Dans les précédents volets, nous avons expliqué ce qu’est une architecture MACH et dans quels cas elle exploite tout son potentiel.
Dans cet article nous allons décrire les 5 points fondamentaux à la mise en place d’une architecture MACH dans un contexte legacy.
Définir le parcours utilisateur et les points de bascule
Le parcours utilisateur est naturellement le point de départ de la création d’une architecture web, mais dans quelle mesure il me permet de la définir et de la concevoir ?
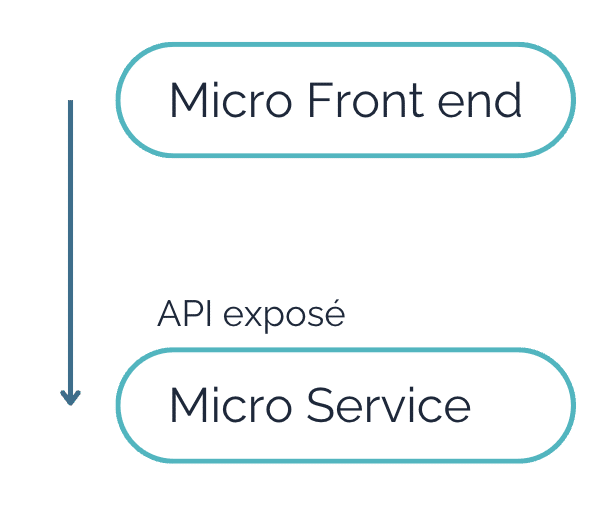
L’identification des différents points de bascule est primordiale pour identifier le découpage de l’architecture. Le “point de bascule” est une étape dans le parcours client qui nous permet de passer d’un contexte fonctionnel à un autre.
Pour identifier les points de bascule, pensez données
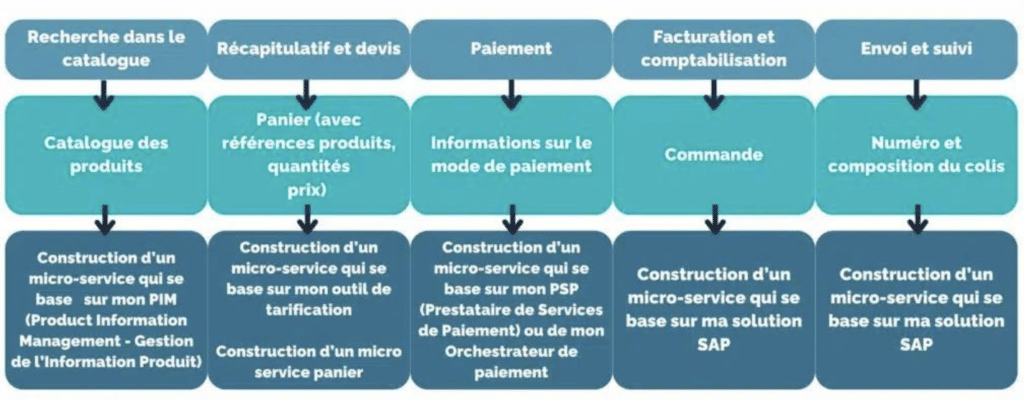
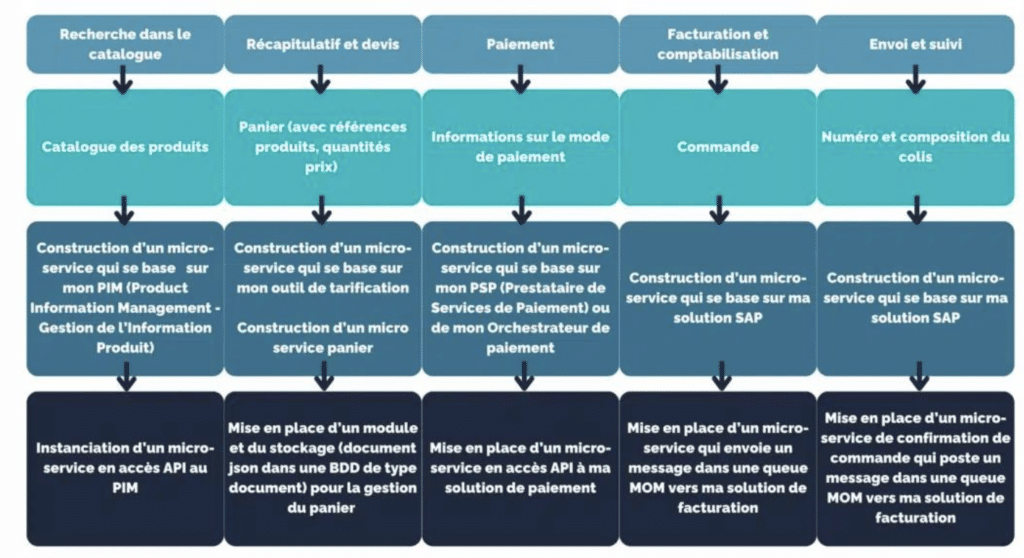
Le point important à retenir, pour assurer un bon découpage de l’application, est que ma donnée peut passer de mon navigateur (micro front-end) à mon application back-end (micro-service) jusqu’à mon back-office (SAP, etc.) sans avoir des dépendances et des liens qui se croisent. En gros, un micro-service qui fait appel à un autre micro-service, n’est plus un micro-service.
Pour cela, nous devons bien identifier les données impliquées dans chaque étape.
Bien que nous ayons des données qui semblent similaires, le découplage est garanti : l’information du panier n’est pas forcément persistée, c’est un “brouillon” de ma commande que je vais abandonner une fois qu’elle sera confirmée, il aura donc un cycle de vie différent avec une “fin de vie” au moment de la création de la commande.
Si nous voulons faire du micro-service, nous devons réfléchir au découpage des micro-services
Quand on parle de mise en place d’une architecture MACH, avec des back-office legacy, alors le découpage doit être adapté au contexte applicatif.
L’utilisation de la logique DDD (Domain Driven Design) ne doit pas s’abstraire de l’implémentation car quand on parle micro-service on parle bien de domaine métier mais également d’indépendance, etc. des principes qui découlent de choix d’implémentation.
Nous devons donc analyser les applications legacy et identifier les interactions qui seront nécessaires.
Ce découpage logique, simple, va créer le découplage entre mon application web, mon site eCommerce, et mes back office legacy, tout en exploitant leur potentiel et en créant des verticaux liés par le processus et indépendants dans leur conception et déploiement.
Penser déploiement et cloud-first
Bien que le Cloud ne soit pas une condition sinequanone, ces architectures se prêtent bien à un déploiement Cloud.
Les services managés des cloudeurs s’adaptent bien à ce type d’architecture. Nous pouvons parler ici de serverless (ex. AWS Lambda, Google Cloud Functions, etc.), de la containerisation dynamique (ex. AWS Fargate, Azure Containers) ou, bien que moins intéressant, de la simple virtualisation.
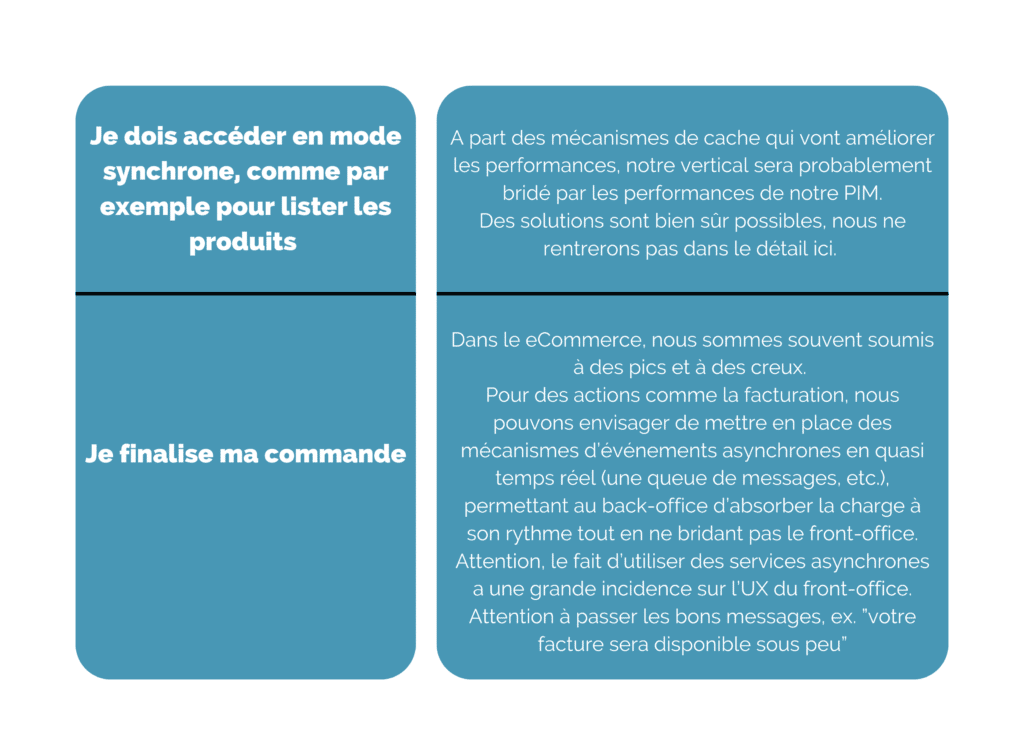
Mais attention, les systèmes legacy ne sont pas forcément scalables autant que nous le souhaiterions. Penser à la chaîne complète des intéractions n’est pas un luxe. Dans certains cas l’échange avec ces outils peut réduire notre potentiel de montée en charge.
Dans ces cas, pensons découplage front-office / back-office.
Voici deux cas de figure et des solutions possibles :
L’architecture MACH s’avère être une solution hautement pertinente pour les entreprises souhaitant accroître leur agilité et améliorer leur réactivité technologique. Malgré les défis que son adoption peut poser, notamment dans des contextes dominés par des systèmes hérités, les bénéfices en matière de personnalisation, de performance et de gestion de l’infrastructure sont incontestables. Les organisations doivent soigneusement évaluer leur capacité à intégrer cette architecture, en considérant leur environnement technique actuel et leurs objectifs futurs.
#2 DÉFINIR POURQUOI L’ARCHITECTURE MACH S’ADAPTE BIEN À L’ECOMMERCE
#2 DÉFINIR POURQUOI L’ARCHITECTURE MACH S’ADAPTE BIEN À L'E COMMERCE
3 juin 2024
Architecture
Erik Zanga
Manager Architecture
L’architecture MACH convient-elle à tous les métiers et cas d’usages, ou existe-t-il des situations où elle est plus avantageuse et d’autres où elle est moins adaptée ?
Pour répondre à cette question nous allons à nouveau décomposer ce style d’architecture dans ses 4 briques essentielles : Microservices, API First, Cloud First et Headless.
La lettre M : Micro-services
C’est probablement ce premier point qui dirige notre choix de partir vers une architecture MACH vs aller chercher ailleurs.
Nous pourrions presque dire que si l’architecture s’adapte à un découpage en Micro-services, le MACH est servi.
Pour aller un peu plus dans le détail, nous allons introduire le concept de “point de bascule” dans le parcours utilisateur. Nous définissons “point de bascule”, dans un processus, chaque étape qui permet de passer d’une donnée à une autre, ou d’un cycle de vie de la donnée à une autre.
Une première analyse pour comprendre si notre architecture s’adapte ou pas à une architecture MACH, est d’établir si dans le parcours utilisateur nous pouvons introduire ces points de bascule, qui permettent de découper l’architecture des front-end et back-end en micro front-end et micro-services.
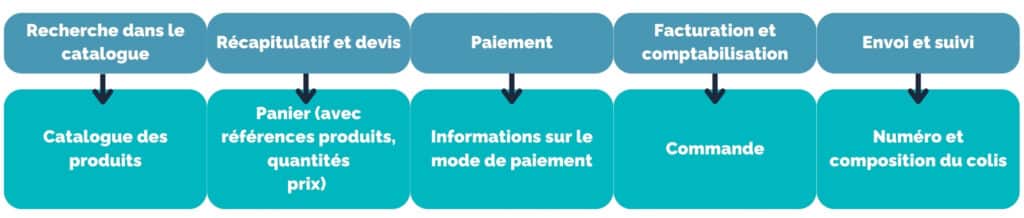
Un processus eCommerce par exemple s’adapte bien à ce type de raisonnement. Les étapes sont souvent découpée en :
Recherche dans le catalogue
Mise en panier
Confirmation
Paiement
Gestion de la livraison
Ces 5 étapes traitent les données de façon séparée, et sont donc adaptées à un découpage en Micro-services.
Résultat : Le “M” de MACH et l’efficacité de cette architecture est fortement liée au cas d’usage et au domaine d’application.
La lettre A : API-First
Qui parle web a forcément dû penser aux APIs, dans le sens de Rest API, pour garantir la communication entre front-end et back-end.
Pas de surprise que cela s’adapte à pas mal de solutions, car la communication entre le front-end (navigateur) et le back-end (application) se base sur le protocole HTTP et donc très adapté à ce type d’interface.
Nous ajoutons à tout ça le fait que la création d’un Micro-services et d’un Micro front-end, avec un découpage vertical sur les données traitées, implique naturellement la mise en place d’APIs et ressources spécifiques à chaque étape du parcours client.
Le contexte eCommerce, encore une fois, est bien adapté à ce cas de figure. Les étapes de parcours dont nous avons parlé avant s’inscrivent dans une logique d’APIsation, avec pour chacune d’entre elles une API dédiée.
Recherche dans le catalogue : adresser une API produits
Mise en panier : adresser une API panier ou devis
Confirmation : adresser une API commande
Paiement : adresser les APIs de paiement d’un prestataire (PSP, orchéstrateur de paiement, etc.)
Gestion de la livraison : adresser une API livraison
Résultat : Le “A” de MACH impacte moins que le “M” dans le choix de l’architecture mais épouse bien les concepts définis dans le “M”. Il est donc également très approprié pour un contexte eCommerce.
Pexels – ThisIsEngineering
La lettre “C” : Cloud-Native
Ce cas est probablement le plus simple : les seules raisons qui nous poussent à rester chez soi (infrastructure on premise), à ne pas s’ouvrir au cloud aujourd’hui sont de l’ordre de la sécurité, de l’accès et de la confidentialité de nos données (éviter le Cloud Act, etc.).
Au-delà de ces considérations, le passage au Cloud est une décision d’entreprise plus dans une optique d’optimisation de l’infrastructure que dans le cadre d’un cas d’usage, de processus spécifiques.
Résultat : Le “C” de MACH n’est pas d’un point de vue architectural pure une variante forte.
Néanmoins si nous regardons le cas d’usage cité auparavant, eCommerce, les restrictions sont levées car qui parle eCommerce parle naturellement d’ouverture, de mise à disposition sur le web, d’élasticité, concepts bien adaptés au contexte Cloud.
La lettre “H” : Headless
L’approche Headless convient particulièrement aux entreprises qui recherchent une personnalisation poussée de l’expérience utilisateur et qui ont la capacité de gérer plusieurs interfaces utilisateur en parallèle.
C’est le cas pour du eCommerce, où l’évolution rapide, le time to market et la réactivité au changements du marché peuvent influencer l’appétence, le ciblage du besoin client et le taux de conversion.
Résultat : Le « H » de MACH souligne l’importance de l’expérience utilisateur et de la flexibilité dans la conception des interfaces. Il est particulièrement avantageux dans les contextes où la personnalisation et l’innovation de l’interface utilisateur sont prioritaires. Cependant, il nécessite une réflexion stratégique sur la gestion des ressources et des compétences au sein de l’équipe de développement.
En somme, l’architecture MACH offre une grande flexibilité, évolutivité, et permet une innovation rapide, ce qui la rend particulièrement adaptée aux entreprises qui évoluent dans des environnements dynamiques et qui ont besoin de s’adapter rapidement aux changements du marché. Les secteurs tels que l’e-commerce, les services financiers, et les médias, où les besoins en personnalisation et en évolutivité sont élevés, peuvent particulièrement bénéficier de cette approche.
Cependant, l’adoption de l’architecture MACH peut représenter un défi pour les organisations avec des contraintes fortes en termes de sécurité et de confidentialité des données, ou pour celles qui n’ont pas la structure ou la culture nécessaires pour gérer la complexité d’un écosystème distribué. De même, pour les projets plus petits ou moins complexes, l’approche traditionnelle monolithique pourrait s’avérer plus simple et plus économique à gérer.
En définitive, la décision d’adopter une architecture MACH doit être prise après une évaluation minutieuse des besoins spécifiques de l’entreprise, de ses capacités techniques, et de ses objectifs à long terme.
L’architecture MACH, de par son acronyme, regroupe quatre pratiques courantes et actuelles dans le développement d’applications web.
C’est quoi Architecture MACH ?
Dans ce premier volet, nous allons nous concentrer sur les concepts fondamentaux qui composent ce concept : Microservices, API First, Cloud First, Headless, afin d’adresser l’objectif de chacun.
Tout d’abord un avis personnel, le fait de mettre ces concepts ensemble découle du bon sens : ce type d’architecture est considéré comme simple, efficace, intuitive, bien structurée, modularisée, bref… un travail que les vrais architectes doivent forcément apprécier !
Quid d’Amazon annonçant faire marche arrière pour Prime Video car la mise en application des micro-services implique un nombre d’orchestrations élevées ?
Les Micro-services, tels qu’expliqués dans d’autres articles (voir article micro-services), sont dans notre vision très fortement liés à un découpage DDD (Domain Driven Design).
Dans notre conception un micro-service définit un composant, dérivé d’un découpage métier et fonctionnel, agissant sur une donnée définie.
Le micro-service ne se limite pas uniquement à la partie back-end. Dans un contexte d’architecture web, il peut s’appliquer également au front-end.
Le Micro front-end et le Micro back-end se retrouvent intimement liés par une logique “composant d’affichage” et “composant qui traite applicativement la donnée affichée”.
Une architecture micro-services implique donc une certaine verticalité affichage, traitement et data.
API-First
C’est presque logique, on fait communiquer les différents composants par APIs.
Être API-first signifie d’intégrer la conception des APIs au cœur du processus de conception globale de l’application. Un peu comme si les APIs étaient le produit final.
Attention par contre, autant nous allons retenir l’API entre micro front end et micro back end, autant ce principe n’est pas partagé avec la communication entre le micro-service et d’autres composants du SI.
Une étude des différents patterns d’échange et un choix judicieux entre des méthodes synchrones et asynchrones est très importante pour éviter de mettre des contraintes fortes là où nous n’en avons pas besoin : pour partager une donnée avec les applications back office, tels qu’une confirmation de prise de commande avec un SAP, nous n’avons pas toujours besoin de désigner des flux synchrones ou API, nous pouvons par exemple découpler avec une logique de messaging, le cas d’usage nous le dira !
Cloud-First
Une vraie prédilection pour le Cloud, que du buzzword ?
En réalité, le fait de mettre en avant du Cloud dans cette démarche n’est que du bon sens.
Nous pouvons mettre en place une architecture on premise, pourquoi pas, mais dans certains cas il s’agit d’un vrai challenge : mise en place des serveurs, déploiement de la couche OS, des services, de la partie VM ou Container, etc.
Le Cloud First des architecture MACH vise la puissance des services managés, rapides de déploiement, scalables et élastiques, sur lesquels le déploiement en serverless ou en conteneur et la mise en place des chaînes CI/CD sont en pratique les seules choses à maîtriser, le reste étant fourni dans le package des fournisseurs de services cloud !
HEADLESS
Le Headless représente une tendance croissante dans le développement web et mobile. Cette approche met l’accent sur la séparation entre la couche de présentation, ou « front-end », et la logique métier, ou « back-end ». Cette séparation permet une plus grande flexibilité dans la manière dont le contenu est présenté et consommé. Elle offre ainsi une liberté de création sans précédent aux concepteurs d’expérience utilisateur et aux développeurs front-end.
Dans un contexte Headless, les front-ends peuvent être développés de manière indépendante. Les développeurs peuvent utiliser les meilleures technologies adaptées à chaque plateforme. Cela s’applique au web, aux applications mobiles, aux assistants vocaux, et à tout autre dispositif connecté. Cette approche favorise une innovation rapide. Cela permet aux entreprises de déployer ou de mettre à jour leurs interfaces utilisateur sans avoir à toucher à la logique métier sous-jacente.
La question qui nous vient à l’esprit maintenant est :
Ce type d’architecture s’applique à tout cas d’usage ? Certains sont plus réceptifs que d’autres de par leur configuration, gestion du parcours utilisateur ?
Qu’en est-il aujourd’hui, le GraphQL est-il réellement une alternative concrète aux APIs standard ?
Mais déjà, qu’est-ce que le GraphQL ?
Le GraphQL se définit par la mise à disposition d’une interface de “requêtage” qui s’appuie sur les mêmes technologies d’intégration / les mêmes protocoles utilisée par les API REST.
Ici, nous restons sur le protocole HTTP et par un payload de retour (préférablement au format JSON) mais la différence principale du GraphQL, pour le client, repose sur le contrat d’interface.
Le contrat d’interface façon GraphQL devient variable, tout comme la réponse. En effet, dans la requête nous pouvons spécifier ce que nous souhaitons recevoir exactement dans la réponse.
Nous mettons ainsi le doigt sur un gros avantage de cette interface GraphQL qui, par essence, va grandement diminuer le “overfetching et le “underfetching” (comprendre ici le fait de récupérer trop peu ou au contraire trop d’informations jugées inutiles dans le contexte) d’API
Autre avantage, ce besoin en données spécifiques pourra être différent à chaque appel et donc permettre une grande flexibilité d’usages à moindre effort.
Le GraphQL s’est fait sa place !
A l’époque de l’écriture de notre premier article, le GraphQL commençait à s’introduire dans certains cas d’usage, très souvent en mode POC et découverte, avec un concept attrayant mais sans preuve réelle de plus value.
Aujourd’hui nous observons une vraie adhésion à ce nouveau mode d’interfaçage, bien que nous en constatons encore des points d’amélioration.
Ce qui est intéressant à remarquer est qu’il se développe sur des métiers très variés. Non seulement au niveau des éditeurs de logiciels mais également dans le cadre de développements spécifiques, de plateformes dédiées.
Les usages à date : quelques exemples
Netflix, qui utilise le GraphQL pour unifier les accès aux différentes APIs.
Dans le retail, Zalando, pour récupérer les informations sur les différents produits et pour gérer les consentements.
MonEspaceSanté, le service lancé par l’ANS en début d’année, et qui effectue de requêtes GraphQL à partir du navigateur.
Le GraphQL comme réponse à un besoin d’uniformisation ?
Avant la naissance du GraphQL, le besoin d’uniformisation de ce type d’interaction était dans la ligne de mire de certains acteurs. Aujourd’hui le GraphQL peut apporter une réponse concrète et standardisée à ces problématiques.
Deux exemples d’envergure :
Microsoft : Microsoft a par le passé essayé de fournir des APIs “flexibles” pour adresser certains cas d’usage. Cette tentative s’est matérialisée par la création de l’OData et de l’API Microsoft Graph.
Ne vous trompez pas, l’objectif reste similaire mais l’approche est, à ce stade, différente. Dans une logique d’uniformisation et standardisation, nous voyons difficilement Microsoft s’affranchir d’une réflexion autour du GraphQL pour atteindre ces objectifs.
Salesforce : Salesforce propose également depuis plusieurs années, une API bas niveau qui pourrait, par ses caractéristiques et son besoin de flexibilité, être adaptée à la technologie GraphQL.
Constat actuel sur les usages du GraphQL
Quand nous regardons les cas d’utilisation de GraphQL, nous pouvons constater qu’il est majoritairement utilisé côté Front-end.
En lien avec ce cas d’utilisation, nous observons également que le GraphQL est souvent vu comme un agrégateur d’API, et pas comme un moyen de requêtage directement lié à une vision pure données.
Mais pourquoi ce type d’usage ?
Nous listons trois arguments principaux pour expliquer la prédominance de ce type de cas d’usage.
La restitution de format est très adaptée au monde du web : une réponse simple, toujours vraie et personnalisable ; le protocole HTTP et des concepts proches des APIs REST, le GraphQL s’adapte très bien aux couches front.
Chaque API derrière GraphQL gère son propre périmètre, si nous faisons la correspondance avec les architectures DDD (Domain-Driven Design), nous pouvons affirmer que l’API bas niveau adresse un domaine particulier, alors que le GraphQL est là pour pouvoir “mixer” ces différents concepts et donner une vision un peu plus flexible et adaptée à chaque cas d’usage. Dans ce cas nous allons faire de l’overfetching sur les couches bas niveaux, et faire un focus utilisation au niveau de la partie frontale.
Le cache, éternelle question autour du GraphQL. Dans ce cas d’usage le cache reste possible au niveau des APIs de bas niveau, qui iront donc moins solliciter les bases de données, alors que sur la couche GraphQL, de par sa variabilité de réponse, nous en avons peut-être moins besoin. Pour rappel, le cache sur une requête GraphQL, bien que possible, devient naturellement plus complexe à gérer et donc perd un peu de son intérêt.
Pourquoi ne faut-il pas limiter le GraphQL à ces usages ?
Pour nous, c’est notre conviction, le GraphQL a de nombreux atouts et doit se développer sur ces usages de prédilection, mais pas que !
UN ARGUMENTAIRE FORT : L’ACCÉLÉRATION DE LA CONCEPTION !
Un des grands atouts de la mise en place d’une API GraphQL reste le côté, si vous m’autorisez le terme, “parfois pénible” de la définition des API Rest : des discussions infinies entre le métier et l’informatique pour définir ce dont nous avons besoin, le découpage, etc.
Une API GraphQL par définition n’a pas une structure ou un périmètre de données définis, mais s’adapte à son utilisateur.
Le GraphQL comme moyen d’accélérer les développements ?
Une évolution de l’API bas niveau n’est plus nécessaire pour satisfaire le front
Un accès unifié aux données par un seul endpoint, sans forcément aller chercher dans les différentes APIs / applications
Tout en exploitant la logique de cache car le front end ne change pas
Et en plus des évolutions dans la gestion des caches permettent aujourd’hui de mettre en cache les données GraphQL
UNE DISTINCTION CLAIRE : ATTENTION AUX CAS D’USAGE !
Nous ne visons certainement pas tous les cas d’usages, mais l’objectif ici est de casser un peu certains mythes.
Si utiliser des mutations (en gros l’équivalent de l’écriture) intriquées, nous l’avouons, peut être très complexe, dans les cas de requêtage de bases de données ayant comme objectif principal l’exposition en consultation, nous disons “pourquoi pas !”.
Vous auriez probablement reconnu le pattern CQRS, avec, par exemple, une Vision 360 Client qui expose les informations avec une API GraphQL.
CÔTÉ TECHNIQUE
Les améliorations dans la gestion des caches, ces dernières années, permettent de gérer ce sujet, tout en restant plus complexe qu’avec une API REST standard.
Attention aux autorisations
Nous n’allons pas nous attarder sur ce sujet, que nous avons déjà traité dans notre précédent article (que nous vous invitons à parcourir ici), mais nous souhaitons le rappeler car il est crucial et extrêmement critique.
Si nous souhaitons traiter les sujets d’accès à la donnée avec une API GraphQL, une logique RBAC avec rôles et droits définis au niveau de la donnée (matrice d’habilitations rôles / droits proche de la donnée elle même) nous semble à ce stade la meilleure solution : N’AUTORISONS PAS L’ACCÈS UNIQUEMENT AU NIVEAU DE L’API, MAIS ALLONS AU NIVEAU DATA !
Conclusion
La technologie continue de s’affirmer, un standard semble se définir et s’étoffe de plus en plus. Dans un monde API qui se complexifie de jour en jour, les enjeux autour de la rationalisation et de l’optimisation des usages API restent au cœur des débats sans pour autant trouver de solution directe et efficace via la technologie REST. Et c’est encore plus vrai quand le besoin de base n’est pas clairement défini…
Le dynamisme apporté par le GraphQL, dans certains cas de figure, permet de simplifier ces discussions en apportant des réponses cohérentes avec le besoin.
Ce n’est pas une solution magique faite pour tous les usages, mais une réelle alternative à considérer dans les conceptions API.
Et vous ? Avez-vous pris en considération cette alternative pour vos réflexions API ?
Ne vous en faites pas, il n’est pas trop tard, parlons-en, ce qui ressortira de nos discussions pourrait vous surprendre.
Vous avez des APIs pour interconnecter les systèmes ? Parfait c’est une belle première étape. Asseyons-nous maintenant pour parler de résilience et de découplage… Une nouvelle étape s’ouvre : les APIs Asynchrones ? Mais quelle obscure clarté, quelle douce violence est-ce donc que cela ??
Un petit récap, pourquoi parler d’APIs asynchrones ?
Le sujet des APIs asynchrones résonne depuis quelques années dans la tête des architectes, et ces derniers en font de plus en plus un de leurs objectifs : une API, donc un contrat d’interface bien défini, qui s’affranchit des défauts des APIs. Comme disait le sage Bruno dans son article : “Favoriser l’asynchronisme est un bon principe de conception de flux”.
Ce besoin d’éviter un couplage fort et de créer des SAS de décompression entre les différentes applications / parcours est certainement cohérent, mais est à priori en contradiction avec la nature même des API et du protocole HTTP. Alors comment concilier le meilleur de ces deux mondes ?
Commençons par les bases, une API asynchrone, concrètement, c’est quoi ?
Une API asynchrone est une API recevant, par exemple, la commande d’un client, client qui n’attend pas la réponse de celle-ci dans l’immédiat. Le seul retour mis à disposition par l’API, dans un premier temps, est la prise en compte de la demande (un « acknowledgement » : vous avez bien votre ticket, merci d’attendre).
Le fournisseur d’API effectue les actions nécessaires pour satisfaire la requête, sans forcément être contraint par des timeouts, en gros il peut prendre son temps pour en garantir la bonne exécution.
Et dans la pratique ?
En pratique, cette architecture peut être garantie par le couple API qui poste dans une queue / topic assurés par un outil de type MOM.
L’API déverse les informations dans une queue (ou topic) du MOM, informations qui sont ensuite prises en compte suivant les disponibilités des applications en aval. L’application appelée devient un consommateur d’un flux asynchrone, ce qui permet de découpler les deux.
Pour notifier, ça passe crème
Ce type de comportement est facilement mis en place lorsque nous nous trouvons dans des cas de figure non critiques, dans lesquels par exemple on doit notifier un utilisateur LinkedIn de l’anniversaire d’un de ses contacts : en tant que client, tant pis si l’information n’arrive pas, nous pouvons accepter un manque de fiabilité.
Un peu moins quand l’objectif porte sur un échange critique
Tout change quand le demandeur s’attend à quelque-chose, soit une information soit une confirmation forte de la livraison de l’information , car cet aspect demeure crucial pour son bon fonctionnement. Dans une API synchrone, nous l’obtenons à la fin de la transaction.
Dans le cas asynchrone, comment garantir le même comportement lorsque la transaction se termine ?
C’est à ce niveau que les avantages de l’asynchronisme induisent une complication de gestion, complication dont souvent les équipes n’ont pas conscience. Une confirmation de réception (“acknowledgement”) est dans ces cas insuffisante (ex. votre transaction bancaire s’est bien passée, comme par exemple un virement).
Mais alors comment notifier le client du résultat ?
La mise en place d’une logique de réponse peut être construite de deux façons différentes.
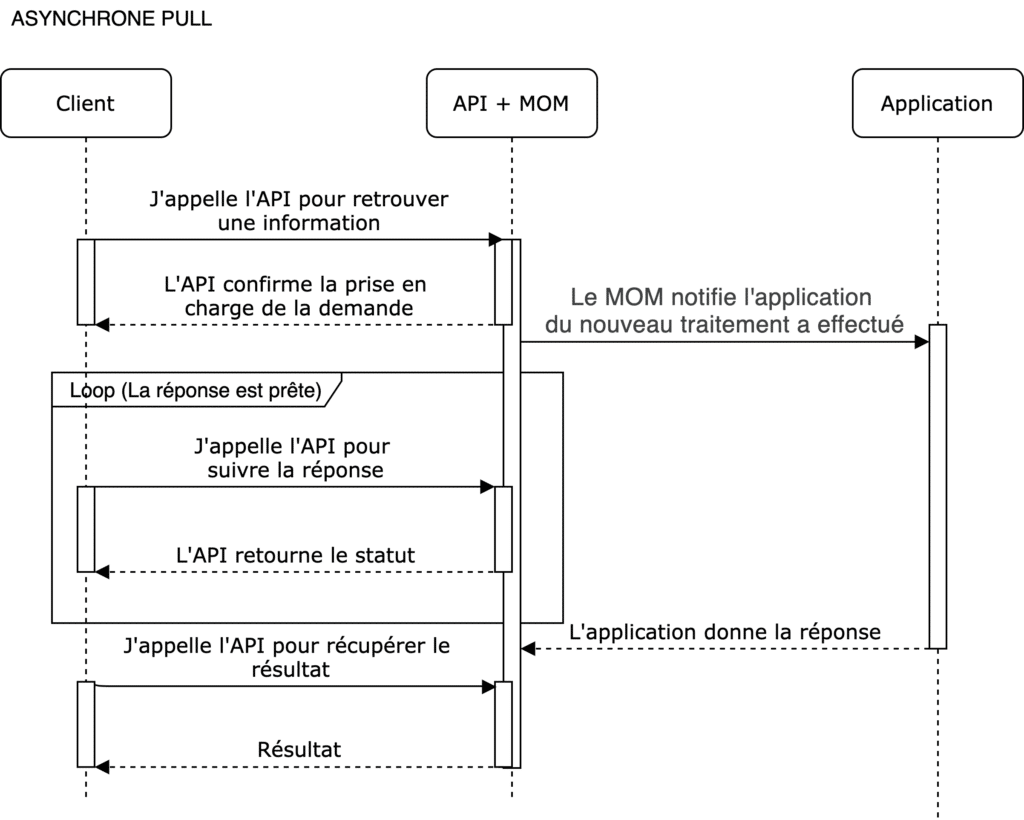
En mode PULL
Le mode pull présuppose que l’action soit toujours à l’initiative du client.
L’API met à disposition le statut de l’action (sous forme de numéro de suivi), sans notifier le client. C’est au client de venir vérifier le statut de sa demande, en faisant des requêtes de suivi à des intervalles réguliers.
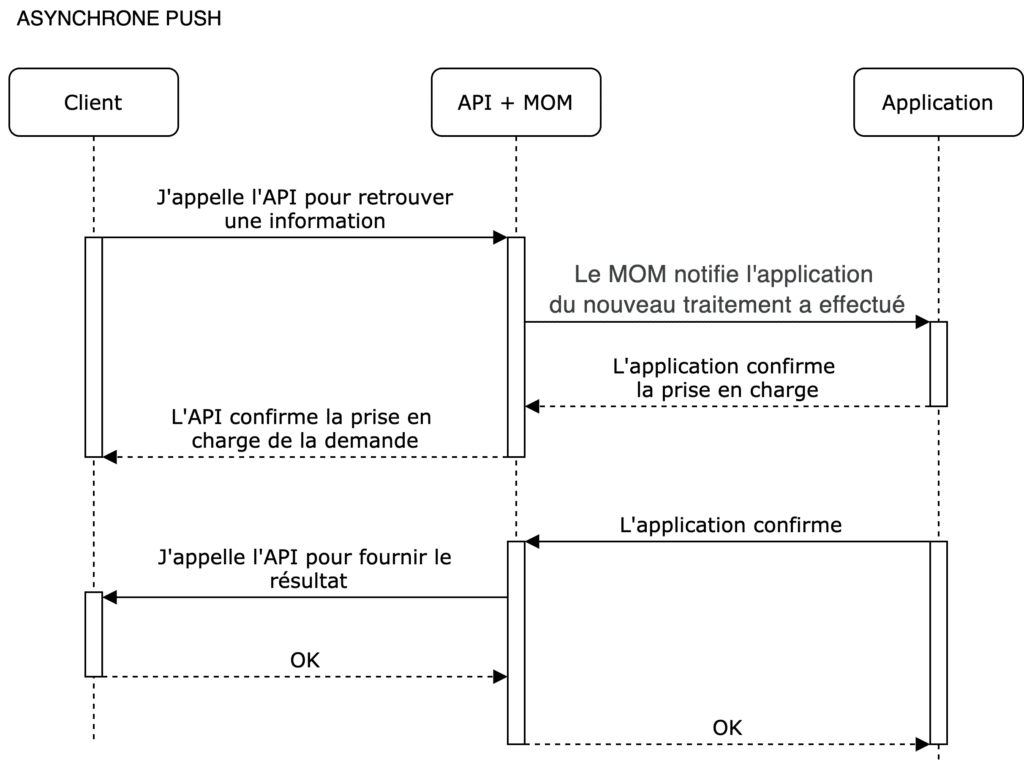
En mode PUSH
Le mode push suppose que le canal de communication soit ouvert dans les deux sens, et que le serveur ne soit pas forcément tenu d’attendre une requête du client pour “pousser” l’information.
Certaines technologies et patterns d’architecture, permettent de mettre en place ce mode de communication, pour citer les plus connus :
Le protocole websocket permettant l’ouverture de canaux pour établir une communication bidirectionnelle entre serveur et client,
Les mécanismes de CallBack et Webhooks,
Les constructions réalisées avec des MOMs, basées sur des queues / topics d’aller et d’autres de retour, qui se traduisent en patterns request / reply implémentés par certains de ces outils,
Basés sur des solutions similaires au précédent point, des patterns d’architecture custom permettant de gérer ces aller-retours entre applications.
Les patterns schématisés ci-dessous ne sont pas exhaustifs mais ont pour objectif de montrer des exemples réels de contraintes, en termes de flux, apportées par les trois modes : synchrone, asynchrone pull et asynchrone push.
Synchrone
Asynchrone Pull
Asynchrone Push
Mais alors, push ou pull ?
L’utilisation d’un pattern par rapport à l’autre doit être réfléchie, car donner un avis tranché sur la meilleure solution est assez compliqué sans connaître l’environnement et les contraintes. Les deux techniques sont fondamentalement faisables mais le choix dépendra du besoin réel, des patterns supportés par les socles déjà déployés et des applications difficilement intégrables en synchrone.
Notre avis est d’éviter au maximum les solutions pull, car ces méthodes impliquent des aller-retour inutiles entre les applications.
Comment mettre du liant entre aller et retour ?
La mise en place d’une API asynchrone présuppose donc une certaine attention à l’intégrité fonctionnelle entre la requête et la réponse, qui ne sont pas, dans le cas de l’asynchronisme, forcément liées par la même transaction.
Pour garantir l’intégrité fonctionnelle et le lien entre la requête et la réponse, surtout dans le cas d’une notification PUSH, un échange d’informations pour identifier et coupler les deux étapes est nécessaire. L’utilisation d’informations spécifiques dans l’entête des requêtes, comme dans le cas d’APIs synchrones, est une solution performante, tout en s’assurant d’avoir mis en place les bonnes pratiques de sécurité visant à éviter l’intrusion de tiers dans la communication. Sans vouloir réinventer la roue, les mécanismes déjà en place pour d’autres technologies peuvent être repris, comme par exemple les identifiants de corrélation, chers au MOMs, identifiants qui permettent de créer un lien entre les différentes communications.
Si on utilise des mécanismes non natifs aux API, pourquoi passer par une API et pas par un autre moyen asynchrone ?
Le choix de passer par une API a plusieurs raisons, suivant le cas d’usage :
c’est le standard actuel auquel la plupart des solutions ont adhéré, avec un fonctionnement API first même si le besoin est asynchrone
l’éventuelle gestion par API gateway, rendue possible sur une construction asynchrone par cette solution, demeure très pratique pour la gestion des échanges, avec des avantages que les protocoles / solutions asynchrones classiques ne sont pas prêts d’intégrer
Cela ne limite pas pour autant le spectre d’APIs asynchrones au seul HTTP. Bien que le standard OpenAPI soit fortement focalisé HTTP, d’autres standards ont été conçus expressément pour les cas d’usage asynchrone.
Exemple, la spécification AsyncAPI. Cette spécification se veut agnostique du protocole de communication avec le serveur, qui peut être du HTTP, mais également du AMQP, MQTT, Kafka, STOMP, etc. standards normalement employés par des MOMs.
Conclusion
En conclusion, notre conviction est que l’asynchronisme est vraiment la pièce manquante aux approches API. L’APIsation a été un formidable bond en termes de standardisation des interfaces mais reste jusque là coincée dans son carcan synchrone. L’heure de la pleine maturité a sonnée !
L’erreur la plus commune, quand on entreprend une démarche micro services, est de vouloir découper en micro-services !
Le concept de micro services existe désormais depuis une dizaine d’années. Netflix étant la première « grande entreprise » (si on pouvait la nommer ainsi à l’époque) à adopter une telle orientation.
Avec le recul, le plus gros problème des micro services repose sur le fait de les avoir appelés « micro ». En lisant sur Wikipedia, on retrouve sous le chapitre « Philosophie », la phrase suivante : « Les services sont petits, et conçus pour remplir une seule fonction ».
Rien de plus incorrect si on veut bien entamer une démarche micro services… Tout comme parler de nano services et macro services, pour analyser des mauvaises pratiques, comme font certains acteurs. Ce n’est pas une question de taille !
Les efforts doivent principalement se focaliser sur trois axes fondamentaux dans la réflexion sur le découpage :
SIMPLICITÉ : un micro-service doit être spécialisé. Il ne doit pas avoir une couverture fonctionnelle complexe, il doit effectuer un ensemble d’actions simples et ciblées. Ceci étant dit, nous ne devons pas non plus réduire un microservice à une simple fonction, dans l’objectif de “faire petit” : un microservice doit couvrir un ensemble fonctionnel cohérent.
ISOLATION : un microservice doit être isolé des autres. Le dysfonctionnement d’un microservice ne doit pas impacter les autres afin d’éviter l’effet domino.
INDÉPENDANCE : un microservice garantit son indépendance, il englobe tout ce qui lui est nécessaire pour son fonctionnement. Dans la décennie de la containérisation, tout a été mis en œuvre pour que le concept d’indépendance, associé aux microservices, devienne simple et intuitif. Un container de par sa nature est facilement associable à un microservice
A partir de ces considérations, quelle est la meilleure approche pour définir le périmètre de ses micro services ?
Partons du besoin primaire d’un SI : Traiter de la donnée ! Conjuguons ce besoin à une autre caractéristique des micro services : un micro service interagit avec une donnée qui lui est propre. Une solution simple se propose : réalisons un découpage par la donnée ! Le premier pas pour dessiner un découpage des microservices est de définir la structure de la donnée.
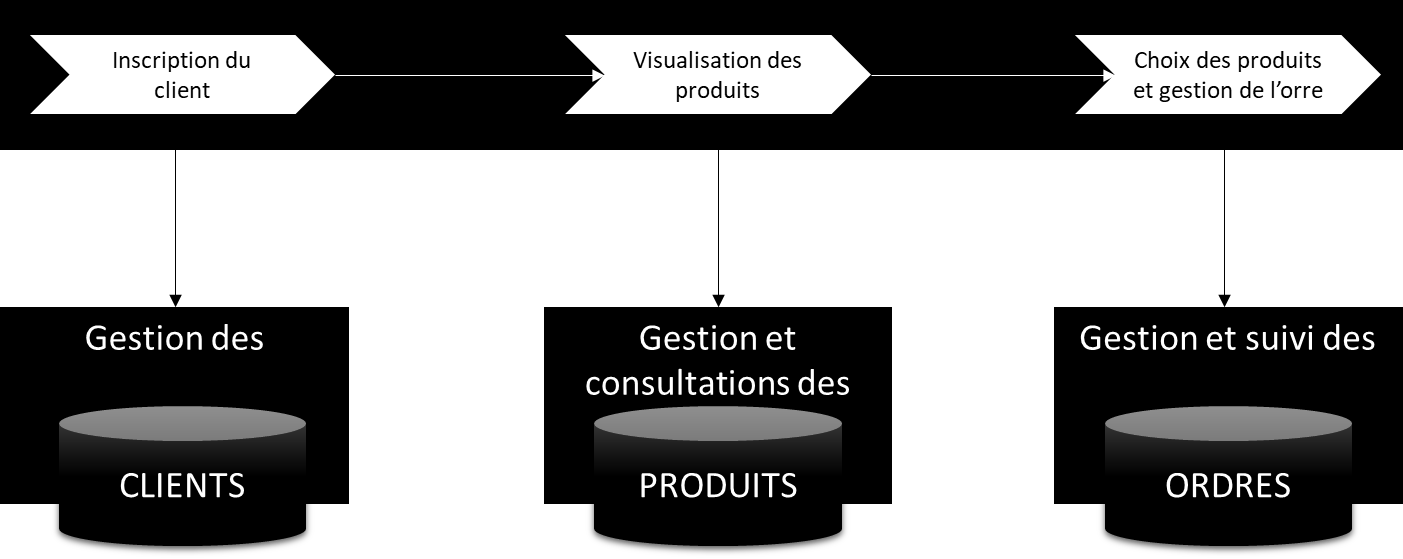
Prenons un exemple très simple : le triptyque CLIENT, PRODUIT et ORDRE.
Dans la logique que je viens d’expliquer, nous pouvons construire un Microservice sur chaque entité métier :
Ce qui permet à une application frontale de combiner les trois pour, par exemple, permettre à un site d’eCommerce, de :
passer un ordre
après avoir consulté la liste des produits
et avoir géré l’inscription d’un client
Cette démarche n’est certainement pas exhaustive. Chaque cas de figure nécessite une analyse à part entière, mais à notre sens c’est un bon point de départ pour une réflexion micro service.
Pour résumer, une bonne pratique de découpage en micro services est initiée par le découpage de la donnée, en entités métier.
Voici une vidéo créée par nos soins pour illustrer ces explications : ici
Conclusion
Essayer de faire « petit » n’est pas forcément le sujet sur lequel focaliser ses efforts… L’indépendance et l’isolation sont les clés d’une bonne démarche micro-services. Si un doute surgit, le mieux est de ne pas découper tant que les autres principes sont respectés.