
15 février 2023
– 6 min de lecture
Valentin Defour
Consultant Senior Transformation Data
Après avoir été successivement décrit comme le job le plus sexy du 21ème siècle puis comme aisément remplaçable par la suite, le data scientist a de quoi souffrir aujourd’hui de sacrés questionnements. Son remplaçant le plus pertinent ? Les solutions d’Auto-Machine Learning, véritables scientifiques artificiels des données, capables de développer seuls des pipelines d’apprentissage automatique pour répondre à des problématiques métier données.
Mais une IA peut-elle prendre en charge la totalité du métier de data scientist ? Peut-elle saisir les nuances et spécificités fonctionnelles d’un métier, distinguer variables statistiquement intéressantes et fonctionnellement pertinentes ? Mais aussi, les considérations d’éthique des algorithmes peuvent-elles être laissées à la main … des mêmes algorithmes ?
Le Data Scientist, vraiment éphémère ?
Le data scientist est une figure centrale de la transformation numérique et data des entreprises. Il est l’un des maîtres d’œuvre de la data au sein de l’organisation. Ses tâches principales impliquent de comprendre, analyser, interpréter, modéliser et restituer les données, avec pour objectifs d’améliorer les performances et processus de l’entreprise ou encore d’aller expérimenter de nouveaux usages.
Toutes les études sur les métiers du numérique depuis 5 ans sont unanimes : le data scientist est l’un des métiers les plus en vogue du moment. Pourtant, il est plus récemment la cible de critiques.
Des observateurs notent une baisse de la « hype » autour de la fonction et une décroissance du ratio offre – demande, qui viendrait même pour certains à s’inverser. Trop de data scientists, pas assez de postes ni de missions.
Deux principales raisons à cela :
- La multiplication de formations et bootcamps certifiants pour le poste, résultant en une inondation de profils juniors sur le marché ;
- Une rationalisation des organisations autour de l’IA et une (parfois) limitation des cas d’usage – l’époque de l’armée de data scientists délivrant en série des POCs morts dans l’œuf est belle est bien révolue.
Mais également, et c’est cela qui va nous intéresser pour la suite, pour certains experts, le « data scientist » ne serait qu’un buzzword : l’apport de valeur de ce rôle et de ses missions serait surévalué, jusqu’à considérer le poste comme un effet de mode passager voué à disparaître des organisations.
En effet, les mêmes experts affirment qu’il sera facilement remplacé par des algorithmes dans les années à venir. D’ici là, les modèles en question deviendraient de plus en plus performants et seraient capable de réaliser la plupart des tâches incombées mieux que leurs homologues humains.
Mais ces systèmes si menaçants, qui sont-ils ?
L’Auto-ML, qu’est-ce que c’est ?
L’apprentissage automatique automatisé (Auto-ML) est le processus d’automatisation des différentes activités menées dans le cadre du développement d’un système d’intelligence artificielle, et notamment d’un modèle de Machine Learning.

Cette technologie permet d’automatiser la plupart des étapes du procédé de développement d’un modèle de Machine Learning :
- Analyse exploratoire : préparation et nettoyage des données, détection de la typologie de problème à adresser ;
- Ingénierie et sélection des variables : analyse purement statistique (et non fonctionnelle, c’est l’un des points faibles) des différentes variables, sélection des variables pertinentes, création de nouvelles variables (ces modèles peuvent-ils le faire… ?) ;
- Sélection du ou des modèles à tester, entraînement, mise en place de méthodes ensemblistes de modèles, fine tuning des hyper-paramètres, analyse et reporting de la performance ;
- Agencement de l’analyse : mise en place du pipeline sous contrainte (coût / durée d’entrainement, complexité du ou des modèles, …) ;
- Industrialisation et cycle de vie : restitution à l’utilisateur des résultats sous la forme de graphes ou d’interface, branchement simplifié à un tableau de bord prêt à l’emploi, sauvegarde et versionning des différents modèles.
L’Auto-ML démocratise ainsi l’accès aux modèles d’IA et techniques d’apprentissage automatique. L’automatisation du processus de bout en bout offre l’opportunité de produire des solutions (ou à minima POC ou MVP) plus simplement et plus rapidement. Il est également possible d’obtenir en résultat des modèles pouvant surpasser les modèles conçus « à la main » en matière de performances pures.
En pratique, l’utilisateur fournit au système :
- Un jeu de données pour lesquelles il souhaite mettre en place son usage d’intelligence artificielle – par exemple une base de données client et d’indicateurs calculés (chiffre d’affaires total, sur la dernière année, nombre de transactions, panier moyen, propension à abandonner son panier, …)
- Une variable cible d’entraînement, qu’il souhaite prédire dans le cadre de l’usage en question – par exemple la probabilité de CHURN du client en question ;
- Des contraintes vis-à-vis de la sélection du modèle : quelle typologie de modèle à utiliser / exclure, quelle(s) métrique(s) de performance considérer, quels seuils de performance accepter, quelle durée d’entraînement maximale tolérer, …
Le système va alors entraîner plusieurs modèles – ensemble de modèles et modéliser les résultats de cette tache sous la forme d’un « leaderboard », soit un podium des modèles les plus pertinents dans le cadre de l’usage donné et des contraintes listées par l’utilisateur.

Quelles sont les limites de l’Auto-ML ?
Pour autant, l’Auto-ML n’est pas de la magie et ne vient pas sans son lot de faiblesses.
Tout d’abord, les technologies d’Auto-ML rencontrent encore des difficultés à traiter des données brutes complexes et à optimiser le processus de construction de nouvelles variables. N’ayant qu’une perception statistique d’un jeu de données et (aujourd’hui) étant dénué d’intuition fonctionnelle, il est difficile de faire comprendre à ces modèles les finesses et particularités de tel ou tel métier. La sélection des variables significatives restant l’une des pierres angulaires du processus d’apprentissage du modèle, apparaît ainsi une limite à l’utilisation d’Auto-ML : l’intuition business humaine n’est ainsi pas (encore) remplaçable.
Également, du fait de leur complexité, les modèles développés par les technologies d’Auto-ML sont souvent opaques vis-à-vis de leur architecture et processus de décision (phénomène de boîte noire). Il peut être ainsi complexe de comprendre comment ils sont arrivés à un modèle particulier, malgré les efforts apportés à l’explicabilité par certaines solutions. Cela peut ainsi amoindrir la confiance dans les résultats affichés, limiter la reproductibilité et éloigner l’humain dans le processus de contrôle. Dans une dynamique actuelle de prise de conscience et de premiers travaux autour de l’IA éthique, durable et de confiance, l’utilisation de cette technologie pourrait être remise en question.
Enfin, cette technologie peut aussi être coûteuse à exécuter. Elle nécessite souvent beaucoup de ressources de calcul (entrainement d’une grande volumétrie de modèles en « one-shot », fine tuning multiple des hyperparamètres, choix fréquent de modèles complexes – deep learning, …) ce qui peut rendre son utilisation contraignante pour beaucoup d’organisations. Pour cette même raison, dans une optique de mise en place de bonnes pratiques de numérique durable et responsable, ces technologies seraient naturellement écartées au profit de méthodologies de modélisation et d’entrainement plus sobres (mais potentiellement moins performantes).
Quelles solutions d’Auto-ML sur le marché ?
On peut noter 3 typologies de solutions sur le marché :
- Les solutions des éditeurs de cloud (GCP, AWS, …), pré-packagées dans les offres, permettant de profiter d’infrastructures d’entraînement performantes et de modèles pré-entraînés ;
- Les éditeurs spécialisés dans les plateformes de data science, comme la licorne française Dataïku ou le pure-player ML DataRobot ;
- Les librairies Python (et leur pendant R, parfois) open-source, certaines se branchant sur des frameworks bien connus de la profession (Auto Sklearn, AutoKeras, …)
H2o Auto-ML en pratique
Jetons un coup d’œil à H2o.ai, librairie Python open source d’Auto-ML développée par l’entreprise éponyme. Nous prendrons comme cas d’usage un problème de classification binaire classique sur des données tabulaires, issu du challenge mensuel Kaggle d’Août dernier.
Après un chargement des données et une initialisation de l’instance locale, on va pouvoir lancer le moteur d’AutoML :
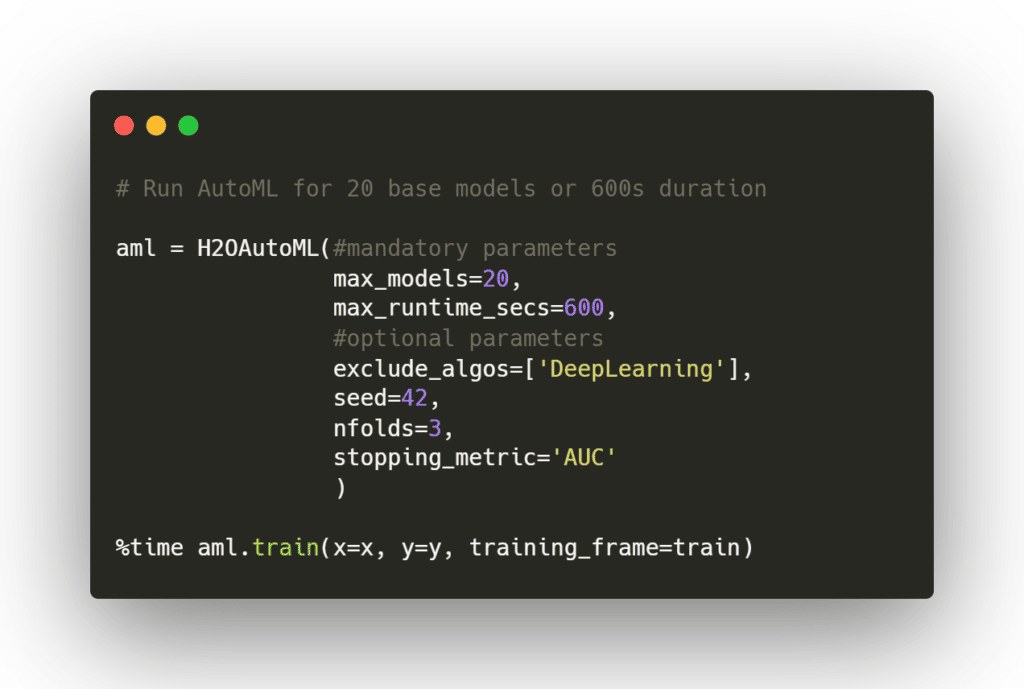
Doivent être spécifiés :
- La volumétrie maximale de modèles à entraîner (permet d’ajuster les performances et de ne pas aller dans le « toujours plus ») ;
- Une durée maximale de temps d’exécution, pratique en phase de prototypage du pipeline ;
- Le H2o dataframe d’entraînement en indiquant les variables indépendantes (x) et la variable à prédire (y). A noter qu’il s’agit d’un format de dataframe spécifique mais que la conversion depuis et vers un dataframe pandas « traditionnel » se fait très simplement.
Il est également possible d’ajouter des paramètres tels que :
- Les éventuelles typologies de modèles à exclure – ici on retire les modèles de deep learning mais peuvent également être exclus l’empilement (« stacking ») de modèles, les xgboost ou encore les algorithmes de « gradient boosting » ;
- Une métrique d’arrêt (ex : logloss, AUC, …) qui permettra, une fois la valeur cible atteinte ou un nombre de rounds d’entrainement sans amélioration dépassé d’arrêter le processus de training ;
- Tout un ensemble de paramètres pour gérer la validation croisée (nombre de folds, conservation des modèles non retenus et leurs prédictions, …) ;
- Des fonctionnalités de ré-équilibrage des classes, afin d’adresser les problématiques de datasets déséquilibrés (par exemple, dans un problème de classification binaire, une répartition 90-10 sur la variable à prédire dans le jeu d’entraînement) ;
- … et bien d’autres – plus d’informations dans la documentation du moteur.
Il est important de noter que H2o AutoML ne propose aujourd’hui qu’une fonctionnalité limitée de préparation des données, se limitant à de l’encodage de variables catégorielles. Mais la société travaille aujourd’hui à enrichir ces fonctionnalités.
Une fois l’entraînement terminé, des informations sur le modèle vainqueur sont affichées :
- Informations de base sur le modèle : nom, typologie, paramètres, … Dans notre cas, il s’agit d’un ensemble de plusieurs modèles et l’ensemble des paramètres n’est pas affiché (disponible via une commande supplémentaire)
- Un listing des performances du modèle : matrice de confusion, métriques de classification (voir ci-dessous)
Il est également possible d’avoir accès au « leaderboard » des modèles entrainés et testés : identifiant, performances, temps d’entrainement et de prédiction, typologies des modèles (ensembles, gradient boosting, …) .
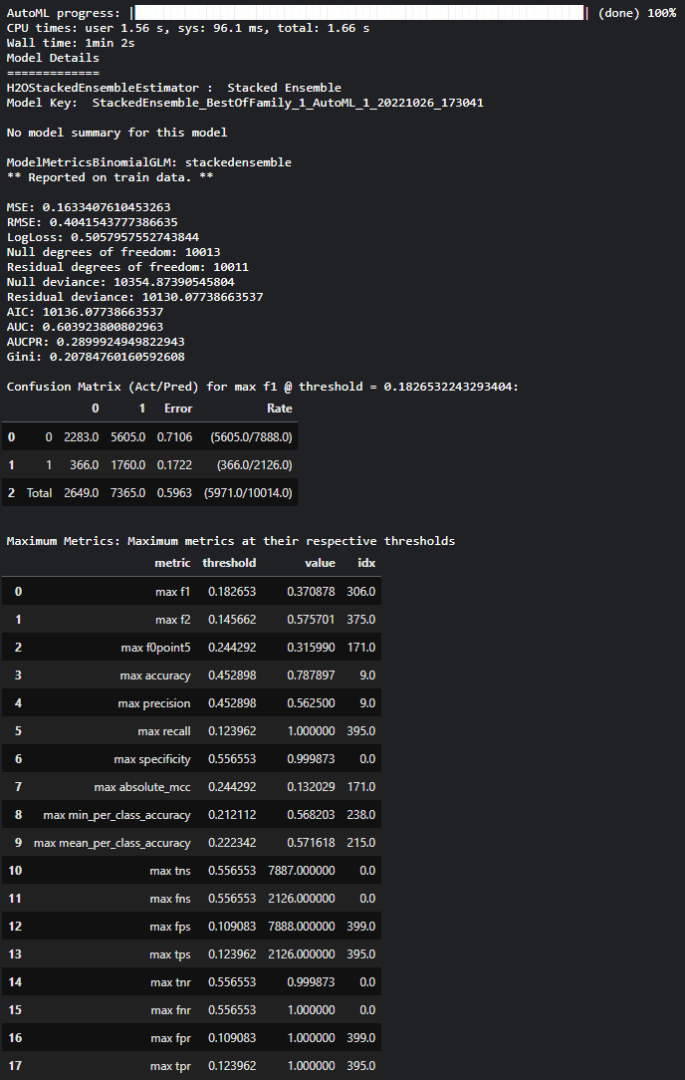
Informations modèle leader
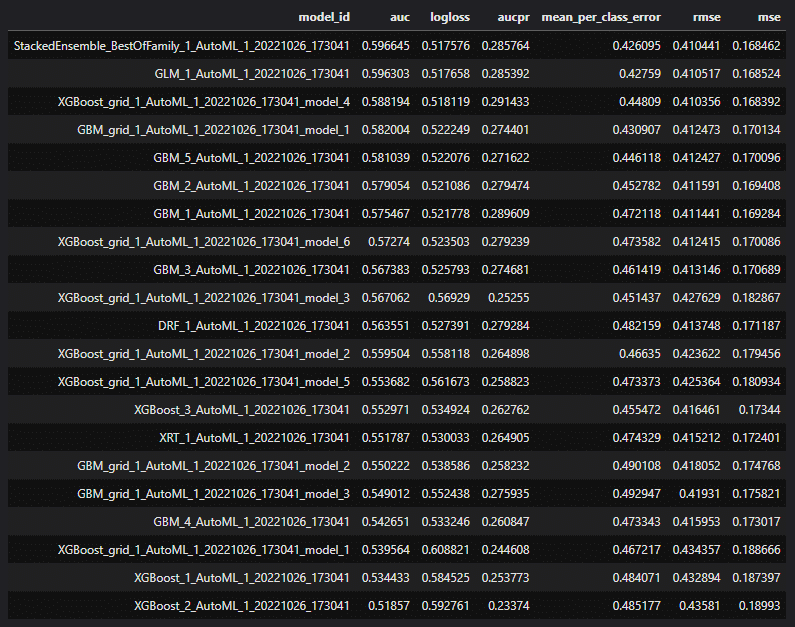
Leaderboard
Enfin, le module d’explicabilité (restreinte…) nous permet d’obtenir des informations sur l’importance globale des variables dans les décisions du modèle, ainsi que l’importance globale des variables par modèle entraîné / testé, des graphes de dépendance partielle, une représentation des valeurs de SHAP des variables, … Il est également possible d’obtenir des explications locales sur des prédictions données.
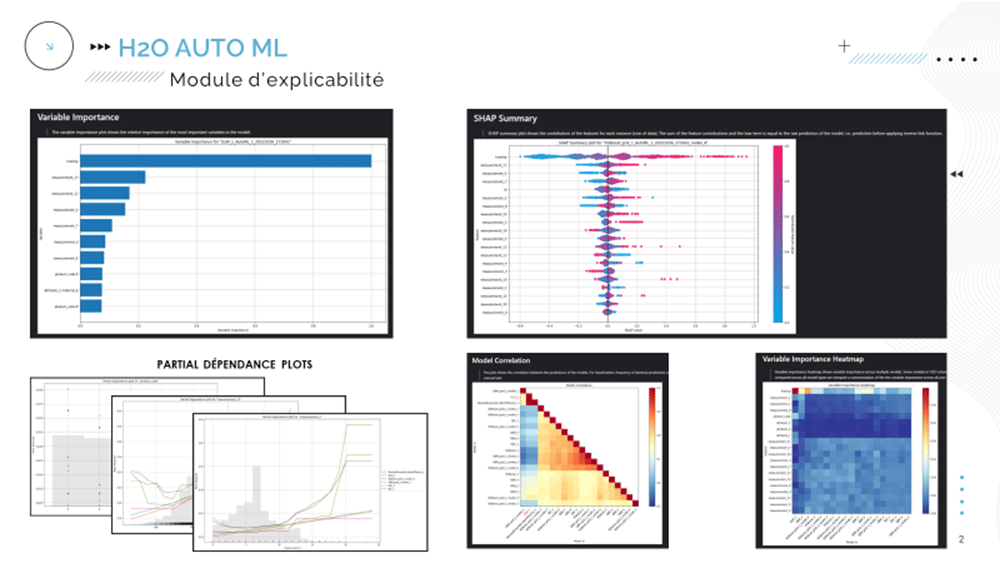
En définitive, H2o AutoML permet d’expérimenter rapidement sur un cas d’usage donné, permettant par exemple de valider l’intérêt d’une approche par Machine Learning. Pour autant, dans notre cas précis, le modèle vainqueur constitue un assemblage complexe de plusieurs modèles non clairement spécifiés (il faut chercher…longtemps !) et cette complexité et ce manque de transparence peuvent en premier lieu rebuter les utilisateurs.
En définitive, l’Auto-ML signe-t-il vraiment la fin du Data Scientist ?
Le succès futur de cette technologie repose aujourd’hui sur les progrès à venir en matière d’apprentissage par renforcement, discipline qui peine aujourd’hui à percer et convaincre dans le monde professionnel. L’explicabilité et la transparence sont également des challenges à relever par cette technologie pour accélérer son adoption.
Mais de toute évidence, l’Auto-ML s’inscrira durablement dans le paysage IA des années à venir.
Quant au data scientist, il est certain que la profession telle que nous la connaissons va être amenée à évoluer. Nouvelle au début des années 2010, comme tous les métiers depuis et selon les organisations, leurs profils et activités vont évoluer.
D’un côté, des profils data scientists plus « business » et moins « tech » vont certainement se dégager se concentrant sur des échanges avec les métiers et la compréhension fine du fonctionnement et des enjeux des organisations. On peut d’ores et déjà voir que ces profils émergent des équipes business elles-mêmes : les fameux citizen data scientists. Ces derniers seront très certainement des fervents utilisateurs des outils d’AutoML.
Également, des profils hybrides data scientist – engineer se multiplient aujourd’hui, ajoutant aux activités classiques de data science la mise en place de pipelines d’alimentation en données et l’exposition des résultats et prédictions sous un format packagé (API, web app, …). L’ère du Machine Learning Engineer a déjà démarré !