Le design system qu’est ce que c’est, pourquoi l’adopter ?
Le design system qu’est ce que c’est, pourquoi l’adopter ?
23 octobre 2024
Rhapsodies Digital
Christophe Roselmac
Responsable design Rhapsodies Digital
L’adoption d’un design system est une décision qui nécessite une compréhension approfondie des besoins de l’entreprise et une communication efficiente avec la sa direction. Dans cet article nous allons apporter notre définition à ce qu’est un design system et les gains qu’il peut apporter à une stratégie globale.
Que suppose l’adoption d’un design system ?
Référence centrale pour tous les projets de conception, le design system est le langage commun entre les designers et les développeurs. Il permet de simplifier le travail des équipes tout en préservant une harmonie dans l’expérience utilisateur et une cohérence visuelle.
La mise en place d’un design system est avant tout un travail de compréhension des besoins, des enjeux et de communication entre les équipes.
La compréhension des besoins passe par une recherche approfondie pour analyser les spécificités des produits existants, identifier les problèmes de cohérence et mesurer l’impact sur l’expérience utilisateur.
L’évaluation des enjeux passe par une compréhension des contraintes budgétaires, des ressources disponibles ou encore de l’analyse de la concurrence afin de savoir à quoi nous faisons face. Cela permettra d’être certain qu’un design system est la solution appropriée à mettre en place.
Cette évaluation des enjeux doit être partagée avec la direction de l’entreprise en mettant en évidence les avantages potentiels qu’apporteront l’adoption d’un design system pour améliorer l’efficacité globale.
Des impacts concrets sur le ROI peuvent être mis en avant, comme l’économie des coûts de développement, de réduction du temps de mise sur le marché ou encore l’amélioration de l’expérience utilisateur et constituent autant d’arguments pour des décideurs quant à son adoption.
Le choix de mettre en place un design system est une décision stratégique, tout en étant un projet à part entière qui vit et évolue au rythme de la production de l’entreprise. Cette dernière peut réaliser des gains significatifs en termes d’efficacité et d’efficience des équipes grâce à la cohérence générale de l’organisation et des produits qui en découlent.
À quel moment se demander si un design system peut être utile ?
Chaque projet a ses particularités et suit des phases d’évolutions depuis sa création. Il peut exister plusieurs contextes spécifiques où il y a une nécessité d’établir des normes et des ressources pour la conception cohérente d’interfaces.
Les deux premiers moments clés où un design system devient pertinent sont lors de la croissance de l’entreprise et/ou de son produit et lors du constat de la répétition et de la redondance d’éléments de design.
En effet, la multiplication des types d’écrans et de pages lorsqu’un produit devient plus complexe peut être facilité grâce à un design system aidant à maintenir la cohérence visuelle et fonctionnelle.
L’augmentation de l’équipe de conception peut également initier la mise en place d’un design system, concentré sur des directives claires et des composants standardisés facilitant l’intégration de nouvelles personnes rejoignant l’équipe.
La répétition et la redondance peuvent être drastiquement réduites grâce à la centralisation d’éléments dans un design system. Il sera important de consacrer du temps à sa mise en place, quand on constate que les mêmes design sont recréés dans différentes sections d’un produit ou différents projets.
Enfin, si différents membres de l’équipe produisent des design qui ne sont pas uniformes, un design system permettra d’harmoniser les styles et les éléments.
Les autres moments importants ou un design system devient indispensable sont lors de phases d’évolution importante de l’entreprise et/ou son produit, voici quelques exemples :
La migration technologique : lorsqu’un produit évolue vers un nouveau produit ou un nouveau framework, un design system à toute sa pertinence pour aider l’intégration des nouveaux composants tout en maintenant la cohérence. Cela va de paire avec de nouvelles normes de conception fournissant une base pour appliquer ces changements de manière uniforme à travers le produit.
Améliorer la collaboration : dans les environnements de travail avec des équipes interfonctionnelles ou dispersées géographiquement ou encore suite à l’intégration de nouvelles équipes suite à une acquisition, un design system fournit un langage commun, des ressources partagées et facilite la standardisation et une meilleure collaboration.
Optimiser les process de conception et développement : une documentation centrale pour la formation et la conformité avec les standards de conception issus d’un design system permet de réduire des temps de développements des nouveaux composants et style en réutilisant les éléments existants.
Vous l’aurez compris, le design system est un outil puissant et devient incontournable lorsqu’une organisation nécessite une approche systématique pour maintenir la cohérence, améliorer l’efficacité et faciliter la collaboration entre différentes équipes. Le design system devient particulièrement pertinent lorsque les défis de cohérence et de gestion de l’interface et de l’expérience nécessitent une solution structurée.
A notre niveau de cabinet de conseil et d’architecture des SI, il nous paraît indispensable d’ajouter notre pierre à cet édifice. D’autant que les précités n’ont pas tout dit…
Le Numérique Durable: pourquoi faire ?
On le dit et le redit et c’est bien le sous titre de notre travail : L’architecture est “Green by design”. En effet, depuis longtemps les architectes construisent des SI solides, non redondants donc sobres en fait…
Sans compter le temps passé à challenger les métiers sur leurs besoins. Et à éviter les travaux inutiles… Faire et défaire c’est du travail inutile et si on peut éviter c’est toujours ça d’économisé…
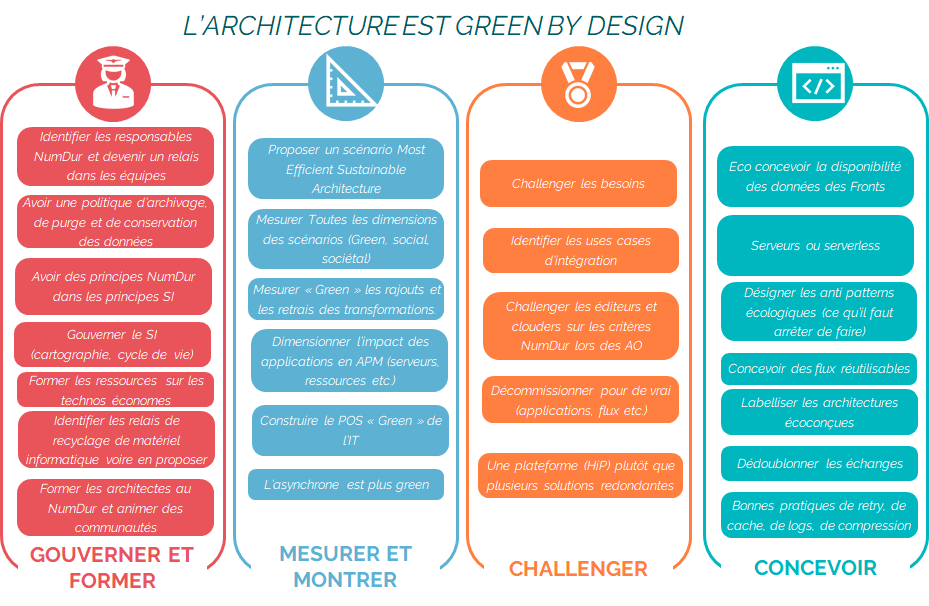
4 grands thèmes qui ne sont pas propres à l’architecture
Nous avons voulu que notre travail puisse être adapté en tant que guide à beaucoup d’expertise en plus de l’architecture :
Gouverner et former : qu’est ce que votre expertise / discipline / domaine de compétences peut mettre en place dans sa gouvernance et dans la formation des personnes pour intégrer les dimensions de responsable et de durable ?
Mesurer et montrer : que va-t-on pouvoir mesurer dans votre discipline et quels résultats va-t-on pouvoir montrer ?
Challenger : quels sont les thèmes ou autres domaines sur lesquels vous allez pouvoir challenger pour aller vers la diffusion des bonnes pratiques ?
Concevoir : quelles sont les bonnes pratiques lors de vos travaux de conception qui peuvent permettre d’aller vers plus de durabilité ?
Les architectes au coeur du Système d’Information
Le travail des architectes est on le rappelle ci-dessous :
L’Architecture d’Entreprise organise le dialogue entre les différents corps de métier pour définir une vision commune de l’entreprise de demain et de son SI, ainsi que la trajectoire pour y parvenir. Elle met en œuvre les approches nécessaires pour assurer la connaissance, la gouvernance et le pilotage opérationnel du SI.
A ce titre, les architectes sont au coeur des SI et des transformations et doivent donc jouer un rôle d’influenceur dans la direction du Numérique Durable. Ce guide est là pour fournir des clés à cette population particulière.
Face aux différentes évolutions réglementaires, un programme a été constitué au sein de la filiale d’Affacturage, intégrant :
Le nouveau moteur de calcul de provisions IFRS9 et le calculateur d’assiette (RWA)
La nouvelle méthode de calcul (IRBF/Standard)
L’alimentation des plateformes groupe cibles :
Assiette fournie au calculateur Bâlois du groupe
Alimentation des outils de reporting groupe
Contrôle de cohérence entre filiale et groupe
Simulation par la filiale de son niveau de Risque.
Solution
La mission de Direction de Programme consiste à assurer la cohérence, maîtriser les adhérences, les chevauchements de plannings et les échéances imposées.
L’intervention a mobilisé un profil Senior Manager :
Forte expérience de pilotage de programme
Capacité de dialogue avec tous les acteurs, métier (Risques, Clientèle…) et IT
Expertise pour sécuriser les chantiers à forte compétence métier : garanties, notation tiers, défaut client/acheteur, FBE/NPE, grappage…
Liaison Groupe : Schéma Directeur Finance Risque, calculateur groupe…
Bénéfices
Livraison des chantiers Notation et Défaut Client
Solution transitoire de prise en compte des garanties
Gain en RWA
Respect des recommandations de l’audit interne et validation des normes BCE
Les autres success stories qui peuvent vous intéresser
Dans le cadre de la mise en œuvre de la nouvelle norme IFRS 9, BPCE a initié dès 2015 le programme qui prend en charge les impacts sur l’ensemble des métiers du Groupe (Finances, Risques, Comptabilités et Consolidation…) :
Classification des instruments financiers au niveau de chaque établissement ;
Révision des plans et schémas comptables ;
Définition et simulation des modèles de dépréciation, avec spécification d’un moteur centralisé.
Missions
Accompagnement de la Direction des Risques Groupe et de la Direction des Comptabilités Groupe dans la formalisation des expressions de besoins sur :
Les Tests SPPI & Business Models ;
La Gestion des Dépréciations ;
La structuration des annexes, en lien avec les évolutions du FINREP ;
Le chronogramme de production et son insertion dans les processus existants ;
Structuration modulaire des fonctionnalités de l’outil centralisé de gestion des dépréciations : segmentation IFRS 9, fonctions de calcul, affectation des provisions, restitutions aux établissements au niveau détail contrat et agrégé comptable (production CRE) ;
Définition des échanges de flux entre les communautés informatiques et le Groupe, et au sein des SI de l’organe central (COREP, FINREP, Consolidation…) ;
Formalisation des dossiers d’architecture fonctionnelle et applicative ;
Animation des comités d’architecture fonctionnelle Groupe et communautés IT.
Bénéfices
Contenu fonctionnel partagé entre les différents acteurs du Groupe ;
Architecture cible définie et partagée aux différents niveaux du Groupe, intégrée à la stratégie d’évolution des SI et alignée sur les exigences BCBS 239 ;
Meilleure maîtrise des enjeux et des risques des projets de la filière SI ;
Définition d’une trajectoire réaliste pour le démarrage du 1er janvier 2018.
Les autres success stories qui peuvent vous intéresser
Au sein de l’équipe Risk Solutions / Risk Monitoring & Synthesis, participer à des chantiers d’évolutions liés à la mise en place des reporting des données risques de crédit pour les besoins réglementaires (programme Filière Unique) et de monitoring (application Global Vision).
Et ce dans le contexte du système de Core Banking ATLAS 2, utilisé par CIB International et par de nombreuses entités « Retail » du Groupe.
Missions
Recueillir les besoins sur les évolutions de monitoring et de reporting des risques de crédit en organisant des séances d’entretiens utilisateurs ;
Elaborer une priorisation des demandes (planification et suivi) ;
Rédiger la documentation fonctionnelle en adéquation avec les besoins exprimés et les solutions proposées (note d’initialisation, expression des besoins) ;
Etudier les solutions susceptibles de répondre aux besoins exprimés en collaboration avec la MOE et valider ces solutions ;
Préparer et exécuter des tests fonctionnels (organisation de la recette et rédaction des cahiers de recette) ;
Organiser et suivre le déploiement des évolutions en collaboration avec les équipes support et déploiement ;
Assurer le support et la formation des utilisateurs (procédures et guides utilisateurs, accompagnement au changement).
Bénéfices
Apport d’expertise Risques de Crédit ;
Optimisation de la supervision et de la coordination des différents projets ;
Gain en efficacité au niveau du suivi et de la prise en charge des actions à mener ;
Renforcement du contrôle de la qualité des livrables.
Les autres success stories qui peuvent vous intéresser