Edge computing vs cloud computing, deux modèles complémentaires ?
Edge computing versus cloud computing, deux modèles complémentaires?
2 septembre 2020
– 6 min de lecture
Architecture
Mohammed Bouchta
Consultant Senior Architecture
Pendant la dernière décennie, nous avons assisté à la montée en puissance du Cloud Computing dans les nouvelles conceptions d’architecture SI.
Sa flexibilité faisant abstraction de la complexité des infrastructures techniques sous-jacentes (IaaS, PaaS) et son mode de facturation à la consommation (Pay as you go) étaient des atouts suffisants pour convaincre les premiers clients. Mais c’est surtout le développement d’un nombre important de nouveaux services innovants avec une grande valeur ajoutée qui a mené la plupart des entreprises à adopter le Cloud. C’est ainsi par exemple que la grande majorité des entreprises ont pu expérimenter le Big Data, le Machine Learning et l’IA sans avoir à débourser des sommes astronomiques dans le matériel approprié en interne.
Le Cloud a facilité également le développement du secteur de l’IoT, ces objets connectés dotés de capteurs qui envoient leurs données régulièrement à un système central pour les analyser. En effet, le Cloud a fourni une panoplie de services pour absorber toutes les données collectées et une puissance de calcul importante pour les traiter et les analyser.
Cependant, le besoin de prendre des décisions en temps réel sans être tributaire de la latence du Cloud et de la connectivité dans certains cas, donne du fil à retordre aux experts lorsque les sources de données commencent à devenir extrêmement nombreuses.
Ainsi, d’autres besoins beaucoup plus critiques ont émergé en lien avec l’utilisation des objets connectés qui nécessitent des performances importantes en temps réel, et ceci même en mode déconnecté. Nous pouvons le constater par exemple dans les plateformes pétrolières en mer, les chaînes logistiques ou les véhicules connectés qui nécessitent une prise de décision locale en temps réel alors que le partage des données sur le Cloud permettra de faire des analyses plus globales combinant les données reçues, mais sans exigence forte sur le temps de traitement.
Ce sont ces contraintes et d’autres encore comme la sécurité des transmissions et la gestion de l’autonomie, qui ont donné naissance à un nouveau paradigme d’architecture, celui du Edge Computing.
Gartner estime que d’ici 2025, 75% des données seront traitées en dehors du centre de données traditionnel ou du Cloud.¹
Que signifie le edge computing exactement ?
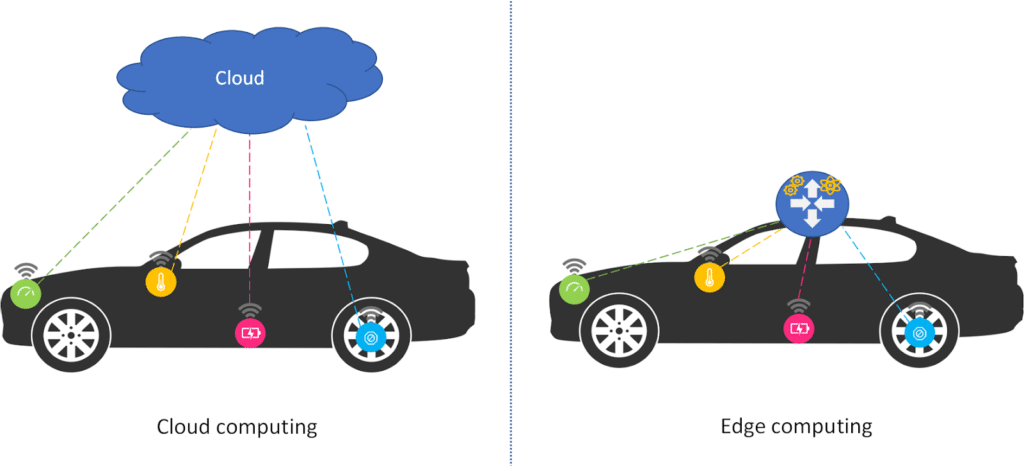
À l’opposé du Cloud Computing qui tend à déplacer tous les traitements dans le Cloud, le Edge Computing vise à rapprocher la puissance de calcul, le stockage et les applications de l’endroit où la donnée a été créée. Cela permet ainsi de pallier les problèmes de connectivité, de latence et les risques liés à la sécurité.
Avec le Edge Computing, l’analyse des données peut se faire directement sur le périphérique qui les a générés, comme par exemple les smartphones ou les objets connectés qui ont des ressources suffisantes. Si l’objet connecté est limité en ressources de calcul, de stockage, de connectivité ou d’énergie, comme dans la majorité des cas, alors c’est une passerelle IoT équipée de ces capacités, qui prend en charge la collecte, la transformation, l’analyse des données et la prise de décision / action.
Cette décentralisation du stockage et du traitement des données permet de répondre aux exigences de la prise de décision en temps réel.
Prenons l’exemple de la voiture autonome dans une situation de danger imminent, nous devons envoyer la globalité des données des capteurs sur un Cloud pour les analyser et attendre que le Cloud renvoie à la voiture les directives à suivre pour éviter l’accident. Même avec toute la puissance de calcul du Cloud, le temps de latence imposé par le réseau peut mener à la catastrophe. Alors qu’avec une analyse des données et une prise de décision locale, en temps réel, la voiture aura une chance d’éviter l’accident.
Ou l’exemple d’une machine dans une chaîne de production qui doit adapter sa vitesse d’action par rapport à plusieurs facteurs environnants qui proviennent des appareils de la chaîne. L’utilisation du Edge Computing au niveau de la Gateway IoT (passerelle) permet de récupérer les données nécessaires des périphériques locaux pour analyser et ajuster la vitesse de la machine en conséquence sans avoir à passer par le Cloud.
L’autre atout majeur du Edge Computing est sa résilience. Le système local peut continuer à fonctionner même s’il y a une défaillance majeure dans le Cloud, dans le réseau ou sur d’autre branche du système.
Toutefois, il ne faut pas croire qu’il est simple de mettre en place ce type d’architecture, bien au contraire. En effet, nous revenons à une architecture distribuée qui nécessite des appareils avec des ressources plus importantes (donc plus chères) et souvent avec des technologies hétérogènes qui doivent s’interfacer ensemble pour communiquer, ce qui complexifie l’administration et la maintenance. Aussi, en stockant les données en local, le problème de sécurité des données est déplacé vers les périphériques qui les stockent. Que ce soient les objets connectés ou la Gateway IoT, ces appareils peuvent être accessibles physiquement et sont donc plus vulnérables à un piratage. Ces périphériques devront se doter d’une politique de sécurité accrue pour s’en prémunir.
Ce changement d’approche a ouvert des opportunités pour les fournisseurs de télécommunications qui développent de nouveaux services liés à la 5G, à l’IoT et à d’autres technologies. Il a poussé les différents acteurs du marché à innover pour proposer des offres plus adaptées au Edge Computing. C’est ainsi que les leaders en matériel informatique comme Cisco, Dell EMC et HP par exemple ont tous mis sur le marché des produits dédiés à ce type d’architecture. Les géants du Cloud ont aussi réagi en force à cette tendance avec une palette de services qui peuvent s’étendre jusqu’aux périphériques connectés pour agir localement sur les données.
D’autre part, les avancées technologiques en matière de microcontrôleurs toujours plus miniaturisés, puissants et avec une consommation réduite de l’énergie, ont permis de faire de l’IA embarquée dans les objets connectés afin d’être plus rapide et efficace dans la prise de décision.
Vers la fin du cloud computing ?
Absolument pas ! Le Cloud a encore de belles années devant lui. En réalité, les deux solutions sont complémentaires et c’est le type de traitement nécessaire, le temps de réponse attendu et les exigences de sécurité qui vont déterminer ce qui doit être traité au niveau du Edge et ce qui doit être envoyé vers le Cloud.
Si nous reprenons le cas de voiture connectée, le Cloud va permettre d’agréger les données envoyées par toutes les voitures afin de les traiter, de les comparer et de faire des analyses approfondies pour optimiser les algorithmes de conduite et le modèle IA à déployer comme nouvelle version du programme embarqué dans les voitures connectées.
En combinant le potentiel de collecte et de l’analyse en temps réel des données du Edge Computing avec la capacité de stockage et la puissance de traitement du Cloud, les objets IoT peuvent être exploités de façon rapide et efficace sans sacrifier les précieuses données analytiques qui pourraient aider à améliorer les services et à stimuler l’innovation.
En conclusion
Il est peu probable que l’avenir de l’infrastructure réseau se situe uniquement dans le Edge ou dans le Cloud, mais plutôt quelque part entre les deux. Il est possible de tirer la meilleure partie de leurs avantages respectifs. Les avantages du Cloud Computing sont évidents, mais pour certaines applications, il est essentiel de rapprocher les données gourmandes en bande passante et les applications sensibles à la latence de l’utilisateur final et de déplacer les processus du Cloud vers le Edge. Cependant, l’adoption généralisée du Edge Computing prendra du temps, car le processus de mise en œuvre d’une telle architecture nécessite une expertise technique approfondie.
En fin de compte, vous devez toujours commencer par bien cibler les usages, les exigences et les contraintes de votre système pour choisir la bonne architecture.
Les autres articles qui peuvent vous intéresser
Dsp2 et openbanking, conclusion de la table ronde api
Dsp2 et openbanking, conclusion de la table ronde api
Petite synthèse à chaud des débats de la table ronde organisée par le GT RED (Groupe de Travail Règles, Evolutions & Déploiements) du France Payments Forum. Le thème « Bilan des API DSP2 » était d’actualité quelques semaines après le 14 septembre.
Petite synthèse à chaud des débats de la table ronde organisée par le GT RED (Groupe de Travail Règles, Evolutions & Déploiements) du France Payments Forum. Le thème « Bilan des API DSP2 » était d’actualité quelques semaines après le 14 septembre.
2 heures d’échanges fournis et directs (la règle avait été partagée : « on est là pour se dire les choses… ») entre :
2 banques : Alain BENEDETTI (BNP Paribas) et Dominique BEAUCHAMP (NATIXIS PAYMENT SOLUTIONS) et
2 TPP : Romain BIGNON (BUDGET INSIGHT) et Mathieu PERE (TINK),
animées par Ludovic VATHELOT (TREEZOR).
Emmanuel NOBLANC (SAB) avait démarré avec une KeyNote pour poser le contexte.
J’avais la charge de restituer une synthèse pour conclure…
Que retenir à chaud, à la fin des débats ?
A défaut d’une analyse posée, j’ai surtout retenu la différence de ton entre les échanges sur :
la DSP2 et les RTS, vécus par tous comme une contrainte, avec des choix pris dans un contexte et étendus abusivement (par exemple entre Agrégation et Initialisation) et générant des positions défensives
l’OpenBanking, avec l’illustration de cas d’usage et d’initiatives, avec un enthousiasme communicatif à l’ensemble de l’auditoire.
Pour commencer, il était utile de rappeler que TPP et ASPSP ont plus en commun que la DSP2 ne le laisse voir : les ASPSP sont aussi des TPP ! Chacun a d’ailleurs noté le caractère schizophrénique de cette double posture des ASPSP :
réticence du fait que les API réglementaires sont imposées sans rémunération
vs. initiatives des ASPSP dans l’initiation de paiement (pour illustration, les cas d’usage de Natixis Payments Solutions avec Foncia et System U).
Ceci dit, les acteurs ont largement souligné les difficultés rencontrées dans la mise en œuvre des RTS, avec un constat unanime de progrès significatifs depuis le 14 septembre, mais encore aucune utilisation opérationnelle significative des API déployées. Les obstacles sont multiples :
Problèmes techniques de stabilité, bien sûr
Complexité générée par l’hétérogénéité
Implémentations techniques différentes (malgré les travaux de standardisation menés autour de STET ou de Berlin Group),
Ecarts fonctionnels (divergences de vue sur le périmètre de la règlementation, sur les données requises, mais au-delà sur ce qui apparaît même comme des incohérences de la DSP2 : comment concilier l’esprit de la Directive d’étendre l’offre de service, notamment l’initiation de paiement marchands et la lecture stricte de présenter via API l’équivalent de son offre de Banque en Ligne),
Parcours clients variant de 2 à 7 étapes utilisateurs (avec la problématique de SCA), rassemblés dans une offre d’agrégation soulignant les différences de fluidité…
Exigence de continuité du service déjà déployé par les TPP, qui ne peuvent basculer sur les API qu’une fois atteint un niveau de fiabilité équivalent aux alternatives actuelles de Direct Access (Scraping, Reverse Engineering).
Et puis, l’illustration de différents parcours utilisateurs et la projection sur les cas d’usage nous ont projeté dans une autre dynamique d’échange, où l’on parlait de :
Expérience client,
Services à valeur ajoutée,
Valorisation de la donnée,
Différenciation et avantage concurrentiel,
Initiatives bilatérales entre banque et TPP,
Modèle économique gagnant-gagnant (la clé du sujet !)…
Le miroir était franchi
Oubliées les postures défensives et la vision strictement réglementaire
Bienvenue dans le monde concurrentiel, avec « les yeux qui brillent » à l’évocation du potentiel de l’initialisation de paiement (combiné à l’Instant Payment) pour offrir les nouveaux services à valeur ajoutée attendus par le marché (et au fondement de la Directive elle-même…).
Au final, c’est bien le consommateur qui validera les meilleures offres !
Il faudra donc encore du courage et de la ténacité pour atteindre la conformité à la DSP2, mais la perspective nous projette déjà plus loin, avec un nouvel élan !
But still, it’s a long way… Un chemin que notre Groupe de Travail au France Payments Forum poursuivra et auquel vous êtes invités à contribuer si vous le souhaitez.
A très bientôt pour un autre événement sur le même thème !
Si la mise en place de la DSP2 semble prendre l’apparence d’une querelle entre anciens et modernes – les banques contre les fintech – la réalité s’avère plus complexe…
Ouvrir à des tiers l’accès aux données et à l’initiation de paiement pour stimuler la concurrence tout en consolidant la sécurité des paiements. C’est l’ambition de la DSP2 (directive européenne sur les services de paiement) entrée en vigueur en janvier 2018 et dont la mise en œuvre est jalonnée par de grandes étapes définies dans les normes techniques et réglementaires (aussi appelées RTS), notamment sur les interfaces d’accès (API) et l’authentification forte.
Une première échéance est tombée le 14 mars 2019, date à laquelle les banques devaient avoir déployé un portail d’API afin de mettre à disposition la documentation et un bac à sable permettant aux TPP (Tiers Prestataires de Paiement) de les éprouver. Une autre suivra le 14 septembre 2019 avec l’ouverture officielle des APIs de production. Dans le contexte de tension entre fournisseurs d’API (teneurs de comptes) et consommateurs (nouveaux acteurs), cette échéance a relancé le débat sur la capacité des banques à respecter le calendrier…
La DSP2, une transformation lourde à marche forcée
Dans ces débats, un même coupable est souvent pointé du doigt : les banques. Qui complexifieraient la sécurité ou encore publieraient des API bien trop partielles pour être exploitables. La réalité est un peu plus… complexe. Et les enjeux ne peuvent se résumer à une querelle entre les anciens (les banques installées) et les modernes (les acteurs de la fintech). Rappelons que la DSP2 est un sujet plutôt nouveau, qui concerne « juste » la sécurité des paiements et la protection des données du client. Et comme pour toute transformation lourde, les acteurs impliqués découvrent en marchant les clarifications qui doivent encore être apportées.
Oui, les différents textes, de la directive aux RTS, ont bien posé des fondamentaux. Trois catégories ont été définies pour les fameux TPP (Tiers Prestataires de Paiement), des agrégateurs de comptes aux initiateurs de paiement en passant par les émetteurs de moyens de paiement.
Des obligations pour les tpp et les banques
Pour entrer dans le jeu, ces TPP doivent remplir des conditions : obtenir un agrément auprès d’une autorité nationale, un certificat (dit « eIDAS ») auprès d’une autre autorité ou encore renoncer (quand des API sont disponibles) au webscraping. Pour rappel, cette technique consiste à collecter les données à partir des sites de banque en ligne, en utilisant les identifiants et mots de passe des clients. Les banques pour leur part doivent respecter le calendrier de déploiement et mettre à disposition les API de production pour les trois catégories de TPP le 14 septembre prochain après avoir mis en ligne, en mars dernier, bac à sable (sandbox) et documentation.
Si les règles du jeu et le calendrier sont là, que manque-t-il ? Nous pourrions résumer en disant « des délais plus cohérents et des modalités plus précises ». À défaut, pour les TPP comme pour les banques, la route manque de lisibilité.
Quelques exemples pour comprendre :
Globalement, le planning de l’autorité de régulation (ACPR, Autorité de Contrôle Prudentiel et de Résolution) a été publié fin décembre pour des actions à lancer mi-janvier et des mises en production mi-avril. Un planning plus que tendu.
Sans surprise, dans ces délais les progiciels bancaires ne sont pas prêts pour intégrer les spécificités de la DSP2.
Selon les prestataires impliqués, les certificats eIDAS ne pourraient entrer en production qu’au 3e trimestre. Compliqué dans ce contexte d’être prêt pour le 14 septembre.
Pas simple non plus pour les TPP de suivre le rythme pour revoir leur mode d’accès aux données (passer du webscraping aux API) ou encore obtenir les certificats adéquats.
Le Fallback et son exemption cristallisent aussi les critiques. Le « Fallback » désigne un mécanisme de secours en cas d’indisponibilité ou de mauvais fonctionnement des API. Les banques peuvent demander une dérogation à ce sujet. Mais le planning n’a pas été aligné en cohérence avec l’échéance 14 mars 2019 et le dossier à fournir demeure complexe. Le mécanisme de Fallback lui-même souffre d’imprécisions.
Comment recueillir le consentement des clients ? Selon quel parcours ? En imposant une redirection vers l’établissement teneur de compte ? Évidemment, ce n’est pas du goût des TPP. Pour l’heure, même à l’échelle française, aucun consensus n’émerge vraiment sur le sujet.
Le renouvellement de l’authentification ? Les RTS prévoient actuellement d’obliger les utilisateurs à se réauthentifier tous les 90 jours auprès de leurs banques. Les TPP estiment le mécanisme incompatible avec une expérience utilisateur digne de ce nom.
Gageons justement que cette expérience client, un peu perdue de vue au fil des textes réglementaires, devrait s’imposer comme l’alpha et l’oméga des discussions à venir. Et comme un objectif commun à l’ensemble des acteurs. Parce que chacun a autant à perdre qu’à gagner. Parce que, aussi, cette expérience dépend de business modèles à caler de part et d’autre.
Une certitude : la DSP2, sujet restructurant à l’échelle bancaire, appelle des investissements lourds dans des délais serrés. Et seule la coopération permettra à chacun d’y trouver des bénéfices – et pas seulement financiers –, en apportant au client final, les nouveaux services fluidifiant le paiement dans son parcours utilisateur.
Les autres articles qui peuvent vous intéresser
Email detox: et si on apprenait à se déconnecter ?
Email detox : et si l'on apprenait à se déconnecter ?
Dans les métiers du digital (et presque partout ailleurs), nous sommes tous un peu accros à nos emails.
65% des salariés consultent leurs emails toutes les 5 minutes.
Les salariés consacrent en moyenne 28% de leur temps à traiter leurs emails … et 19% supplémentaires à chercher et rassembler l’information pour traiter leurs emails. Cela représente 28h par semaine pour les travailleurs de la connaissance.
L’impact sur l’économie américaine est estimé à 588 milliards de $ par an (source : Trésor Américain), et à 1 milliard de $ pour Intel.
Cette addiction aux emails est nourrie par :
Le principe de réciprocité qui veut que nous ayons tendance à répondre à quelqu’un qui nous sollicite,
L’attrait de l’immédiateté et l’adrénaline qui est libérée lorsque nous recevons un message (avec des sentiments de tension, d’exaltation, de nouveauté et de stimulation),
La valorisation sociale afférente : si je reçois un message c’est que je suis important,
Et enfin la décharge cognitive de l’émetteur vers le récepteur (le « bonheur » de renvoyer la patate chaude).
Les toilettes sont la cause n°1 de perte de smartphone.
Apple
Quelques conseils pour reprendre le contrôle et maîtriser cette addiction ?
Supprimer les « pushs » et autres notifications sonores et visuelles, pour ne pas être interrompu et décider du moment où nous aurons envie de voir ces informations,
Le matin, ne pas relever ses emails avant 10h30 et se mettre à un travail de fond dans les 30 secondes qui suivent l’arrivée au bureau, car cela permet d’avoir un niveau de concentration plus élevé sur la journée entière. Pas avant 10h30 car il est important de traiter en premier NOS priorités plutôt que celles des autres
Se tenir à trois créneaux maximum de traitement d’emails en dehors desquels la messagerie restera fermée
Mettre son smartphone en mode avion pendant les réunions et éviter de relever ses emails quand on ne peut pas agir (pendant un hackathon, WE en rafting, pause restaurant…)
Se préserver des temps longs (2x2h30 par semaine) et travailler de manière séquentielle et mono-tâche, ce qui signifie avoir UN SEUL logiciel ouvert
Aller à l’essentiel : aurions-nous cherché cette information si on ne nous l’avait pas transmise ? Non ? Alors supprimez cet email !
Pratiquer la minute consciente : visualiser le visage du ou des destinataires avant d’envoyer un email. Cela permet de challenger si le contenu et les destinataires sont les bons. A noter que ce conseil est valable aussi sur les réseaux sociaux
Éteindre tout avant le dîner et séparer matériellement le pro et le perso : téléphone, PC, agenda, liste de tâches
Se déconnecter complètement à intervalle régulier pour se « rafraichir » le cerveau (24 heures par semaine et 2 semaines par an).
Alors à la veille des vacances, pourquoi ne pas se fixer un challenge « 0 connexion » pendant 2 semaines ?
Et pour la rentrée, mettre en pratique quelques-uns de ces conseils. C’est à vous de décider vos moyens d’interactions avec vos appareils, pas l’inverse.
Saviez-vous qu’il faut 2000 essais avant qu’un enfant soit capable de marcher sur ses deux pieds ?
Pourtant à l’âge adulte et en particulier dans le monde professionnel, l’échec est trop souvent stigmatisé et tabou. Comment inverser cette perception en voyant ses échecs comme le premier pas d’une future réussite ?
Cette démystification de l’échec passe par trois phases : l’observation & la captation des signaux faibles sur le terrain, l’expérimentation sur des cycles relativement courts, et pour finir la capitalisation afin de garantir de meilleurs résultats la fois d’après.
A l’aube de la « période transitoire » qui s’ouvre le 13 janvier, avec l’entrée en vigueur de la directive DSP2, on a un peu le sentiment de pénétrer en territoire inconnu !
Jusqu’ici, la communauté des paiements s’est concentrée sur la cible des normes techniques sous la conduite de l’Autorité Bancaire Européenne et plus particulièrement sur le débat entre API et « Web Scraping ».
A trop regarder la cible de mi-2019, en aurait-elle oublié les exigences à respecter dès le 13 janvier 2018 ?
En effet, c’est bien dès janvier que débute la « période transitoire » prévue à l’article 115 de la Directive, entre la prise d’effet de la DSP2 transposée en droit national et l’application, mi-2019, des normes techniques de réglementation concernant l’authentification et la communication (RTS SCA & CSC).
Certains travaux sont en cours pour préparer cette échéance, tels que :
L’information du client, notamment la mise à jour des conventions de comptes et contrats cartes,
La mise en place et la diffusion de la procédure de réclamation, avec des exigences resserrées de délai et de complétude de réponse et la révision de la franchise (50€ au lieu de 150€),
La mise à jour des tarifs (gratuité des demandes de recherche…) et la gestion partagée des frais entre Prestataires de Paiements,
Le monitoring des incidents et le reporting à la Banque de France sur les incidents majeurs,
L’information du client en cas d’incident susceptible d’avoir des répercussions sur ses intérêts financiers…
Toutefois, il sera compliqué de respecter les exigences de janvier sans remise en cause ou adaptation du « web scraping », actuellement utilisé par les Agrégateurs et Initiateurs de Paiement :
Comment concilier cette solution, basée sur l’appel aux sites de Banque en Ligne des Gestionnaires de Comptes, et les exigences de Janvier ?
Sécuriser les données de sécurité personnalisées de l’utilisateur (identification / authentification),
Limiter l’accès aux informations provenant des comptes de paiement uniquement,
Identifier le Prestataire de Paiements dans les échanges avec le Gestionnaire de Compte.
Les solutions ont certes déjà été discutées dans la communauté, au cœur même des débats sur les RTS SCA & CSC (Open API ou « Web Scraping sécurisé »), mais elles ne s’imposeront aux acteurs que dans 18 mois…
Alors, quelle sera la stratégie des acteurs à partir du 13 janvier ?
C’est donc bien une part d’incertitude qui plane sur la période transitoire, avec sur le fond, la question de l’attitude choisie par les acteurs, Banques et Fintech :
Tolérance et anticipation de la mise en œuvre des solutions discutées, sans attendre l’échéance réglementaire des normes techniques ?
Ou affrontement sur la base des exigences non respectées ?
Les décideurs y répondront, sans doute en revenant à l’esprit de la Directive : créer les conditions d’un nouveau marché, avec de nouveaux services rendus possibles par l’apport de tous les acteurs, dans le respect des conditions de sécurité et de protection pour l’utilisateur.
ls devraient alors y voir de nouveaux territoires à conquérir et privilégier l’initiative, la créativité et la capacité d’adaptation. En un mot : l’esprit de conquête !