les exigences de l’AI Act comme la gestion des risques tout au long du cycle de vie du système d’IA.
Gouvernance des données : Une structure solide
Une gouvernance des données efficace est cruciale pour garantir des données maîtrisées et conformes à la réglementation. Cette efficacité passe par des politiques claires de gestion et suivi de la qualité des données, des responsabilités définies, ainsi que par une traçabilité des données. Et ce, en lien avec le cycle de vie du projet IA.
En assurant une supervision continue, la gouvernance aide à éviter les biais, à respecter les droits des individus et à maintenir la transparence des processus, en ligne avec les exigences des autorités régulatrices.
Qualité des données : L’essence de l’IA
Pour que les modèles d’IA fonctionnent de manière optimale, il est essentiel de fournir des données de haute qualité. Cela implique la vérification de la cohérence, de l’exactitude et de la pertinence des données. Des processus de validation et de nettoyage des données doivent être mis en place pour éviter les erreurs, les biais et garantir que les modèles sont alimentés par des informations fiables.
Cette démarche est d’autant plus essentielle pour les applications classées « à haut risque » par l’AI Act. Tout traitement automatisé de données personnelles pour évaluer divers aspects de la vie d’une personne (situation économique, intérêts, localisation, etc.), est considéré comme un traitement à haut risque. Ainsi les défaillances peuvent avoir des conséquences majeures comme des fuites de données personnelles, des biais discriminatoires ou la mise en place par ceux qui déploient des systèmes de surveillance humaine.
Conformité avec l’AI Act : Processus intégrés et documentation
L’AI Act impose des obligations précises aux projets IA, notamment en matière de documentation, de traçabilité des décisions et d’explicabilité des modèles. Les fournisseurs de modèles doivent effectuer des évaluations de modèles, y compris mener et documenter des tests contradictoires afin d’identifier et d’atténuer le risque systémique. Ils doivent repérer, documenter et signaler les incidents graves et les éventuelles mesures correctives à l’Office AI et aux autorités nationales compétentes dans les meilleurs délais.
Pour répondre à ces obligations, il est essentiel de mettre en place des processus intégrés qui permettent de suivre, documenter et auditer les données utilisées à chaque étape du projet.
Cette approche préventive renforce non seulement la conformité, mais facilite également l’adaptation aux futures régulations et les audits de conformité éventuels.
En résumé, avant de vous lancer dans un projet IA nous vous conseillons fortement de respecter un ensemble de bonnes pratiques Data et de les personnaliser selon votre contexte :
Nous attirons aussi votre lecture sur un sujet crucial de l’impact de l’IA. En raison de l’impact environnemental et social important et croissant de l’IA et en particulier de l’IA Générative, ses usages doivent rester limités au strict nécessaire pour les organisations. Les prises de décision autour du déploiement de ces technologies doivent se faire en prenant en compte systématiquement ces enjeux.
–> Voir la norme AFNOR de référence sur le sujet !
Pour aller plus loin, n’hésitez pas à contacter l’un de nos experts Transformation Data :
Nous l’avons vu dans les deux premiers articles de cette trilogie: la question du libre accès à l’information date d’avant l’ère informatique. Cette question, qui s’est transformée en obligation pour les acteurs ayant trait au service public, doit bénéficier d’une réponse adaptée. En France, la plateforme “data.gouv.fr” joue un rôle central en permettant aux administrations de publier et de partager leurs données de manière transparente avec le public. Cependant, pour garantir une publication de qualité et exploitable, les contributeurs doivent entre autres suivre trois étapes importantes.
Midjourney, prompt : A technical drawing of a computers and databases network. A pole with a French flag is located in the middle.
Étape 1 : Mise en gouvernance des données et des produits
La première étape du processus consiste à identifier les ensembles de données à publier, ou plutôt, vu que la règle est la publication, et l’exception est la rétention, identifier quelles données ne pas publier.
Cela suggère un prérequis important : Connaitre son patrimoine des données. Dans ce cas de figure, être capable de déterminer exhaustivement et explicitement quelles données possèdent des caractéristiques empêchant leur publication en open data (telles que des données personnelles ou des atteintes à la sûreté de l’État).
Un autre sujet important est celui de la connaissance et de la maitrise du cycle de vie des données. Où la donnée est-elle créée dans le Système d’Informations ? Où la récupérer dans son état le plus consolidé et certifié en termes de qualité ? A quelle fréquence la donnée devient-elle obsolète ?
Enfin, et sujet tout aussi majeur : quelle est la notion « Métier » (Ou « Réelle ») portée par cette donnée ? Quelle information interprétable et exploitable dans différents cas d’usages recouvre-t-elle ? En somme, quelle est sa définition ?
Afin d’arriver à cette connaissance et cette gestion systématique et qualitative des données, c’est toute une organisation qui doit être transformée, dotée de rôles et de processus adéquats. Et si l’Open Data est une bonne raison de se lancer dans une telle démarche, de nombreuses externalités positives (Par exemple, fiabilisation d’indicateurs, réduction du temps de traitement/recherches de données) sont à anticiper pour l’ensemble de ses usages basés sur les données, donc pour l’activité de la structure.
Enfin, un angle pertinent pour amorcer une transformation peut être de considérer le jeu de données à publier comme un « Data Product ». Même s’il n’y a pas de finalité financière directe attendue de la publication en open data, il est bénéfique de penser au jeu de données comme un produit. Responsabiliser des collaborateurs, tels que des Data Product Managers, autour de leur conception ou de leur suivi, au-delà des données qui les composent, permet d’aller vers une véritable gestion d’un portefeuille open data. La structure peut alors traiter les données comme un actif, et les produits qui en résultent permettent d’activer leur valeur.
Midjourney, prompt : An orchestra conductor in front of a computer assembly
Étape 2 : Préparer son jeu de données
Nous identifions les données, assurons leur qualité et déterminons leur point d’accès. C’est un bon début, mais il reste encore quelques étapes techniques avant de procéder au chargement des données.
Une des obligations légales de l’Open Data est de proposer un format exploitable par machine.
Data.gouv.fr détaille la liste des formats de fichier adéquats :
Formatage des Données : Les données doivent être formatées de manière à être facilement accessibles et exploitables par le public. Il est recommandé d’utiliser des formats ouverts et standardisés tels que CSV, JSON ou XML. Les données doivent également être bien structurées, avec des en-têtes explicites pour chaque information.
Documentation des Métadonnées : Nous devons accompagner chaque ensemble de données de métadonnées détaillées. Les métadonnées fournissent des informations essentielles sur les données, telles que la description de l’ensemble de données, la source, la fréquence de mise à jour, les licences d’utilisation, et les balises (tags). Ces informations, qui décrivent les données que l’on veut publier, permettent d’en assurer le suivi, la traçabilité, et de faciliter leur recherche, consultation, et réutilisation.
Organisation et Schémas de données : En parallèle de ces aspects techniques, les notions d’organisation et de schéma sont importantes à prendre en compte pour assurer une publication de qualité. L’organisation va permettre d’identifier un acteur (Une personne morale, une entreprise, un service de l’état), et de publier des jeux de données depuis plusieurs comptes « en son nom ».
La proposition et l’adoption d’une nomenclature particulière pour un type de données qui sera fréquemment mis à jour ou régulièrement complété par d’autres acteurs constituent le schéma de données. Par exemple, si des communes commencent à publier des jeux de données sur l’installation de défibrillateurs dans les lieux public, il existe un grand intérêt à converger vers un schéma de données commun afin de valoriser l’information.
Étape 3 : Publication des Données sur Data.gouv.fr et suivi
En fonction du type de données, de leur taille, de la fréquence de mise à jour de l’informations, il existe plusieurs possibilités pour les publier.
Du dépôt manuel de données à la mise à disposition par API , ou à l’import automatique en moissonnage, ces différents itinéraires techniques sont à examiner pour chaque situation, avec possibilité de consulter les collaborateurs administrateurs de datagouv.fr
En première partie, nous avons vu que dès les premières réflexions et bien en amont de la première publication, il est essentiel de penser à l’aspect « pérenne » d’un jeu de données, en commençant par une démarche de gouvernance des données. Il existe cependant un suivi possible à postériori, sur l’utilisation et la réutilisation des jeux de données. Là encore la plateforme datagouv.fr permet aux organisations d’accéder à des statistiques sur l’exploitation des données qu’elles mettent en Open Data.
Midjourney, prompt : A golden and shiny computer
Encore récent, et pour l’instant souvent « contraint », le sujet de l’Open Data pourrait voir un basculement de paradigme dans les années à venir. L’ensemble des acteurs socio-économiques pourraient s’engager à partager des connaissances, ce qui pourrait être inscrit comme un objectif RSE. Et au-delà de penser l’open data comme un centre de coût du fait de l’activité nécessaire à la mise à disposition des jeux de données, les acteurs économiques légalement contraints à la publication pourraient également en faire un centre de profit en tant que ré-utilisateurs.
La Culture Open Source – Partie 2 : Histoire et Lien avec l’Open Data
La Culture Open Source - Partie 2 : Histoire et Lien avec l'Open Data
Au cours des dernières décennies, l’évolution de la technologie a vu émerger une culture et une philosophie qui ont profondément influencé la manière dont nous développons, partageons et utilisons les logiciels et les données. Cette culture repose sur des principes fondamentaux de transparence, de collaboration et de partage. Pour faire suite à notre premier article, explicitant ce qu’était l’Open Data, nous aborderons ici l’histoire de la Culture Open Source et expliquerons en quoi l’open data en découle naturellement.
Qu’est-ce que la Culture Open Source ?
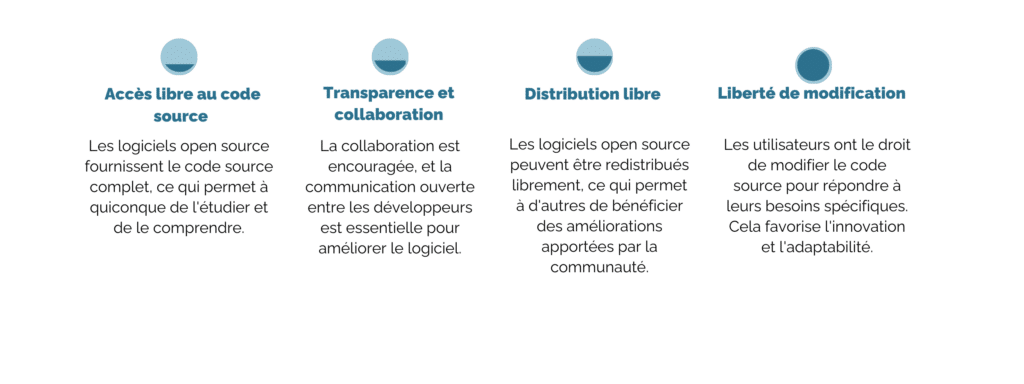
La culture open source est un mouvement qui promeut l’accès ouvert et le partage de logiciels et de ressources, permettant à quiconque de consulter, d’utiliser, de modifier et de distribuer ces ressources. Cela contraste avec le modèle de développement de logiciels propriétaires, où les entreprises gardent le code source secret et limitent les droits de modification et de distribution. Bien que le terme « open source » ait été popularisé au début des années 2000, les principes qui le sous-tendent remontent beaucoup plus loin dans l’histoire de l’informatique.
La Culture Open Source repose sur plusieurs principes clés :
Longtemps considérée comme une culture ne renfermant que des geek et informaticiens, l’Open Source s’est démocratisée et se retrouve dans de nombreux outils que nous utilisons tous (VLC, Mozilla Firefox, la suite LibreOffice, 7Zip…). Le partage des logiciels Open Source est favorisé par des plateformes de centralisation dont la plus connue est GitHub. Malgré une réputation de visuel dépassé et d’une utilisation parfois laborieuse et incomplète, le logiciel Open Source est souvent considéré comme plus sûr car ses failles sont rapidement identifiées, les mises à jour disponibles et l’adaptabilité favorisé (on n’est pas obligé de mettre à jour constamment son logiciel si on ne le souhaite pas, gardant ainsi la possibilité ou non d’ajouter des fonctionnalités).
Image générée par Midjourney: A picture of an orange firefox wrapped around an orange and silver traffic cone
L’Histoire de la Culture Open Source
L’histoire de la culture open source remonte aux débuts de l’informatique moderne. En effet, dans les années 1950 et 1960, les chercheurs construisaient souvent les premiers ordinateurs en tant que projets collaboratifs, et ils partageaient librement des informations sur la conception et le fonctionnement de ces machines, considérant le partage d’informations comme essentiel pour faire progresser la technologie.
L’une des premières incarnations de la culture open source telle que nous la connaissons aujourd’hui est le mouvement du logiciel libre, lancé par Richard Stallman dans les années 1980. Stallman a fondé la Free Software Foundation (FSF) et a développé la licence GNU General Public License (GPL), qui garantit que les logiciels libres restent accessibles à tous, permettant la modification et la redistribution. Cette licence a joué un rôle crucial dans la création d’une communauté de développeurs engagés dans le partage de logiciels.
Dans les années 1990, le développement de Linux, un système d’exploitation open source, a été un événement majeur. Linus Torvalds, son créateur, a adopté la philosophie du logiciel libre et a permis à des milliers de développeurs du monde entier de contribuer au projet. Linux est devenu un exemple emblématique de la puissance de la collaboration open source et a prouvé que des logiciels de haute qualité pouvaient être produits sans les restrictions du modèle propriétaire.
Plus récemment, le sujet de l’open source apparait comme un marqueur majeur de différenciation entre les différents acteurs AI :
Si l’on regarde du côté de l’entrainement de différents moteurs, une majorité des acteurs de l’IA utilise des données publiques issues d’espace de stockagedisponible tels que CommonCrawl, WebText, C4, BookCorpus, ou encore les plus structurés Red Pajama et OSCAR.C’est lorsque l’on observe l’usage et la publication des résultats que plusieurs stratégies s’opposent.
Le leader de l’IA générative Open AI a un positionnement “restrictif” dans la publication de ses avancées, au motif de protéger l’humanité de publications trop libre de sa création. Cela a par ailleurs contribué au feuilleton médiatique récent qui a secoué la direction de la structure.De l’autre côté du spectre, nous avons Mistral AI, que nous avons eu l’occasion de présenter auprès des journalistes de Libération et du site internet d’Europe 1. En effet, celle-ci propose l’ouverture totale de l’ensemble des données, modèles et moteurs, dans une orientation typiquement Européenne (Data Act).
Les données ouvertes dans l’histoire
Le développement de cette culture open source, par le développement des outils informatiques, marque le vingtième siècle. Mais l’humanité n’a pas attendu ces progrès technologiques pour se poser des questions sur la libre diffusion des connaissances.
Au premier siècle avant JC, Rome édifie une bibliothèque publique au sein de l’Atrium Libertatis, ouverte aux citoyens.
De plus, si le moyen-âge marque une restriction des accès aux livres pour la population, de nombreux ouvrages restent accessibles à la lecture, mais pas encore à l’emprunt ! Les livres sont attachés aux tables par des chaînes, et l’on trouve dans certaines bibliothèques des avertissements assez clairs : « Desciré soit de truyes et porceaulx / Et puys son corps trayné en leaue du Rin / le cueur fendu decoupé par morceaulx / Qui ces heures prendra par larcin » (voir plus)
Enfin, plus récemment, la révolution française provoque des évolutions significatives dans la diffusion des connaissances, et cette ouverture à tous des données: la loi fixe maintenant l’obligation de rédiger et de diffuser au public les comptes rendus des séances d’assemblées.
Qu’il s’agisse de processus de démocratisation, ou simplement d’outil de rayonnement culturel, on voit donc que la question du libre accès à l’information ne date pas de l’ère de l’informatique.
Image générée par Midjourney: A picture of an antic roman library, with people dressed in toga. There is several modern objects like computers and screens on tables.
L’Open Data : Une Conséquence Logique
L’open data est une extension naturelle de la culture open source. Cependant, comme nous l’avons déjà présenté dans notre premier article, l’Open Data est un concept qui repose sur la mise à disposition libre et gratuite de données, afin de permettre leur consultation, leur réutilisation, leur partage. Elle repose sur des principes similaires à ceux de l’open source, à savoir la transparence, la collaboration et le partage.
L’open data présente de nombreux avantages. Il favorise la transparence gouvernementale en rendant les données gouvernementales accessibles au public. Cela renforce la responsabilité des gouvernements envers leurs citoyens. De plus, l’open data stimule l’innovation en permettant aux entreprises et aux développeurs de créer de nouvelles applications et solutions basées sur ces données.
Par exemple, de nombreuses villes publient des données ouvertes sur les transports en commun. Cela a permis le développement d’applications de suivi des horaires de bus en temps réel et d’autres outils qui améliorent la vie quotidienne des citoyens.
En conclusion, la culture de l’Open Source repose sur des principes de transparence, de collaboration et de partage. Tout cela a permis la création de logiciels de haute qualité et l’innovation continue. L’open data, en tant qu’extension de cette culture, renforce la transparence, l’innovation et la responsabilité gouvernementale en permettant un accès libre aux données publiques et privées. Ensemble, l’open source et l’open data façonnent un monde numérique plus ouvert, collaboratif. Par conséquent, cette culture est quasi omniprésente de nos jours, en 2022, selon un rapport Red Hat. 82 % sont plus susceptibles de sélectionner un fournisseur qui contribue à la communauté open source. De plus, 80 % prévoient d’augmenter leur utilisation de logiciels open source d’entreprise pour les technologies émergentes.
Merci d’avoir pris le temps de lire ce second article de notre trilogie consacrée à l’open data. Retrouvez-nous prochainement pour le dernier tome, consacré aux modes opératoires et aux bonnes pratiques de la publication de données en open data.
Open Data en France – PARTIE 1 : contexte légal et pratiques actuelles
Open Data en France - PARTIE 1 : contexte légal et pratiques actuelles
L’Open Data est un concept qui repose sur la mise à disposition libre et gratuite de données. Cela va permettre leur consultation, leur réutilisation, leur partage. C’est aujourd’hui un enjeu majeur pour la transparence gouvernementale, l’innovation et le développement économique.
Nous allons explorer ce qu’est l’Open Data, son contexte légal et son obligation pour certains acteurs publics. Mais aussi les pratiques de mutualisation de données hybrides telles que le data sharing et les plateformes data.
Enfin, nous aborderons les enjeux organisationnels et techniques nécessaires à prendre en compte avant de se lancer dans une telle démarche.
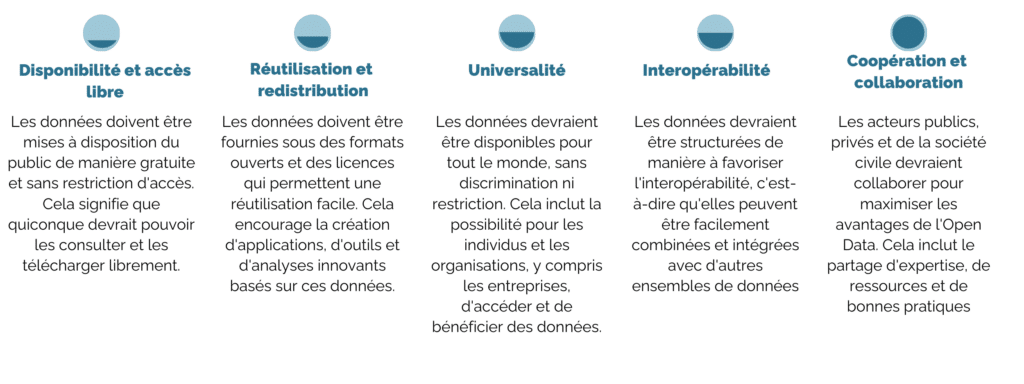
Qu’est-ce que l’Open Data ?
Tout d’abord, l’Open Data se caractérise, entre autres, par les principes suivants :
L’Open Data et la loi
Image générée automatiquement / Midjourney: A judge in a tribunal, surrounded by datas in assembly.
En France, l’Open Data a été promu par la Loi pour une République Numérique, adoptée en octobre 2016. Cette loi impose aux administrations publiques de publier certaines catégories de données de manière ouverte, à moins que des exceptions ne s’appliquent. Ces données incluent les données relatives aux marchés publics, aux prestations et services publics, aux résultats électoraux, et bien d’autres.
Cette loi a modifié le paradigme de publication de l’Open Data. Avant, la publication était souvent conditionnée à une demande d’accès à l’administration, avec des modalités de refus spécifiques à chaque demande qui étaient encadrées par la Commission d’Accès aux Documents Administratifs (CADA). Dorénavant, la publication en Open Data devient la norme, et doit anticiper une éventuelle demande par un citoyen, une association.
Les administrations peuvent toujours choisir de ne pas publier certaines données, en justifiant par exemple que leur publication porterait atteinte à la sureté de l’Etat. Ou bien encore qu’une anonymisation des données personnelles serait un effort disproportionné ou qu’elle dénaturerait le sens des données. Il convient de préciser que la publication des documents est obligatoire uniquement pour les documents dits « achevés» (a atteint sa version finale, à date : les brouillons, documents de travail, notes préalables ne sont pas considérés comme des documents achevés), c’est à dire validés et n’ayant plus objet à évoluer.
Il est également important de noter que les articles L. 300-2 et L. 300-3 du CRPA précisent que les acteurs privés investis d’une mission de service publique sont également soumis à ces obligations de publication.
Quels usages de l’Open Data
Image générée automatiquement / MidJourney: An anthropomorphic computer ingesting data and creating charts and plots.
Un des principes de l’Open Data est de permettre le “re-use” des données, à des fins d’analyses simples ou croisées, à titre non lucratif ou commerciales.
Le site datagouv.fr permet d’inventorier toutes les réutilisations des données liées à un data set, par exemple pour le data set des parcelles et agricultures biologiques :
Sur la page « Parcelles en Agriculture Biologique (AB) déclarées à la PAC » comprenant les données issues des demandes d’aides de la Politique Agricole Commune entre 2019 et 2021, on peut trouver des utilisations de ces données par l’agence bio elle-même, par l’Institut Technique et Scientifique de l’Abeille et de la Pollinisation ou par des sociétés privées de cartographies.
Ces exemples montrent la diversité des réutilisations de données, aussi bien en termes de cas d’usage, que d’acteurs impliqués.
Autres pratiques de Mutualisation de Données
Outre l’Open Data dans le sens “Obligation légale” auprès des acteurs publics, on trouve aujourd’hui des formes hybrides qui font du partage de la donnée un sujet transverse :
Le Data Sharing
Le data sharing, ou partage de données, implique la collaboration entre différentes organisations pour partager leurs données. Par exemple, des acteurs économiques ayant un domaine d’activité similaire mais n’étant pas en concurrence directe (Verticalité de l’offre, Disparité géographique) peuvent mutualiser des donner afin d’optimiser leur R&D, ou leurs études commerciales.
Les Plateformes Data
Les plateformes data sont des infrastructures qui facilitent le stockage, la gestion et le partage de données. On les retrouve au sein de structures, qui souhaitent mutualiser le patrimoine de leurs services, voire de leurs filiales. Il s’agit souvent de créer un point de référence unique, standardisé et facilement accessible des données pour toutes les parties intéressées. Cette plateforme n’est applicable que dans certain cas de figure (plusieurs filiales d’un même groupe par exemple).
L’Open Data s’adresse donc à la fois à la sphère publique et aux acteurs privés de par les obligations légales. Mais aussi par adoption volontaire du principe, ou par exploitation de données mises en open data. Et avec les pratiques liées (plateformes de données, data sharing), on retrouve des enjeux et des risques communs.
Image générée automatiquement / MidJourney: Three books on a table, one of them is open, the two others are closed
Cet article est le premier d’une trilogie consacrée à l’Open Data, qui se conclura par les modes opératoires et les prérequis de réalisation. D’ici-là, le second tome fera office de prequel, en s’intéressant aux origines culturelles de l’Open Data, notamment l’Open Source.