
2 septembre 2020
– 6 min de lecture
Architecture
Mohammed Bouchta
Consultant Senior Architecture
Pendant la dernière décennie, nous avons assisté à la montée en puissance du Cloud Computing dans les nouvelles conceptions d’architecture SI.
Sa flexibilité faisant abstraction de la complexité des infrastructures techniques sous-jacentes (IaaS, PaaS) et son mode de facturation à la consommation (Pay as you go) étaient des atouts suffisants pour convaincre les premiers clients. Mais c’est surtout le développement d’un nombre important de nouveaux services innovants avec une grande valeur ajoutée qui a mené la plupart des entreprises à adopter le Cloud. C’est ainsi par exemple que la grande majorité des entreprises ont pu expérimenter le Big Data, le Machine Learning et l’IA sans avoir à débourser des sommes astronomiques dans le matériel approprié en interne.
Le Cloud a facilité également le développement du secteur de l’IoT, ces objets connectés dotés de capteurs qui envoient leurs données régulièrement à un système central pour les analyser. En effet, le Cloud a fourni une panoplie de services pour absorber toutes les données collectées et une puissance de calcul importante pour les traiter et les analyser.
Cependant, le besoin de prendre des décisions en temps réel sans être tributaire de la latence du Cloud et de la connectivité dans certains cas, donne du fil à retordre aux experts lorsque les sources de données commencent à devenir extrêmement nombreuses.
Ainsi, d’autres besoins beaucoup plus critiques ont émergé en lien avec l’utilisation des objets connectés qui nécessitent des performances importantes en temps réel, et ceci même en mode déconnecté. Nous pouvons le constater par exemple dans les plateformes pétrolières en mer, les chaînes logistiques ou les véhicules connectés qui nécessitent une prise de décision locale en temps réel alors que le partage des données sur le Cloud permettra de faire des analyses plus globales combinant les données reçues, mais sans exigence forte sur le temps de traitement.
Ce sont ces contraintes et d’autres encore comme la sécurité des transmissions et la gestion de l’autonomie, qui ont donné naissance à un nouveau paradigme d’architecture, celui du Edge Computing.
Gartner estime que d’ici 2025, 75% des données seront traitées en dehors du centre de données traditionnel ou du Cloud.¹
Que signifie le edge computing exactement ?
À l’opposé du Cloud Computing qui tend à déplacer tous les traitements dans le Cloud, le Edge Computing vise à rapprocher la puissance de calcul, le stockage et les applications de l’endroit où la donnée a été créée. Cela permet ainsi de pallier les problèmes de connectivité, de latence et les risques liés à la sécurité.
Avec le Edge Computing, l’analyse des données peut se faire directement sur le périphérique qui les a générés, comme par exemple les smartphones ou les objets connectés qui ont des ressources suffisantes. Si l’objet connecté est limité en ressources de calcul, de stockage, de connectivité ou d’énergie, comme dans la majorité des cas, alors c’est une passerelle IoT équipée de ces capacités, qui prend en charge la collecte, la transformation, l’analyse des données et la prise de décision / action.
Cette décentralisation du stockage et du traitement des données permet de répondre aux exigences de la prise de décision en temps réel.
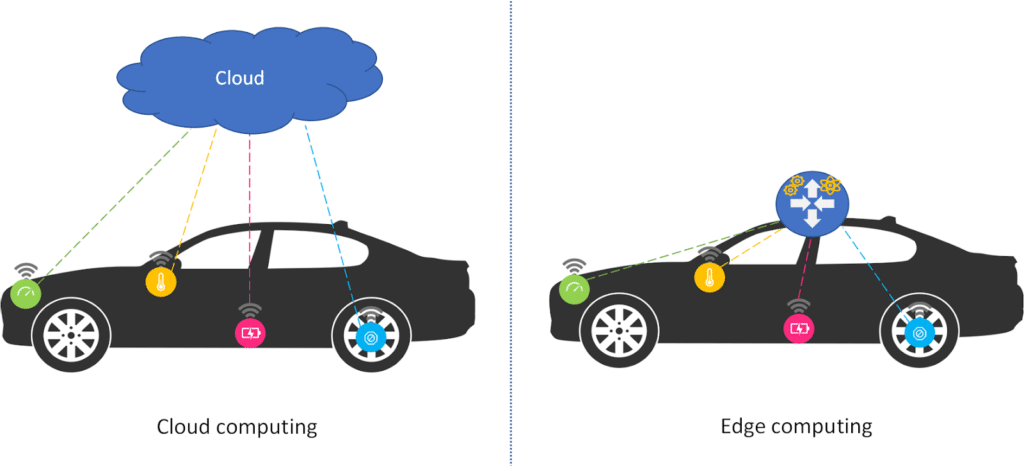
Prenons l’exemple de la voiture autonome dans une situation de danger imminent, nous devons envoyer la globalité des données des capteurs sur un Cloud pour les analyser et attendre que le Cloud renvoie à la voiture les directives à suivre pour éviter l’accident. Même avec toute la puissance de calcul du Cloud, le temps de latence imposé par le réseau peut mener à la catastrophe. Alors qu’avec une analyse des données et une prise de décision locale, en temps réel, la voiture aura une chance d’éviter l’accident.
Ou l’exemple d’une machine dans une chaîne de production qui doit adapter sa vitesse d’action par rapport à plusieurs facteurs environnants qui proviennent des appareils de la chaîne. L’utilisation du Edge Computing au niveau de la Gateway IoT (passerelle) permet de récupérer les données nécessaires des périphériques locaux pour analyser et ajuster la vitesse de la machine en conséquence sans avoir à passer par le Cloud.
L’autre atout majeur du Edge Computing est sa résilience. Le système local peut continuer à fonctionner même s’il y a une défaillance majeure dans le Cloud, dans le réseau ou sur d’autre branche du système.
Toutefois, il ne faut pas croire qu’il est simple de mettre en place ce type d’architecture, bien au contraire. En effet, nous revenons à une architecture distribuée qui nécessite des appareils avec des ressources plus importantes (donc plus chères) et souvent avec des technologies hétérogènes qui doivent s’interfacer ensemble pour communiquer, ce qui complexifie l’administration et la maintenance. Aussi, en stockant les données en local, le problème de sécurité des données est déplacé vers les périphériques qui les stockent. Que ce soient les objets connectés ou la Gateway IoT, ces appareils peuvent être accessibles physiquement et sont donc plus vulnérables à un piratage. Ces périphériques devront se doter d’une politique de sécurité accrue pour s’en prémunir.
Ce changement d’approche a ouvert des opportunités pour les fournisseurs de télécommunications qui développent de nouveaux services liés à la 5G, à l’IoT et à d’autres technologies. Il a poussé les différents acteurs du marché à innover pour proposer des offres plus adaptées au Edge Computing. C’est ainsi que les leaders en matériel informatique comme Cisco, Dell EMC et HP par exemple ont tous mis sur le marché des produits dédiés à ce type d’architecture. Les géants du Cloud ont aussi réagi en force à cette tendance avec une palette de services qui peuvent s’étendre jusqu’aux périphériques connectés pour agir localement sur les données.
D’autre part, les avancées technologiques en matière de microcontrôleurs toujours plus miniaturisés, puissants et avec une consommation réduite de l’énergie, ont permis de faire de l’IA embarquée dans les objets connectés afin d’être plus rapide et efficace dans la prise de décision.
Vers la fin du cloud computing ?
Absolument pas ! Le Cloud a encore de belles années devant lui. En réalité, les deux solutions sont complémentaires et c’est le type de traitement nécessaire, le temps de réponse attendu et les exigences de sécurité qui vont déterminer ce qui doit être traité au niveau du Edge et ce qui doit être envoyé vers le Cloud.

Si nous reprenons le cas de voiture connectée, le Cloud va permettre d’agréger les données envoyées par toutes les voitures afin de les traiter, de les comparer et de faire des analyses approfondies pour optimiser les algorithmes de conduite et le modèle IA à déployer comme nouvelle version du programme embarqué dans les voitures connectées.
En combinant le potentiel de collecte et de l’analyse en temps réel des données du Edge Computing avec la capacité de stockage et la puissance de traitement du Cloud, les objets IoT peuvent être exploités de façon rapide et efficace sans sacrifier les précieuses données analytiques qui pourraient aider à améliorer les services et à stimuler l’innovation.
En conclusion
Il est peu probable que l’avenir de l’infrastructure réseau se situe uniquement dans le Edge ou dans le Cloud, mais plutôt quelque part entre les deux. Il est possible de tirer la meilleure partie de leurs avantages respectifs. Les avantages du Cloud Computing sont évidents, mais pour certaines applications, il est essentiel de rapprocher les données gourmandes en bande passante et les applications sensibles à la latence de l’utilisateur final et de déplacer les processus du Cloud vers le Edge. Cependant, l’adoption généralisée du Edge Computing prendra du temps, car le processus de mise en œuvre d’une telle architecture nécessite une expertise technique approfondie.
En fin de compte, vous devez toujours commencer par bien cibler les usages, les exigences et les contraintes de votre système pour choisir la bonne architecture.