Et si mon nouveau CRM devenait mon référentiel Client
Et si mon nouveau CRM devenait mon référentiel Client ?
Et si mon nouveau CRM devenait mon référentiel client ?
La question est légitime, car le CRM doit contenir l’ensemble des Clients / Prospects et l’information peut être tenue à jour par les commerciaux qui les rencontrent régulièrement. Mais avant de faire ce choix, quelques interrogations méritent d’être levées.
La gouvernance à mettre en place est-elle compatible avec mon CRM ?
Le CRM n’est pas le seul système à pouvoir créer, compléter ou mettre à jour des données Clients. Les systèmes de gestion, de facturation ou autres frontaux Clients influent également sur la vie de ces données. Appliquer au CRM l’étiquette de référentiel n’est donc pas suffisant. Il faut mettre en place l’ensemble de la gouvernance des données de référence Client (ou plus généralement concernant les Tiers) associées au principe de référentiel :
Définir le cycle de vie des Clients,
Définir un modèle objet exhaustif (qui ne soit pas limité aux seuls besoins du service commercial),
Pour chaque attribut, définir quels utilisateurs seront en capacité de le mettre à jour, à partir de quel outil, le tout en fonction du statut ou de l’état du Client,
Mettre en place une couche pour assurer la qualité de la donnée (formatage, dédoublonnage, contrôle de cohérence, complétion via des bases externes, …),
Prévoir les mécanismes et processus de validation des données,
Construire les interfaces nécessaires afin de consolider et de diffuser la donnée,
Définir les droits/politiques d’accès à la donnée,
Anticiper les impacts sur le pilotage, le reporting, la traçabilité, le versionning des données, la gestion des données à date, …
Quel modèle de donnée client dans le référentiel ?
Il faut également garder en mémoire que les CRM se concentrent par nature sur les éléments ayant trait à la relation commerciale avec les Clients. Or l’ensemble des données du CRM ne sont pas forcément à porter dans un référentiel. Inversement, dans bien des cas un CRM ne contient pas l’ensemble des données référentielles d’un Client (rôles du Client [payeur / commanditaire / bénéficiaire…], données techniques liées à la mise en place d’un service pour le Client…).
Construire le référentiel Client au sein du CRM implique donc de s’assurer que ce dernier contienne bien l’ensemble des données référentielles et de pouvoir aisément distinguer celles-ci des données à caractère opérationnel.
De plus, dans de nombreux cas cela implique également que des acteurs non commerciaux aient accès au CRM afin de maintenir ces données Client. La Direction Commerciale et Marketing souhaitera-t-elle ouvrir son outil à ces acteurs ? Ceux-ci accepteront-ils d’utiliser le CRM, outil qui n’est pas fait pour répondre à leurs propres besoins ?
Quel périmètre de données est concerné ?
Lorsque les clients sont des personnes morales, il peut être intéressant de croiser les données afin de savoir quels sont les clients qui sont également fournisseurs, quel est le chiffre d’affaire généré par un Client/Fournisseur vs la charge que représente ses prestations. Toute consolidation risque d’être complexe si les référentiels Client et Fournisseur sont distincts. Il s’agit pourtant dans les deux cas de personnes morales mais gérer ses Fournisseurs dans un CRM ne fait pas forcement sens. Dans ce cas, un référentiel ad hoc permettrait de pallier le problème. La problématique sera identique pour tout autre tiers d’intérêt comme les apporteurs d’affaire, les sous-traitants, les cautions / garants…).
Et la technique dans tout ça ?
Point inhérent aux précédents, le CRM a-t-il les capacités techniques pour assurer le rôle de référentiel ? Est-il capable de faire de la gestion de la qualité des données ? Ou alors s’intégrer avec un outil de DQM (Data Quality Management) spécifique ? Est-ce que le modèle de données du CRM est compatible ou suffisamment personnalisable afin d’intégrer le modèle de données de l’entreprise ? L’outil aura-t-il les capacités techniques pour diffuser l’information au sein du SI ? Supportera-t-il des dizaines de milliers de requête par jour ? Est-ce que le contrat de service associé à ce CRM est suffisant pour permettre à l’ensemble des applications qui en dépendent de fonctionner correctement ?
Est ce que je fais un bon investissement ?
Les aspects financiers sont également un élément-clé de la décision. Certes, de prime abord, utiliser le CRM comme référentiel Client permet d’éviter un investissement dans un nouveau système, mais à quel prix ? Combien coûte la mise en place (et l’exploitation) des fonctionnalités de référentiel au sein d’un CRM ? Combien coûtent la haute disponibilité, la qualité de service, les SLA qui n’étaient peut-être pas nécessaires pour le simple usage des commerciaux ? Combien coûtent les licences supplémentaires attribuées aux utilisateurs qui n’étaient pas dans le périmètre initial ? Le modèle de facturation du fournisseur est-il en cohérence avec l’usage que l’on souhaite en faire (un coût à l’usage peut s’avérer rapidement très onéreux) ? Est-ce que l’économie est réelle lorsque l’on compare cette option à la mise en place d’un référentiel dédié ?
Quelles sont les autres solutions possibles ?
Si le CRM n’est pas l’outil le plus adapté à votre cas, quelles sont les autres possibilités ?
Les MDM (Master Data Management) sont a priori plus aptes à traiter les problématiques de référentiel de données puisqu’ils ont été développés dans cette optique. Ils possèdent des fonctionnalités pour traiter la saisie, la consolidation et la diffusion des données et intègrent généralement une couche de DQM permettant d’en assurer la qualité.
Toutefois, la prudence s’impose car tous les outils n’ont pas forcement la même maturité et tous proposent des fonctionnalités qui répondent à des besoins qui ne sont peut-être pas les vôtres. Pourquoi payer les fonctionnalités d’un progiciel si c’est pour ne pas les utiliser ?
Pour répondre à des besoins relativement simples, le développement d’une solution spécifique pourrait être considéré.
Quelle est la meilleure solution pour mon référentiel client ?
CRM, MDM ou développement spécifique, il n’y a pas de réponse générique, mais il peut y avoir des conséquences sur l’ensemble du système d’information.
Bien que tous les éditeurs (de CRM) soutiennent que leur solution peut être utilisée en tant que référentiel Client, ils sont beaucoup plus tempérés une fois les besoins et contraintes à traiter exprimés.
Par ailleurs, et non des moindres, il faut noter que ce n’est pas uniquement le réceptacle qui fait le référentiel. C’est bien la gouvernance qui encadre la donnée qui permet de maintenir le point de vérité. Il est nécessaire de mettre en place une organisation avec des rôles et responsabilités définis ainsi que des outils adaptés respectant l’urbanisation et l’architecture du système d’information.
Mais n’en sommes-nous pas à la vision 360° client désormais ?
Encore une fois, malgré des éditeurs de CRM et de MDM qui promettent la Vision 360° Client, il faut replacer ces solutions à leurs « justes » fonctionnalités et regarder vers de nouveaux outils autour du Big Data qui permettent effectivement la mise en place d’une « vraie » Vision 360° Client sans pour autant remplacer le CRM ni le Référentiel Client. Ces visions consolidées et cross-business sont généralement utiles aux clients eux-mêmes mais aussi et surtout aux commerciaux ou gestionnaires pour leur permettre d’être encore plus efficient dans leur travail au quotidien.
Notons surtout que ces nouveaux outils ne font que renforcer l’intérêt d’un Référentiel Client qui soit partagé au sein du SI car construire une vision 360° Client nécessite d’agréger en un point unique des données venant de l’ensemble du SI.
De nouveaux types d’architecture, incluant la mise en place de Data Lake, d’API, de frontaux digitaux permettent la construction et l’utilisation de cette vision 360° mais elle ne restera possible que si les données peuvent être corrélées les unes avec les autres. Cette corrélation est grandement facilitée lorsqu’un référentiel Client a été mis en place au cœur du système d’information. La vision 360° n’a alors plus qu’à relier tous les éléments métier autour du « golden record » Client unique.
Préparation des champs, culture, traitement, récolte, acheminement, tri, emballage, préparation, … la liste est encore très longue avant que vous ne puissiez déguster votre produit.
Ceci est bien souvent imperceptible du grand consommateur mais les challenges à relever sont innombrables entre le champ et l’assiette.
Challenges d’autant plus compliqués à résoudre avec les enjeux qui courent :
Nourrir 7,7 Milliards d’humain sur Terre avec une tendance à la hausse de 1,2% par an,
Mieux répartir les denrées alimentaires pour éviter les gâchis aberrant et les famines navrantes,
Jongler avec un climat capricieux qui joue avec les extrêmes entre sécheresse et inondation,
Mieux manger avec une exigence réglementaire de traçabilité mais également impulsé par les consommateurs soucieux d’inverser la tendance,
Pour être efficace il faut agir sur chacun des maillons de la chaîne Production – Supply Chain – Vente tout en ayant une approche holistique.
Plusieurs révolutions ont bouleversé ces champs d’activité ces dernières décennies, une autre est en marche il s’agit de l’Internet Of Things.
L’IoT dans le champ : Agriculture 4.0
La production de denrées alimentaires est un secteur critique répondant à notre besoin primaire de se nourrir. Vous, moi, nous sommes désormais tous quasi dépendants de cette production qu’elle soit agricole, piscicole, …
Il faut optimiser les productions tout en respectant dame nature et ses ressources mais également les consommateurs finaux en garantissant une nourriture saine et de qualité.
La culture intensive est toujours très utilisée de par le monde mais aux vues des dégâts engendrés, des méthodes plus respectueuses ont émergé : agriculture raisonnée, durable, biologique, mais elles ne sont pas forcément viables dans tous les contextes (la perte de production pouvant se traduire par une perte de rentabilité sur un secteur déjà difficile et malmené).
C’est là que les nouvelles technologies et l’IoT entrent en jeu.
A bien des égards il peut être aberrant et contre nature de barder de capteurs cette dernière.
Et pourtant, quelques capteurs/actionneurs connectés …
… bien localisés avec une empreinte faible sur l’écosystème constituent un important levier d’optimisation pour :
Prédire la météo (à l’échelle de l’exploitation) et agir en conséquence,
Optimiser l’utilisation des ressources (eau, électricité, traitement, nourriture, …) en répondant au juste besoin (en quantité et en temporalité),
Déceler les comportements anormaux et les prémisses de maladies pour intervenir en anticipation,
Contribuer au bien être animal,
Identifier précisément les niveaux de maturation pour récolter au bon moment et limiter les pertes,
Préserver la qualité de la marchandise stockée,
Connaître en temps réel le stock disponible,
Diminuer la pénibilité du travail en automatisant certaines activités,
Limiter la pollution, l’usage de la biochimie (pesticide), et l’impact sur la faune et la flore.
La GreenTech rayonne de plus en plus avec des solutions innovantes et diversifiées, que ce soit sur les objets connectés eux mêmes mais également sur les plateformes IoT spécialisées (Sencrop, Libelium, Observant, Agrilab.io, pycno, arable, …).
En France, la valorisation des données Agricoles est lancée, la société API AGRO a créé une place de marché (AgDataHub) permettant aux éditeurs de services digitaux, notamment les start-up, de co-développer de nouvelles applications web et mobiles pour l’agriculture numérique.
Bien que ce paroxysme de la maîtrise de l’environnement et de la réutilisation des ressources en circuit fermé est parfaitement atteint dans les cultures hydroponiques, ces moyens technologiques peuvent trouver leur place dans tous types de production de par leur polyvalence d’emploi et leur facilité de mise en œuvre.
L’IoT dans la Supply Chain : Industrie 4.0
2 tonnes de poissons frais arrivent au port, 1 tonne de fraises sortent de l’exploitation, la course contre la montre démarre pour mettre ces denrées sensibles et périssables à disposition des consommateurs finaux.
La Supply Chain entre dans la danse avec son infrastructure (Entrepôts, chaînes mécanisées, poids lourds, camionnettes réfrigérées, …), ses processus très normés et son lot d’enjeux :
Comment garantir la chaîne du froid : pas uniquement au niveau du contenant (palette) mais également au niveau du contenu (poisson) lui-même ?
Comment géolocaliser mes flux d’entrées/sorties de marchandise ?
Comment optimiser le temps de transport et éviter les retards ?
Comment automatiser le rapprochement de données entre marchandises commandées et marchandises livrées ?
Comment garantir la qualité de mon aliment fragile à son arrivée à destination ?
…
L’accessibilité, l’autonomie et la performance des capteurs IoT couplés à un réseau 0G (LPWAN) peuvent faire des miracles …
Equiper vos moyens de transports et vos containers d’un tracker GPS pour :
les suivre en temps réel et adapter les parcours et moyens à mettre en oeuvre en fonction des aléas rencontrés sur le trajet,
gérer vos flux intermodaux d’entrée/sortie,
garantir la disponibilité de vos moyens de transport pour la prise en charge d’une nouvelle marchandise,
Placer des capteurs de températures / hygrométrie dans vos moyens de transport mais également au coeur de la marchandise pour agir au besoin sur les équipements de régulation afin de préserver la qualité des produits et garantir le respect de la chaîne du froid,
Installer des capteurs de mouvement et vibration pour déceler le malmenage de vos marchandises et :
agir en conséquence auprès de vos équipes, équipements et partenaires,
router la marchandise abîmée sur une voie parallèle plutôt que de la livrer à la poubelle
Étiqueter vos Unités de Conditionnement avec des tags RFID pour automatiser l’identification et le calcul de la quantité de marchandises reçues.
… en intégrant cet écosystème IoT au Système d’Information Supply (Warehouse Management System, Warehouse Control System, Manufacturing Execution System), l’ensemble devient connecté, plus efficient et proactif face aux défis et aléas à relever.
L’IoT en point de vente
Malgré la forte progression de l’e-commerce, 90% des ventes sont toujours réalisées dans les points de vente (PDV) physiques.
Ces derniers, en passant leurs commandes de marchandises, se positionnent en clients des deux précédents maillons (Production et Supply Chain).
Ils ont donc une responsabilité certaine sur :
la répartition des produits alimentaires,
le gâchis alimentaire
Mais également des exigences fortes sur la performance et l’agilité des deux précédents maillons pour obtenir de la marchandise de qualité en temps et en heure convenus.
Les points de vente ont finalement trois enjeux fondamentaux :
Piloter finement leur stocks pour à la fois :
éviter les ruptures qui engendrent un manque à gagner sur les ventes manquées et une insatisfaction client,
éviter le sur-stockage qui coûte cher et peut générer un important gâchis alimentaire
Vendre une marchandise de qualité pour…
… Satisfaire et fidéliser les clients.
Là encore les acteurs de l’IoT ont su cerner ces cas d’usage et proposer des solutions aux Retailers pour optimiser les processus clés de leur métier :
Utiliser des racks, étagères, présentoirs connectés afin de connaitre l’état réel des stocks en rayon pour optimiser le processus d’achalandage et de réapprovisionnement,
Utiliser des armoires réfrigérées connectées permettant de monitorer finement leur bon fonctionnement afin d’ intervenir rapidement en cas de panne et ainsi éviter les pertes de marchandises sensibles,
Remplacer les étiquettes papiers par des étiquettes électroniques connectées afin d’optimiser les processus d’affichage des prix de vente mais également pour afficher des informations recherchées par les consommateurs (traçabilité, ….)
Utiliser des caméras connectées (sous réserve d’autorisation) pour analyser la fréquentation, le comportement des consommateurs en fonction de la période et adapter en conséquence les commandes de marchandises,
Donner de l’autonomie aux clients pour que leur parcours de courses et d’achat soit agréable et efficace avec des solutions de self scanning, de panier connecté ou de casier connecté pour le retrait de marchandises en Click & Collect.
L’IoT sur chacun des maillons de la chaîne (Production, Supply, Retail) a su s’adapter et décliner des solutions efficaces pour répondre à leurs enjeux propres. Le challenge à relever pour atteindre l’efficience de l’ensemble, réside dans la capacité de chacun des maillons à s’intégrer (partage de données IoT/métier) avec les autres pour créer un écosystème connecté et intelligent au service du “mieux manger” et d’un environnement durable.
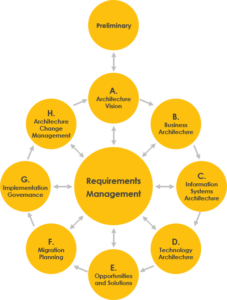
TOGAF est le Framework de l’architecture. Sa roue ADM est un classique. Le nombre de certifiés a explosé en France et dans le monde. Le but de cette série d’article est de voir avec vous, en se basant sur mon expérience de 13 années en tant qu’architecte, si ce framework doit être appliqué ou non, et sans renier la certification, réfléchir à comment l’appliquer et avec quel niveau d’investissement.
Nous allons donc commencer par explorer, dans cet article, les 2 premières phases, puis nous aborderons les autres phases dans de prochains articles.
Enfin certifié
Imaginons un plan de transformation du système d’information, vous êtes architecte et
on vous propose une formation. Comme vous êtes curieux, vous acceptez, et comme vous êtes travailleur vous réussissez l’examen final. Une fois la certification obtenue, et la satisfaction qui va avec, chacun s’est posé cette question : Qu’est-ce que je fais maintenant ? Et trop souvent, le résultat obtenu est décevant.
Il est décevant pour les certifiés qui ne savent pas comment mettre en œuvre ce qu’ils ont appris, mais aussi pour ceux qui ont financé cette certification et tout le monde a déjà entendu « TOGAF est trop loin de la réalité, cela ne sert à rien ». Alors, comment faire pour ne pas en arriver là ?
La phase préliminaire
Une phase primordiale
La première des phases de la roue ADM est celle qui, justement, est en dehors de la fameuse roue. C’est pourtant une phase vitale pour la suite de vos travaux. Elle sert à préparer l’entreprise aux travaux d’architecture (et pas uniquement la DSI). Les questions que l’on doit se poser sont « Où allons-nous faire de l’architecture ? avec Qui et Comment ? », mais également « Pourquoi ? ». L’odbjectif principal de cette phase est donc de construire une vue succincte des besoins, pour ensuite définir les capacités d’architecture que l’on pense nécessaire. Nous sommes en train de cadrer la mise en œuvre de l’architecture.
Capitaliser sur le sponsor
Lors de la formation, nous avons appris qu’il fallait commencer par définir la structure de l’entreprise puis les éléments métiers qui poussent au lancement de ce projet, de formuler la demande de travaux, de définir les principes d’architecture s’appliquant au projet, le référentiel à utiliser et les relations avec les autres référentiels de pilotage. Mais c’est également à ce moment qu’il faut évaluer la maturité de l’entreprise sur les notions d’architecture et que l’on peut adapter la méthodologie et l’ADM au projet.
Les « entrées », informations censées être collectées avant le projet, seraient : le modèle de l’organisation de l’entreprise, le référentiel méthodologique d’architecture, les outils, les principes d’architecture, le continuum d’entreprise, le référentiel d’architecture et le cadre de capacité… mais dans les faits, ces « entrées » sont rarement présentes.
Et pourtant, TOGAF préconise une première réunion avec le sponsor / commanditaire lors de cette phase et celle-ci est obligatoire. Lors de cette première réunion, les points cruciaux sont les entités / fonctions de l’entreprise pour définir le périmètre de l’étude, la gouvernance du projet d’architecture et bien sûr, le driver de la transformation. Sans cette réunion, il n’est pas utile d’aller plus loin, et si cela est difficile à organiser, vous avez déjà votre évaluation de la maturité.
Capitaliser sur ce qui existe pour ne pas consommer trop de temps
D’après TOGAF, il est possible, lors de cette phase, de modifier la roue ADM pour répondre au mieux aux besoins du projet de l’entreprise. Attention toutefois, il peut être dangereux de remettre en cause la roue ADM à chaque itération, et il faut absolument en garder le principe (l’enchainement des phases et les liens entre elles). Il est préférable d’avoir une roue stable sur un segment fonctionnel donné.
Nous allons donc commencer par la phase préliminaire elle-même : Le but est de de capitaliser sur ce qui a déjà été fait. Lors de la réunion avec le sponsor, vous avez identifié les grandes fonctions impactées. Pour identifier la capacité d’architecture nécessaire à votre projet, 3 situations peuvent se présenter à vous :
Si vous être dans une grande entreprise, il y a déjà des architectes en charge de ces fonctions, il suffit de leur exposer les attendus métier et de collecter leurs retours.
Si ce n’est pas le cas, il est possible de se baser sur des projets précédents. De façon native, de nombreuses étapes de la roue TOGAF sont déjà mises en place au sein d’un SI : des architectures applicatives ou techniques, parfois des processus sont déjà modélisés, des plans de migration sont mis à plat avec la gouvernance associée. Cela est tout à fait normal car TOGAF est un framework pour répondre à des besoins liés à une DSI et parfois, des réponses ont déjà été apportées à des besoins apparus lors des projets. Il faut alors se baser sur ce retour d’expérience.
Si vous n’êtes dans aucun des cas précédents, Il ne reste plus qu’à construire vous-même vos hypothèses. Basez vous sur quelques concepts faciles à identifier : Combien de processus ? Sont-ils le cœur de métier de l’entreprise ou pas ? Quelle est l’application au cœur de la transformation et quelle est l’équipe qui en a la charge ? Ces hypothèses seront évidemment fausses mais cela permet de poser une première brique.
Savoir comment valider ses propositions
Pour finir cette phase, il reste à définir comment faire valider vos travaux. Pour cela rien de plus facile : Si un processus de validation existe déjà, demandez-le ainsi que le temps moyen de validation. S’il vous semble imparfait, n’essayer pas de le faire modifier. Vous allez perdre du temps qui serait utile à votre projet. Si aucun processus n’existe, faites valider vos propositions par le sponsor et les parties prenantes, comme cela est préconisé par TOGAF.
Tout le monde sur la ligne de départ
A la fin de cette phase, vous aurez la structure de votre équipe d’architecture, qui valide les étapes et les résultats de l’étude, prête à démarrer votre projet.
La phase a : la vision de l’architecture
Les choses sérieuses commencent
La phase de vision de l’architecture permet de définir les impacts du projet sur le système d’information ainsi que les chantiers d’architecture à mettre en place. Elle est précédée de la phase préliminaire ou de la roue ADM précédente (en plus clair, la précédente phase du projet).
D’après TOGAF, a liste des étapes pour construire la vision d’architecture sont : identifier les parties prenantes et leurs exigences, les enjeux métiers (les bénéfices attendus par le métier), confirmer les objectifs, évaluer le niveau de motivation et de préparation des métiers, ainsi que les capacités des dits métiers, confirmer les principes d’architecture, définir les KPI pour mesurer les bénéfices d’architecture, les risques… Bien sûr, tout cela est logique dans un monde sans contrainte, mais cela arrive peu, pour ne pas dire jamais :
Comment évaluer les capacités du métier à répondre aux attentes de l’architecture, son niveau de motivation ou de préparation ? L’architecture est habituellement intégrée à la DSI et à quoi bon faire cela ? Comment présenter au métier, qui finance la DSI et l’étude, qu’il n’est pas au niveau et quels seraient les critères pour dire cela ?
Comment estimer la capacité du métier ? A partir des chaines de valeur ? Le contrôle de gestion de l’entreprise est le seul à avoir les informations nécessaires, mais les informations sont rarement partagées.
Et pour les KPI, comment faire une évaluation des gains alors que les problèmes à résoudre sont noyés dans le reste des activités des utilisateurs ?
Se concentrer sur l’essentiel
En fait, tout cela s’ajuste au fur et à mesure de l’avancée de l’étude, car cela permet au métier de reprendre le contrôle sur ses outils et ses processus. Cependant, on peut rapidement réaliser quelques étapes de cette phase :
Construire une carte des parties prenantes permet de faire une estimation rapide des influences de chacun.
Faire une macro-cartographie pour définir les grands ensembles du projet ainsi que quelques scenarios métiers pour pouvoir « jouer » des cas pratiques lors de la conception de la solution.
Si la mise en place des KPI n’est pas possible, on peut au moins demander au métier de faire une pondération « à dire d’expert » de ses attendus. En fait, il suffit souvent de demander les différents « pain points » à résoudre ainsi que les nouveaux besoins auxquels répondre, et de demander un ordre de priorité. A la fin du projet, vous pourrez demander au métier si la solution apportée lui convient.
L’état des lieux est terminé
Au final, cela permet à chacun de faire une évaluation plus fine de l’étude à réaliser et de compléter la note de cadrage. Comme dans toutes les épreuves, tous ces éléments vont s’affiner avec le temps et il est bon de garder le document pour le confronter au réel.
La suite
La grande force de la roue TOGAF est qu’elle traite toutes les problématiques liées à l’architecture et apporte une réponse, ou au moins un Framework pour répondre, à ces problématiques. Et comme tout framework, il est important de l’appliquer à un contexte. Suivre TOGAF c’est bien, savoir le faire sans oublier pourquoi, c’est mieux. Il n’est pas utile de tout faire exactement comme cela est préconisé – tous les acteurs du projet n’en saisissent pas forcement les bénéfices – mais il est tout à fait possible d’en extraire l’essentiel. Apres avoir traité les deux premières phases, nous continuerons, dans les prochains articles, à parcourir les autres phases la roue ADM et explorer ensemble TOGAF IN REAL LIFE.
Des bâtiments aux systèmes d’information en passant par la santé, l’intelligence artificielle joue un rôle croissant dans la transformation de l’entreprise en ouvrant de nouvelles potentialités, mais aussi de nouvelles innovations. D’autre part, l’architecture d’entreprise (AE), historiquement au cœur des transformations de l’entreprise, est particulièrement concernée par les opportunités offertes par ces nouvelles capacités, notamment pour améliorer le fonctionnement interne de l’AE. L’hybridation entre l’intelligence humaine et l’intelligence artificielle (IA) sera la clé de voûte dans la mise en œuvre des capacités de l’IA, notamment au service de la transformation de l’AE et plus globalement au service de l’entreprise.
Cette hybridation se traduit notamment par…
Cartographie et contrôles de conformité
Avec les algorithmes de Machine Learning (ML), les architectes d’entreprise ont à leur disposition une nouvelle approche de cartographie des systèmes d’information au sein de l’entreprise. En effet, ces nouvelles capacités permettent à l’architecture d’entreprise d’automatiser (via un processus d’audit automatique) la cartographie des systèmes d’information en reliant les acteurs, l’organisation, les processus métier et les données. Cette cartographie automatique a le double avantage de permettre une accélération de l’ouverture du SI via une APIsation.
Dans le même sillage, les nouvelles capacités offertes par les algorithmes de l’IA permettront d’accélérer et de simplifier l’analyse des données dans le cadre règlementaire (RGPD par exemple) mais aussi pour les dictionnaires des données. Étant donné les nouvelles méthodes de travail (plus de collaboration, méthodes agiles, …), l’architecture d’entreprise aura à évoluer vers un modèle lui permettant de s’adapter rapidement aux changements continus. Elle aura aussi pour effet de libérer les architectes des tâches chronophages liées à la création et mise à jour des référentiels.
Proposer des modèles d’architecture en utilisant l’IA
Un des fondements des algorithmes de ML est de permettre de générer des solutions imitant la distribution statistique des données qui lui sont soumises pendant la phase d’apprentissage et de se soustraire des modèles statiques. Cette capacité permettra à l’AE de pouvoir présenter plus rapidement et plus efficacement des modèles d’architecture proche des besoins et des contraintes propres à l’entreprise. Certaines entreprises sont déjà dans le secteur.
Proposer des modèles de mise en oeuvre
Reconnaissances biométriques, recommandations personnalisées, Chatbots, autant de modèles de ML largement utilisés dans différentes entreprises dans le monde, dans ce contexte hautement disruptif. L’utilisation de ces fonctionnalités a un impact majeur sur les processus standards des entreprises allant du métier à la technique. A ce titre, l’architecture d’entreprise, garante de l’harmonisation des processus et des SI, se doit de prendre en compte les impacts de l’intégration de ces technologies. De par son rôle, l’architecture d’entreprise anticipe la mise en place de ces technologies via des recommandations stratégiques.
L’architecture d’entreprise soutient les initiatives d’IA
Les initiatives IA ne sont pas simplement un ensemble d’initiatives complexes et coûteuses dans un environnement complexe, ce sont aussi des accélérateurs de la transformation des processus métiers. Du fait de sa fonction première, l’architecture d’entreprise est une alliée des initiatives IA sur ce domaine. L’architecture d’entreprise apporte la structure et la transparence nécessaires à la planification et à l’exécution de changements complexes dans un domaine aussi vaste et diversifié qu’une entreprise moderne. Une méthode pouvant servir à la mise en place d’une IA :
Identifier les éléments/capacités qui favorisent la satisfaction du client
Evaluer l’impact de l’introduction d’une solution d’IA
Planifier et gérer la mise en œuvre
Analyser le REX
Optimiser les prochaines itérations.
Conclusion
L’architecture d’entreprise a un rôle central à jouer dans l’expérimentation de futurs scénarios impliquant les algorithmes de ML. La connaissance transversale des flux de valeur, des processus, des technologies et des données de l’entreprise est un puissant vecteur de transformation et une opportunité pour toutes les entreprises. Adopter l’IA, c’est permettre à son entreprise de rester dans la course à l’innovation et pour délivrer un maximum de valeur.
Je n’ai rien contre vous, mais ça va prendre trop de temps de référencer et de compléter nos applis… Vous avez une ligne d’imputation ?
Chef de projet
C’est surtout un énième référentiel qui ne sera pas tenu à jour : beaucoup d’efforts d’initialisation au départ et pas de récompense à l’arrivée !
Directeur d’un domaine applicatif
Je monterai à bord seulement si on me prouve que ça marche et que les autres ont déjà complété leur part.
Indiana Jones
Damn…
En entendant ces retours, Indiana réalise à quel point le déploiement d’un référentiel d’architecture pour son entreprise d’archéologie ne va pas être chose facile… Surtout auprès des parties prenantes qui devront se charger de compléter les informations sur leurs applications.
L’arrivée d’un référentiel des applications, quel que soit l’usage qui en est fait (Application Portfolio Management, gestion de l’obsolescence, transformation du SI…), est majoritairement vu par les équipes opérationnelles comme une contrainte, en termes de temps, et donc de budget.
Armé de son chapeau fedora d’explorateur intrépide, Indiana se lance sur les eaux sinueuses de la mise en place d’un référentiel d’architecture et de la conduite du changement auprès de ses équipes.
Nous retracerons ses péripéties à travers ce retour d’expérience : que pouvons-nous faire concrètement pour lever les freins et faciliter ainsi le changement et l’acceptation de l’outil ?
Enfilez votre meilleur pantalon cargo et chaussez des boots en cuir confortables (nota bene : vous pouvez exclure le fouet de votre attirail) et… Action !
Pour bien se dérouler, l’expédition doit être bien organisée
Première étape, Indiana part à la recherche de recrues sur lesquelles il pourra compter pour mener à bien sa quête.
La mise en place d’un référentiel d’architecture ne s’effectue pas sans un fort sponsoring de la part de la direction. Ces sponsors seront les plus pertinents pour répondre au « pourquoi » (Simon SINEK, « How great leaders inspire action »), ce fameux adverbe qui, à défaut de nous laisser coi, doit au contraire éclairer les lanternes et permettre aux intéressés comme aux sceptiques de rallier la cause. Ainsi, le directeur du Système d’Information, de l’architecture, des études, voire de la sécurité et des différents pôles applicatifs, semblent tous désignés pour accomplir ce rôle de « parrain » (sorte d’Al Pacino corporate) du projet.
Si nos sponsors semblent désignés d’office, nous aurons besoin d’aventuriers au sein de notre organisation projet, de personnes qui promeuvent la démarche et qui veulent utiliser l’outil. Ils seront de préférence opérationnels ou auront une bonne connaissance des équipes, de leurs besoins et contraintes. Ces aventuriers devront également être capables d’aller vaincre les démons de la réticence et de prendre du recul sur la situation. Ce seront des ambassadeurs du projet : des responsables d’applications, des responsables de pôles, des PMO ou autres fonctions transverses, ou même des personnes qui connaissent peut-être l’entreprise et son SI depuis plus de 20 ans… En bref, ces opérationnels seront nos yeux et nos oreilles pour les remontées terrain, afin de permettre à l’équipe projet référentiel d’architecture de répondre aux attendus et de lever le plus tôt possible les principaux freins au changement.
Armé de cette équipe solide, Indiana est prêt à débuter son expédition auprès des responsables d’applications !
Équipement approprié + capacité d’adaptation = le kit du bon aventurier
Qui dit déploiement d’un nouvel outil dit nécessairement conduite du changement auprès des populations concernées. En l’occurrence, si nous arrivons avec un outil qui est vu comme une contrainte, il sera important d’adapter nos leviers à notre public. (Mettons momentanément de côté la méthode Indiana : le fouet n’EST PAS une solution adaptée à la conduite du changement. Est-ce bien clair ?)
En revanche, il conviendra de s’équiper d’un attirail adéquat en fonction de la situation. Qui sont mes utilisateurs ? Quels sont les canaux de communication les plus adaptés ? Qu’est-ce qui fonctionne bien dans l’entreprise ? Sur quelles ressources puis-je m’appuyer ? sont autant de questions qui aideront à constituer l’équipement de l’aventurier.
Prenons l’exemple d’un kit qui a fonctionné :
des kick-off courts auprès de chaque équipe pour présenter le « pourquoi » du projet, recueillir les besoins et premiers retours et convaincre à l’aide de cas d’usage adaptés en fonction de leurs objectifs ;
des formations sur-mesure et interactives (cet accessoire indispensable est à calibrer en fonction de l’ergonomie et de la facilité d’utilisation de l’outil choisi) ;
du coaching à volonté à l’aide d’un point de contact et de support bien identifié et accessible par les utilisateurs (de ce fait, cela ne peut pas être un directeur, mais quelqu’un qui sera disponible pour les équipes) ;
une documentation abordable, pas trop longue, pour ne pas décourager les élèves, et tenue à jour pour assurer la cohérence du discours ;
des vidéos tutos pas-à-pas, avec une communication régulière, parfois légère ou informelle (via Workplace, SharePoint, mail, voire même papyrus antique).
L’une des composantes principales de la conduite du changement est la communication. L’enjeu sera d’apporter, avec pédagogie, toute la connaissance nécessaire à nos populations concernées, afin de les rendre autonomes et de les convaincre de l’utilité de la démarche. Pour cela, des formations adaptées, couplées à une communication régulière et orientée en fonction du public, seront nécessaires.
La réussite du succès : itérer
Inutile d’arriver avec un schéma de déploiement trop préconçu : avoir des principes, oui, mais rigides, non ! Ce serait le meilleur moyen pour que les utilisateurs n’adhèrent pas. Il nous faudra faire preuve de souplesse et d’agilité pour éviter les écueils et nous emparer des idoles aztèques conservées dans les temples maudits sans se faire transpercer par les flèches piégées.
Plus encore, il faudra également donner la parole à ces parties prenantes de tout horizon et les inclure dans les décisions prises autour du référentiel (nomenclatures, règles de modélisation d’une application, ses instances, ses interfaces, ses composants techniques et les informations complémentaires utiles à renseigner).
Pour faciliter l’acceptation, nous prendrons en compte les points de vue et adapterons l’expédition en fonction des imprévus, qui ne manqueront pas d’arriver (cf. Indy dans « Les Aventuriers de l’arche perdue »), mais qui permettront à coup sûr d’enrichir la portée du référentiel !
Après avoir recueilli les doléances, il sera important de trouver des solutions, de les documenter et de les généraliser auprès de tous les utilisateurs. Les équipes se sentiront plus ainsi engagées et responsabilisées, d’autant plus qu’on aura itéré avec elles sur leurs besoins.
Bien entendu, il faut savoir dire non à certaines demandes, afin de ne pas se retrouver avec une liste au Père Noël qui diluerait les objectifs premiers du référentiel.
Conclusion
Intérieur – une deuxième salle de réunion dans une Université
Responsable d’application
Ça m’a pris du temps, mais j’ai mieux compris à quoi le référentiel allait me servir : partager la carte d’identité de mon application, visualiser ses flux d’échange, anticiper l’évolution de son état de santé technique, pour faciliter les études d’impacts.
Chef de projet
Je peux dorénavant avertir les autres responsables d’application de l’arrivée d’une nouvelle application dans la cartographie et afficher les impacts sur le système d’information. Associé au travail des architectes sur la vision future de l’entreprise, le référentiel prend une vraie valeur.
Directeur d’un domaine applicatif
Je dispose à présent d’une vue exhaustive de mon périmètre et d’informations de qualité sur les applications. Je me porte garant pour assurer la maintenance dans le temps de cette cartographie afin d’en faire bénéficier toutes les parties prenantes de la direction informatique.
Indiana Jones
Is this the real life? Is this just fantasy?
The end
Comme nous le constatons en cette fin de scénario, Indiana a pu lever les réticences majeures à l’aide de sponsors investis, de cas d’usage ciblés et d’une conduite du changement adaptée aux besoins des équipes opérationnelles. L’apport d’un tiers dans la démarche, neutre et indépendant, facilite cette conduite du changement.
Un exemple de la réussite de cette phase de déploiement est d’avoir fait entrer le référentiel d’architecture en tant que « réflexe » dans les mœurs de la direction du système d’information : « As-tu vérifié ce que dit le référentiel à ce sujet ? As-tu capitalisé ton étude SI dans le référentiel ? » Une fois que c’est fait, nous pouvons entrer dans une phase de mise à jour récurrente des informations, à l’aide d’un processus adapté et de KPI pour évaluer la qualité globale du référentiel dans le temps.
De votre côté, comment vous êtes-vous frayés un chemin à travers la végétation luxuriante de l’inventaire applicatif ? Comment avez-vous organisé l’expédition et quel kit du bon aventurier vous a le plus aidé ?
Les données sont partout et nulle part et sont bien souvent intangibles. Notre quotidien devient petit à petit un flot permanent de données générées, collectées et traitées. Elles sont cependant un moyen pour atteindre des objectifs et non une finalité.
Les entreprises doivent donc avoir la capacité à naviguer vers leurs objectifs business, sur une rivière qui deviendra vite un océan de données. L’important maintenant est donc de savoir si elles ont les moyens de braver les éléments.
Les ‘éléments’ auxquels il faut faire face
1. L’obligation de la donnée
La donnée est omniprésente. Données personnelles, confidentielles, de navigation, de consentement, data science, data platform, data visualization, chief data officer font partie d’une longue liste de termes qui font le quotidien des experts mais aussi du client consommateur. Les données sont aujourd’hui un asset reconnu et à forte valeur ajoutée (1). Elles sont aussi un asset pérenne du fait des usages numériques et des opportunités business qui se réinventent tous les jours.
Premier constat donc, l’obligation de la donnée. Elle est un passage obligatoire pour mieux connaître les consommateurs, répondre à leurs nouveaux besoins et être innovant.
2. La surabondance
La digitalisation croissante dans tous les secteurs, les réseaux sociaux, l’IOT, la mobilité, l’utilisation croissante des smartphones sont des exemples qui provoquent une forte augmentation de la génération de données. Les sources se multiplient, les besoins en stockage également (2). Par conséquent, nous sommes vite confrontés à une problématique grandissante : comment maîtriser toutes ces données ? Comment faire face à ce flot surabondant ? Et comment en tirer des informations utiles sans être noyé ?
Les prévisions (3) tablent en effet sur une multiplication par trois ou quatre du volume annuel de données créées tous les cinq ans. Les chiffres sont implacables.
Le deuxième constat est donc la surabondance. Un océan numérique déferle et chaque entreprise, peu importe sa taille, devra y faire face.
3. L’éphémère
Le numérique génère de nouvelles habitudes chez le consommateur : l’instantanéité, le choix abondant et la rapidité de changement. (offre, prix, produit, etc.). Ces habitudes se traduisent par des besoins de plus en plus éphémères. Elles raccourcissent les durées de vie des produits et des services, ou imposent de continuellement se renouveler pour se différencier. Les opportunités marchés sont nombreuses et il faut aller vite pour les saisir le premier. Être le premier est ainsi souvent synonyme de leadership sur le marché. (exemple : Tesla, Airbnb, Uber) L’éphémérité des besoins impose donc d’accélérer en permanence tous les processus internes, métier et SI.
Le troisième constat est donc l’éphémère (besoin, produits, services) qui devient de plus en plus présent. Il est ainsi nécessaire d’être de plus en plus réactif pour s’adapter et évoluer rapidement face à ces changements permanents.
4. L’innovation permanente
Le numérique engendre aussi une accélération de l’innovation. Il rend accessible au plus grand nombre la possibilité de réinventer son quotidien. Cette accélération permanente rend plus rapidement obsolète l’invention d’hier.
Qui aurait en effet pensé que nous allions pouvoir partager nos appartements il y a 10 ans ? Qui aurait pensé que payer sa place de parking se ferait sur son téléphone ? Et surtout qui aurait pensé qu’un téléphone deviendrait l’accès privilégié à toutes nos innovations de demain ?
Le dernier constat est donc l’innovation permanente. Comme pour l’instantanéité, cela génère un besoin de flexibilité et de rapidité fort pour pouvoir suivre le rythme d’innovations imposé par le monde digital.
5. La capillarité de la donnée
Quel est le point commun aux constats précédents ? La donnée. La donnée est présente dans tous les processus et tous les usages en contact ou non avec le client. Ainsi la donnée, par nature, telle la propagation d’un liquide sur une surface, oblige à s’interroger sur les briques du SI qui l’utilisent pendant ces processus et ces usages : c’est la capillarité des données.
Ensuite avec de l’expertise et de la méthodologie, tout s’enchaîne! La définition des besoins et la conception fonctionnelle au travers du prisme “donnée” dans une vision d’ensemble, feront que naturellement par capillarité, vous adresserez le cycle de vie de la donnée, sa valeur et l’architecture de votre SI pour répondre à ces besoins.
Survivre grâce au SI Data Centric
Dans ce contexte de surabondance, d’éphémérité et d’innovation permanente, comment alors maîtriser son patrimoine de données ? Il s’agit de raisonner données et non plus SI. L’objectif devient la gestion de la donnée. Se poser la question de comment gérer des données permet en effet d’adresser ces changements détaillés précédemment et par capillarité, le SI. Un SI centré sur les données est donc le moyen d’adresser ces vagues de changements et de résister aux éléments. En effet, gérer les données impliquent des notions d’unicité, de qualité, de volumétrie, de performance, de confidentialité, d’échanges, de réglementations. L’amélioration de la conception du SI pour faire face à ce nouveau contexte est donc immédiate.
Les fonctions à adresser par le SI, qu’elles soient métiers ou techniques, et la gouvernance nécessaire à la gestion des données vont soulever des questions qui permettront d’adresser ce nouveau contexte d’éphémérité et de surabondance. L’innovation permanente oblige, elle, à industrialiser la livraison des nouvelles fonctionnalités de ce SI centré sur les données. Le SI se construit ainsi autour de la donnée : flexible, modulaire, et industrialisé. Par exemple des référentiels (produits, clients, fournisseurs, etc.) sont mis en place, garantissant la qualité et la mise à jour des données utilisées par toute l’entreprise. Un autre exemple est que les données collectées sont conservées à un seul endroit brutes puis standardisées pour identifier les relations entre elles. Ou encore des outils permettant d’avoir la définition, le cycle de vie et le propriétaire de chaque donnée sont déployés. Le SI devient ainsi un SI centré sur les données. (“Data Centric”).
Il s’adaptera donc naturellement aux futurs changements du marché grâce à tout ce qu’implique la donnée. Il devient un socle solide adressant différents usages sans forcément avoir besoin de transformation en profondeur, longue et coûteuse. Pourquoi ? Car encore une fois, gérer une donnée et faire en sorte qu’elle soit collectée, de qualité, sous contrôle, disponible partout en temps réel et en unitaire ou en masse, intégrées aux processus cœur de métier de l’entreprise, est universel et adaptable à tout usage.
Intrinsèquement la donnée est agnostique de l’usage qu’elle sert. C’est le SI Data Centric qui garantit cette fonction, et assure la survie de l’entreprise dans la jungle digitale.
Conclusion
S’impliquer fortement dans l’évolution du SI est donc nécessaire. L’objectif est de commencer petit mais de commencer Data Centric. Usage après usage, votre SI se construit toujours plus résilient aux différentes vagues de cet océan de données. Un autre bénéfice, et non des moindres : l’innovation des équipes n’étant plus ralentie par le SI, elle s’en trouve ainsi décuplée.
Construire un SI Data Centric, c’est la garantie d’avoir un SI modulaire et adaptable qui répond aux enjeux d’aujourd’hui et de demain. Il est ainsi une base solide sur laquelle construire la pérennité de l’entreprise dans ce nouveau contexte.