L’évolution du métier de contrôleur de gestion a été profondément influencée par l’avènement de l’intelligence artificielle (IA) et des technologies associées. En 2025, le contrôleur de gestion, désormais qualifié d’Homo numericus, intègre pleinement ces outils pour optimiser ses fonctions et apporter une valeur ajoutée stratégique à l’entreprise.
L’âge de l’IA et de l’analyse prédictive : le contrôleur de gestion Homo numericus
L’intelligence artificielle et l’analyse prédictive ont révolutionné les pratiques du contrôleur de gestion. Ces technologies lui permettent de :
Anticiper les tendances financières avec une précision accrue : en exploitant des algorithmes avancés, le contrôleur peut prévoir les évolutions du marché et adapter les stratégies en conséquence.
Automatiser les tâches répétitives : la collecte et le traitement des données sont désormais pris en charge par des systèmes automatisés, libérant du temps pour des analyses plus approfondies.
Générer des insights en temps réel : l’accès immédiat à des informations pertinentes facilite une prise de décision rapide et éclairée.
Nouvelles compétences clés
Pour s’adapter à ces évolutions, le contrôleur de gestion doit développer de nouvelles compétences, notamment :
Maîtrise des algorithmes d’IA et de machine learning appliqués à la finance : comprendre et utiliser ces outils est essentiel pour analyser des volumes massifs de données et en extraire des informations stratégiques.
Compréhension approfondie de la data science et de la visualisation de données : savoir interpréter et présenter les données de manière claire est crucial pour communiquer efficacement avec les parties prenantes.
Capacité à interpréter et à communiquer des analyses complexes : le contrôleur doit être capable de traduire des résultats techniques en recommandations compréhensibles pour les décideurs.
L’ère de la durabilité et de la responsabilité sociale
Le rôle du contrôleur de gestion s’étend également à l’intégration des enjeux de durabilité et de responsabilité sociale. Il est impliqué dans :
Le reporting extra-financier (ESG – Environnement, Social, Gouvernance) : élaborer des rapports détaillés sur les performances non financières de l’entreprise.
L’évaluation de l’impact carbone des activités : mesurer et analyser l’empreinte écologique pour orienter les actions vers une réduction des émissions.
La mise en place d’indicateurs de performance durable : développer des KPIs reflétant les objectifs de développement durable de l’entreprise.
Le partenaire stratégique augmenté
En 2025, le contrôleur de gestion est devenu un Partenaire Stratégique Augmenté, capable de :
Fournir des simulations financières complexes en temps réel : grâce à des outils sophistiqués, il peut modéliser divers scénarios pour évaluer les impacts potentiels sur l’entreprise.
Proposer des scénarios d’optimisation basés sur l’analyse prédictive : en utilisant des données historiques et actuelles, il identifie les meilleures options pour améliorer la performance.
Faciliter la prise de décision agile dans un environnement économique volatile : sa capacité à fournir des informations précises et opportunes soutient une réactivité accrue face aux changements du marché.
L’expert en cybersécurité financière
Avec la digitalisation croissante, le contrôleur de gestion doit également développer une expertise en cybersécurité financière, notamment pour :
Protéger les données financières sensibles : assurer la confidentialité et l’intégrité des informations critiques de l’entreprise.
Mettre en place des processus de contrôle interne robustes face aux menaces cyber : élaborer des protocoles pour prévenir et détecter les intrusions ou anomalies.
Évaluer les risques financiers liés à la sécurité informatique : analyser les vulnérabilités potentielles et leur impact sur la santé financière de l’entreprise.
Vers un contrôleur de gestion hybride et agile
En 2025, le contrôleur de gestion a évolué pour devenir un professionnel hybride, alliant expertise financière, technologique et stratégique. Sa capacité à s’adapter rapidement aux innovations technologiques et aux nouveaux enjeux fait de lui un acteur central de la transformation digitale et durable des entreprises. L’évolution du métier se poursuit, avec l’intégration future de technologies émergentes telles que la blockchain ou l’informatique quantique appliquées à la finance.
Constat d’un monde toujours plus numérisé : naviguer et interagir en ligne s’apparente aujourd’hui à un jeu d’enfant pour la majorité d’entre nous !
Une bonne partie de nos activités du quotidien se font par l’intermédiaire d’une interface homme-machine : Travailler, se divertir, s’informer, interagir socialement ou même faire nos courses.
Pourtant, tout le monde n’accède pas à internet avec la même aisance : Difficultés de lecture, déficiences visuelles, handicaps moteurs, handicaps cognitifs, mauvais réseau et le plus présent : se sentir dépassée par l’immensité d’internet et la peur de faire une mauvaises manipulation.
Il existe une action prioritaire à effectuer pour réduire ces inégalités sociales : rendre accessible les interfaces et contenus en ligne.
Qu’est-ce que l’accessibilité numérique ? Pourquoi cette démarche est primordiale ? Qui est concerné ? Par où commencer et que faire ? Cet article a pour objectif de répondre à ces questions et de vous donner les arguments pour mettre ce sujet au premier plan, sa place légitime.
Qu’est ce que l’accessibilité numérique ?
L’accessibilité dans le numérique c’est donner la possibilité à tout un chacun, qu’importe sa situation, d’utiliser à 100% les fonctionnalités d’un service numérique.
Cela signifie que ce service doit être facilement accessible (pas caché et trop lourd), que son contenu est compréhensible par n’importe qui (pas de complexité inutile, pas d’indication par la couleur seulement) et qu’une personne en situation de handicap pourra l’utiliser à son plein potentiel.
L’accessibilité numérique ne concerne pas seulement les personnes handicapées mais plutôt toute personne qui se retrouve en situation de handicap. Cette subtilité peut paraître exagérée mais en réalité, elle est l’élément le plus important.
Pour rappel, constitue un handicap, toute limitation d’activité ou restriction de participation à la vie en société subie par une personne, en raison d’une altération substantielle, durable ou définitive, d’une ou plusieurs fonctions physiques, sensorielles, mentales, cognitives ou psychiques, d’un polyhandicap ou d’un trouble de santé invalidant.
Pourquoi parler d’accessibilité numérique ?
Dans un premier temps, depuis 2006, l’accessibilité numérique est considérée comme un droit fondamental dans la convention relative aux droits des personnes handicapées de l’ONU.
De fait, c’est un sujet phare qui est depuis ce moment-là réglementé. En effet, en France, la loi pour l’égalité des droits et des chances, la participation et la citoyenneté des personnes handicapées a, dès 2005, créé des obligations en matière d’accessibilité numérique pour les services numérique publics, et les a étendu à partir de 2019 aux entreprises dont le chiffre d’affaires excède 250 millions d’euros.
Lorsqu’on parle de service numérique, voici les services concernés :
les sites internet, intranet, extranet
les progiciels, dès lors qu’ils constituent des applications utilisées au travers d’un navigateur web ou d’une application mobile
les applications mobiles qui sont définies comme tout logiciel d’application conçu et développé en vue d’être utilisé sur des appareils mobiles, tels que des téléphones intelligents (smartphones) et des tablettes, hors système d’exploitation ou matériel
le mobilier urbain numérique, pour leur partie applicative ou interactive, hors système d’exploitation ou matériel.
Pour encadrer cette démarche d’accessibilité numérique, un référentiel national, s’appuyant sur les standards internationaux (WCAG) a été créé : le Référentiel Général d’Amélioration et d’Accessibilité (RGAA). Ce référentiel comporte 106 critères répartis en 13 thématiques (images, navigation, couleurs, etc.) qui permettent de rendre des services numériques utilisable, perceptible, compréhensible et robuste.
Malheureusement, même si une réglementation existe, la réalité en est tout autre.
Aujourd’hui, internet n’est pas accessible
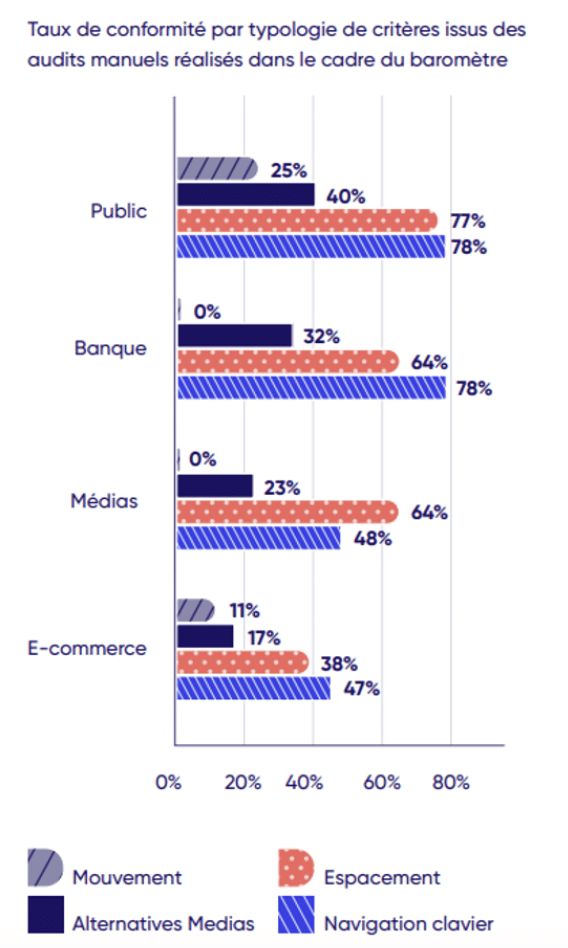
D’après un audit effectué par Contentsquare, sur les 50 sites français les plus visités, voici leurs taux de conformité :
Résultat des courses, 1 site sur 2 ne respecte pas les obligations d’affichage de conformité. Parmi eux, seulement 1 affiche un taux de conformité à 100% alors que plus de la moitié affichent un taux inférieur à 50%, ce qui signifie qu’il sont totalement inaccessibles.
Pour apporter plus de clarté, selon le RGAA, un site ayant un taux de conformité entre 0 et 50% est inaccessible, entre 50 et 99% il est partiellement accessible et à 100% il est totalement accessible.
Derrière ces services numériques non conformes, il y a des entreprises qui se justifient bien souvent de cette façon :
“ Nos utilisateurs ne sont pas handicapés ”
“ L’accessibilité ne concerne qu’un petit groupe d’utilisateurs “
“ L’accessibilité n’aide que les personnes handicapées “
Pourtant, lorsqu’on se renseigne sur le nombre de personnes en situation de handicap, on comprend rapidement que ces arguments sont tout bonnement faux.
Une personne sur trois est en situation de handicap
Aujourd’hui, 80% des handicaps ne sont pas visibles. Et en France :
2 millions de personnes ayant un handicap lié à la vue
3,3 millions de personnes daltoniennes
5,4 millions ayant des handicaps liés à l’audition
2,3 millions ayant des handicaps moteurs
5 à 6 millions ayant des handicaps intellectuels / mentaux
6,6 millions étant dyslexiques
Dans cette représentation de la population, on peut observer que lorsque l’on prend en compte les handicaps invisibles à l’œil nu, près d’un tiers de la population est en situation de handicap. En sachant cela, il est impossible de continuer à ignorer les bienfaits de l’accessibilité numérique.
Pas encore convaincu ? Voici d’autres arguments qui ne pourront que vous embarquer dans cette démarche.
Pourquoi l’accessibilité numérique est l’affaire de tous ?
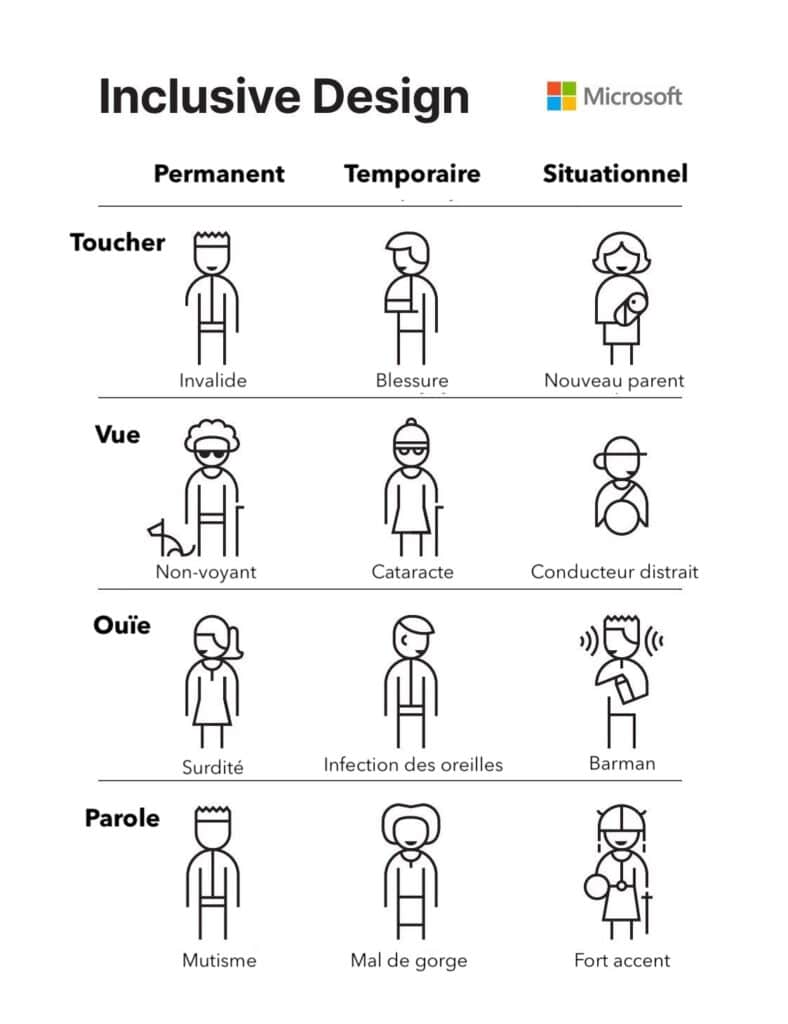
Les différents types de handicap
De façon temporaire ou situationnelle, un grand nombre de personnes pourraient bénéficier de l’accessibilité numérique.
Cette illustration de Microsoft Inclusive Design montre que derrière chaque handicap permanent, il existe des similitudes avec des situations que nous pouvons tous vivre. Par exemple, une personne chargée physiquement bénéficiera des fonctionnalités accessibles pour une personne ayant perdu un membre (validation sans contact). Une personne dans un environnement bruyant bénéficiera des fonctionnalités accessibles pour une personne en situation de surdité (sous-titres).
Mitiger la fracture numérique
Selon le CSA, un français sur 6 est en situation d’illectronisme, ce qui signifie qu’elle est en difficulté, voir incapable d’utiliser un service numérique en raison d’un manque ou d’une absence totale de connaissances à propos de leur fonctionnement et parfois même de la peur de mal faire. L’accessibilité numérique ayant pour but d’améliorer la compréhension, la perceptibilité et l’utilisabilité d’un service numérique, il est aujourd’hui indéniable qu’il est nécessaire d’en faire un sujet d’importance pour réduire la fracture du numérique.
Améliorer son image
En étant publiquement plus inclusif, on promeut l’engagement citoyen de l’entreprise. Cela permet d’attirer non seulement les clients, les investisseurs, etc; mais aussi de nouveaux talents en quête de sens.
Renforcer son référencement en ligne
Google (pour ne citer que ce moteur de recherche) peut pénaliser les sites inaccessibles, ce qui impacte négativement votre référencement. Si le robot d’indexation Google était humain, il cumulerait les handicaps :
Il serait en partie aveugle (il a besoin d’aide pour comprendre les images)
Il serait sourd
Et n’aurait pas la possibilité de percevoir les couleurs (comme un daltonien)
C’est donc en prenant en compte les bonnes pratiques d’accessibilité web que l’on améliore la compréhension du robot d’indexation et donc son classement sur les moteurs de recherche.
Être au service de l’écoconception
Penser accessible et inclusif dès la conception, c’est se concentrer sur les fonctionnalités les plus essentielles :
Se focaliser sur la clarté du contenu permet de rendre les services plus légers et donc moins consommateurs d’énergie;
Se focaliser sur l’utilisabilité permet :
D’être compatible avec différentes spécificités des terminaux utilisateurs (OS, navigateur, résolution d’écran, langues, etc.)
Et donc d’éviter le coût économique et environnemental du renouvellement des terminaux utilisateurs non adaptés au service.
Pour en savoir plus sur l’éco-conception, nous avons rédigé un article qui pourrait vous intéresser ici.
Brisons quelques mythes
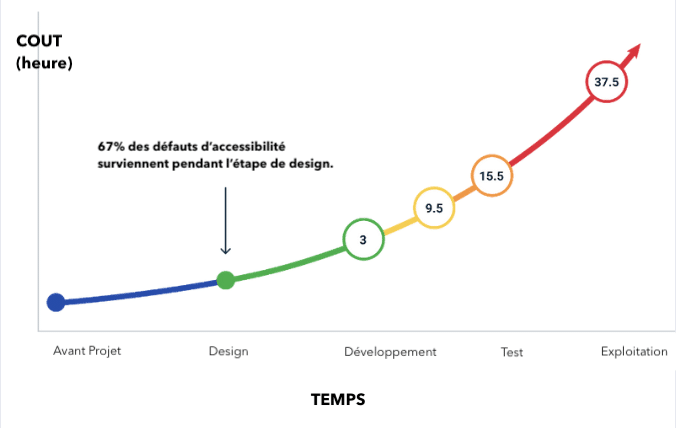
“Rendre un site web accessible est coûteux et prend du temps“ & “On peut rapidement ajouter l’accessibilité avant la Mise en Production“
Prendre en compte l’accessibilité numérique d’un service coûte de l’argent et prend du temps. C’est encore plus vrai lorsque c’est la première fois. En revanche, plus on prend tardivement en compte le référentiel d’accessibilité, plus son coût de mise en place sera élevé car nous serons obligés de refaire certains éléments non-accessibles.
C’est pour cette raison que l’accessibilité est un sujet à prendre en compte dès le début de la conception d’un service numérique.
“L’accessibilité numérique c’est de la responsabilité des développeurs”.
Non, toutes les parties prenantes d’un produit sont garantes de l’accessibilité.
Le client doit consacrer du temps et du budget à l’intégration de l’accessibilité dès le début du projet pour des soucis de conformité et d’utilisabilité.
Les équipes marketing et de vente doivent comprendre que le fait de rendre les sites web et les applications plus accessibles peut directement influencer l’utilisation ou non des services.
Les équipes de design, doivent garder en tête qu’elles influencent de façon directe les bases du code qui sera écrit et ont une grande influence sur l’accessibilité d’un service numérique. Dans certaines organisations, un développeur ne remettra pas (ou ne pourra pas remettre) en question ce qui lui est envoyé par ce groupe. Les concepteurs et les spécialistes UI/UX doivent donc s’assurer que leurs maquettes sont accessibles avant qu’un développeur n’écrive ne serait-ce qu’une ligne de code.
Les utilisateurs finaux, doivent être au centre des choix effectués, qu’importe leurs situations, leurs navigateurs, leurs appareils et leurs technologies d’assistance. Il est impossible de rendre votre service accessible à 100 % à toute cette variété sans leurs retours. Les utilisateurs doivent donc pouvoir signaler les problèmes qu’ils rencontrent sur le service et l’on se doit d’apporter les modifications nécessaires.
Et bien sûr tout ça est rendu possible grâce aux développeurs qui rendent utilisable le service !
Convaincu ? Voici comment se mettre en marche :
Commençons par les bonnes pratiques d’accessibilité numérique les plus importantes, catégorisées par les 4 piliers de l’accessibilité :
Perceptible :
Une mise en page simplifiée (démarche Mobile First)
Des légendes sous les médias
Des sous-titres dans les vidéos ou extraits audio
Utilisable :
Faciliter la navigation
Rendre accessible au clavier
Des délais suffisants pour agir
Compréhensible :
Des contrastes élevé et adapté aux handicaps visuels
Des polices lisibles par tous
Un fonctionnement prévisible pour un utilisateur lambda
Robuste :
Compatible avec tous types de terminaux
Compatible avec les périphériques d’assistance
Compatible avec le plus de système d’exploitation / navigateur possible
Comme dit précédemment, l’accessibilité est à prendre en compte avant même le début des développements du service. C’est au moment de l’expression de besoin et des choix de conception que nous avons le plus de chance de prendre en compte l’accessibilité numérique. En effet, faire machine arrière ensuite sera plus compliqué car cela reviendrait à refaire !
Donc, avant même de penser à l’expérience utilisateur et les interfaces, il est important :
D’ajouter l’accessibilité comme un critère déterminant dans le cahier des charges du projet
D’identifier les prestataires les plus apte à vous accompagner sur le sujet (certification, formations suivies, projets précédents)
De se fixer un objectif de conformité
Ensuite, pendant l’étape de conception il sera nécessaire :
De présenter l’enjeu de la démarche d’accessibilité numérique et partager les outils et référentiels utiles.
D’identifier des personae spécifiques d’un point de vue accessibilité afin qu’ils soient représentés comme des utilisateurs à part entière du service.
De proposer une expérience et une interface utilisateur suivant les critères d’accessibilité à l’aide d’une checklist du designer accessible qui permet de :
Rendre les contenus accessibles et inclusifs
Utiliser une palette de couleurs accessible
Faire des formulaires bien conçus
Rendre la navigation simple
Ensuite, pendant la phase de développement, l’objectif sera de rendre “utilisable” le design proposé.
Pour préparer au mieux cette étape, il conviendra dans un premier temps :
De présenter l’attendu en termes d’accessibilité numérique sur le projet aux équipes de développement (référentiel, outils, taux de conformité souhaité, …)
D’ajouter dans le « à faire » le respect des bonnes pratiques d’accessibilité
Dans une gestion de projet agile, prendre en compte la conformité au RGAA dans la Definition of Ready et la Definition of Done (ou équivalents).
Pendant le développement, il ne faudra pas oublier :
D’utiliser les outils à ma disposition pour rendre le service le plus accessible possible
De remonter à l’équipe lorsque des éléments à développer n’ont pas été pensés de façon à ce qu’ils soient accessibles.
De tester l’accessibilité des parcours de bout en bout avec des outils comme Lighthouse ou AXE DevTools pour le web.
Et avant la mise en production, un audit est à prévoir pour obtenir le score de conformité au RGAA et une déclaration d’accessibilité, si vous êtes concernés par les exigences. Enfin, pendant la période d’exploitation du service, l’accessibilité numérique sera à maintenir et à suivre tout le long de sa vie.
Deux points d’attentions sont à garder en tête :
L’accessibilité doit être améliorée à la suite des retours d’expérience d’utilisation du produit et des tests utilisateurs.
Il est également important de prendre en compte l’accessibilité dans les évolutions du produit pour répondre aux exigences légales.
L’accessibilité numérique est l’affaire de tous car :
Si on ne la prend pas en compte, on ferme la porte aux personnes en situation de handicap et celles qui ne sont pas à l’aise avec le numérique
Tout service numérique plus accessible est finalement plus lisible pour tout le monde
Si l’on n’embarque pas toute les parties prenantes de nos projets/produits numériques dès la phase de conception, les coûts liés à la mise en conformité peuvent exploser
Le sujet ne concerne pas strictement l’accès au numérique mais l’accès à la société.
L’accessibilité est un état d’esprit, une culture à développer et à suivre, pas quelque chose de ponctuel car sinon cela ne fonctionne pas. La démarche ne doit pas être un one shot sur quelques produits mais plutôt une démarche de bout en bout.
Chez Rhapsodies Conseil, nous proposons de vous accompagner dans la mise en place d’une démarche de Conception Responsable by design dans votre organisation.
Pour faire de cette démarche une réalité, nous pouvons intervenir à plusieurs niveaux :
La sensibilisation avec l’animation de Fresque de l’Accessibilité Web ou Fresque du Numérique
La formation avec nos modules entre 1 journée et 3 jours en fonction des profils de vos équipes et de leur maturité sur le sujet (Chef de projet (MOA, MOE), Designer, Développeur, Architecte, etc.)
La stratégie, construction et le déploiement d’un cadre de Conception Responsable adapté à vos processus et gouvernances existantes comme nous l’avons déjà fait dans plusieurs organisations publiques et privées.
Si cela vous intéresse, vous pouvez nous contacter !
Rhapsodies Conseil Maroc a accompagné un client du secteur bancaire.
Contexte et enjeux
Un programme a été lancé pour faire évoluer le SI en désimbriquant le Core Banking existant qui avait été étendu sur trop de fonctions et faire évoluer le SI au global. Le choix s’est porté sur une modularisation du SI, seule solution à même de permettre de répondre aux différents besoins d’évolution.
Rhapsodies Conseil a réalisé un audit sur ce programme et ses différents composants pour analyser les causes du retard et l’alignement sur les bonnes pratiques d’architecture de la cible
A la suite de cet audit, un accompagnement dédié sur l’architecture du programme et son suivi a été mis en place avec des experts de Rhapsodies Conseil.
Mission
Accompagner le programme et les projets au jour le jour
Arbitrer les décisions d’Architecture
Proposer des remédiations de la dette accumulée par les anciens arbitrages
Décrire la cible d’architecture et les paliers
Equilibre des choix entre les briques progicielles et développement
Désimbrication de la vente et de la gestion des produits du Core Banking
Mise en place d’une nouvelle solution de vente et de gestion des contrats
Mise en place d’un référentiel de gestion des produits, des tarifs et de la facturation
Mise en œuvre d’un portail conseiller unifié
Exposition des fonctions de conseil et de vente aux différents canaux
Intégration de ces solutions avec le reste du SI et des partenaires de la banque
Résultats
Un accompagnement dédié au programme par un architecte référent
Capacité d’influer sur les décisions du programme
Capacité d’échange haut niveau avec les éditeurs sur les briques stratégiques du programme
Autres success stories qui pourraient vous intéresser
Terraform, grand favori du public concernant les logiciels d’Infrastructure as Code est connu principalement comme étant Cloud Agnostic. Mais le connaissez-vous réellement ? Terraform c’est près de 5000 fournisseurs de plateformes, infrastructure ou Saas allant bien au-delà du Cloud et un rachat récent soulevant un problématique de souveraineté.
Quelles sont les limites de cet outil qui paraît pouvoir tout faire ? Comment marche t-il et où se trouve sa prévalence par rapport à ses concurrents ? Sa place de favori est déjà remise en question et cette dynamique semble bel et bien en marche..
Le fonctionnement de Terraform ainsi que ses limites
Bien que Terraform soit souvent qualifié d’outil cloud agnostic, cela ne signifie pas pour autant que le même code peut être déployé tel quel sur AWS, Azure ou OVH. En réalité Terraform nécessite une configuration spécifique pour chaque (cloud) provider.
Pour bien comprendre cette nuance, il est essentiel de revenir sur le fonctionnement de Terraform et de clarifier ce que signifie réellement le terme cloud – ou provider – agnostic dans ce contexte.
Terraform utilise le langage HLC (Hashicorp Langage Configuration) pour communiquer avec les plateformes des fournisseurs. Cette communication se fait par le biais d’appels vers les APIs mis en place par ces fournisseurs. En théorie Terraform peut communiquer avec toute plateforme ou service qui expose une API. Mais bien évidemment la plupart des plateformes dont on parle sont intégrées via des “providers Terraform”.
Les APIs des fournisseurs, que ce soit niveau protocole, services exposés, champs requis etc diffèrent les uns des autres entraînant inéluctablement une différence au niveau de la suite d’instructions demandée à Terraform pour chaque provider.
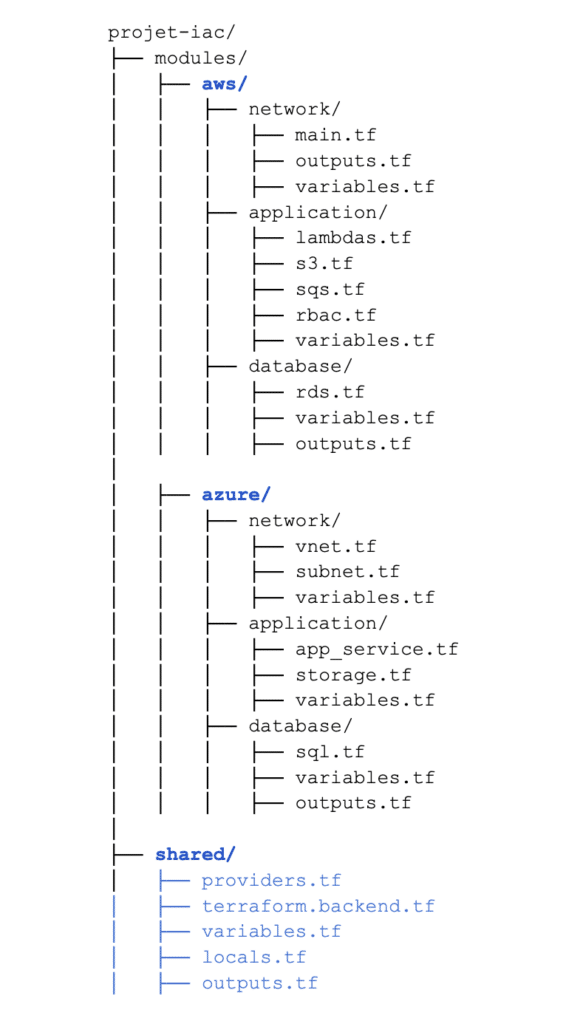
Comme on peut le voir dans l’arborescence suivante, on devra typiquement créer un dossier spécifique à chaque provider, en plus d’un dossier partagé pour des variables plus globales.
Le fait d’avoir tous les providers décrits dans le même projet nous permet d’établir une logique et des conditions sur quand et comment utiliser chaque provider. Terraform a bien évidemment d’autres avantages.
Utilisez pleinement Terraform
On l’a dit Terraform c’est près de 5000 providers dont les solutions souveraines OVH, Scaleway ainsi que les incontournables Kubernetes, Datadog, AWS, GitHub etc.
Cette diversité permet :
De combiner des infrastructures on-premise et cloud, permettant de gérer au même endroit l’intégralité des ressources d’un projet hybride.
En corollaire, optimiser les coûts en mettant en concurrence les services des différents fournisseurs (exp. stockage dans AWS, bases de données dans GCP)
Créer des configurations spécifiques et réutilisables: En choisissant d’exposer certains modules comme point d’entrée, l’équipe OPS ou Opérationnelle peut offrir aux équipes de développeurs une façon simple de créer des ressources en masquant toute la logique propre au fournisseur à l’intérieur desdits modules.
Exemple: Ici on implémente les modules application, database etc avec toute leur complexité “cachée”
De plus, Terraform est de type déclaratif, c’est-à-dire qu’il décrit l’état final de l’infrastructure: l’ordre dans lequel on déclare les ressources n’est donc pas important, ce qui peut faire une préoccupation technique en moins.
Enfin, Terraform permet de réduire la courbe d’apprentissage lors du lancement ou du basculement d’un projet vers de l’IaC.
Nous le verrons dans les lignes suivantes, l’IaC est également une façon non négligeable d’optimiser ses ressources.
Optimisation des ressources, résilience et numérique durable
Les outils d’IaC quels qu’ils soient permettent de décrire comment construire et donc reconstruire une infrastructure simplement en exécutant un code. Cette facilité offre de la résilience: si l’infrastructure est corrompue, il suffit de la reconstruire en ré-exécutant le code versionné “avant incident”.
Un autre avantage est qu’on peut se permettre de détruire totalement notre infrastructure au moment où l’on en a pas besoin, pour la reconstruire aussitôt que le besoin s’en re-fait sentir. Cela implique que l’on peut supprimer notre environnement de dev ou de pré-prod le week-end ou le soir en fin de journée pour la reconstruire à l’identique le lundi matin.
Cette économie de ressources génère des optimisations financières notamment pour les services facturés à l’heure et une utilisation plus responsable des ressources.
Souveraineté de la plateforme
L’acquisition récente de Hashicorp (la société derrière Terraform) par IBM pose un problème au niveau de la souveraineté.
Terraform propose trois offres :
Terraform CLI : Communautaire (chacun peut créer/rajouter un provider) et “Open Source” (voir note en fin d’article)
HCP Terraform : Terraform version SaaS, hébergé sur la plateforme Cloud de Terraform: la Hashicorp Cloud Platform
Terraform Enterprise : La version hébergeable dans nos propres datacenters ou cloud privés.
En matière de souveraineté, la discussion s’articule ici autour de la version Communautaire Terraform CLI qui, en plus d’être la plus populaire, est la seule qui ne soit pas propriétaire.
Ce rachat de Terraform par IBM donc, pourrait entraîner des changements de licences dans la version communautaire. Le mot d’ordre pourrait peu à peu devenir l’accroissement des bénéfices commerciaux au détriment de la communauté Terraform.
Et pour cela, pas forcément besoin d’un revirement de situation à 180°, des décisions à priori anodines pourraient contraindre la liberté d’agir sur la version communautaire et ainsi inciter à se tourner vers les versions payantes.
De plus, IBM ayant également sa propre plateforme Cloud, l’entreprise pourrait mettre celle-ci en avant, au détriment du multi-cloud à la Terraform. (1)
A noter le parallèle flagrant avec le rachat de Red Hat par IBM en 2019.
Vous avez la main…
La souveraineté des données est une préoccupation majeure de notre temps et force est de noter que la communauté est très résiliente à s’efforcer de proposer des solutions Open Source dès lors que celle-ci est menacée.
Depuis le changement en 2023 de la license de Terraform CLI, la version “Open Source” de Terraform vers la license BSL (Business Source License) qui restreint les usages à but de compétition commercial directe, une solution dérivée nommée Open TOFU a vu le jour et continue de prendre de l’ampleur avec le rachat récent.
Il est vrai que IBM assure à ce jour sur le site Hashicorp que Terraform CLI restera “Always Free”, mais les adages “la confiance n’exclut pas le contrôle”, “il ne faut pas pas mettre tous ses oeufs dans le même panier non souverain”, ainsi que le principe du “zero trust”, sont autant de beaux préceptes qu’il serait prudent de garder à l’esprit.
Dans un monde où les attentes des consommateurs deviennent de plus en plus variées, les entreprises ne peuvent plus se contenter d’une approche unique pour séduire leur clientèle. C’est ici qu’intervient la segmentation client, une méthode indispensable pour comprendre, cibler et fidéliser les consommateurs. Cette démarche, bien qu’essentielle, mérite d’être explorée en profondeur pour maximiser son impact.
Comprendre la segmentation client
La segmentation client consiste à diviser un marché en groupes homogènes d’individus partageant des caractéristiques similaires. Ces groupes, appelés segments, permettent aux entreprises de personnaliser leurs stratégies marketing et d’améliorer l’expérience client.
Mais pourquoi segmenter ? Tout simplement parce que tous les clients n’ont pas les mêmes besoins, attentes ou comportements d’achat. En segmentant, une entreprise peut éviter le gaspillage de ressources en se concentrant sur les segments les plus prometteurs et en élaborant des actions sur-mesure.
Approfondir les types de segmentation client
Segmentation démographique
Ce type de segmentation repose sur des données tangibles et mesurables comme l’âge, le sexe, la profession, le revenu ou le niveau d’éducation. Par exemple, une marque de cosmétiques peut créer une gamme différente pour les adolescents et une autre pour les seniors.
2. Segmentation géographique
Adapter une offre en fonction de la localisation géographique est particulièrement pertinent pour des entreprises internationales ou des commerces locaux. La culture, le climat ou encore les coutumes locales influencent grandement les comportements d’achat.
3. Segmentation psychographique
Moins visible mais tout aussi puissante, cette approche s’intéresse aux valeurs, au style de vie, aux centres d’intérêt et aux traits de personnalité des clients. Par exemple, une entreprise de vêtements de sport pourrait cibler les amateurs de fitness intensif différemment des pratiquants occasionnels.
4. Segmentation comportementale
Ici, les actions des clients prennent le dessus : fréquence d’achat, fidélité, réactions aux promotions ou sensibilité au prix. Ce type de segmentation permet de repérer les acheteurs réguliers, les chasseurs de bonnes affaires ou encore les ambassadeurs de marque.
5. Segmentation par valeur client
Les clients ne génèrent pas tous la même valeur pour une entreprise. En identifiant les clients les plus rentables, il devient possible de développer des stratégies de rétention et d’upsell pour maximiser leur contribution.
Les bénéfices concrets de la segmentation client
1. Mieux connaître sa clientèle
Grâce à une segmentation fine, une entreprise acquiert une connaissance approfondie de ses clients, ce qui lui permet de mieux anticiper leurs attentes et d’adopter une approche proactive.
2. Personnalisation accrue
En segmentant, il devient possible de proposer des messages, des offres et des expériences sur-mesure. Résultat : une relation client renforcée et une satisfaction accrue.
3. Amélioration des performances marketing
Les campagnes ciblées génèrent souvent des taux de conversion supérieurs, car elles parlent directement aux besoins spécifiques des clients. Moins de gaspillage, plus d’efficacité.
4. Fidélisation et rétention des clients
En répondant précisément aux attentes des segments les plus importants, une entreprise peut développer des relations durables et limiter le churn (perte de clients).
5. Découverte de nouvelles opportunités
L’analyse des segments peut révéler des marchés de niche ou des besoins jusqu’alors ignorés, offrant ainsi de nouvelles opportunités de croissance.
Les défis de la segmentation client
Malgré ses avantages, la segmentation client comporte certains défis :
Collecte de données : Une segmentation efficace repose sur des données fiables et actualisées. Les entreprises doivent donc investir dans des outils de gestion et d’analyse de données.
Complexité croissante : Plus les segments sont nombreux, plus il devient complexe de gérer et de personnaliser les stratégies. Une segmentation trop détaillée peut être contre-productive.
Évolution constante des segments : Les comportements et les attentes des clients changent avec le temps. Une surveillance régulière est nécessaire pour adapter les segments.
Les étapes pour une segmentation réussie
Pour réussir une segmentation client, il est essentiel de suivre une méthodologie rigoureuse :
1. Collecter et centraliser les données clients : cela inclut les données CRM, les enquêtes, les données transactionnelles et comportementales.
2. Analyser et identifier les critères pertinents : quels sont les points communs entre vos meilleurs clients ? Quels sont les freins à l’achat pour d’autres ?
3. Créer des segments clairs et exploitables : chaque segment doit être mesurable, significatif et atteignable. Il ne s’agit pas seulement de découper, mais de le faire intelligemment.
4. Tester et affiner les stratégies : testez vos campagnes sur différents segments pour comprendre ce qui fonctionne le mieux. Ajustez régulièrement vos segments et vos stratégies en fonction des résultats.
5. Suivre et mesurer les performances : l’efficacité d’une segmentation se mesure par des KPIs (Key Performance Indicators) tels que l’augmentation des ventes, le taux de conversion ou encore la satisfaction client.
Tendances actuelles en segmentation client
Segmentation basée sur l’intelligence artificielle (IA) : Les outils d’IA permettent d’analyser d’immenses quantités de données pour identifier des segments avec une précision accrue.
Segmentation dynamique en temps réel : Avec les avancées technologiques, il devient possible d’ajuster les segments en temps réel en fonction des comportements actuels des clients.
Segmentation éthique : Les consommateurs sont de plus en plus sensibles à la protection de leurs données. Une segmentation respectueuse et transparente est devenue un impératif pour les entreprises.
La segmentation client n’est pas seulement une technique marketing, c’est une philosophie qui place le client au cœur de la stratégie. En comprenant mieux les attentes de chaque segment, une entreprise peut non seulement optimiser ses performances, mais aussi construire une relation durable et de confiance avec ses clients. Investir dans une segmentation bien pensée, c’est investir dans un avenir où chaque client se sent unique et valorisé.
Elle est au rendez-vous de presque l’ensemble des salons, conférences, webinar ou encore pause-café avant les premières réunions de la semaine et tend à devenir le principe clef dans l’intégration ou la mise en place d‘une plateforme data : La gouvernance de données.
Le mot peut paraître abstrait, brutal et directif mais tout l’enjeu est justement de la vulgariser un maximum pour la partager et évangéliser son adoption.
Il faut bien avoir conscience que si vous rencontrez des incidents liés à la qualité, la cohérence ou la fiabilité de vos données aujourd’hui c’est probablement lié soit à un manque de gouvernance soit à un manque de suivi de cette gouvernance.
Parce que mettre en place une plateforme permettant de brasser des Tera de data c’est bien mais le faire avec des principes clefs et des règles de sécurités c’est mieux, nous allons voir quelques notions clefs pour pouvoir mettre en place une gouvernance réussie.
Dans 76% des cas, la gouvernance existe mais elle est vite négligée au profit du time to market conduisant souvent à une perte de confiance des sponsors voir du déficit commercial.
Kezako la gouvernance de données ?
Sortant d’une mission de presque 6 ans sur le SI Data Architecture & Engineering chez Givaudan, je vais tenter de vous en donner ma définition et ma vision afin de vous familiariser avec le sujet.
Tout en ayant conscience qu’il n’est pas aisé de donner une définition simple de la gouvernance de données sans tomber dans un premier travers qui est sa mécompréhension conduisant inévitablement à sa dévalorisation puis sa négligence, je tente quand même ma chance :
Au-delà d’un simple ensemble de règles ou d’un outil, d’un concept ou d’une méthodologie, la gouvernance est un cadre stratégique qui regroupe à la fois l’ensemble des principes humains et machines liés aux acteurs de la data mais aussi la garantie du respect des normes et processus liés à l’utilisation de ces données.
Elle regroupe l’ensemble des pratiques et processus permettant de créer, maintenir, sécuriser et faire évoluer l’ensemble des data et metadata d’un SI.
C’est à la fois une déclinaison du RACI lié à la plateforme data et en même temps l’implémentation de ses règles de maintenance et d’utilisation. Le tout n’étant pas exclusif à la plateforme Data, mais doit s’inscrire dans la gouvernance SI dans son entièreté.
La gouvernance de données ne décrit pas uniquement la gestion de la donnée mais la politique contribuant à la manipuler et les responsabilités de chacun afin d’éviter les imbroglios de qui ou quel job a maintenu quoi, comment et pourquoi ?
Et c’est un point crucial à mettre en place dès l’introduction d’une nouvelle typologie de données en nommant un ou des responsables de la gouvernance de cette donnée qui auront la charge de documenter et garantir les règles d’ingestion, d’accès, d’enrichissement, dédoublonnage, maintenance, diffusion pour en citer quelques unes et en les faisant évoluer au grès de la politique d’entreprise.
Qu’est qui ne fait pas partie de la gouvernance de données ?
La gouvernance n’oriente pas les choix de plateformes, la mise en place d’une infrastructure. Elle n’est pas une composante de l’analyse d’une donnée ou dans le choix d’un scénario projet.
Pourquoi la gouvernance ?
Vous l’aurez compris quand le sujet traite de politique cela fait souvent vite fuir le business qui sera pourtant l’atout clé dans l’évangélisation de la pratique.
Les problèmes liés à un manque de gouvernance ont souvent pour résultat une initiative prise hors du champ de responsabilité ou un manque de clarté amenant des interprétations diverses voire faussées.
Les principaux piliers clefs permettant d’apporter un ROI notable de la gouvernance sont selon moi :
La Gestion et maintenance des métadonnées : Pour vulgariser un temps soit peu, les métadonnées sont le passeport des données. Les bonnes pratiques consistent à définir un modèle de métadonnées, à documenter les données et à mettre en place un catalogue de données.
Qualité des données : La qualité est essentielle pour prendre des décisions business éclairées. Les bonnes pratiques incluent la mise en place de processus de validation, l’utilisation d’outils de profilage et de nettoyage, et la définition de métriques de qualité.
Sécurité : La protection des données est une priorité absolue. Les bonnes pratiques consistent à mettre en place des contrôles d’accès, à chiffrer les données sensibles, à réaliser des sauvegardes régulières et à mener des audits de sécurité.
Conformité : protocol sécurisé d’échanges de données HIPP / instances réglementaires lié au stockage et à l’utilisation de la donnée.Le respect des réglementations est obligatoire. Les bonnes pratiques incluent la connaissance des réglementations applicables, la mise en place de processus de conformité et la désignation d’un responsable de la protection des données.
Politique et Standards: partager un socle de définition des données clefs de l’entreprise
Fiabilité : garantir la véracité d’une donnée à n’importe quel moment et n’importe quel endroit du SI
Et dans la pratique ça donne quoi ?
Tout d’abord, vous devrez avoir en tête les étapes clés pour pouvoir définir le cycle de vie de la gouvernance :
Obtenir le soutien de la direction : La gouvernance des données est un projet d’entreprise qui nécessite l’engagement de tous les niveaux hiérarchiques.
Effectuer un audit des données existantes : Identifier les manques et les redondances pour déterminer les axes de transformations.
Définir une stratégie: Aligner la gouvernance avec les objectifs de l’entreprise.
Mettre en place un comité de gouvernance : Définir les rôles et les responsabilités de chaque acteur.
Sensibiliser les utilisateurs : Former les collaborateurs à l’importance de la gouvernance.
S’en suivent les bonnes pratiques pour s’assurer d’une mise en oeuvre efficace :
Impliquer les métiers : Les utilisateurs finaux doivent être impliqués dans la définition des règles de gouvernance.
Utiliser des outils adaptés : Choisir des outils de gouvernance qui répondent aux besoins spécifiques de l’entreprise.
Adopter une approche agile : La gouvernance doit être évolutive et s’adapter aux changements de l’entreprise.
Mesurer la performance : Définir des indicateurs clés de performance (KPI) pour évaluer l’efficacité de la gouvernance.
Les bénéfices de la gouvernance des données
Amélioration de la prise de décision : Les données fiables et accessibles permettent de prendre des décisions plus éclairées et de réduire les risques.
Augmentation de la productivité : Les équipes passent moins de temps à chercher des données et peuvent se concentrer sur des tâches à plus forte valeur ajoutée.
Réduction des coûts : La gouvernance permet d’éviter les erreurs coûteuses et d’optimiser l’utilisation des ressources.
Amélioration de la réputation : Une bonne gouvernance des données renforce la confiance des clients et des partenaires.
Les défis et les tendances
Les défis :
La complexité des environnements de données : Big data, cloud, IoT.
La résistance au changement : Impliquer les utilisateurs peut être difficile.
Le coût des investissements : La mise en œuvre d’une gouvernance peut représenter un coût important.
Les tendances :
L’IA au service de la gouvernance : L’intelligence artificielle peut automatiser certaines tâches de gouvernance.
La gouvernance des données dans le cloud : Les enjeux spécifiques du cloud.
La gouvernance des données personnelles : Le respect des réglementations comme le RGPD.
La gouvernance des données est un voyage, pas une destination. Elle nécessite un engagement continu de la part de tous les acteurs de l’entreprise. En suivant les bonnes pratiques et en s’adaptant aux évolutions technologiques, les entreprises peuvent tirer pleinement parti de leurs données et gagner en compétitivité.