Le triptyque Big Data, Data Science, Data Lake a fait naître l’espérance de nouveaux débouchés pour l’entreprise, basés sur une meilleure exploitation de la valeur supposée des données. Ce nouvel eldorado inspiré par des technologies créées par les GAFA est souvent perçu comme une solution purement technique. Il apparaît pourtant nécessaire d’aborder les apports essentiels de l’architecture d’entreprise dans la valorisation et le succès d’un Data Lake à travers trois chapitres distincts :
L’activité urbanisation des systèmes d’information qui permet d’anticiper la place que le Data Lake occupera dans le « paysage applicatif » et dans l’organisation du système d’information.
L’activité modélisation de données et mise en place de référentiels afin de garder le contrôle de son Data Lake et empêcher la transformation du lac (Data Lake) en marais (Data Swamp).
L’activité pilotage du changement centré sur les données et les usages, pour être en capacité de transformer les futures idées innovantes issues de votre Data Lake en avantages compétitifs réels pour l’organisation.
En effet, si le Data Lake démonte techniquement les silos de données et ouvre la porte à des analyses globales et instantanées qui étaient inaccessibles jusque-là, il ne permet pas de disposer automatiquement d’une avance sur ses concurrents.
Chacun des chapitres qui suivent rappelle que le décloisonnement de la donnée n’est utile qu’à condition de faire évoluer en conséquence son système d’information et son organisation. Non par une démarche dogmatique qui imposerait un cadre, mais par une concertation autour des mutations à venir de l’organisation.
Si la résistance au changement, celle qui annihile les bonnes intentions, terrasse votre initiative de Data Lake, c’est probablement que certains des points qui suivent ont été sous-estimés.
Urbanisation : la place du big data dans la big picture
Si l’on s’en tient à une définition technique du Data Lake – un espace de stockage de données brutes à partir desquelles les Data Scientists effectuent des analyses pertinentes – la stratégie d’adoption est souvent la même. Un environnement moderne d’analyse est créé et un espace de stockage y est adjoint. Il s’ensuit une alimentation progressive en flux de données. Comme un POC qui ne dirait pas son nom. Cela ne permet aucune démarche d’urbanisation et n’embarque aucune réflexion sur les enjeux de l’industrialisation future. Pourtant, les sujets sont nombreux et porteurs d’enjeux forts.
Types d’utilisations et qualité des données
Un Data Scientist utilise toutes les données pour ses expérimentations, mêmes les erronées et les « incertaines ». Un responsable produit veut des données consolidées et visualisables quotidiennement. Un Marketing veut de la segmentation à la volée pour proposer les meilleurs produits. Les commerciaux sont sensibles au « time-to-market », de l’idée à son exploitation commerciale. Sans parler des préoccupations du RSSI, du DPO, du management, du DSI, du DAF, des partenaires…
Ces différents modes de fonctionnement évoluent dans le temps et définissent des séparations logiques dans le Data Lake. Non pas des silos, mais des contraintes d’utilisations qu’un Data Lake n’embarque pas par défaut, et qui nécessitent une certaine maturité dans l’urbanisation du Data Lake. Le Data Lake n’est pas un COTS – un produit informatique standard « vendu sur étagère ». Définir un écosystème est nécessaire pour découpler ces utilisations. Echanges de flux, orchestration des processus, supervision, autorisations d’accès, tout cela est nécessaire pour que le Data Lake évolue en phase avec le reste du SI.
Processus de collecte
En rapatriant toutes les données brutes dans le Data Lake, l’industrialisation des collectes de données ne peut pas faire l’économie d’une réflexion globale sur les qualités prioritaires attendues des échanges et de l’urbanisation qui en découle. Et toutes les entreprises n’auront pas les mêmes contraintes. Un opérateur de téléphonie peut générer un million de données par seconde de mille sources différentes, dont certaines sont soumises à des obligations légales de traçabilité et d’autres à des obligations comptables. Une petite mutuelle génèrera péniblement cinq mille données par jour, mais certaines seront des données de santé sensibles. D’autres auront leurs données dans des progiciels, dont certains en mode SaaS. D’autres encore exploiteront les données de partenaires de fiabilités variables. Des entreprises au SI de plus de trente ans passeront par des couches d’encapsulation de leur mainframe. Et toutes ces contraintes peuvent se combiner. Une logique urbanisée est vitale.
Sécurité des données
Le Data Lake a aussi pour vocation de faire circuler une part très importante des données de l’entreprise pour des usages dont le nombre, la nature et les utilisateurs finaux seront amenés à évoluer. Cela ne peut pas se faire sans une automatisation de la traçabilité, de la supervision et de la sécurisation des échanges et du stockage. C’est même bien souvent une obligation légale (RGPD, données de santé, Sarbanes-Oxley…).
La gestion des identités et des accès (IAM), l’API Management, leur intégration avec les données sensibles ou réglementées sont des sujets que l’architecture d’entreprise et le RSSI doivent orchestrer.
Quels modules dans l’écosystème data lake ?
D’autres éléments structurants de votre SI doivent être pris en compte dans l’urbanisation du Data Lake :
Le « catalogue des données », les référentiels associés et leurs cycles de vie,
L’orchestration des processus entourant la gestion des créations, évolutions ou disparitions des sources et destinations,
Le transport physique des données, la gestion de l’intégrité et de l’unicité des transactions, la reprise sur erreur…
La normalisation des données doit retrouver sa place autour d’un Data Lake qui favorise la donnée brute d’origine. La repousser en aval dans la chaîne de traitement ou faire cohabiter anciennes et nouvelles chaînes en parallèle, les choix dépendent des contraintes et attentes.
Chaque SI étant spécifique, cette liste est loin d’être exhaustive.
Se lancer dans la constitution d’un Data Lake sans faire le point sur les impacts, les contraintes et les opportunités mène généralement à une mauvaise adéquation par rapport aux enjeux stratégiques et aux besoins pressentis. Qui d’autre que l’architecte d’entreprise pour donner le recul nécessaire à la définition de la solution de bout-en-bout qui correspond à vos impératifs ?
Référentiels : connais-toi toi-même
Le principal avantage du Data Lake est aussi son principal inconvénient : il casse les silos de données en acceptant n’importe quelle donnée sans surveillance ni gouvernance. Or, il est bien hasardeux, en ces temps de RGPD, de laisser accéder n’importe qui à n’importe quelle donnée.
Autant il est facile de déverser en vrac des données non-dénaturées dans une couche persistante accessible par des personnes autorisées (le Data Lake dans sa forme épurée), autant se passer de référentiels qui permettent la mesure de la valeur des différentes sources de données fait perdre la maitrise du contenu du Data Lake et de tous ses usages possibles.
Les référentiels sont principalement des données de référence sur les données, des métadonnées. Savoir quelle donnée est disponible dans quelle source. Discriminer les données de référence, les données opérationnelles et les données d’exploitation. Connaître les fréquences de rafraîchissement, les versions disponibles, les responsables, la classification, les moyens de les visualiser.
L’utilisation qui en est faite dans le Data Lake est également un élément essentiel pour éviter la création de « silos logiques » venant remplacer les « silos physiques ». Le référentiel peut permettre de connaître le responsable des autorisations d’accès, l’endroit où elle est utilisée, son usage dans des expérimentations, des processus ou des rapports, les référents techniques, fonctionnels ou Métiers…
Si une donnée se trouve dans plusieurs sources, il faut savoir quelle source fait référence (« golden source »), les applications possédant une copie locale, celles pouvant mettre à jour la référence et les règles de propagation des modifications dans le SI, les mécanismes détectant et remédiant les inconsistances entre sources…
Il n’est pas possible de lister ici toutes les informations qui, dans un contexte ou un autre, peuvent être pertinentes. Mais c’est bien l’architecture d’entreprise qui définit le périmètre et les limites de cette gouvernance des données.
Cette gouvernance doit faire en sorte que l’utilisation des données ne reflète pas les anciens silos techniques. Elle permet aussi de faire contribuer les experts Métiers, fonctionnels et techniques sur la façon d’utiliser ces données qu’ils connaissent bien. Leur engagement et leur implication participent grandement du décloisonnement.
La technologie Data Lake pourrait permettre d’accepter n’importe quelle donnée sans surveillance ni gouvernance. Mais les organisations qui ont profité de cette possibilité de ne plus surveiller, ni mettre en place une gouvernance se sont retrouvés avec un Data Swamp dont la gestion est plus complexe, les bénéfices plus aléatoires et les risques opérationnels sans commune mesure avec ceux d’un Data Lake sous le contrôle des architectes d’entreprise.
Transformation continue et pilotage par la donnée
Commencer par aligner dans les deux sens
On se prive d’opportunités lorsque l’alignement entre le système d’information et les Métiers se fait toujours au détriment du SI. La complexité technique invisible aux demandeurs d’évolutions et la difficulté de rendre le SI adaptable aux exigences imprévues, rendent l’alignement difficile.
Dans le cas d’un Data Lake, lorsque différents acteurs Métiers accèdent au catalogue de données et aux services associés, le Métier s’aligne de lui-même sur ce que le SI lui rend disponible. En ouvrant son catalogue et en étant capable d’afficher ce qu’il est techniquement possible de fournir, le SI rationalise les exigences du Métier. Il le doit au socle urbanisé qui assure la maîtrise technique des flux et à la gouvernance pour la maîtrise fonctionnelle des données.
Certes, un travail effectué par le SI est toujours nécessaire pour s’aligner sur le besoin. Mais ce besoin sera plus naturellement cadré et les impossibilités techniques seront beaucoup plus rares.
Puis baliser la propagation de l’innovation
De même que le DevOps est le chaînon manquant entre deux mondes aux fonctionnements difficilement compatibles (le développement et l’exploitation), de même, il manque une étape importante entre la Data Science – qui extrait la valeur et valide la pertinence d’une nouvelle utilisation d’un ensemble de données – et le Métier qui attend une mise en production rapide de cette segmentation, cette visualisation ou cette publication.
Votre Data Lake va peut-être vous apporter de nombreuses idées de nouvelles utilisations de votre patrimoine de données. Il est rationnel de mettre en place des processus simples pour l’industrialisation de ces différents types d’utilisations.
Un « DevOps Data » avec des outils plus proches de la gestion de paramétrage que de la gestion d’une intégration continue. Il s’agit moins d’injecter de nouvelles versions applicatives dans le SI que de faire cohabiter des usages à différents degrés de maturation dans le même SI. A partir du Data Lake, il sera permis d’enrichir en continu des API à usages internes ou externes, ou d’automatiser la création de Data Sets pour des besoins de BI et de reporting. Ce DevOps se met en œuvre principalement autour :
D’outils d’orchestration des processus,
D’une bibliothèque extensible de connecteurs,
Du travail algorithmique des Data Scientists,
De la gestion des droits et des accès aux différents services,
D’une gestion des sources, des environnements et des déploiements, plus classiques du DevOps.
De convertisseurs en sortie pour fournir les formats utiles.
L’architecture d’entreprise associée à un Data Lake vous permet de créer du logiciel robuste, professionnel et évolutif sans vous lancer dans des appels d’offres de COTS qui reproduisent prioritairement les besoins du plus grand nombre, et non vos besoins spécifiques. Votre Data Lake devient l’élément central d’un applicatif adressant vos innovations sur-mesure.
Data lake et transformation
Cette évolution continue à l’échelle de l’entreprise fera le succès du Data Lake. Ce changement de paradigme a beau être souvent problématique, la nécessité d’une conduite du changement amenant à une modification de l’organisation est rarement perçue ; alors même que les Data Lake sont issus de GAFA et de startups dont la culture et l’organisation sont souvent à l’opposé des organisations matricielles qui s’emparent actuellement du Big Data et des Data Lake.
Ce mode de fonctionnement va bouleverser des pans entiers de votre organisation, modifier les circuits de décisions, les périmètres de responsabilités, les modes de communications internes et externes, les cycles de vie des produits et services, le contrôle des mises en production. Ces nouveautés sont anxiogènes et vont entraîner des résistances et des stratégies d’évitement.
C’est justement pour adopter plus facilement une démarche transverse affectant aussi bien l’architecture technique, les processus métiers, que l’accompagnement de la transformation de l’organisation, que l’architecture d’entreprise a été créée.
La mise en place d’un Data Lake est un saut dans l’inconnu. L’architecture d’entreprise est votre parachute.
« Gouvernance », le mot fait souvent peur. Si vous êtes consultant, vos clients les plus opérationnels vous font certainement un sourire poli quand vous évoquez le sujet, alors qu’ils pensent « Mais qu’est ce qu’il veut encore me vendre celui-là. Une machine à gaz qui va prendre beaucoup de temps, beaucoup de slides, et ne servir à rien ! » ; « Vous savez, nous avons déjà bien d’autres sujets à traiter ».
« Gouvernance des données », vous amenez l’expression avec habileté, en rappelant le volume considérable des données qui deviennent de plus en plus complexes à maintenir, sécuriser, exploiter, BLA, BLA, BLA. Et votre client le plus pragmatique vous dira « C’est bien gentil, mais ça ne m’aide pas à répondre à la demande de ce matin de l’équipe Marketing qui veut que je lui propose une solution pour cibler plus intelligemment les opérations / campagnes marketing… ou celle de l’autre jour de l’équipe Finance, qui n’en peut plus de faire à la main tous ses rapports sur Excel… »
Toute gouvernance, la gouvernance de données incluse, doit être une solution pour répondre à des usages et des points d’attention du métier (la DSI étant un métier parmi les autres).
Évitez la gouvernance de données pour la gouvernance de données !
Il existe une démarche qui a depuis longtemps trouvé sa place dans de nombreuses entreprises, mais qui a très vite montré ses limites, la voici (cela va vous parler si vous avez déjà challengé vos consultants sur le sujet) :
On va modéliser toutes les données existantes dans votre système d’informations
On va identifier les sources applicatives associées à ces différentes données
On va désigner des responsables pour chaque objet de données (des data owners, data stewards, …)
On va écrire des processus de gouvernances des données (validation, workflow, …)
On va mettre en place une instance de gouvernance sur la donnée
On fait tout ça d’abord avec notre vision DSI, on ira voir les métiers une fois qu’on aura une démarche déjà bien en place…
Alors, cela vous rappelle quelque chose ? Cette démarche : c’est faire de la gouvernance pour… SE FAIRE PLAISIR !
Une fois à l’étape 6, je vous défie de répondre précisément à la question suivante : « Alors, à quoi sert-elle cette nouvelle gouvernance ? Que va-t-elle améliorer précisément pour le marketing ? pour l’équipe financière ? pour l’équipe communication ? etc. ». N’ayez aucun doute là-dessus, la question vous sera posée !
La gouvernance des données doit être une solution pour mieux répondre aux usages :
Vos métiers utilisent les données. Ils savent ce qui doit être amélioré, ce qui leur manque comme données pour mieux travailler, tout ce qu’ils doivent faire aujourd’hui pour parer aux problématiques de qualité des données, le nombre de mails qu’ils doivent faire pour trouver la bonne donnée, parfois en urgence, pour leurs usages courants … Ils savent tout cela. Alors plutôt que d’inventorier toutes les données de vos systèmes, partez des usages des métiers et de leur point de vue et formalisez ces usages existants et les usages de demain
Concentrez vos efforts de gouvernance pour améliorer ou permettre les usages à plus forts enjeux ou risques pour l’entreprise
Cherchez à maîtriser l’ensemble de la chaîne de valeur, usage par usage (de la collecte à l’utilisation effective de la donnée pour l’usage) : organisation, responsabilités, outillages/SI
Faites évoluer votre gouvernance par itération, en partant toujours des usages.
Comprenez la stratégie de votre entreprise. Votre direction générale doit être sponsor. Donnez-lui les éléments pour la faire se prononcer sur une question simple : Sur quel pied doit danser en priorité la gouvernance Data, 40% sur le pied offensif (Aide au développement de nouveaux usages innovants), 60% sur le pied défensif ? (Gestion des risques GDPR, maîtrise de la qualité des données concernant les usages identifiés les plus critiques, …) ? 50/50 ? Elle doit vous donner les clés pour prioriser et itérer en adéquation avec la stratégie de l’entreprise.
La gouvernance des données est avant tout un sujet métier. Vous ne le traiteriez pas correctement en restant dans votre étage DSI… Cela peut paraître évident. Mais même quand certains le savent, ils choisissent la facilité : Rester à la maison…
Sortez, rencontrez tous les métiers, et vous formerez une base solide pour votre gouvernance. Ne sortez pas, et vous perdrez beaucoup de temps et d’argent…
Vous avez peut-être souvent entendu ces mots « Data is an Asset ». Mais la personne qui les prononce va rarement au bout de l’idée. Et pour cause, l’exercice est plus complexe qu’il n’en a l’air. Cet article a pour ambition d’éclairer le domaine et, pour cela, procédons par étape :
1 – Qu’est-ce qu’un Asset ?
Nous n’allons pas l’inventer, il existe une très bonne définition sur ce site : https://www.investopedia.com/ask/answers/12/what-is-an-asset.asp)
« An asset is anything of value that can be converted into cash. Assets are owned by individuals, businesses and governments »
« Un asset est quelque chose qui peut être converti en monnaie sonnante et trébuchante ».
Avec une maison, cela marche bien en effet. Une expertise suffira à vous donner une bonne idée de la valeur euro de votre maison. Mais pour vos données, ça ne paraît pas si simple.
Le défi aujourd’hui est d’être en mesure de valoriser une donnée, ce qui signifie :
Pouvoir par exemple très formellement comparer deux actifs Data entre eux, deux jeux de données (par exemple sur la base de critères bien définis)
Mettre une valeur « euro » sur un jeu de données (monétisation, prise en compte de l’actif Data sur des opérations d’acquisition / fusion, etc.)
Gérer nos données comme des Actifs, pour maintenir ou développer leur valeur dans le temps
Sur ce dernier point, faisons l’exercice rapide ensemble. Prenons un processus d’asset management standard, appliquons-le à la donnée.
2 – Appliquons un Processus d’Asset management à la Data
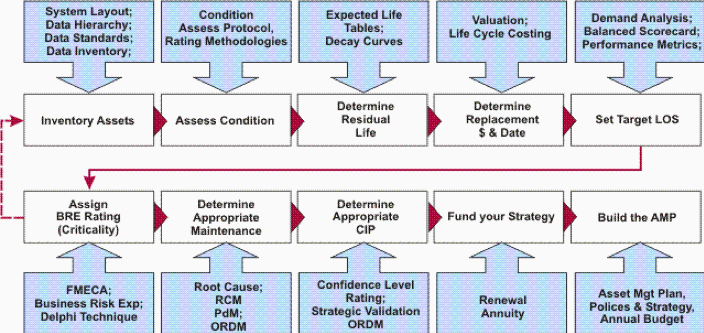
Alors allons y ! Appliquons ce processus sur les données pour voir si elle peut être gérée comme un Asset ?
« Inventory » :Inventorier les assets Data. Jusque-là tout va bien.
« Asset Condition Assessment » :Évaluer l’état des biens: Est-ce que la donnée est de qualité, est-ce qu’elle il y a souvent des erreurs qui apparaissent ? Comment les gère-t-on ?
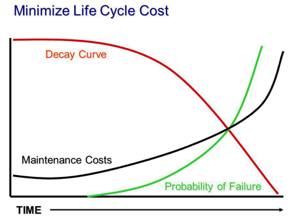
« Determine residual Life / Decay curve » : Il s’agit d’évaluer l’évolution potentielle de différents critères de valeur dans le temps. Par exemple est-ce que la donnée risque de perdre en rareté ? Les usages vont-ils être moins importants ? etc. En général cette notion porte sur le vieillissement d’un bien physique :
« Valuation » : Pour valoriser la donnée, on sent qu’il nous faut poser clairement un cadre de valorisation sur base d’un ensemble de critères. Au même titre que l’expert par exemple en Asset commercial connaît parfaitement les critères qui permettent da valoriser un commerce (surface du commerce, chiffre d’affaire, situation géographique, etc…). Notre conviction est qu’il faut aujourd’hui développer ce cadre pour l’actif « Data ».
« Life Cycle Costing » : C’est le processus qui permet d’identifier tous les coûts impliqués dans le cycle de vie de l’actif (coût d’une erreur, coût de la réparation / correction, coût de la perte de production éventuelle, coût de la maintenance corrective, ….)
« Determine replacements» : Est-ce qu’il faut revoir la manière de gérer certains asset Data ? Faut-il en abandonner/purger certains, non rentables ?
« Set target LOS » : Quel est le niveau de service attendu sur chaque asset Data ? A quels besoins faut-il répondre pour que l’asset ait de la valeur, soit viable ? Quels critères de valorisation veut-on améliorer ? (rareté, qualité, …)
« Assign BRE rating » = Business Risk Evaluation : Et quels sont les risques ? (GDPR, perte de données, …) : « Comment est-ce que des problèmes / incidents peuvent apparaître ? Quelle probabilité d’apparition ? Qu’est cela coûterait si le problème apparaissait ? Quelles en seraient les différentes conséquences ? »
« Determine Appropriate Maintenance » : Si l’on veut maintenir la qualité d’une donnée par exemple, par exemple 3 stratégies de maintenance existent dans le monde physique, elles sont applicables à l’actif Data (Use Base Maintenance : revue à une fréquence donnée, Fail based maintenance : correction sur incident/erreur, Condition Bases Maintenance : Maintenance plus préventive)
« Determine Appropriate CIP » (Capital Investment Program) : Initier (ou mettre à jour) notre programme d’investissement (Projet d’extension du capital d’assets Data, de renouvellement/modification de la gestion de certains Assets, mise en place de nouveaux processus de maintenance = gouvernance…)
« Fund your strategy » : On obtient le financement pour tout cela
« Build the Asset Management Plan » : Enfin on construit, ou on met à jour notre plan de gestion et de valorisation de nos assets Data
La méthode a l’air adaptée. Mais elle soulève des questions clés, auxquelles il va nous falloir répondre, notamment concernant les critères de valorisation. A titre d’exemple, le CIGREF a travaillé sur un cadre d’appréciation de la valeur économique des projets de transformation numérique. Il est intéressant d’avoir une approche comparable pour l’actif « Data ».
3 – Et après ?
Nous venons de voir que la data est effectivement un actif, d’un type bien particulier. Pour aller plus loin, il va falloir identifier des critères objectifs de valorisation des données, et faire des usages de ces données un vecteur clé de sa valorisation.
Dans cet optique, nous pensons qu’un cadre méthodologique de valorisation des données est nécessaire.
Rhapsodies Conseil construit une approche méthodologique pour mesurer la valeur des données, en mettant les usages métiers des données au cœur de la méthodologie, approche que nous vous invitons à découvrir prochainement. En parallèle, nous vous recommandons les travaux initiés sur ces sujets par Doug Laney pour Gartner Inc., en particulier à travers son ouvrage « Infonomics » aux éditions Routledge.
Plusieurs questions se posent aujourd’hui, alors que de nombreux environnements Hadoop sont en production depuis quelques mois / années :
Le Data Lake est-il aussi utile/utilisé que prévu ? et ne l’utilise-t-on pas, à défaut d’avoir trouvé un usage pertinent, à des fins qui n’étaient pas prévues au départ ( exemple courant … GPP : Gros Passe Plat ou encore EDDC : Extracteur De Données Centralisé … )
Comment structurer les données dans le Data Lake ? Si c’est pour mettre un Hadoop chez soi et structurer sa donnée dans quelques parquets et des tables hive, mais avec la même logique que nos bonnes vieilles tables SQL normalisés 3NF, à part de dire « Youhou, hadoop on l’a fait, on en a une belle maintenant ! » Quel intérêt ? C’est comme s’acheter une console Switch en ne la décrochant jamais de son socle (pardon pour l’image pour ceux qui ne connaîtraient pas la dernière console de Nintendo…).
Comment on rend la valeur de l’outil palpable par l’utilisateur final ? Que ce soit pour du reporting quasi temps-réel / journalier / mensuel, de la Data Viz ou de l’analyse de données avancée (un super Random Forest, un neural Network au top en production…) qu’est ce qui fera la différence pour l’utilisateur final ? Par rapport à ce qu’on lui donnait déjà avant…
J’essaie de donner des éléments de réponses ci-dessous et ce n’est que mon humble avis. Si vous avez vos expériences à partager n’hésitez pas.
1 – Le data lake est-il aussi utile/utilisé que prévu ?
Les environnements distribués naissent un peu partout au moment ou j’écris ces lignes. 2 cas caractéristiques existent qui peuvent être problématiques :
Cas 1 – Etre gourmand, trop gourmand : De nombreuses entreprises se sont ruées vers la tendance sans même vraiment avoir eu une réflexion de fond sur la valeur que devraient leur apporter ces nouvelles capacités dans leur contexte, elles se retrouvent aujourd’hui avec des téras stockées qui ne leur apportent pas autant qu’elles l’auraient espérées. On a voulu en mettre beaucoup, on n’a pas pris le temps de travailler sur la description de ce qu’on y a mis (meta data), et peu de gens comprennent vraiment ce qu’on peut y trouver et si c’est vraiment fiable.
Leur Data Lake devient petit à petit un passe-plat facilitant préparations et fournitures de certaines données bien spécialisées, même sur des volumes qui ne justifient en rien son usage, opérant quelques croisements ici et là entre sources originales qui n’étaient pas avant dans le même environnement technique. Elles font face à des bi-modes Hadoop VS Entrepôt Oracle/SAS (pour ne donner qu’un exemple). Certaines données sont dans les deux types de système et l’utilisateur Analyste ne sait pas vraiment lequel utiliser. Alors les Data Scientist, statisticiens – vieux de la vieille continuent à bosser dans SAS parce qu’ils n’ont pas le temps d’apprendre Python, et les petits jeunes qui sortent d’écoles pensent pouvoir changer le monde avec leur modèle de churn codé en Python / Spark mais qui a en réalité déjà été implémenté il y a 10 ans par un Data Miner expert SAS avec une méthode et des résultats similaires… Ce n’est qu’un rien caricaturale.
Pour prouver sa valeur et justifier son coût, ce Data Lake là va devoir se recentrer sur des usages clés porteur de valeur (et de gain euros…) pour l’entreprise, qui justifie son existence, ou mourir de désillusion ou rester un gros GPP (gros passe plat…).
Cas 2 – Etre timide, trop timide : D’autres entreprises plus prudentes, fonctionnent en petites itérations, à base de POC Big Data sous Microsoft AZURE, AWS et autres google cloud, en sélectionnant des cas d’usages qui justifient l’utilisation de telles plateformes. Parfois, le risque est d’être dans l’excès inverse du premier cas, en priorisant trop et en ne montrant rien.
Trouver 3 usages coeur de métier pour commencer est une excellente chose, mais les cas d’usages doivent être assez complets pour montrer l’étendue des possibilités que peut apporter un environnement comme hadoop et tous ses petits (la multitude d’outils d’intégrations, d’analyses, de traitements qui se basent sur hadoop).
Toutefois, faire un vrai POC métier est la clé pour les entreprises qui en sont à ce stade, montrer que Hadoop traite très très très vite un très très très gros volume de données, n’apporte rien au métier. Faire une démo d’un outil métier qui illustre un vrai cas métier en mettant en valeur :
La performance ressentie par l’utilisateur (des jolis diagrammes qui s’affiche rapidement quand l’utilisateur clique sur la carte 🙂 « C’est beau, ca va vite, c’est utile ! ouaouh ! »
La valeur/connaissance apportée en plus en allant au bout de l’usage : On sait détecter un problème, une fraude, etc…et ça génère une alerte en temps réel dans l’outil de l’opérateur qui lui recommande l’action à faire ! Ouaouh merci c’est ce qui fallait ! c’était possible alors ? dingue…)
Dans tous les cas, encore une fois allez au bout de l’usage ! On a tendance à s’arrêter juste un peu avant ce qu’il faudrait (par manque de temps, de connaissance métier, de courage). Ne faites pas un POC IT, ayez le courage de faire un vrai POC business pas juste à moitié parce que vous ne connaissez pas assez le métier, allez jusqu’au bout de la démonstration, jusqu’à la jolie petite interface interactive qui fera la différence. Sinon vous n’aurez pas votre Waouh. Faites collaborer les Data Scientist avec les développeurs des appli métiers pour avoir un vrai résultat.
Si vous ne faites pas cela, les gens comprendrons peut être la théorie « D’accord vous faites une grosse boîte où vous mettez toutes les données et puis ça tourne vite comme une machine à laver, c’est ça ? 🙂 ».
Non ! vous voulez un : « Ah, mon opérateur ne va plus devoir scruter toutes les logs à la mano pour essayer de trouver les problèmes, et je vais multiplier par 10 ma productivité donc…En fait…Ai-je toujours besoin d’un opérateur ? » OUI, là on est bon.
2 – Quelques principes pour structurer le data lake
Ne traitez pas votre Data Lake comme une poubelle à données qu’on recyclera peut être un jour en cas de besoin (le fameux « on prend, on sait jamais » du Data Lake, anti GDPR par dessus le marché). Mais traitez le bien comme un lac nourrissant, abreuvant et vital ! Moins de quantité, plus de qualité.
Structurer vos Données intelligemment. Ce n’est pas parce que vous avez beaucoup de place que vous pouvez en mettre de partout et n’importe comment (que dirait votre mère franchement?). Votre Data Lake doit normalement séparer :
Les données sources (Raw Data)à l’image des données du système sources
Les données sources (Raw Data) retraitées uniquement par applications de règles purement techniques (votre format de date standard, types de données, etc…). Pas de règles métiers ! Pas ici, le but est juste de récupérer la donnée brute ! C’est d’ailleurs un sage principe que vous trouvez aussi dans la philosophie DataVault de Dan Linstedt. Vous n’appliquez des règles métier qu’au moment de la construction de vues métiers qui répondent à un usage donné. C’est aussi surtout du bon sens…Cela apportera bien plus d’agilité à l’ensemble du système.
Une Historisation structurée et intelligentedes données du Data Lake. « OH Non ! Il a dit « structuré » et « Data Lake » dans la même phrase le monsieur, c’est pas joli ». Malheureusement, beaucoup d’entreprises oublient cette étape. Mais pourquoi donc ? Suivez par exemple ici (encore désolé…) la modélisation Data Vault 2.0, je parle principalement des concepts de Hubs, Links, Satellites, ou au moins la philosophie pour cette partie. Vous pouvez éventuellement exclure de cette phase certaines données exceptionnelles (par exemple si ce sont des données vraiment peu utilisées très spécialisées, que vous savez ponctuelles comme des données externes one shot (que vous n’achetez pas tous les mois…).
!!! Attention je ne dis pas qu’il faut faire un Data Warehouse d’entreprise dans le Data Lake (je ne rentrerai pas dans ce débat). Le Data Lake doit couvrir un certain nombre de cas d’usage spécifiques, qui nécessitent d’historiser (avec agilité !) un certain périmètre de données, qui tend à grandir au fur à mesure que les nouveaux cas d’usages apparaissent.
Si vous vous arrêtez aux Raw Data et aux business View et que vous ne mettez rien entre les deux, que vous ne faites pas ce travail de structuration fonctionnelle, au bout d’un moment vous aurez un gros sac de données applicatives, et les Data Scientists et autres utilisateurs devront eux même comprendre la logique de recoupement de toutes les sources (notamment le grain, la définition des clés techniques/métiers, etc.). Faites ce travail de structuration de l’historisation (DataVault 2.0 recèle de bonnes idées).
Les données préparées pour être prêtes à l’Usage (Business View), requêtables rapidement pour usages business. C’est dans la consolidation de chacun de ces socles que les règles métiers sont appliquées ! Ici, On ramène les données au plus proche de l’usage et structurées pour l’usage en question. Et n’hésitez pas à dé-normaliser vos Business View! Vous n’êtes pas dans mysql… Plein de lignes et plein de colonnes ? C’est fait pour ! Vous pouvez même aller (dans certains cas) jusqu’à pré-calculer dans une grosse table adaptée tous les indicateurs sur toutes les combinaison de segments (dimensions), de périodes, de dates… (attention, intérêt à mesurer par rapport à votre propre usage de consommation de la donnée), mais ça se fait : « ouahou ! comme les graphiques s’affiche vite… »
Les métadonnées : leur intégration peut se faire de diverses manières, mais faites en sorte que les gens ait confiance aux données qu’ils utilisent (C’est quoi cette donnée ? d’où vient la donnée ? quelle application, quel fichier source ? Qui l’a saisie ? Quand l’a-t-on intégré au Data Lake ? quelle fréquence de mise à jour ? etc.)
3 – Comment on rend la valeur de l’outil palpable par l’utilisateur final ?
Ne croyez pas (et je suis sûr que vous ne le croyez pas) que votre Data Lake se suffit à lui même
S’il est déjà bien structuré (c’est déjà un gros avantage), il a quand même besoin de belles décorations :
je ne vous apprendrai rien : un outil de Data Viz/report qui plaît au métier (parce qu’il a été impliqué dans son choix…). Je ne ferai pas de pubs ici…
Une bonne intégration avec les systèmes opérationnels et dans les deux sens (un savoir faire sur le sujet), pas qu’en collecte. Par exemple : Lancer des simulations directement depuis mon application de gestion qui va lancer un job spark sur la business view associée qui elle va renvoyer des résultats en un rien de temps sur l’application de gestion : L’utilisateur est heureux, il ne connaît pas Hadoop ou Spark, il ne veut rien en savoir, mais vous avez amélioré significativement sa façon de travailler. C’est ce qu’il faut viser. C’est cela aller au bout de l’usage.
Un environnement complet d’analyse pour vos Data Scientist (Data Viz, développement IDE, collaboration/gestion de version, notebooks, les bonnes librairies de dev !) parce qu’ils en ont besoin. Impliquez réellement les principales personnes concernées dans ce choix !
Pour conclure, les idées clés :
Les usages doivent toujours driver la construction itérative de votre Data Lake
Ne cherchez pas à refaire un/des Data Warehouse 2 sans vraiment savoir par qui, pour quoi ce sera utilisé, ne cherchez pas à manger un maximum de données pour devenir le plus vite possible la plus grosse base de données et justifier le nom de votre équipe, BIG Data, j’imagine…
Si on vous pousse un usage auquel on pourrait répondre sur une base mysql, redirigez gentiment le destinateur…A moins que vous soyez force de proposition pour faire évoluer son usage pour justifier l’utilisation d’une telle plateforme.
Si vous êtes assez matures, ne voyez plus votre Data Lake comme un Lab collecteur qui se suffit à lui-même, si vous allez au bout des usages, vous serez obligés de l’intégrer avec des applications métier (vous savez, l’utilisateur qui clique dans son appli et ça lui sort toute sa simulation en 0.5 secondes…).
Inspirez-vous de la philosophie de monsieur Data Vault 2.0 (Dan linstedt) (je ne dis pas qu’il faut tout prendre, mais au moins inspirez vous des concepts de Hub / Links / Satellites qu’un enfant de 4 ans peut comprendre pour une structuration agile de l’historique de vos données). Cela évitera bien des noeuds au cerveau à vos utilisateurs, Data Engineer et Data Scientist, et cela apportera de l’agilité au bout du compte.
Dé-normaliser vos vues métiers ! Dénormalisez vos étoiles, vos 3NF, ça ira bien plus vite !
Le Data Scientist « Stateu » doit ouvrir les yeux au Data Scientist « Informaticien » sur ce qu’il est vraiment en train de faire tourner. Le Data Scientist « informaticien » doit apprendre au Data Scientist trop « stateu » à produire du code industrialisable et réutilisable. Recrutez les deux types de profils (Ecoles de stats, et école d’ingé informatique)
Si vous faites collaborer vos Data Scientist avec les équipes de développements des applications métiers, alors c’est que vous êtes sur les bons usages…
Les APIs sont omniprésentes. Les métiers en demandent car elles promettent les plus belles perspectives commerciales, des effets boules de neige et de la démultiplication de valeur. Les consultants ne jurent que par cette solution. Pas un schéma d’architecture sans que l’API Gateway ne règne en maitresse, ayant comblé le moindre interstice entre les applications et s‘érigeant en barrière impérieuse entre les deux mondes du Legacy et des frontaux Web, chantre et cœur de l’IT bi-modal.
Obnubilé par les promesses de l’API management, la réflexion sur le bien-fondé de l’utilisation d’un échange synchrone est morte née.
Votre direction a donc investi (cher) et la cellule d’architecture applique une stratégie d’API par défaut.
Mais obnubilé par les promesses bien connues de l’API Management, la réflexion sur le bien-fondé de l’utilisation d’un échange synchrone est passée au second plan. Tout comme la SOA avait imposé ses Web-Services pour des raisons de vitesse de propagation, l’API Management assoit sa domination sur sa supériorité technologique pour l’exposition à l’ensemble des partenaires.
Les échanges synchrones n’offrent aucun mécanisme efficient de reprise des erreurs.
On en oublie une caractéristique et une limite intrinsèque à ce type de flux. Les échanges synchrones ne se justifient en effet que quand une réponse (et donc un aller-retour) est nécessaire, et ils imposent en contrepartie un couplage fort entre l’appelant et l’appelé, l’échange ne pouvant pas aboutir si l’appelé n’est pas disponible au moment précis de l’appel. Les échanges synchrones n’offrent ainsi aucun mécanisme efficient de reprise des erreurs techniques (des retry toutes les 5 secondes ? Pendant 1 heure par exemple ? avec de plus en plus de services qui ne répondent plus… ? Autant sortir les arva® et attendre le Saint Bernard).
On tombe ainsi dans des cas où le rejeu devient très gênant et où la responsabilité de ce rejeu est déporté vers l’appelant alors que son message était correctement émis, correctement formaté et qu’il ne tire aucun bénéfice de l’acquittement HTTP qui lui reviendra. On rencontrera particulièrement ce cas sur des appels visant à créer ou modifier des données. Qui est responsable du rejeu d’une fonction POST ou PUT tombée en erreur ? Pour peu que le partenaire appelant soit une application SaaS, un logiciel propriétaire voire pire un partenaire B2B, on se retrouve dans une impasse.
Les échanges asynchrones et leur pattern publish-subscribe apportent par construction une extrême résilience à ce type d’incident en persistant les messages et en laissant les destinataires maitres de leur rythme de consommation. Ajouter à cela la grande facilité de paramétrage d’une nouvelle cible -là ou une plateforme d’API demandera une nouvelle règle de routage- et l’on retrouve pourquoi les solutions asynchrones sont des impératifs d’un SI bien structuré.
Il serait bien trop limitant de se passer d’un portail d’API et de l’accessibilité externe qu’il offre.
Favoriser l’asynchronisme est un bon principe de conception de flux.
Si l’échange est unidirectionnel, que la donnée peut être stockée chez le consommateur et que la fréquence de modification n’est pas trop importante, oubliez le synchronisme, rendez sa liberté au fournisseur d’information et appuyez-vous sur votre MOM ou EAI !
Pour autant il serait bien trop limitant de se passer d’un Portail d’API et de l’accessibilité externe qu’il offre. La facilité d’exposition offerte par ces solutions est sans pareil sur le marché actuel.
Appliquez-vous donc à construire un système hybride. Pensez l’API Gateway, et le package HTTP, REST et JSON comme un connecteur, une porte d’entrée sur votre SI, et débrayez immédiatement derrière sur une solution de bus de messages (MOM ou EAI) dès que cela est sensé.
En cassant la chaine du synchronisme on récupère la souplesse souhaitée, en maintenant la Gateway en frontal on conserve l’ouverture et la facilité d’utilisation.
Architecture d’entreprise et agilité – chap 4 : comment les architectes d’entreprise peuvent interagir avec l’agilité ?
En tant qu’architecte, quelle posture adopter face à un projet Agile ? Et dans le cadre plus global d’une entreprise Agile, comment est intégrée la notion d’architecture ? Quel rôle est dévolu à la fonction Architecture ?
Les principaux frameworks d’agilité à l’échelle intègrent l’architecture d’entreprise : DAD – Disciplined Agile Delivery-, SAFe – Scaled Agile Framework- et LeSS – Large Scaled Scrum.
Que nous manque-t-il alors pour vraiment travailler ensemble ?
Les architectes et l’agilité se connaissent !
D’un côté, les architectes ont travaillé à l’évolution de leurs pratiques et regardent l’agilité avec intérêt depuis plusieurs années déjà : article de 2008, article de 2010, conférence de l’Agile Tour en 2011, etc… Ils ont inventé la « Continuous Architecture »
La « Continuous Architecture » énonce des principes facilitant l’interaction avec les projets en agilité. Ces principes mettent en avant l’adaptation et l’intelligence qui doivent guider les travaux des architectes pour convenir au rythme et au fonctionnement des projets Agiles.
Voici quelques principes de « Continuous Architecture » qu’il est intéressant de noter : partager les décisions, partager l’information, être collaboratif, etc …
D’un autre côté, les framework d’agilité à l’échelle les plus connus (DAD, LeSS ou SAFe par exemple) ont pris en compte les architectes dans leurs modes opératoires. Des définitions de l’architecture sont proposées. Les livrables et interactions des architectes avec les projets / programmes agiles sont définis.
Quelles questions restent donc à traiter pour que les 2 travaillent en symbiose ?
Une bonne définition de l’architecture d’entreprise dans l’agilité
Les définitions proposées par les frameworks d’agilité à l’échelle reprennent les éléments essentiels de l’Architecture d’Entreprise :
Vision long terme et à haut niveau de la transformation de l’entreprise,
Réutilisation,
Interaction avec les projets,
etc…
Des exemples concrets mettent en avant les apports de l’architecture dans le cycle de vie d’un produit Agile. DAD a un chapitre « Pourquoi l’Architecture d’Entreprise » qui décrit les apports essentiels de l’architecture d’Entreprise pour les projets comme de pouvoir se concentrer sur la valeur ajoutée et une plus grande cohérence dans les solutions.
L’architecture devient agile – forcément
Les frameworks mettent en avant des principes d’agilité que les architectes se doivent de respecter. Ainsi SAFe recommande aux architectes de bien rester en contact avec les activités journalières de développement et les équipes projets. De ce rapprochement, un gain mutuel de confiance est espéré : les architectes auront plus confiance dans les équipes projet pour suivre les cadres d’architecture, les équipes projet auront plus confiance dans les solutions proposées par les architectes.
Pour être en conformité avec les principes agiles, on remarquera que dans DAD, tous les livrables de l’Architecture sont sujets à des feedbacks (retours d’expérience). Il n’y a pas de décision unilatérale. L’architecture est dans un processus permanent de discussion et d’évolution.
Continous architecture – l’architecture agile
Pour se mettre en accord avec les concepts de l’agilité, l’architecture d’entreprise a énoncé un certain nombre de recommandations. L’une d’elles est justement de donner des principes d’architecture et non des règles !
Une autre de ces recommandations consiste à prendre les décisions le plus tard possible, laissant aux projets la possibilité d’étudier plusieurs solutions avant de trancher quand vraiment il le faut.
Une autre recommandation consiste à dire « il faut partager de l’information et non de la documentation », nous rappelle la discussion du chapitre 2 de cette série d’article. En d’autres termes et pour citer le manifeste Agile : les individus et leurs interactions plutôt que les processus et les outils.
Mais parfois l’Architecture semble quand même trop éloignée des préoccupations des projets…
Less et les architectes powerpoint vs les master programmers
Le framework LeSS, dans son chapitre sur Architecture & design, consacre son introduction à préciser que l’architecture de l’informatique est dans le code : ceux qui font sont ceux qui savent. Les architectes qui ne font plus du code mais font de l’architecture pour les managers ou de l’architecture pour de l’architecture finissent par se couper du monde et ne plus être entendus par les projets. Ils deviennent des « Architectes PowerPoint dans leur tour d’ivoire ».
Même si tous les architectes, qui plus est dans les grandes entreprises, ne peuvent pas rester au contact du code (qui plus en est quand la politique d’entreprise est centrée sur l’intégration de progiciels plutôt que la conception d’applications), il est de leur devoir d’interagir avec les architectes plus opérationnels et de veiller à ce que leurs travaux restent compréhensibles par tous. Et bien sûr applicables !
LeSS rappelle que le principal intérêt d’un modèle est la discussion que l’on a en faisant ce modèle. Le modèle n’est pas la solution et ne doit pas rester figé dans le temps.
Ces images illustrent la différence entre ce qui a été proposé (chemin goudronné) et les usages (chemin tracé par le passage des piétons)
Coaching et agilité ?
La transformation vers l’entreprise agile se fait beaucoup à partir de coaching des équipes et des managers. Ils sont accompagnés dans une réelle évolution de leurs pratiques afin de développer des modes de travail plus collaboratifs et les conditions d’une meilleure coopération.
En général, des coachs agiles interviennent pour faire évoluer ces pratiques et accélérer la transformation. Il faut alors qu’un mode de fonctionnement soit établi et les parties prenantes (comme les architectes) impliquées dans ces transformations.
Les architectes doivent donc être inclus dans ces transformations afin de bien mettre en place les modes de fonctionnement adaptés à chaque entreprise.
Les architectes doivent-ils être certifiés SCRUM Master ou Product Owner ? Doivent-ils être formés aux frameworks d’agilité à l’échelle comme DAD, LeSS ou SAFe ? Doivent-ils être accompagnés de coachs agiles ?
Suivant la transformation en cours, chaque entreprise devra apporter sa réponse. Que cela soit pour les architectes ou d’autres fonctions d’ailleurs !
Pour que l’architecture d’entreprise et l’agilité puissent travailler ensemble, il faut que l’entreprise s’approprie l’un et l’autre et pense bien à les faire travailler ensemble. La communication est un élément clé de cette réussite.
L’architecture d’Entreprise doit être un facteur facilitateur de l’agilité car elle apporte une vision partagée de la stratégie d’évolution du SI et doit donc servir à guider l’ensemble des travaux de l’entreprise sur son SI.
Dans le chapitre suivant, nous parlerons de l’évolution d’un des travaux majeurs des Architectes, le Schéma Directeur du SI.