Rhapsodies Conseil Maroc a accompagné un client du secteur bancaire.
Contexte et enjeux
Un programme a été lancé pour faire évoluer le SI en désimbriquant le Core Banking existant qui avait été étendu sur trop de fonctions et faire évoluer le SI au global. Le choix s’est porté sur une modularisation du SI, seule solution à même de permettre de répondre aux différents besoins d’évolution.
Rhapsodies Conseil a réalisé un audit sur ce programme et ses différents composants pour analyser les causes du retard et l’alignement sur les bonnes pratiques d’architecture de la cible
A la suite de cet audit, un accompagnement dédié sur l’architecture du programme et son suivi a été mis en place avec des experts de Rhapsodies Conseil.
Mission
Accompagner le programme et les projets au jour le jour
Arbitrer les décisions d’Architecture
Proposer des remédiations de la dette accumulée par les anciens arbitrages
Décrire la cible d’architecture et les paliers
Equilibre des choix entre les briques progicielles et développement
Désimbrication de la vente et de la gestion des produits du Core Banking
Mise en place d’une nouvelle solution de vente et de gestion des contrats
Mise en place d’un référentiel de gestion des produits, des tarifs et de la facturation
Mise en œuvre d’un portail conseiller unifié
Exposition des fonctions de conseil et de vente aux différents canaux
Intégration de ces solutions avec le reste du SI et des partenaires de la banque
Résultats
Un accompagnement dédié au programme par un architecte référent
Capacité d’influer sur les décisions du programme
Capacité d’échange haut niveau avec les éditeurs sur les briques stratégiques du programme
Autres success stories qui pourraient vous intéresser
Terraform, grand favori du public concernant les logiciels d’Infrastructure as Code est connu principalement comme étant Cloud Agnostic. Mais le connaissez-vous réellement ? Terraform c’est près de 5000 fournisseurs de plateformes, infrastructure ou Saas allant bien au-delà du Cloud et un rachat récent soulevant un problématique de souveraineté.
Quelles sont les limites de cet outil qui paraît pouvoir tout faire ? Comment marche t-il et où se trouve sa prévalence par rapport à ses concurrents ? Sa place de favori est déjà remise en question et cette dynamique semble bel et bien en marche..
Le fonctionnement de Terraform ainsi que ses limites
Bien que Terraform soit souvent qualifié d’outil cloud agnostic, cela ne signifie pas pour autant que le même code peut être déployé tel quel sur AWS, Azure ou OVH. En réalité Terraform nécessite une configuration spécifique pour chaque (cloud) provider.
Pour bien comprendre cette nuance, il est essentiel de revenir sur le fonctionnement de Terraform et de clarifier ce que signifie réellement le terme cloud – ou provider – agnostic dans ce contexte.
Terraform utilise le langage HLC (Hashicorp Langage Configuration) pour communiquer avec les plateformes des fournisseurs. Cette communication se fait par le biais d’appels vers les APIs mis en place par ces fournisseurs. En théorie Terraform peut communiquer avec toute plateforme ou service qui expose une API. Mais bien évidemment la plupart des plateformes dont on parle sont intégrées via des “providers Terraform”.
Les APIs des fournisseurs, que ce soit niveau protocole, services exposés, champs requis etc diffèrent les uns des autres entraînant inéluctablement une différence au niveau de la suite d’instructions demandée à Terraform pour chaque provider.
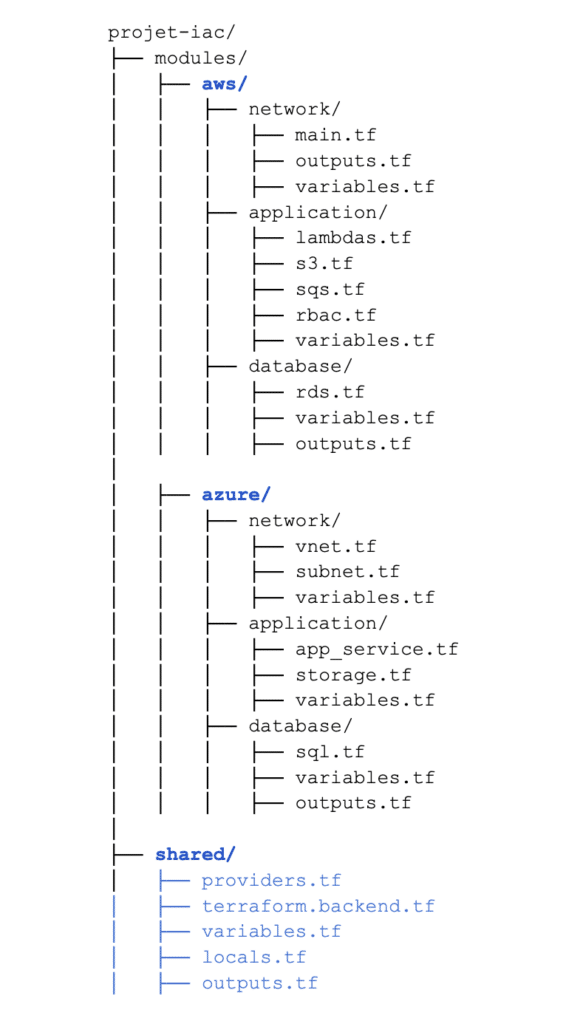
Comme on peut le voir dans l’arborescence suivante, on devra typiquement créer un dossier spécifique à chaque provider, en plus d’un dossier partagé pour des variables plus globales.
Le fait d’avoir tous les providers décrits dans le même projet nous permet d’établir une logique et des conditions sur quand et comment utiliser chaque provider. Terraform a bien évidemment d’autres avantages.
Utilisez pleinement Terraform
On l’a dit Terraform c’est près de 5000 providers dont les solutions souveraines OVH, Scaleway ainsi que les incontournables Kubernetes, Datadog, AWS, GitHub etc.
Cette diversité permet :
De combiner des infrastructures on-premise et cloud, permettant de gérer au même endroit l’intégralité des ressources d’un projet hybride.
En corollaire, optimiser les coûts en mettant en concurrence les services des différents fournisseurs (exp. stockage dans AWS, bases de données dans GCP)
Créer des configurations spécifiques et réutilisables: En choisissant d’exposer certains modules comme point d’entrée, l’équipe OPS ou Opérationnelle peut offrir aux équipes de développeurs une façon simple de créer des ressources en masquant toute la logique propre au fournisseur à l’intérieur desdits modules.
Exemple: Ici on implémente les modules application, database etc avec toute leur complexité “cachée”
De plus, Terraform est de type déclaratif, c’est-à-dire qu’il décrit l’état final de l’infrastructure: l’ordre dans lequel on déclare les ressources n’est donc pas important, ce qui peut faire une préoccupation technique en moins.
Enfin, Terraform permet de réduire la courbe d’apprentissage lors du lancement ou du basculement d’un projet vers de l’IaC.
Nous le verrons dans les lignes suivantes, l’IaC est également une façon non négligeable d’optimiser ses ressources.
Optimisation des ressources, résilience et numérique durable
Les outils d’IaC quels qu’ils soient permettent de décrire comment construire et donc reconstruire une infrastructure simplement en exécutant un code. Cette facilité offre de la résilience: si l’infrastructure est corrompue, il suffit de la reconstruire en ré-exécutant le code versionné “avant incident”.
Un autre avantage est qu’on peut se permettre de détruire totalement notre infrastructure au moment où l’on en a pas besoin, pour la reconstruire aussitôt que le besoin s’en re-fait sentir. Cela implique que l’on peut supprimer notre environnement de dev ou de pré-prod le week-end ou le soir en fin de journée pour la reconstruire à l’identique le lundi matin.
Cette économie de ressources génère des optimisations financières notamment pour les services facturés à l’heure et une utilisation plus responsable des ressources.
Souveraineté de la plateforme
L’acquisition récente de Hashicorp (la société derrière Terraform) par IBM pose un problème au niveau de la souveraineté.
Terraform propose trois offres :
Terraform CLI : Communautaire (chacun peut créer/rajouter un provider) et “Open Source” (voir note en fin d’article)
HCP Terraform : Terraform version SaaS, hébergé sur la plateforme Cloud de Terraform: la Hashicorp Cloud Platform
Terraform Enterprise : La version hébergeable dans nos propres datacenters ou cloud privés.
En matière de souveraineté, la discussion s’articule ici autour de la version Communautaire Terraform CLI qui, en plus d’être la plus populaire, est la seule qui ne soit pas propriétaire.
Ce rachat de Terraform par IBM donc, pourrait entraîner des changements de licences dans la version communautaire. Le mot d’ordre pourrait peu à peu devenir l’accroissement des bénéfices commerciaux au détriment de la communauté Terraform.
Et pour cela, pas forcément besoin d’un revirement de situation à 180°, des décisions à priori anodines pourraient contraindre la liberté d’agir sur la version communautaire et ainsi inciter à se tourner vers les versions payantes.
De plus, IBM ayant également sa propre plateforme Cloud, l’entreprise pourrait mettre celle-ci en avant, au détriment du multi-cloud à la Terraform. (1)
A noter le parallèle flagrant avec le rachat de Red Hat par IBM en 2019.
Vous avez la main…
La souveraineté des données est une préoccupation majeure de notre temps et force est de noter que la communauté est très résiliente à s’efforcer de proposer des solutions Open Source dès lors que celle-ci est menacée.
Depuis le changement en 2023 de la license de Terraform CLI, la version “Open Source” de Terraform vers la license BSL (Business Source License) qui restreint les usages à but de compétition commercial directe, une solution dérivée nommée Open TOFU a vu le jour et continue de prendre de l’ampleur avec le rachat récent.
Il est vrai que IBM assure à ce jour sur le site Hashicorp que Terraform CLI restera “Always Free”, mais les adages “la confiance n’exclut pas le contrôle”, “il ne faut pas pas mettre tous ses oeufs dans le même panier non souverain”, ainsi que le principe du “zero trust”, sont autant de beaux préceptes qu’il serait prudent de garder à l’esprit.
Elle est au rendez-vous de presque l’ensemble des salons, conférences, webinar ou encore pause-café avant les premières réunions de la semaine et tend à devenir le principe clef dans l’intégration ou la mise en place d‘une plateforme data : La gouvernance de données.
Le mot peut paraître abstrait, brutal et directif mais tout l’enjeu est justement de la vulgariser un maximum pour la partager et évangéliser son adoption.
Il faut bien avoir conscience que si vous rencontrez des incidents liés à la qualité, la cohérence ou la fiabilité de vos données aujourd’hui c’est probablement lié soit à un manque de gouvernance soit à un manque de suivi de cette gouvernance.
Parce que mettre en place une plateforme permettant de brasser des Tera de data c’est bien mais le faire avec des principes clefs et des règles de sécurités c’est mieux, nous allons voir quelques notions clefs pour pouvoir mettre en place une gouvernance réussie.
Dans 76% des cas, la gouvernance existe mais elle est vite négligée au profit du time to market conduisant souvent à une perte de confiance des sponsors voir du déficit commercial.
Kezako la gouvernance de données ?
Sortant d’une mission de presque 6 ans sur le SI Data Architecture & Engineering chez Givaudan, je vais tenter de vous en donner ma définition et ma vision afin de vous familiariser avec le sujet.
Tout en ayant conscience qu’il n’est pas aisé de donner une définition simple de la gouvernance de données sans tomber dans un premier travers qui est sa mécompréhension conduisant inévitablement à sa dévalorisation puis sa négligence, je tente quand même ma chance :
Au-delà d’un simple ensemble de règles ou d’un outil, d’un concept ou d’une méthodologie, la gouvernance est un cadre stratégique qui regroupe à la fois l’ensemble des principes humains et machines liés aux acteurs de la data mais aussi la garantie du respect des normes et processus liés à l’utilisation de ces données.
Elle regroupe l’ensemble des pratiques et processus permettant de créer, maintenir, sécuriser et faire évoluer l’ensemble des data et metadata d’un SI.
C’est à la fois une déclinaison du RACI lié à la plateforme data et en même temps l’implémentation de ses règles de maintenance et d’utilisation. Le tout n’étant pas exclusif à la plateforme Data, mais doit s’inscrire dans la gouvernance SI dans son entièreté.
La gouvernance de données ne décrit pas uniquement la gestion de la donnée mais la politique contribuant à la manipuler et les responsabilités de chacun afin d’éviter les imbroglios de qui ou quel job a maintenu quoi, comment et pourquoi ?
Et c’est un point crucial à mettre en place dès l’introduction d’une nouvelle typologie de données en nommant un ou des responsables de la gouvernance de cette donnée qui auront la charge de documenter et garantir les règles d’ingestion, d’accès, d’enrichissement, dédoublonnage, maintenance, diffusion pour en citer quelques unes et en les faisant évoluer au grès de la politique d’entreprise.
Qu’est qui ne fait pas partie de la gouvernance de données ?
La gouvernance n’oriente pas les choix de plateformes, la mise en place d’une infrastructure. Elle n’est pas une composante de l’analyse d’une donnée ou dans le choix d’un scénario projet.
Pourquoi la gouvernance ?
Vous l’aurez compris quand le sujet traite de politique cela fait souvent vite fuir le business qui sera pourtant l’atout clé dans l’évangélisation de la pratique.
Les problèmes liés à un manque de gouvernance ont souvent pour résultat une initiative prise hors du champ de responsabilité ou un manque de clarté amenant des interprétations diverses voire faussées.
Les principaux piliers clefs permettant d’apporter un ROI notable de la gouvernance sont selon moi :
La Gestion et maintenance des métadonnées : Pour vulgariser un temps soit peu, les métadonnées sont le passeport des données. Les bonnes pratiques consistent à définir un modèle de métadonnées, à documenter les données et à mettre en place un catalogue de données.
Qualité des données : La qualité est essentielle pour prendre des décisions business éclairées. Les bonnes pratiques incluent la mise en place de processus de validation, l’utilisation d’outils de profilage et de nettoyage, et la définition de métriques de qualité.
Sécurité : La protection des données est une priorité absolue. Les bonnes pratiques consistent à mettre en place des contrôles d’accès, à chiffrer les données sensibles, à réaliser des sauvegardes régulières et à mener des audits de sécurité.
Conformité : protocol sécurisé d’échanges de données HIPP / instances réglementaires lié au stockage et à l’utilisation de la donnée.Le respect des réglementations est obligatoire. Les bonnes pratiques incluent la connaissance des réglementations applicables, la mise en place de processus de conformité et la désignation d’un responsable de la protection des données.
Politique et Standards: partager un socle de définition des données clefs de l’entreprise
Fiabilité : garantir la véracité d’une donnée à n’importe quel moment et n’importe quel endroit du SI
Et dans la pratique ça donne quoi ?
Tout d’abord, vous devrez avoir en tête les étapes clés pour pouvoir définir le cycle de vie de la gouvernance :
Obtenir le soutien de la direction : La gouvernance des données est un projet d’entreprise qui nécessite l’engagement de tous les niveaux hiérarchiques.
Effectuer un audit des données existantes : Identifier les manques et les redondances pour déterminer les axes de transformations.
Définir une stratégie: Aligner la gouvernance avec les objectifs de l’entreprise.
Mettre en place un comité de gouvernance : Définir les rôles et les responsabilités de chaque acteur.
Sensibiliser les utilisateurs : Former les collaborateurs à l’importance de la gouvernance.
S’en suivent les bonnes pratiques pour s’assurer d’une mise en oeuvre efficace :
Impliquer les métiers : Les utilisateurs finaux doivent être impliqués dans la définition des règles de gouvernance.
Utiliser des outils adaptés : Choisir des outils de gouvernance qui répondent aux besoins spécifiques de l’entreprise.
Adopter une approche agile : La gouvernance doit être évolutive et s’adapter aux changements de l’entreprise.
Mesurer la performance : Définir des indicateurs clés de performance (KPI) pour évaluer l’efficacité de la gouvernance.
Les bénéfices de la gouvernance des données
Amélioration de la prise de décision : Les données fiables et accessibles permettent de prendre des décisions plus éclairées et de réduire les risques.
Augmentation de la productivité : Les équipes passent moins de temps à chercher des données et peuvent se concentrer sur des tâches à plus forte valeur ajoutée.
Réduction des coûts : La gouvernance permet d’éviter les erreurs coûteuses et d’optimiser l’utilisation des ressources.
Amélioration de la réputation : Une bonne gouvernance des données renforce la confiance des clients et des partenaires.
Les défis et les tendances
Les défis :
La complexité des environnements de données : Big data, cloud, IoT.
La résistance au changement : Impliquer les utilisateurs peut être difficile.
Le coût des investissements : La mise en œuvre d’une gouvernance peut représenter un coût important.
Les tendances :
L’IA au service de la gouvernance : L’intelligence artificielle peut automatiser certaines tâches de gouvernance.
La gouvernance des données dans le cloud : Les enjeux spécifiques du cloud.
La gouvernance des données personnelles : Le respect des réglementations comme le RGPD.
La gouvernance des données est un voyage, pas une destination. Elle nécessite un engagement continu de la part de tous les acteurs de l’entreprise. En suivant les bonnes pratiques et en s’adaptant aux évolutions technologiques, les entreprises peuvent tirer pleinement parti de leurs données et gagner en compétitivité.
Nous vous accompagnons dans le pilotage de votre architecture
18 décembre 2024
– 3 minutes de lecture
Architecture
Olivier Constant
Senior Manager Architecture
Nous vous accompagnons dans le pilotage de votre architecture
Aujourd’hui, nous repartageons une success story de notre mission chez un acteur majeur du secteur bancaire. Olivier et ses équipes sont intervenus pour accompagner de façon globale ce client sur son architecture d’entreprise au travers d’un centre de services.
N’hésitez pas à nous contacter pour plus d’informations ! 💬
Les autres sucess story qui peuvent vous intéresser
Envie d’intégrer l’intelligence artificielle à vos processus métiers ?
Envie d'intégrer l'intelligence artificielle à vos processus métiers ?
L’intelligence artificielle à vos processus métiers
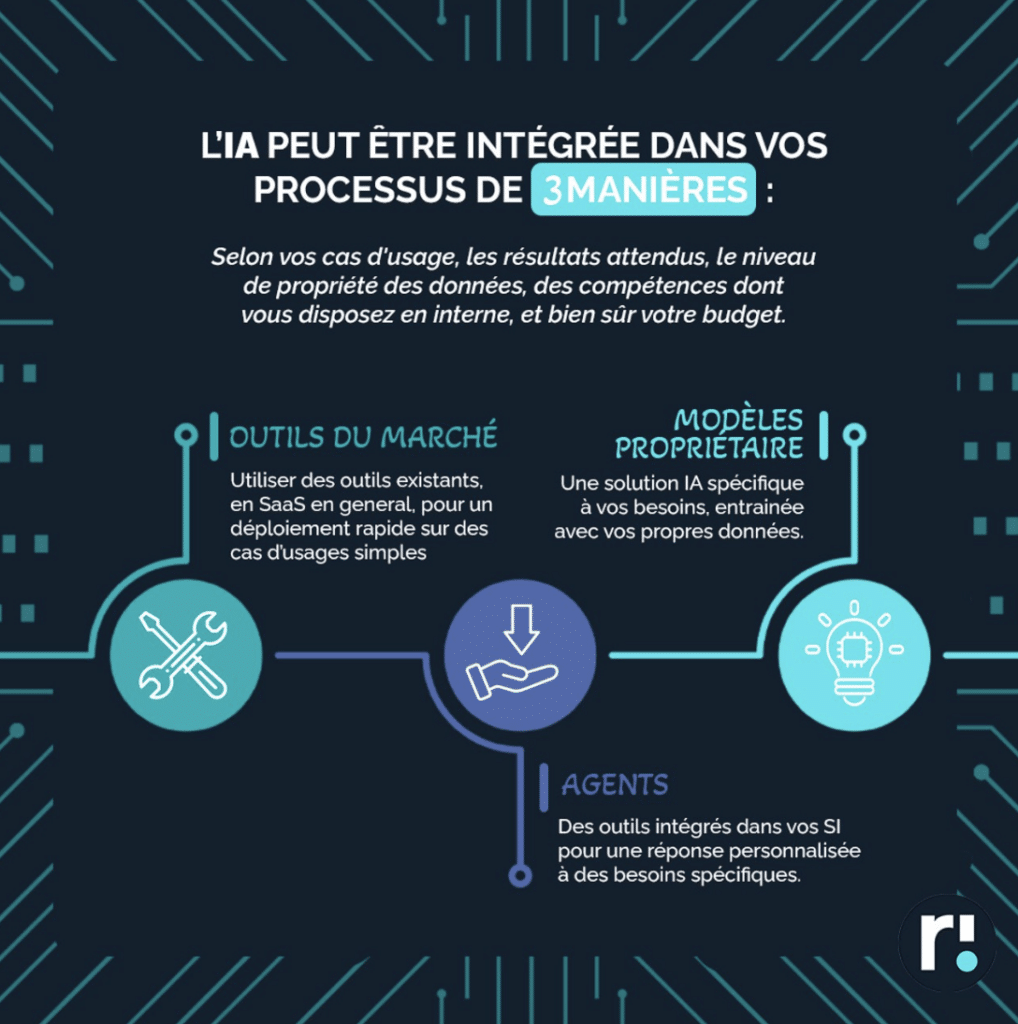
Chez Rhapsodies Conseil, nous vous accompagnons à chaque étape pour maximiser votre potentiel IA.
Notre expertise vous propose trois approches pour tirer parti de l’IA : des outils préexistants, des agents personnalisés ou des modèles sur mesure. Chaque solution s’adapte à vos besoins, budget et ressources internes.
Vous souhaitez en savoir plus ? 🔍
Parlons de votre projet IA et découvrez comment Rhapsodies Conseil peut transformer vos idées en actions concrètes.
D’autres sujets d’expertise qui pourraient vous intéresser
10 février 2025
Pilotage & Performance Opérationnelle et Contractuelle