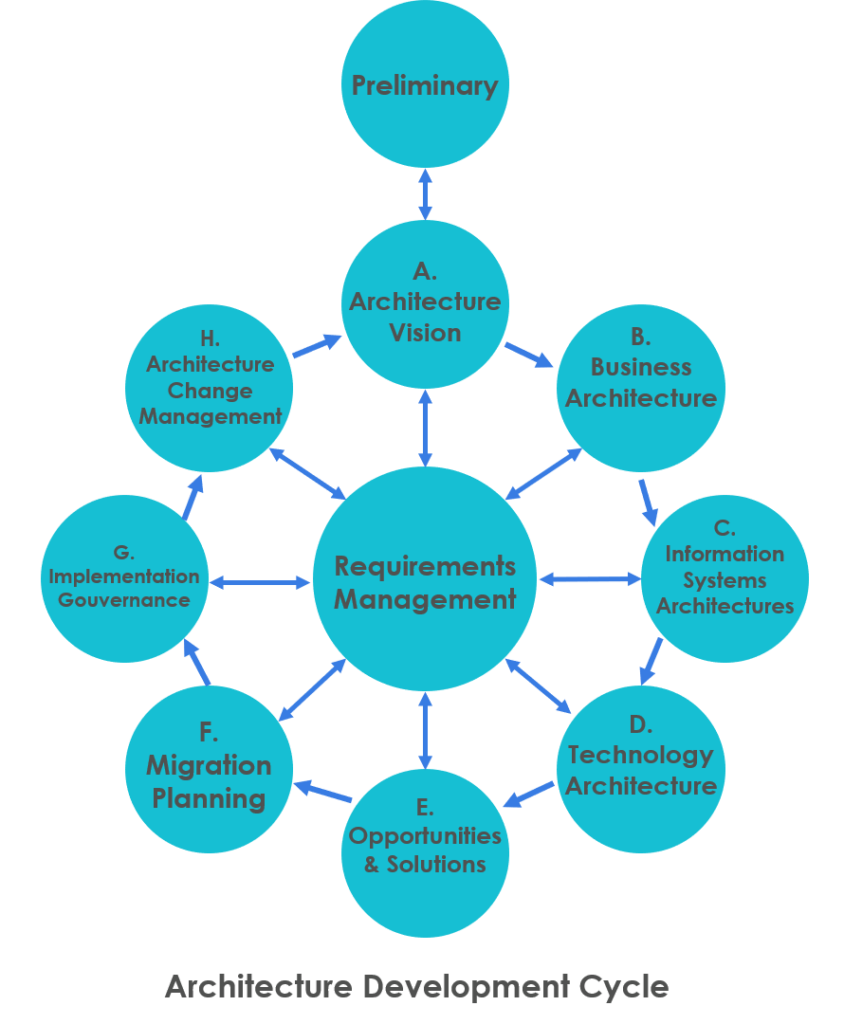
Souvenez-vous ! Lors du dernier article, nous venions d’obtenir notre certification TOGAF et nous voulions voir comment appliquer ce framework dans la « vraie vie ». Nous avons donc mis en place Les capacités d’architecture (phase Préliminaire et phase A), et maintenant nous allons continuer en suivant la roue ADM (Architecture Development Method).
Nous allons donc parler dans cet article, de la définition des exigences propres à chaque niveau du Système d’Information (la couche métier, la couche applicative et la couche technique) et qui vont impacter le projet. Puis dans le prochain article, nous finirons avec leurs conséquences sur le design des solutions et comment fermer la roue.
La définition des exigences peut changer du tout au tout en fonction du domaine d’activité de votre entreprise / client. Culturellement, le domaine industriel a toujours été plus sensible à la rédaction des exigences que le domaine tertiaire. Vous imaginez bien que pour construire une centrale nucléaire, la liste des exigences est plus importante que pour construire une application de gestion de la solution client (CRM) car en cas de problème, les conséquences sont moins importantes.
Gestion des exigences ou le référentiel des exigences
La gestion des exigences doit permettre de s’assurer du bon suivi des exigences exprimées lors des différentes phases de la roue ADM mais également de s’assurer de leur cohérence. Pour cela, il faut 3 choses :
Un référentiel des exigences pour les stocker
Un processus de mise à jour
Un processus de revue pour la mise en cohérence des exigences.
TOGAF est un framework avec une approche « Test Driven Design ». C’est-à-dire que les exigences du système d’information ont pour but d’être testées. Il est donc primordial de bien les maîtriser de les prioriser, de connaître leur historique, de pouvoir les évaluer et de voir à la fin si le produit fini du projet y répond correctement.
Pour cela, il peut être intéressant d’outiller la gestion des exigences et de créer un référentiel. Si un outil existe déjà, utilisez-le, les plus connus sont IBM rational DOORS, Envision Requirements, JIRA ou autre. Dans le cas contraire un fichier Excel dont la gestion sera sous la responsabilité de l’architecte projet sera bien suffisant. De plus, les exigences seront gardées à la fin du projet et pourront être réutilisées lors du démarrage d’un nouveau cycle de la roue ADM. Il est alors préférable de nommer un responsable de l’administration de ce référentiel.
Maintenant que tout est prêt, nous pouvons continuer de parcourir la roue ADM et commencer à identifier les exigences auxquelles il va falloir répondre.
Phase B : Architecture métier ou comment solliciter son métier à bon escient ?
La phase B de la roue ADM doit permettre de décrire comment votre entreprise (ou le domaine métier impacté par votre projet) doit s’organiser pour atteindre les objectifs. Le travail va donc se concentrer sur la définition de la stratégie, sur la gouvernance, l’organisation métier et les informations clés des processus métier. Et comme lors des précédentes phases, le but est de ne pas surinvestir et de ne consommer que de la charge de travail avec une véritable valeur ajoutée.
La majorité du temps, les équipes d’architectes font partie de la DSI, les relations avec le métier peuvent donc être multiples :
Nous avons directement accès au métier et les impacts sur les processus sont faibles : La disponibilité du métier risque d’être faible car il a ses tâches récurrentes à effectuer (vente, gestion, comptabilité). Dans ce cas, il est nécessaire de lui prendre le moins de temps possible : traduire les enjeux métier, lister les processus et les « pain points ». Seuls quelques ateliers seront nécessaires pour collecter ces informations, il suffit ensuite d’en déduire les exigences métiers.
Nous avons directement accès au métier et les impacts sur le métier sont importants : dans ce cas, le métier doit se rendre disponible pour répondre au besoin. C’est généralement le cas préféré des architectes car cela permet de poser ses questions en toute liberté.
Nous devons passer par une MOA, qui est un intermédiaire avec le métier. L’avantage de cette relation est qu’une MOA est intégrée dans le projet et qu’elle se rendra disponible pour répondre aux besoins du projet. Le problème est que la MOA n’est pas forcément au courant des enjeux du métier, selon l’organisation mise en place entre la DSI et le métier.
Une fois que les exigences métiers sont identifiées et le référentiel mis à jour, nous pouvons passer aux exigences liées au système d’information.
Phase C : L’architecture du système informatique car même l’IT a ses propres exigences…
Les exigences du système d’informations se découpent en 2 catégories. Celles qui s’appliquent à l’intégralité du système d’information et celles qui s’appliquent au projet.
Les exigences qui s’appliquent à tout le SI sont souvent les plus faciles à appréhender pour les architectes : ce sont les exigences d’architecture que nous connaissons tous comme :
Un identifiant doit être unique et non interprétable.
Une fonction ne peut pas être implémentée plusieurs fois dans le SI…
La séparation des fonctions de production et de distribution,
Celles liées aux échanges (API, couche d’échange…),
Sur les sources de données (le terme de « Golden Source » est souvent utilisé),
Ou les réglementations comme sur la protection des données (Règlement Général sur la Protection des Données, ….).
Puis viennent toutes les exigences spécifiques au projet en lui-même comme celles liées à la confidentialité, l’intégrité, la disponibilité ou l’authentification / identification. La mise à niveau des exigences précédemment édictées par le métier est souvent négligée. Quand cette mise à niveau n’est pas faite (peu importe le formalisme), cela révèle souvent un manque de dialogue entre les équipes projet métier et IT. Cet effort est nécessaire car une partie de la valeur de l’architecte est justement de créer un pont entre ces deux mondes.
Phase D : Architecture technique
Dans les DSI importantes, des architectes dédiés ont généralement la charge de la partie technique. En effet, un architecte ne peut pas avoir le même niveau d’expertise sur toutes les couches du système d’information et la frontière se trouve historiquement à ce niveau. Dans les DSI plus petites, la césure entre les architectes techniques et les architectes fonctionnels est moins importante mais elle existe souvent malgré tout.
L’architecte technique doit avoir une bonne connaissance du catalogue des normes et standards de l’entreprise. Savoir quels sont les composants (technologies, logiciels…) à utiliser, où en est leur cycle de vie et les mettre en regard du projet. L’architecte se confronte également à la stratégie de la DSI et à sa politique fournisseurs notamment (quand elle existe).
Dans le cas de solutions hébergées en interne, l’architecte technique doit définir les exigences techniques qui permettent de dimensionner correctement l’infrastructure. Dans le cas de solutions Cloud ou d’application en SAAS, les exigences liées aux infrastructures n’ont plus de raison d’être, elles doivent être définies en termes de SLA (plus besoin de calculer le nombre de serveurs, car l’hébergeur est garant du dimensionnement). Dans ce dernier cas, s’occuper des interfaces est plus que nécessaire.
A la fin de cette phase, le référentiel d’architecture doit s’enrichir en précisant les composants à utiliser pour atteindre la cible désirée et la feuille de route provisoire avec les recommandations de mises en œuvre.
Conclusion
A ce niveau d’avancement, nous avons pu collecter et finaliser l’ensemble des exigences du projet. Nous avons également une vue assez claire d’où nous partons et où nous voulons aller, sauf que nous sommes encore dans un monde « sans contrainte ». Nous savons ce que nous voulons (ou ne voulons pas) mais il faut à présent se confronter au monde réel, fait de contraintes de planning, de budget, de disponibilités des ressources et donc sortir de cette tour d’ivoire où se sont parfois enfermés d’autres architectes avant vous. Les négociations et les arbitrages commencent et la valeur tangible apportées aux projets se mesure ici, comme nous le verrons dans le troisième et dernier article de cette série sur TOGAF In Real Life.
L’erreur la plus commune, quand on entreprend une démarche micro services, est de vouloir découper en micro-services !
Le concept de micro services existe désormais depuis une dizaine d’années. Netflix étant la première « grande entreprise » (si on pouvait la nommer ainsi à l’époque) à adopter une telle orientation.
Avec le recul, le plus gros problème des micro services repose sur le fait de les avoir appelés « micro ». En lisant sur Wikipedia, on retrouve sous le chapitre « Philosophie », la phrase suivante : « Les services sont petits, et conçus pour remplir une seule fonction ».
Rien de plus incorrect si on veut bien entamer une démarche micro services… Tout comme parler de nano services et macro services, pour analyser des mauvaises pratiques, comme font certains acteurs. Ce n’est pas une question de taille !
Les efforts doivent principalement se focaliser sur trois axes fondamentaux dans la réflexion sur le découpage :
SIMPLICITÉ : un micro-service doit être spécialisé. Il ne doit pas avoir une couverture fonctionnelle complexe, il doit effectuer un ensemble d’actions simples et ciblées. Ceci étant dit, nous ne devons pas non plus réduire un microservice à une simple fonction, dans l’objectif de “faire petit” : un microservice doit couvrir un ensemble fonctionnel cohérent.
ISOLATION : un microservice doit être isolé des autres. Le dysfonctionnement d’un microservice ne doit pas impacter les autres afin d’éviter l’effet domino.
INDÉPENDANCE : un microservice garantit son indépendance, il englobe tout ce qui lui est nécessaire pour son fonctionnement. Dans la décennie de la containérisation, tout a été mis en œuvre pour que le concept d’indépendance, associé aux microservices, devienne simple et intuitif. Un container de par sa nature est facilement associable à un microservice
A partir de ces considérations, quelle est la meilleure approche pour définir le périmètre de ses micro services ?
Partons du besoin primaire d’un SI : Traiter de la donnée ! Conjuguons ce besoin à une autre caractéristique des micro services : un micro service interagit avec une donnée qui lui est propre. Une solution simple se propose : réalisons un découpage par la donnée ! Le premier pas pour dessiner un découpage des microservices est de définir la structure de la donnée.
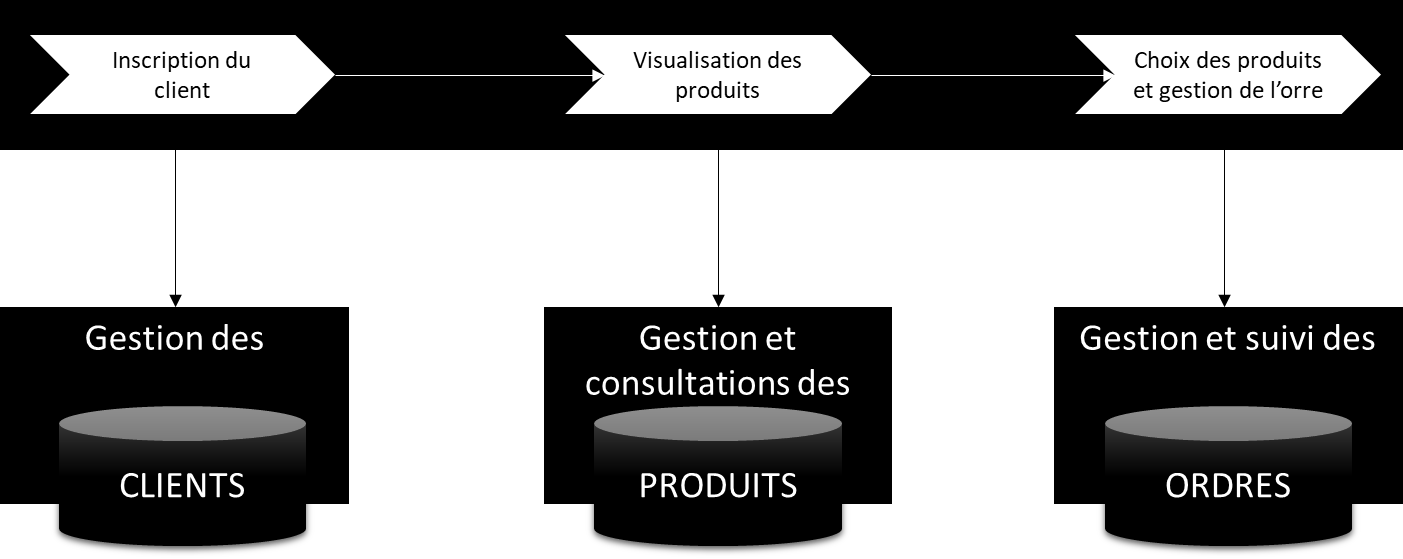
Prenons un exemple très simple : le triptyque CLIENT, PRODUIT et ORDRE.
Dans la logique que je viens d’expliquer, nous pouvons construire un Microservice sur chaque entité métier :
Ce qui permet à une application frontale de combiner les trois pour, par exemple, permettre à un site d’eCommerce, de :
passer un ordre
après avoir consulté la liste des produits
et avoir géré l’inscription d’un client
Cette démarche n’est certainement pas exhaustive. Chaque cas de figure nécessite une analyse à part entière, mais à notre sens c’est un bon point de départ pour une réflexion micro service.
Pour résumer, une bonne pratique de découpage en micro services est initiée par le découpage de la donnée, en entités métier.
Voici une vidéo créée par nos soins pour illustrer ces explications : ici
Conclusion
Essayer de faire « petit » n’est pas forcément le sujet sur lequel focaliser ses efforts… L’indépendance et l’isolation sont les clés d’une bonne démarche micro-services. Si un doute surgit, le mieux est de ne pas découper tant que les autres principes sont respectés.
Les autres articles qui peuvent vous intéresser
IoT – Une gouvernance à double niveau semée d’embûches
IoT - Une gouvernance à double niveau semée d'embûches
Qui n’a jamais tremblé lorsque le post-it “Définir le Target Operating Model (TOM)”, alias Gouvernance, lui a été attribué ?
Il s’agit là d’une activité complexe mais pourtant au combien nécessaire pour l’efficacité et la pérennité d’une offre ou d’un service.
La Gouvernance IoT n’échappe pas à ce constat général, la difficulté en est même démultipliée :
l’IoT s’applique à une diversité de Métiers ayant chacun leurs particularités,
la chaîne IoT nécessaire à un cas d’usage métier est constituée de nombreux maillons technologiques (cf. notre article IoT Un Marché en pleine ébullition) répartis sur un large spectre de compétences.
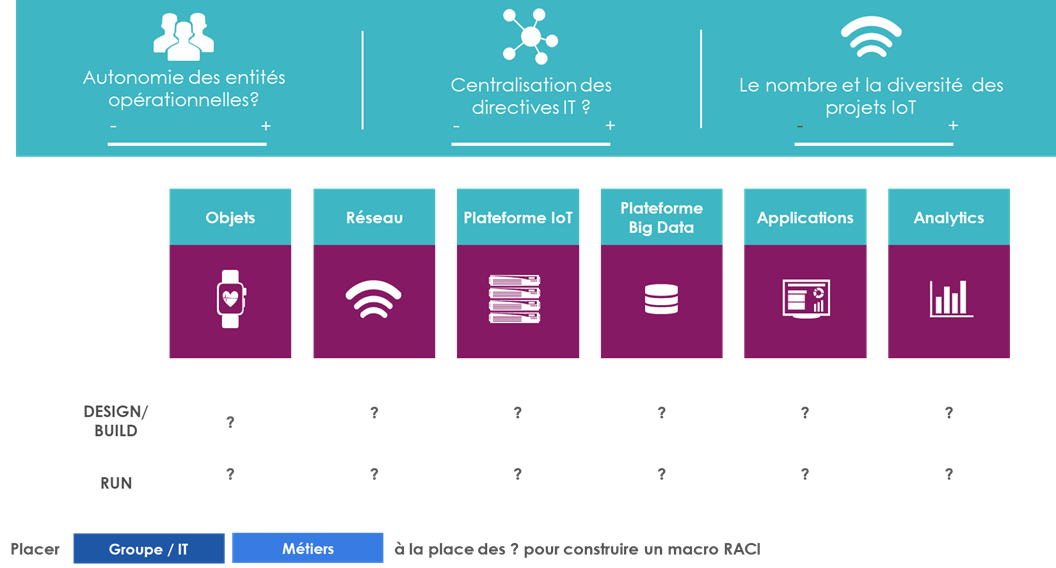
Quelle part de responsabilité attribuer aux Métiers / à l’IT ? Comment définir une structure commune transverse à l’échelle de l’Entreprise ? Comment fédérer les initiatives locales pour les encadrer et démultiplier les bénéfices ? Quel RACI peut être mis en place ?
IoT, flagrant délit de franchissement de ligne, de l’Information Technology (IT) vers les Operational Technology (Métier)
Comme nous l’avons évoqué dans notre précédent article, les technologies IoT s’immiscent sur des cas d’usages purement métier assurés jusque là par des Operational Technology.
Les Métiers étaient et sont toujours les sachants sur :
Le contexte et les finalités du cas d’application,
Les contraintes environnementales applicables (vibration, climatique, form factor, interférence, …),
Les données pertinentes à récolter, et leurs fréquences,
Les traitements métiers à appliquer sur les données pour obtenir les informations nécessaires au cas d’usage ciblé.
L’IT apporte son expertise sur les différentes couches technologiques :
Les infrastructures à mettre en oeuvre,
Les objets connectés (ou composant) à utiliser,
Les plateformes qu’elles soient on-premise ou en mode PaaS / SaaS,
La connectivité (les protocoles réseaux adéquats…),
Les best practices et pattern d’intégration pour véhiculer, stocker et partager l’information,
La sécurité sur l’ensemble de la chaîne.
De facto, nous identifions rapidement les risques à adopter une Gouvernance portée de façon unilatérale par :
Le Métier : solution non pérenne technologiquement ou ne répondant pas aux standards de l’entreprise, solution propriétaire “vendor lock-in”, solution sous-dimensionnée, …
L’IT : une couverture fonctionnelle non adaptée aux besoins réels (trou dans la raquette VS Rolls-Royce), une solution trop rigide et peu évolutive au regard des transformations du métier, …
Il y a donc une vraie dualité Métier / IT à mettre en oeuvre au niveau de la Gouvernance.
Une Gouvernance mixte, N approches
Personne aujourd’hui ne saura en mesure de vous conseiller de procéder comme-ceci ou comme celà sans avoir sondé votre existant :
Quelle est le degré d’autonomie des entités opérationnelles ?
Les métiers disposent-ils de ressources IT propres ?
Est-ce que les directives IT sont centralisées ?
Les cas d’usages IoT sont-ils déjà bien ancrés en transverse dans l’entreprise ou bien largement isolés ? Est-ce qu’une équipe dispose d’une vision globale sur toutes les initiatives / tous les projets ?
Est-ce qu’il y a déjà des affinités à positionner telle entité sur le BUILD ou le RUN de tel ou tels maillons d’une chaîne IoT ?
Est-ce que quelqu’un dispose de la vision bout en bout entre le cas d’usage et les moyens IT à mettre en oeuvre pour le traiter ?
Comment renseigneriez-vous les quelques éléments ci-dessous ?
Néanmoins quelques modèles de gouvernance IoT émergent. Ci-dessous une illustration non-exhaustive :
Filière 1 : Miser sur un socle IoT transverse à l’entreprise
Le Groupe est un enabler pour les métiers :
Le Digital est en charge de la définition de la stratégie IoT Groupe,
Le département IT, est responsable de la mise en oeuvre des socles / plateformes IoT (horizontales), d’accompagner et de supporter les métiers dans leurs projets.
Les Métiers sont responsables de leurs projets IoT positionnés en verticaux.
Filière 2 : Miser sur l’agilité d’une Feature Team pour délivrer des solutions sur mesure
Les Métiers sont à l’origine des projets IoT,
Le département IT dédie des ressources à l’IoT dans ses différentes équipes (infrastructure, plateforme, réseaux, développement…). Ces ressources s’organisent généralement en Features Teams pour accompagner les projets métiers IoT avec le maximum de réactivité.
Et vous, vers quel modèle vous projetez-vous ?
Les victoires collectives sont les plus belles
La définition d’une Gouvernance est toujours complexe.
L’instruction d’un sujet IoT de bout en bout n’est pas une mince affaire. Cela requiert énormément de compétences technologiques (électronique, hardware, software, en passant par les télécoms…), tout en devant constamment s’assurer de l’adéquation avec la réalité terrain (contraintes mécaniques, etc.).
De là à dire que définir une Gouvernance IoT est impossible, il n’y a qu’un pas.
Métier et IT doivent travailler main dans la main, le fossé les séparant devant être définitivement comblé.
Adopter une démarche d’Open Innovation (ateliers d’idéation, fablabs, pizza teams…) permettra de casser les silos, de cadrer et d’affiner le “Qui fait Quoi ?” dans cet écosystème en constante évolution.
#Teasing : dans un prochain article nous vous parlerons des différentes stratégies, des positionnements possibles pour mettre sur le marché une Offre IoT.
L’adoption du Cloud Public par les entreprises est une réalité et plusieurs d’entre elles ont fait le choix d’adopter cette stratégie dans le cadre de leur transformation digitale. Avoir une stratégie Cloud First pour une entreprise consiste à utiliser des services ou infrastructures Cloud par défaut pour répondre à toute nouvelle application, processus ou fonction. Mais l’adoption d’une stratégie Cloud First est-elle une bonne idée? Répond-elle aux promesses de réduction des coûts ou de gain en agilité? Faut-il foncer tête baissée avec une approche jusqu’au-boutiste? Cloud First, mythe ou réalité ?
Nous allons essayer de répondre à ses différentes questions en vous présentant les 5 mythes les plus répandus lors du cadrage d’une stratégie Cloud First !
Mythe #1 : Le cloud vous permettra de réduire vos coûts liés à l’infrastructure
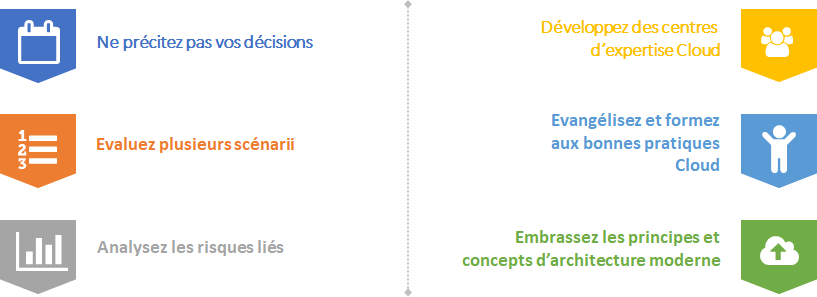
Faux ! Ne pensez surtout pas que par défaut vous réaliserez des économies en migrant votre application sur le Cloud. Établissez très vite une grille de critères et un arbre de décision pour opter pour la meilleure stratégie de migration pour chaque socle applicatif et n’hésitez pas à décommissionner lorsque vous le pouvez.
Exemple d’arbre de décision “Go to Cloud”
Mythe #2 : Toute application est éligible au cloud public
Faux ! Il ne convient pas également de supposer que toutes vos applications ou processus métiers devraient s’exécuter sur le Cloud Public. Ce sera adapté dans certains cas et pour d’autres il faudra convenir du bon scénario (Cloud Privé, Serveurs physiques) en prenant le temps d’évaluer les bénéfices et les risques.
Mythe #3 : Il vous faut choisir un fournisseur cloud privilégié qui deviendra l’option par défaut
Faux ! Une stratégie Cloud First ne signifie pas pour autant se lier à un seul ou deux fournisseurs avec un catalogue de services le plus important possible. Il ne faut pas oublier qu’il n’y a pas que AWS, Azure et GCP sur le marché. D’ailleurs en terme de sourcing, il sera préférable d’éviter d’être complètement dépendant d’un fournisseur unique. Il existe pléthore de fournisseurs cloud, notamment SaaS, qui sont souvent plus adaptés pour certaines catégories d’applications pour des fonctions support ou de back-office (messagerie, outils de collaboration, crm, erp, etc.). Dans ce cas précis, une stratégie “Best-of-breed” où vous retenez la solution répondant au mieux dans l’état de l’art en service SaaS puis dans un deuxième temps la meilleure architecture solution via le catalogue de service de votre fournisseur Cloud Public privilégié peut être une meilleur stratégie. Si vous choisissez cette option, nous vous conseillons de déployer une Hybrid Integration Platform (HIP) pour gérer vos échanges de données.
Mythe #4 : Migrer votre application vers le cloud la rendra automatiquement plus résiliente
Faux ! Le SLA ou engagement de service pour un service Cloud sur Azure par exemple est de 99,95%. Bien que ce chiffre puisse paraître important et suffisant, cela signifie tout de même qu’il sera toléré par le fournisseur que le service soit arrêté ou en panne pendant 4 heures par mois, soit 2 jours par an en cumulés ! Or, plusieurs fonctions ou applications métier ou techniques nécessitent des engagements de service plus élevés. Afin de bénéficier d’une meilleure résilience de vos services sur le Cloud public, il sera nécessaire de revoir la conception de votre application et de choisir des principes d’architecture haute disponibilité distribuée adaptés à cet environnement pour rendre vos applications « Cloud Native » : «event-driven », fonctions isolées et indépendantes, « data centric », « stateless », etc.
Mythe #5 : une fois dans le cloud, la fonction d’architecture technique ne sera plus nécessaire
Faux ! Il vous sera toujours nécessaire d’avoir des architectes techniques pour supporter les besoins suivants :
Gouverner, surveiller et sécuriser le Cloud,
Estimer les coûts d’infrastructure pour vos prévisions budgétaires,
Faire des recommandations d’optimisation d’architecture solution et technique,
Automatiser des processus liés à la gestion et au déploiement de solution/infrastructure,
Maintenir et mettre à jour votre catalogue de services et les patterns d’architectures Cloud associés,
Réaliser de la veille techno et évaluer de nouveaux produits et fonctionnalités offerts par vos fournisseurs,
Implémenter des outils annexes pour compléter ceux disponibles dans le Cloud en tenant compte des résultats de votre veille techno.
Il sera donc primordial de nommer un Lead Cloud Architect et d’avoir votre centre d’expertise d’architecture technique Cloud pour assurer ces tâches. Evitez le piège d’énoncer uniquement des principes théoriques à suivre par les projets et prenez le temps d’expérimenter les modèles ou tester vos hypothèses.
Capteur de température intelligent , smart watch, smart light … les smart things c’est IN, c’est HYPE, la majorité des publications en font l’éloge.
Est-ce que ces objets sont si smart qu’ils le prétendent ? Uniquement du point de vue technologique ? Qu’en est-il du point de vue utilisateur ?
Prenons le cas de Mr Dupont qui acquiert il y a quelques années son premier Smart Bracelet : le Jawbone UP 3.
Sur le papier : cet objet est vendu comme très intelligent car disposant de plein de capteurs (accéléromètre, gyroscope, température, …).
Dans la vraie vie :
Mr Dupont est agacé car certaines fonctionnalités n’ont jamais été implémentées bien que les capteurs nécessaires soient présents,
Étant très fragile, le bracelet (caoutchouc) s’est rompu à de multiple reprises. Par ailleurs, cette partie disposant d’un certain nombre de capteurs et étant indissociable de la véritable partie électronique, Mr Dupont a dû faire remplacer la totalité de son objet bon nombres de fois.
La société Jawbone a arrêté son activité Wearable grand public, les serveurs ont été débranchés.
Bilan :
L’objet en lui même fonctionne bien, mais ne dispose pas d’écran pour afficher les données basiques (nombres de pas, …),
La synchronisation des données entre l’objet et le smartphone n’est plus fonctionnelle,
Quoi qu’il arrive le service étant décommissionné chez le fournisseur, les indicateurs et recommandations pour l’utilisateur ne sont plus calculés,
Les centaines de millions d’unités vendues peuvent être jetées à la poubelle.
Ce simple exemple peut être décliné sur un grand catalogue de produit « smart ».
En conclusion
Il est effectivement facile d’écrire Smart sur un package marketing mais ce n’est pas une mince affaire à implémenter.
L’intelligence de l’objet doit être pensée sur chacune des phases du projet : de la conception de l’objet, en passant par l’architecture IoT (la localisation des traitements, …), jusqu’à l’ouverture à d’autres écosystèmes.
Nous tenterons très prochainement via un nouvel article (#RhapsodiesConseil #TeamIoT) de vous éclairer sur les différentes stratégies concernant la localisation des traitements (Cloud Computing VS Edge Computing).
Et si le client n’était que la partie visible de l’iceberg ? Pour tous les “transformers” digitaux des entreprises, l’objectif est de mieux connaître les clients. Imaginez cependant que vos clients vous écartent de votre véritable objectif : maîtriser la totalité de votre patrimoine de données.
Priorité client ne signifie pas priorité SI client
Les métiers expriment le besoin de mieux connaître les clients. Le premier réflexe est donc de lancer des projets sur les outils permettant de travailler étroitement avec les clients. Par SI orienté Client, nous entendons ainsi parler par exemple de CRM, Data lake client, DMP. La priorité est ainsi souvent donnée aux outils centrés sur la relation client et centrés sur les métiers en contact quotidien avec les clients.
Vous faites cependant face à des changements rapides du marché et à la transformation des habitudes des clients, liés aux opportunités du digital. L’évolution du seul SI client ne répondra pas à ces changements. L’approche client ne doit donc pas être uniquement synonyme d’évolution du SI client : elle doit piloter l’analyse de l’évolution du SI au travers de l’évolution des attentes des clients.
Connaître les attentes des clients avant tout
Prenons quelques exemples pour démontrer que bien connaître les attentes des clients permettra d’avoir le socle de votre transformation.
Le premier exemple concerne la confidentialité des données. Garantir la confidentialité et être transparent avec les clients, sont des sujets qui vont révolutionner la relation avec les clients. “Aujourd’hui 54% ¹ de la “GenTech” (génération Z) s’inquiètent quant à l’accès qu’ont les organisations à leurs données”. Les entreprises devront garantir et prouver à cette génération (les futurs clients) qu’ils répondent à la réglementation qui se développe sur le sujet.
Le deuxième exemple concerne le parcours d’un client qui cherche une assurance habitation. Suite à un ciblage et à une campagne par e-mail il est informé d’une toute nouvelle assurance habitation. Il ne donnera pas suite cependant car il n’a pas trouvé les informations détaillées sur la nouvelle assurance. Le parcours client ne comprend plus uniquement le fait de communiquer et de fournir un prix : il s’agit aussi de mettre à disposition les caractéristiques détaillées des produits pour faciliter l’acte d’achat.
Le dernier exemple concerne la disponibilité produit. Selon une étude PwC, “85% ² des enseignes françaises déclarent générer des revenus sur plusieurs canaux”. Cependant les clients souhaitent connaître la disponibilité d’un produit peu importe le canal. Intégrer tous les points de vente dans vos stocks est la réponse qu’attendent dorénavant les clients.
Ces quelques exemples montrent qu’il est primordial d’avoir une vision à 360° des attentes des clients pour capter l’exhaustivité des besoins. Cette exhaustivité est le socle pour opérer votre transformation. Comment alors ensuite construire ce socle? Le plus sûr chemin pour y parvenir est de travailler à l’échelle de vos données.
La capillarité des données, base de la Transformation
La donnée est présente dans tous les processus, en contact ou non avec le client. C’est la capillarité des données. Pour répondre à l’ensemble des attentes des clients, il faut donc préférer travailler les données au travers de leurs utilisations.
Ainsi par ricochet, de nombreux sujets SI transverses seront adressés grâce à la capillarité des données. Collecter les données, créer des référentiels, mettre en place une gouvernance pour garantir la mise en qualité des données, garantir des informations en temps réel, connaître l’état d’avancement de processus, sont des sujets transverses à adresser dont tous les clients bénéficieront.
La capillarité des données oblige en effet à se concentrer la maîtrise du patrimoine de données. L’analyse des attentes des clients au travers des données, va donc petit à petit faire émerger le SI permettant de maîtriser ces données : un SI Data Centric.
Être data centric est pérenne
Les bénéfices d’un SI Data Centric sont de construire un SI agile, évolutif et pérenne.
Définir au travers d’une approche “données” des principes de gouvernance et de mise en qualité, oblige à avoir des architectures SI orientées données, basées sur des “piliers SI” tels que les référentiels, les échanges, les outils de qualité de données et les workflows.
Cette transformation sera durable tout en étant évolutive. Peu importe le besoin, le référentiel client alimente les systèmes liés à ce besoin. De même, les outils de qualité sauront s’adapter à tous les sujets business. Pour finir, l’approche API, conçue à partir de vos données, des besoins, et s’appuyant sur une conception fonctionnelle transverse à votre entreprise, sera aussi un outil robuste face aux changements des habitudes de vos clients.
A chaque nouveau besoin, vous enrichirez un de ces “piliers SI”. Chacun vous sollicite et profite de l’approche et de la capillarité des données. L’effet en est ainsi démultiplié avec l’accumulation des projets.
Il reste cependant à savoir si vous avez la capacité à définir votre approche par les données et à mettre en place ces “piliers SI”.
L’expert en vaut la chandelle
De la collecte à la mise à disposition des données, les “piliers SI” doivent garantir la bonne gestion des données et permettre de mieux satisfaire les clients. L’enjeu business est donc important.
Pour cela, des experts sur les SI Data Centric sont indispensables. L’expertise garantit d’optimiser les coûts et les plannings de construction du SI Data Centric autour des “piliers SI”. D’ailleurs, maintenant qu’il est établit qu’un SI répondant aux besoins clients est un SI Data Centric, quels sont les “piliers SI” à construire ?