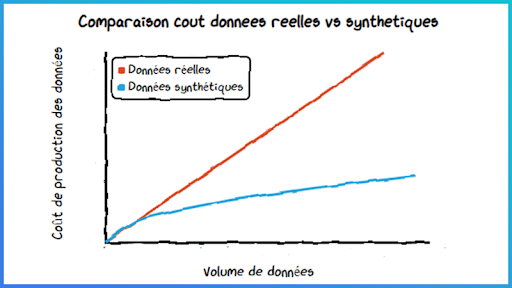
Dans un récent post de blog, le Gartner prévoit que d’ici 2030, 60% des données d’entrainement des modèles d’apprentissage seront générées artificiellement. Souvent considérées comme substituts de qualité moindre et uniquement utiles dans des contextes réglementaires forts ou en cas de volumétrie réduite ou déséquilibrée des datasets, les données synthétiques ont aujourd’hui un rôle fort à jouer dans les systèmes d’IA.
Nous dresserons donc dans cet article un portrait des données synthétiques, les différents usages gravitant autour de leur utilisation, leur histoire, les méthodologies et technologies de génération ainsi qu’un rapide overview des acteurs du marché.
Les données synthétiques, outil de performance et de confidentialité des modèles de machine learning
Vous avez dit données synthétiques ?
Le travail sur les données d’entrainement lors du développement d’un modèle de Machine Learning est une étape d’amélioration de ses performances parfois négligée, au profit d’un fine-tuning itératif et laborieux des hyperparamètres. Volumétrie trop faible, déséquilibre des classes, échantillons biaisés, sous-représentativité ou encore mauvaise qualité sont tout autant de problématiques à adresser. Cette attention portée aux données comme unique outil d’amélioration des performances a d’ailleurs été mis à l’honneur dans une récente compétition organisée par Andrew Ng, la Data-centric AI competition.
Également, le renforcement des différentes réglementations sur les données personnelles et la prise de conscience des particuliers sur la valeur de leurs données et la nécessité de les protéger imposent aujourd’hui aux entreprises de faire évoluer leurs pratiques analytiques. Fini « l’open bar » et les partages et transferts bruts, il est aujourd’hui indispensable de mettre en place des protections de l’asset données personnelles.
C’est ainsi qu’entre en jeu un outil bien pratique quand il s’agit d’adresser de front ces deux contraintes : les données synthétiques.
Par opposition aux données « traditionnelles » générées par des événements concrets et retranscrivant le fonctionnement de systèmes de la vie réelle, elles sont générées artificiellement par des algorithmes qui ingèrent des données réelles, s’entraînent sur les modèles de comportement, puis produisent des données entièrement artificielles qui conservent les caractéristiques statistiques de l’ensemble de données d’origine.
D’un point de vue utilisabilité data on peut alors adresser des situations où :
La donnée est coûteuse à collecter ou à produire – certains usages nécessitent par exemple l’acquisition de jeux de données auprès de data brokers. Ici, la génération et l’utilisation de données synthétiques permettent de diminuer les coûts d’acquisition et favorisent ainsi une économie d’échelle pour l’usage data considéré.
Le volume de données existant n’est pas suffisant pour l’application souhaitée – on peut citer les cas d’usage de détection de fraude ou de classification d’imagerie médicale, où les situations « d’anomalie » sont souvent bien moins représentées dans les jeux d’apprentissage. Dans certains cas, la donnée n’existe simplement pas et le phénomène que l’on souhaite modéliser n’est pas présent dans les datasets collectés. Dans ce cas d’usage, la génération de données synthétiques est toutefois à différencier des méthodes de « data augmentation », technique consistant à altérer une donnée existante pour en créer une nouvelle. Dans le cas d’une base d’images par exemple, ce processus d’augmentation pourra passer par des rotations, des colorisations, l’ajout de bruits… l’objectif étant d’aboutir à différentes versions de l’image de départ.
Il n’est pas nécessaire d’utiliser des données réelles, comme lors du développement d’un pipeline d’alimentation en données. Dans ces situations, un dataset synthétique peut être largement suffisant pour pouvoir itérer rapidement sur la mise en place de l’usage, sans se préoccuper de l’alimentation en données réelles en amont.
Mais comme vu précédemment, ces données synthétiques permettent aussi d’adresser certaines problématiques de confidentialité des données personnelles. En raison de leur nature synthétique, elles ne sont pas régies par les mêmes réglementations puisque non représentatives d’individus réels. Les data scientists peuvent donc utiliser en toute confiance ces données synthétiques pour leurs analyses et modélisations, sachant qu’elles se comporteront de la même manière que les données réelles. Cela protège simultanément la confidentialité des clients et atténue les risques (sécuritaires, concurrentiels, …) pour les entreprises qui en tirent parti, tout en levant les barrières de conformité imposées par le RGPD…
Parmi les bénéfices réglementaires de cette pratique :
Les cyber-attaques par techniques de ré-identification sont, par essence, inefficaces sur des jeux de données synthétiques, à la différence de datasets anonymisés : les données synthétiques n’étant pas issues du monde réel, le risque de ré-identification est ainsi nul.
La réglementation limite la durée pendant laquelle une entreprise peut conserver des données personnelles, ce qui peut rendre difficile la réalisation d’analyses à plus long terme, comme lorsqu’il s’agit de détecter une saisonnalité sur plusieurs années. Ici, les données synthétiques s’avèrent pratiques puisque non identifiantes : les entreprises ont ainsi le droit de conserver leurs données synthétiques aussi longtemps qu’elles le souhaitent. Ces données pourront être réutilisées à tout moment dans le futur pour effectuer de nouvelles analyses qui n’étaient pas menées auparavant ou même technologiquement irréalisables au moment de la collecte des données.
L’utilisation de services tiers (ex : ressources de stockage / calcul dans le cloud) nécessitent la transmission de données (parfois personnelles et sensibles) vers ce service. Il en va de même pour le partage de données avec des tiers pour réalisation d’analyses externes. En plus du casse-tête habituel de la conformité, cela peut (et devrait) être une préoccupation importante pour les entreprises, car une faille de sécurité peut rendre vulnérables à la fois leurs clients et leur réputation. Dans ce cas, utiliser des données synthétiques permet de réduire les risques liés aux transferts de données (vers des tiers, des fournisseurs de cloud, des prestataires ou encore des entités hors UE pour les entreprises européennes).
Un peu d’histoire…
L’idée de mettre en place des techniques de préservation de la confidentialité des données via les données synthétiques date d’une trentaine d’années, période à laquelle le US Census Bureau (organisme de recensement américain) décida de partager plus largement les données collectées dans le cadre de son activité. A l’époque, Donald B. Rubin, professeur de statistiques à Harvard, aide le gouvernement américain à régler des problèmes tels que le sous-dénombrement, en particulier des pauvres, dans un recensement, lorsqu’il a eu une idée, décrite dans un article de 1993 .
« J’ai utilisé le terme ‘données synthétiques’ dans cet article en référence à plusieurs ensembles de données simulées. Chacun semble avoir pu être créé par le même processus qui a créé l’ensemble de données réel, mais aucun des ensembles de données ne révèle de données réelles – cela présente un énorme avantage lors de l’étude d’ensembles de données personnels et confidentiels. »
Les données synthétiques sont nées.
Par la suite, on retrouvera des données synthétiques dans le concours ImageNet de 2012 et, en 2018, elles font l’objet d’un défi d’innovation lancé par le National Institute of Standards and Technology des États-Unis sur la thématique des techniques de confidentialité. En 2019, Deloitte et l’équipe du Forum économique mondial ont publié une étude soulignant le potentiel des technologies améliorant la confidentialité, y compris les données synthétiques, dans l’avenir des services financiers. Depuis, ces données artificielles ont infiltré le monde professionnel et servent aujourd’hui des usages analytiques multiples.
Méthodologies de génération de données synthétiques
Pour un dataset réel donné, on peut distinguer 3 types d’approche quant à la génération et l’utilisation de données synthétiques :
Données entièrement synthétiques – Ces données sont purement synthétiques et ne contiennent rien des données d’origine.
Données partiellement synthétiques – Ces données remplacent uniquement les valeurs de certaines caractéristiques sensibles sélectionnées par les valeurs synthétiques. Les valeurs réelles, dans ce cas, ne sont remplacées que si elles comportent un risque élevé de divulgation. Ceci est fait pour préserver la confidentialité des données nouvellement générées. Il est également possible d’utiliser des données synthétiques pour adresser les valeurs manquantes de certaines lignes pour une colonne donnée, soit par méthode déterministe (exemple : compléter un âge manquant avec la moyenne des âges du dataset) ou statistique (exemple : entraîner un modèle qui déterminerait l’âge de la personne en fonction d’autres données – niveau d’emploi, statut marital, …).
Données synthétiques hybrides – Ces données sont générées à l’aide de données réelles et synthétiques. Pour chaque enregistrement aléatoire de données réelles, un enregistrement proche dans les données synthétiques est choisi, puis les deux sont combinés pour former des données hybrides. Il est prisé pour fournir une bonne préservation de la vie privée avec une grande utilité par rapport aux deux autres, mais avec un inconvénient de plus de mémoire et de temps de traitement.
GAN ?
Certaines des solutions de génération de données synthétiques utilisent des réseaux de neurones dits « GAN » pour « Generative Adversarial Networks » (ou Réseaux Antagonistes Génératifs).
Vous connaissez le jeu du menteur ? Cette technologie combine deux joueurs, les « antagonistes » : un générateur (le menteur) et un discriminant (le « devineur »). Ils interagissent selon la dynamique suivante :
Le générateur ment : il essaie de créer une observation de dataset censée ressembler à une observation du dataset réel, qui peut être une image, du texte ou simplement des données tabulaires.
Le discriminateur – devineur essaie de distinguer l’observation générée de l’observation réelle.
Le menteur marque un point si le devineur n’est pas capable de faire la distinction entre le contenu réel et généré. Le devineur marque un point s’il détecte le mensonge.
Plus le jeu avance, plus le menteur devient performant et marquera de points. Ces « points » gagnés se retrouveront modélisés sous la forme de poids dans un réseau de neurones génératif.
L’objectif final est que le générateur soit capable de produire des données qui semblent si proches des données réelles que le discriminateur ne puisse plus éviter la tromperie.
Pour une lecture plus approfondie sur le sujet des GANs, il en existe une excellente et détaillée dans un article du blog Google Developers.
Un marché dynamique pour les solutions de génération de données synthétiques
Plusieurs approches sont aujourd’hui envisageables, selon que l’on souhaite s’équiper d’une solution dédiée ou bien prendre soi-même en charge la génération de ces jeux de données artificielles.
Parmi les solutions Open Source, on peut citer les quelques librairies Python suivantes :
Mais des éditeurs ont également mis sur le marché des solutions packagées de génération de données artificielles. Aux Etats-Unis, notamment, les éditeurs spécialisés se multiplient. Parmi eux figurent Tonic.ai, Mostly AI, Latice ou encore Gretel.ai, qui affichent de fortes croissances et qui ont toutes récemment bouclé d’importantes levées de fond
Un outil puissant, mais…
Même si l’on doit être optimiste et confiant quant à l’avenir des données synthétiques pour, entre autres, les projets de Machine Learning, il existe quelques limites, techniques ou business, à cette technologie.
De nombreux utilisateurs peuvent ne pas accepter que des données synthétiques, « artificielles », non issues du monde réel, … soient valides et permettent des applications analytiques pertinentes. Il convient alors de mener des initiatives de sensibilisation auprès des parties prenantes business afin de les rassurer sur les avantages à utiliser de telles données et d’instaurer une confiance en la pertinence de l’usage. Pour asseoir cette confiance :
Bien que de nombreux progrès soient réalisés dans ce domaine, un défi qui persiste est de garantir l’exactitude des données synthétiques. Il faut s’assurer que les propriétés statistiques des données synthétiques correspondent aux propriétés des données d’origine et mettre en place une supervision sur le long terme de ce matching. Mais ce qui fait également la complexité d’un jeu de données réelles, c’est qu’il capture les micro-spécificités et les cas hyper particuliers d’un cas d’usage donné, et ces « outliers » sont parfois autant voire plus important que les données plus traditionnelles. La génération de données synthétiques ne permettra pas d’adresser ni de générer ce genre de cas particuliers à valeur.
Également, une attention particulière est à porter sur les performances des modèles entrainés, partiellement ou complètement, avec des données synthétiques. Si un modèle performe moins bien en utilisant des données synthétiques, il convient de mettre cette sous-performance en regard du gain de confidentialité et d’arbitrer la perte de performance que l’on peut accepter. Dans le cas contraire où un modèle venait à mieux performer quand entrainé avec des données synthétiques, cela peut lever des inquiétudes quand à sa généralisation future sur des vraies données : un monitoring est donc nécessaire pour suivre les performances dans le temps et empêcher toute dérive du modèle, qu’elle soit de concept ou de données.
Aussi, si les données synthétiques permettent d’adresser des problématiques de confidentialité, elles ne protègent naturellement pas des biais présents dans les jeux de données initiaux et ils seront statistiquement répliqués si une attention n’y est pas portée. Elles sont cependant un outil puissant pour les réduire, en permettant par exemple de « peupler » d’observations synthétiques des classes sous-représentées dans un jeu de données déséquilibré. Un moteur de classification des CV des candidats développé chez Amazon est un exemple de modèle comportant un biais sexiste du fait de la sous représentativité des individus de sexe féminin dans le dataset d’apprentissage. Il aurait pu être corrigé via l’injection de données synthétiques représentant des CV féminins.
On conclura sur un triptyque synthétique imageant bien la puissance des sus-cités réseaux GAN, utilisés dans ce cas là pour générer des visages humains synthétiques, d’un réalisme frappant.
Il est à noter que c’est également cette technologie qui est à l’origine des deepfakes, vidéos mettant en scène des personnalités publiques ou politiques tenant des propos qu’ils n’ont en réalité jamais déclarés (un exemple récent est celui de Volodymyr Zelensky, président Ukrainien, victime d’un deepfake diffusé sur une chaine de télévision d’information).
Les autres articles qui peuvent vous intéresser
Pourquoi votre organisation a besoin de développer sa capacité de changement ?
Pourquoi votre organisation a besoin de développer sa capacité de changement ?
Ce qui était vrai hier, ne l’est plus forcément aujourd’hui. Et ce qui fonctionnait hier pourrait causer votre perte demain. Votre entreprise fait face à de nombreux enjeux au quotidien. À travers cet article, nous allons nous concentrer sur les déclencheurs qui incitent à considérer l’organisation sous un angle plus souple et flexible.
L’avantage n’est pas au premier à se mettre en mouvement. L’avantage est à celui qui apprend le plus vite. La seule façon de gagner est d’apprendre plus vite que n’importe qui d’autre.
Eric Ries
The Lean Startup
1881 : vous créez une petite entreprise de fabrication de pellicules photographiques sur la base d’une innovation de votre création : un procédé révolutionnaire de plaque sèche qui améliore considérablement la maniabilité des plaques auparavant recouvertes de gélatine. 4 ans plus tard, vous créez le premier film souple transparent qui permet aux photographes du monde entier de vous envoyer leurs films pour que vous les développiez. Vous devenez leader sur le marché de la photographie. 1907 : votre entreprise compte déjà 5000 salariés. 1927 : en 20 ans, votre entreprise a quadruplé sa taille, passant à 20000 employés.
1950 : à la sortie de la guerre, après avoir racheté Pathé quelques années plus tôt, vous êtes à la tête d’une entreprise florissante. Un inventeur, Edwin Land, vient vous proposer une idée : un appareil photo avec des pellicules qui se développent en quelques minutes après la prise de vue. Peu convaincu, vous le laissez partir. Il fondera sa propre compagnie : Polaroid…
1972 : toutes les idées de vos collaborateurs sont maintenant brevetées. L’un d’entre eux développe un capteur numérique qui permet de stocker les photos sur un support informatique. La technologie est naissante, la qualité médiocre par rapport aux appareils argentiques existants. Vous n’y croyez pas. 3 ans plus tard, vous abandonnez le projet et enterrez cette technologie. En tout, votre entreprise aura déposé 1100 brevets sur l’imagerie numérique.
2012 : le lancement de quelques appareils photos numériques sur un marché déjà en pleine explosion et sur lequel vous avez du mal à vous faire une place ne suffira pas à vous sauver. Vous êtes déclarés en faillite. Tous vos brevets sont rachetés pour 1/4 de leur valeur par des sociétés comme Apple, Google ou votre principal concurrent : Fuji.
Vous aurez reconnu l’histoire de Kodak, souvent évoquée pour montrer comment un mastodonte âgé de plus d’un siècle peut s’effondrer car il n’a pas su s’adapter à un changement de paradigme technologique. Alors que de plus en plus de clients étaient séduits par la facilité d’utilisation et le côté pratique de l’appareil photo numérique (quitte à accepter une baisse de qualité), Kodak est resté campé sur sa stratégie argentique et a continué à investir sur la qualité de ses pellicules et de ses appareils photos. Au moment où Kodak s’en est rendu compte, il était trop tard pour s’adapter aux nouvelles orientations du marché. La marche était devenue trop grande.
Le principal concurrent de Kodak, Fuji, possède dans son ADN les secrets d’une histoire qui dure encore aujourd’hui. Créé en 1934, Fuji fabrique des pellicules photo et cinéma. En 1986, il lance un produit innovant qui sera un succès commercial : l’appareil photo jetable. Financé par ce succès, Fuji lance en 1988 son premier appareil numérique et en 1994 son premier appareil reflex numérique (allié avec Nikon). Néanmoins ce marché hyper concurrentiel des appareils numériques et la quasi disparition du marché de la pellicule argentique ne lui permet pas de maintenir son niveau de revenu. En 1997, Fuji décide de se diversifier et lance sa première machine pour imprimer simplement les photos numériques directement dans les boutiques (Minilab Frontier). Ils deviendront leader de ce marché. En 2006, l’entreprise lance le FinePix S5 Pro, un boitier réflex très apprécié par les professionnels. Ce produit fait de Fuji un acteur de référence de ce marché de niche, très rentable.
Au milieu des années 70, Harley-Davidson était à 3 mois de la faillite. Une nouvelle direction va se concentrer non plus uniquement sur le produit mais sur tout l’écosystème : le lifestyle ! Accompagnée d’une profonde transformation interne, avec beaucoup plus d’autonomie pour ses salariés, l’entreprise va rapidement redresser la barre. En 2005, la capitalisation boursière de Harley-Davidson va dépasser celle du géant General Motors.
Ces exemples nous montrent que le risque de faillite ou de disparition est important pour tout type d’entreprise, des plus petites et plus jeunes aux plus grandes et plus anciennes, dès lors qu’elles cessent de s’adapter aux changements et restent sur leurs acquis. L’avènement d’internet, sur les 20 dernières années, a intensifié ce phénomène où l’on voit de nouveaux acteurs arriver et chambouler des marchés historiques (par exemple : N26 ou Revolut dans le monde bancaire). Avez-vous déjà entendu parler de Meero ? Cette start-up parisienne quasiment inconnue est spécialisée dans la mise en relation de photographes. Elle a effectué en juin 2019 la plus grosse levée de fond française (205 millions d’€). Aucun marché n’est à l’abri.
Ce dynamisme actuel doit avant tout être vu comme une opportunité, celle d’explorer de nouveaux sentiers en expérimentant en permanence pour trouver des réponses aux besoins de vos clients. Les évolutions de stratégie qui ont fait le succès des entreprises ci-dessus sont le fruit d’une organisation performante qui plébiscite l’innovation et l’adaptabilité.
2. Pour être plus performant
Sans solidarité, performances ni durables ni honorables.
François Proust
Maximes à l’usage des dirigés et de leurs dirigeants
Nous entendons souvent nos clients nous indiquer qu’ils veulent se transformer pour être agile. Mais être agile n’est pas une fin en soi. C’est plutôt un facteur déterminant pour améliorer les performances de l’entreprise.
Les leviers de performance sont propres à chaque entreprise : satisfaction clients et/ou collaborateurs, time-to-market, qualité, positionnement marché, gestion du risque, innovation, stratégie produit, collaboration, bien-être… Ces leviers sont très nombreux et chaque entreprise doit définir les siens.
Une partie non négligeable de la performance est liée à la culture et aux valeurs de l’entreprise. C’est ainsi que l’entreprise FAVI a subsisté dans un petit village de Picardie. Sa raison d’être ? Le maintien de l’emploi dans cette zone sinistrée. Un de ses leviers de performance est donc le maintien de l’emploi dans ce bassin.
Nous avons vu dans l’exemple du chapitre précédent qu’il ne suffit pas d’être (extrêmement) performant à un instant t, il est nécessaire de viser un niveau de performance sur une longue durée. Pour cela, la manière dont votre entreprise pilote sa performance, ainsi que la manière de produire et de développer de nouvelles idées, vont être prépondérantes. Nous en reparlerons dans la 2ème partie.
3. Pour continuer à grandir
Vessels large may venture more, but little boats should keep near shore.
Benjamin Franklin
The Way To Wealth
En grandissant, les entreprises font souvent face à des problèmes similaires. Lorsqu’elles atteignent certains paliers en nombre d’employés, les règles du jeu changent.
Ainsi, à partir de 30 personnes, les dirigeants font face au premier défi : la délégation. Il est impossible de continuer à tout gérer à 2-3 fondateurs. Continuer à grandir passe par une bonne distribution des activités, et des responsabilités qui vont avec.
À partir de 100 personnes, apparait un nouveau défi : comment réussir à scaler son organisation. Un des premiers signaux est qu’on commence à ne plus connaître tout le monde. De nombreux chefs d’entreprises nous ont indiqué avoir été surpris un jour de croiser quelqu’un dans leur entreprise qu’ils ne connaissent pas et qui pourtant y travaille. Un autre signal souvent observé est l’émergence d’une concurrence interne : 2 équipes peuvent travailler sur un même sujet sans le savoir. La structure de communication n’est plus adaptée. Cela doit déclencher un déclic et un travail important est nécessaire pour mieux diriger les flux d’information et la gestion des priorités.
A partir de 500 personnes, le niveau de complexité de l’organisation explose. Les interactions peuvent devenir difficiles entre départements qui peuvent avoir tendance à se replier sur eux-mêmes, quitte à créer un fonctionnement en silos. Les collaborateurs voient s’accumuler les couches hiérarchiques au-dessus d’eux, perdant ainsi le contact avec les dirigeants. Maintenir la culture d’origine est souvent difficile car des micro-cultures émergent et le nous contre eux peut prendre le pli sur la collaboration.
4. Pour renforcer la culture
Culture eats strategy for breakfast.
Peter Drucker
La culture d’une entreprise correspond à l’ensemble des comportements qui sont promus et encouragés au sein de l’organisation. Elle se traduit à travers les interactions entre collaborateurs dans un contexte donné.
La culture va agir comme un élément fédérateur pour l’entreprise et permettre de construire un liant entre les collaborateurs, nouveaux ou anciens. Elle constitue les fondations ou les piliers sur lesquels les collaborateurs peuvent s’appuyer pour prendre les (meilleures) décisions au quotidien.
Néanmoins, il faut garder à l’esprit qu’une culture s’incarne plus qu’elle ne se décrète. Ce sont les comportements du quotidien qui la matérialisent. De nombreuses entreprises disposent même de plusieurs cultures qui cohabitent, par exemple à la suite de rachats, fusions ou dans une organisation multi-sites. Poussées à l’extrême, ces cultures peuvent rendre l’entreprise “schizophrène” et alimenter une compétition interne qui va au détriment de la performance collective de l’entreprise. C’est particulièrement vrai quand des équipes qui travaillent de manière différente (outils, méthodes, comportement et donc culture) se retrouvent à collaborer ensemble.
L’enjeu est donc de (re)mettre à plat la culture de l’entreprise, de la rendre compréhensible et palpable, afin d’unifier les collaborateurs autour d’un projet commun.
5. Pour (ré)engager les collaborateurs
Un employé responsabilisé et écouté sera mieux dans son travail, son attachement à l’entreprise grandira et il aura fatalement une meilleure relation avec les clients.
Vineet Nayar
Les employés d’abord, les clients ensuite
Des études sur le niveau d’engagement moyen dans le monde entier montrent des résultats assez déstabilisants.
Ainsi, en 2017 en France, seuls 6% des employés étaient dans la catégorie «activement engagés». Cela représente 1 personne sur 16 impliquée et enthousiaste dans son travail.
69% des employés étaient «désengagés». Cette catégorie d’employés vient au travail avec une seule idée en tête : chercher son salaire, ne pas prendre d’initiatives et en repartir le plus tôt possible.
Enfin 25%, soit 1 employé sur 4, étaient « activement désengagés ». Cela signifie qu’ils sont tellement déçus et démotivés par leur entreprise qu’ils passent leur temps à détruire le travail et la motivation des autres.
Mettre en place un modèle d’organisation qui favorise l’émergence de collaborateurs engagés va aider à améliorer la performance de votre entreprise.
6. Pour (re)mettre le client au centre
Faites du service au client une priorité pour toute la société et pas seulement pour un département de l’entreprise. Par ailleurs, une attitude de service client doit venir du sommet de la hiérarchie.
Tony Hsieh
PDG de Zappos
Nombre de ces maximes ornent les murs des entreprises pour rappeler à tous que, avant tout, le client -celui qui paie pour notre produit ou service – doit être au centre de nos préoccupations.
Si votre attention de dirigeant ne doit pas forcément être prioritairement affectée aux clients (voir le livre Les employés d’abord, les clients ensuite de Vineet Nayar), il est évident que les clients sont essentiels au développement de l’entreprise.
Dans certaines entreprise, il arrive que les jeux de pouvoir prennent le dessus sur le bon sens. Par exemple, une direction va développer ses propres processus d’innovation sans consulter la direction en charge de l’innovation, créant de fait des projets concurrents au sein de la même entreprise. Et si on peut considérer que de la concurrence naissent parfois d’excellentes idées, elle conduit probablement plus fréquemment à dépenser l’énergie (et donc l’argent) à mauvais escient au sein d’une même entreprise. Se concentrer sur son client nécessite de le connaître, décrypter ses besoins, et donc de multiplier les points de rencontre avec lui, et ce à tous les niveaux de l’entreprise.
Il ne faut pas non plus oublier que votre client – celui qui utilise votre produit ou service – n’est pas nécessairement à l’extérieur de votre entreprise. D’une part, vous avez des collaborateurs qui sont des utilisateurs de votre produit ou service. D’autre part, vous avez des produits ou services qui sont conçus directement pour vos collaborateurs.
Être assis côte à côte avec son client est un avantage trop peu utilisé. Il n’est pas normal de développer des applications internes totalement inadaptées aux besoins des utilisateurs, qui, bien que logés dans le même bâtiment, n’auront jamais été sollicités. Cela va se traduire par des effets négatifs sur la motivation des équipes : les utilisateurs enragent que le produit ne leur convienne pas, tandis que l’équipe qui a fabriqué le produit récupère un flot de critiques et de demandes de modifications qui gâche leurs efforts.
7. Pour préparer l’avenir
Préparer l’avenir ce n’est que fonder le présent. Il n’est jamais que du présent à mettre en ordre. A quoi bon discuter cet héritage. L’avenir, tu n’as point à le prévoir mais à le permettre.
Antoine de Saint Exupéry
Si vous êtes les fondateurs de votre entreprise, et que vous lisez ces lignes, vous avez certainement déjà franchi certains des paliers de croissance évoqués précédemment. Vous en êtes peut-être même à cette étape de votre vie où après 10-15-20 ans à avoir des activités opérationnelles, vous souhaitez «prendre du recul». C’est normal.
Et c’est parfois compliqué car il existe un risque à confier les clés du camion à quelqu’un qui pourrait déconstruire tout ce que vous avez bâti. Pour éviter les déconvenues, au lieu de confier ces clés à un nouveau chauffeur, vous pouvez construire un camion autonome.
Déjà parce que l’aventure de transformation est une aventure passionnante : elle vous permet de sortir de l’opérationnel et vous fera (re)découvrir votre entreprise sous un jour nouveau. Cela peut vous remotiver et vous apprendrez beaucoup.
Ensuite, construire une entreprise autonome, c’est la préparer à passer les tempêtes qui l’attendent. L’organisation en réseaux qui caractérise ces formes d’entreprises amène une meilleure capacité de résilience. Cela vous rassurera au moment de réellement passer la main.
Rhapsodies Conseil a participé à la table ronde FPF organisée par France Payments Forum le 8 avril 2021. Lors de cet événement, Hervé de France Payments Forum, Damien de Galitt, Sami de Hipay, Jean-Michel de Mercatel, Aude de Market Pay, Hervé de Arkea, Régis de Worldline et Ikbel, notre Senior Manager et expert Digital Payment Experience ont échangé sur les nouveaux modes de paiement en point de vente.
Ce sujet, bien que les événements liés à la pandémie de COVID-19 soient d’actualité, a été choisi étant donné que la Commission Européenne a établi une nouvelle stratégie de paiement.
Le débat présenté a permis de montrer les scénarios potentiels d’évolutiondes paiements au point de vente et les préalables qu’il faudrait lever pour les réaliser.
Vous souhaitez (re)voir la table ronde en partie ou en intégralité? Cliquez sur le bouton play situé ci-dessous.
Industrialiser les processus et automatiser les actions de tous les acteurs du back-office
Apporter de la visibilité sur le suivi des demandes et des incidents ; Piloter vos prestataires infogérants.
Anticiper les incidents et les changements grâce à une CMDB efficace
Gérer et maîtriser son parc informatique matériel et logiciel (ITAM et SAM) et réduire ses dépenses
Proposer la meilleure expérience utilisateur possible tout en renforçant l’attractivité de votre portail de services et en augmentant l’autonomie de vos collaborateurs (Self-Care)
Optimiser les coûts CAPEX & OPEX et le ROI sur vos outils ITSM/ESM
Augmenter la valeur perçue par vos utilisateurs de la chaîne de support et de delivery des DSI
Nos offres
Définir la stratégie ESM
Audit et mesure de la maturité
Co-construction de la stratégie digitale ESM*
Etude et préconisation d’une trajectoire cible
*ESM = Enterprise Service Management (ITSM/ ITAM/ ITOM/ PPM…)
Optimiser les processus
Audit et analyse de l’existants
Optimisation ou refonte des processus selon les référentiels ITIL
Définition de l’organisation cible alignée avec les nouveaux processus
Rationaliser l’usage des outils
Cartographie et analyse des outils existants
Sourcing et accompagnement à la contractualisation de l’outillage et/ou de prestations d’intégration
Préconisation et alignement des outils par rapport aux besoins fonctionnels et aux bonnes pratiques
Accompagnement pour la mise en place du plan d’actions
Pilotage de la mise en oeuvre
Gouvernance dédiée autour des projets ESM
Suivi de la performance des services : éditeur / prestataires intégrateurs
Mise en place d’un plan de conduite du changement
Des bénéfices clés pour votre organisation
Amélioration des niveaux de services
Standardisation des processus à hauteur de 80%
Amélioration de l’expérience utilisateur (accès aux services en 3 clics, augmentation de l’autonomie et du self-care)
Atteinte des objectifs de conformité des actifs IT
Norme ISO 20022 : Comment s’y adapter quand on est métier compliance ?
Norme ISO 20022 : Comment s’y adapter quand on est métier compliance ?
Comment s’adapter à ce changement quand notre métier est de surveiller le caractère licite de millions d’opérations, qui plus est sur une variété de sous-jacents ?
Échange de flux financiers, transferts internationaux, nouvelle structuration de données, règles, outils. Tout est dit.
Comment s’adapter à ce changement quand notre métier est de surveiller le caractère licite de millions d’opérations, qui plus est sur une variété de sous-jacents ?
Migration ISO 20022 et métier compliance, quèsaco ?
La société SWIFT administre la norme ISO 20022. A ce titre, elle publie les guidelines qu’il convient de respecter dans le cadre des échanges de flux.
ISO 20022 est une norme régissant les échanges de données entre institutions financières.
C’est logiquement que SWIFT endosse le rôle d’administrateur car c’est cette même société qui fournit la solution de messagerie du même nom. Autrement dit, SWIFT donne le LA sur la structure des données de paiements.
La messagerie SWIFT permet d’échanger les instructions de transfert de fonds :
soit vers un système de règlement régional (TARGET2 pour les flux en EUR des banques de la zone),
soit vers les arcanes du correspondant banking pour les flux cross border (Devise ou hors zone SEPA principalement)
La migration concerne ces deux types de transfert : de gros montants en EUR pour Target2 ou les opérations internationales pour le correspondant banking (CBK).
Les processus de conformité sont essentiels. Le changement de format ne doit pas dégrader les niveaux de conformité. Pour assurer cette continuité, appliquer la migration ISO20022 nécessitera de bien identifier les travaux d’évolution à promouvoir…
De quoi parlons-nous exactement ? Comme évoqué plus haut, la migration concerne plusieurs périmètres.
Le premier T2/T2S, du système Target2, commence dès novembre 2021. Certains établissements parlent même de Big Bang.
Le second périmètre concerne les flux internationaux. Swift déploie le format MX, implémentant la norme ISO 20022, avec pour échéance Novembre 2025..
Les participants directs à Target 2 ont commencé les phases de tests de place pour être prêts en novembre 2022. Tout ne sera pas pour autant conforme à la cible à cette date, en raison des impacts dans les systèmes pour alimenter les nouvelles structures de données : en particulier un mode « like for like » pourra être toléré jusqu’à novembre 2025 sur les adresses, qui ne peuvent être simplement restructurées à partir des seuls messages MT actuels.
Les équipes métier sont directement concernées par ce changement de norme. C’est en particulier le cas des équipes Compliance.
Quels sont les impacts du changement ISO 20022 pour la compliance ?
La démarche d’étude d’impacts et des actions peuvent se mener sous 3 axes :
1. Les impacts du changement ISO 20022 sur les données
Construire la table de concordance entre le format historique et le format cible
Construire la table de concordance entre le format historique et le format cible permettra d’établir le socle pour assurer le maintien du service.
De quelles données ai-je besoin aujourd’hui pour alimenter mes indicateurs ?
Où se situeront mes données demain ?
Le schéma fonctionnel pour les transactions internationales, lui, ne changera pas. Le circuit des messages d’instruction des ordres de paiements pour compte propre ou pour compte des clients de l’établissement s’opère de la manière suivante :
Exemple de messages édités lors d’un flux de paiement
L’exploitation des données de paiements est dépendante des éléments permis par la norme.
Les champs significatifs d’un message MT 103 (message de paiement) aux yeux de la conformité sont structurés de la manière suivante :
Champ 20 : La référence de la transaction pour la banque émettrice
Champ 23B : Le code du type d’opération bancaire
Champ 32A : Contient le montant, la devise ainsi que la date de valeur de la devise utilisée pour la transaction
Champ 33B : Spécifie le montant et la devise de l’opération (contrairement au champ 32A, celui-ci est facultatif)
Champ 50 : Mentionne l’émetteur de la transaction
Champ 57 : Spécifie l’institution financière du bénéficiaire
Champ 59 : Mentionne le bénéficiaire
Champ 70 : C’est un champ libre contenant des informations complémentaires que l’émetteur veut transmettre au bénéficiaire, par exemple un numéro de facture
Champ 71 : Détermine quelle partie de la transaction prend en charge les frais de traitement de la transaction
S’approprier les innovations
Comme nous pouvons le voir ci-dessus, le contenu des messages à l’ancien format ne fait pas mention de tous les acteurs impliqués dans la transaction.
La norme ISO 20022 apporte une réponse, avec l’ajout de nouvelles données relatives aux bénéficiaires effectifs et aux émetteurs originaux. Le message MT s’appellera demain Pacs 008 comme le montre le schéma suivant :
Mention des acteurs dans un paiement par type de message
Cet apport est précisément une réponse de conformité à la suite du scandale des Panama Papers de 2016, où la fraude s’effectuait notamment par le biais de virements ne mentionnant pas les émetteurs et bénéficiaires effectifs.
Les innovations seront dorénavant développées à partir du format MX. Parmi celles-ci, nous pouvons évoquer l’utilisation d’un nouvel encodage pour ces flux financiers, UTF-8 qui élargit le panel d’alphabets utilisables.
A titre d’illustration sur une transaction internationale, les noms peuvent être altérés lorsqu’ils passent d’un système de caractères tel que le japonais à notre alphabet latin, comme l’illustre l’exemple ci-dessous :
Avec l’utilisation de l’ISO 20022 et l’adaptation de la chaîne de communication entre les applications, de nouveaux alphabets sont disponibles de bout en bout. Cela permettra d’améliorer la surveillance des flux.
On peut prendre par exemple des personnes portant des noms différents selon les transcriptions alphabétiques résidentes dans des pays disposant d’alphabets différents.
D’autres innovations sont envisageables, hors conformité, comme l’automatisation des réponses de SWIFT GPI et l’uniformisation des plateformes du système TARGET.
Ces innovations au niveau Compliance devront toutefois tenir compte des réglementations locales (paradis fiscaux, …) qui pourraient minimiser l’usage de certaines balises, sous couvert de confidentialité… ISO 20022 est une norme permettant d’améliorer l’efficacité de la conformité, mais ne peut pas fonctionner dans ce but toute seule, sans l’aval des régulateurs des pays dans lesquels elle opère.
2. Les impacts du changement ISO 20022 sur les indicateurs
L’objectif de la conformité est de détecter les transactions illicites.
Aujourd’hui, cette mission requiert des revues manuelles. Les traitements urgents sur l’analyse des faux-positifs et la détection des faux négatifs monopolisent un nombre important de ressources.
Comment optimiser ces actions ? Comment détecter les transactions illicites ?
Les données alimentent les indicateurs de compliance. Modifier les données source a un impact sur la fiabilité des indicateurs.
Construire ou mettre à jour la matrice des indicateurs
Les indicateurs de Sécurité Financière servant à la LCB-FT, au KYC et au respect des Sanctions et Embargos ont besoin d’être organisés (comme l’illustre l’exemple de matrice d’indicateurs ci-dessous) :
Les indicateurs génèrent des alertes sur la base de la détection de données contenues dans les messages de paiement. Aussi, l’efficacité de la Sécurité Financière ne repose pas uniquement sur les indicateurs mais sur la qualité des données sur lesquelles ils s’appuient pour émettre leurs alertes ou non. D’où la pertinence d’avoir une bonne adhérence entre les indicateurs d’une part, et les données normées ISO 20022 de l’autre.
Construire ou mettre à jour la matrice d’applicabilité
Il convient d’appliquer la conformité selon le métier et les normes de la filiale afin de s’assurer de l’optimisation des coûts et du temps nécessaires à l’application de la conformité.
Il y a des enjeux de priorité différents. Concernant la conformité, la priorité n°1 est de ne pas être en situation de non-conformité. Les éléments restants ne sont pas bloquants, mais peuvent en effet augmenter les coûts et le coefficient d’exploitation.
3. Les impacts du changement ISO 20022 sur les applications
Le capot du moteur d’échange des établissements financiers sera ouvert pour faire évoluer le Core Banking System (CBS) et ses applications en adhérence. Parmi ces applications figurent celles du métier Compliance.
Analyser le schéma d’architecture applicative et fonctionnelle
Cependant, afin de profiter du potentiel de la nouvelle norme, la variété des outils servant à la conformité tend vers la nécessité d’une stratégie adaptée à leurs usages.
Ceux-ci communiquent avec des formats différents, comme l’illustre le schéma ci-contre à titre d’exemple. Cela rend chaque mise à jour et connexion complexe, nécessitant du temps et de l’expertise.
Étudier l’impact des changements de formats permet d’identifier les éléments des messages de paiement se retrouvant dans les outils.
Les applications de filtrage analysent les données du Core Banking System. Ces données peuvent être utilisées par d’autres applications.
Évaluer le niveau de transcodage dans les applications et les pivots
La communication se fait entre des applications fonctionnant avec des langages de programmation différents, générant des impacts de retranscription.
Dans beaucoup de cas, des pivots de transcodification ont été mis en place pour permettre le transfert de données entre les applications.
Bien évaluer la qualité de transcodage entre les applications et les pivots permettra de faire des choix face au chiffrage des évolutions.
Faire évoluer les applications et interfaces internes en cohérence avec votre usage métier
Obtenir les roadmaps et les évolutions des éditeurs. Analyser des éléments vis-à-vis de votre cahier des charges
Décider de remplacer dans certains cas l’application.
Le CBS est le garant des informations. Les autres applications ne peuvent pas évoluer sans lui. Les CBS auront donc à leur charge de migrer en premier au nouveau format afin de pouvoir alimenter les TMS (Transaction Monitoring System). La présence de la conformité est donc essentielle dans un projet de migration.
L’ISO 20022 s’impose aux systèmes d’échanges internationaux. Les institutions financières pourront bénéficier de nouvelles données efficaces dans le cadre de la conformité. Toutefois, cette migration nécessite des travaux pour les exploiter :
Sur la donnée
Sur les indicateurs
Sur les applications métiers
Si vous n’avez pas encore été impliqué en tant que métier Compliance, c’est le moment !
« La data actif essentiel et incontestable de nombreuses organisations ».
Il suffit de poursuivre cette phrase en citant 2 ou 3 chiffres clefs de grands cabinets de conseil en stratégie, et voilà l’argument d’autorité posé… Oui mais quand on a dit ça, hé bien, qu’est-ce qu’on en fait ?
« La data » est en effet transverse aux entités d’une organisation, source d’opportunités commerciales, d’innovation ou de relation client de qualité, mais elle est bien souvent jugée comme un sujet technique ou abstrait. Le rôle de CDO est encore récent dans de nombreuses organisations : il lui faut trouver sa place et la meilleure articulation avec les Métiers, la DSI, mais aussi la Direction Générale. Il y a donc un enjeu à ce que ce dernier asseye son rôle stratégique dans toute organisation qui veut gérer ses données comme des actifs stratégiques. Le Chief Data Officer a un rôle clef, transverse et à de multiples facettes pour exploiter pleinement le potentiel que représentent les données : compétences humaines, techniques et de leadership. Il doit incarner la transformation vers un mode d’organisation orienté données.
Constructeur de fondations stables
Partons du plus évident (mais pas forcément du plus simple !). Pour toute construction il faut des fondations stables, hé bien avec la data c’est pareil. Des « datas », objets parfois suspects et mal identifiés, sont stockées un peu partout dans les bases de données des entreprises, des Sharepoint collaboratifs ou des fichiers Excel sur le disque dur des collaborateurs… La clef sera dans un premier temps de maîtriser et de sécuriser ces données. Le CDO doit impulser cette dynamique, s’assurer que les données soient connues (recensement dans un data catalog par exemple), accessibles (stockage efficient ), de qualité (règle de gouvernance des données avec des data owners), conformes aux réglementations et à l’éthique (RGPD ou autre) et répondent à des cas d’usages simples et concrets (avant de vouloir faire de l’IA ne faut-il pas que les reporting opérationnels les plus basiques et indispensables soient bien accessibles par les bonnes personnes au bon moment et avec le bon niveau de qualité ?).
Le CDO : architecte et chef d’orchestre
Le Chief Data Officer doit être l’architecte (rôle opérationnel) et le chef d’orchestre (rôle stratégique) de ces projets de fondations en concertation avec les métiers et l’IT. Avec son équipe, il doit accompagner les métiers pour répondre aux usages à valeur et avancer de façon pragmatique. Rien ne sert de lancer 12 projets stratégiques sur la data en même temps : apporter des preuves concrètes en traitant de façon pertinente 2 ou 3 cas d’usages clefs pour améliorer les enjeux opérationnels et vous pouvez être certain que la dynamique métier autour de votre transformation data sera bien mieux lancée ! Il en est de même pour l’IT : il doit aussi soigner sa relation avec la DSI avec laquelle il doit travailler sur des solutions concrètes nécessaires à la mise en œuvre de sa vision data et des usages métiers.
Le Chief Data Officer doit être fédérateur
Le CDO n’a pas nécessairement pour vocation à prendre en charge lui-même l’ensemble des sujets qui traitent de la donnée. Les métiers doivent être des acteurs de première ligne sur le sujet. Le CDO s’intègre régulièrement à un existant désordonné, où les sujets sont déjà plus ou moins traités, mais de façon dispersée. Il doit apporter la vision transverse tout en laissant de l’autonomie aux métiers. Dans la mesure où les équipes data se sont constituées et professionnalisées dans les grands groupes, l’enjeu se déplace aujourd’hui vers la capacité à faire travailler ensemble tous les départements de l’organisation. L’acculturation de l’entreprise et la formation des équipes sont au cœur des enjeux du CDO en 2021.
En résumé : le Chief Data Officer doit faire preuve de savoir-faire mais aussi de savoir-être. Il doit incarner la vision, adosser son action au sponsorship inconditionnel de la Direction Générale, tout en restant au contact des équipes métier et en travaillant avec bonne intelligence avec les équipes IT.
Chiefs Data Officers, si vous n’aviez qu’une idée à retenir de cet article : pour en tirer sa valeur, la data doit pouvoir être expliquée et comprise par ma grand-mère (et je précise que ma grand-mère n’est pas data scientist !) ; visez le pragmatisme et les sujets à valeur immédiate pour votre organisation. Cela fondera le socle indispensable de votre transformation data dans la durée : expériences, résultats concrets et crédibilité !
Les idées exposées ici sont peut-être évidentes pour certains, utiles pour d’autres ! En tout cas, chez Rhapsodies Conseil, au sein de notre équipe Transformation Data, nous essayons d’appliquer cela systématiquement, et nous pensons que c’est le minimum vital.