Au sein de DSI, les équipes de la Digital Factory de notre client (secteur des transports) accompagnent les grands domaines métiers du Groupe en leur fournissant des systèmes d’information performants (développement spécifique ou intégration de SaaS / Progiciels). Dans le cadre du programme Numérique Responsable Groupe, elle souhaiterait monter en compétence sur une conception plus vertueuse des services numériques.
Mission
La mission consiste à :
Sensibiliser et former aux bonnes pratiques : Onboardings, Webinaires, Fresques du Numérique, Fresque de l’Accessibilité
Accompagner à l’évolution des modèles de delivery de la Digital Factory
Accompagner les équipes projets et leads de practice transverses (Tech, Design, Produit, etc.) dans le suivi des indicateurs Numérique Responsable et l’amélioration continue des outils (Design System, Framework Dev, Component Factory, etc.)
Mise en place de solution de pilotage de la mesure et de bonnes pratiques sur la conception responsable
Accompagner les équipes techniques : DevOps, Architecte Technique / Solution dans la prise en compte des bonnes pratiques d’éco-conception
Résultats
Boîte à outils pour une conception plus responsable (référentiels, ressources, outils, etc.)
Diagnostic environnemental & social des services numériques produits par la Digital Factory
Accompagnement d’une trentaine de projets sur l’année 2024 avec un score d’éco-conception (Éco-index) d’en moyenne B et un score d’accessibilité de 90 sur Lighthouse.
Autres Success Stories qui pourraient vous intéresser
Notre client, issu du secteur touristique, souhaite proposer à ces visiteurs une expérience de construction de séjour bas carbone. Ce client a très à coeur d’innover sur ces sujets et ces indicateurs qui sont aussi de plus en plus regardés par les clients finaux. Par ailleurs, renforcer le positionnement d’un tourisme durable ouvre des potentiels de recrutement de nouvelles clientèle engagées. Afin que l’offre soit la plus riche possible, les acteurs du tourisme de la ville ont besoin d’outils pour évaluer leur bilan carbone et leur maturité dans les pratiques durables. C’était le principal enjeu de notre mission.
Mission
La mission consiste à :
Embarquer les parties prenantes du tourisme de la ville dans les enjeux de durabilité afin de les convaincre d’adhérer au projet porté par l’Office de Tourisme : mettre en avant les acteurs engagés dans un séjour bas carbone
Construire les calculettes et leurs méthodologies de mesure d’empreinte carbone des acteurs du tourisme (restauration, hébergements, activités de loisirs comme le sport, la culture, les événements)
Pré-tester les méthodologies et les calculettes afin de recueillir les problématiques et les freins au remplissage
Valider les prototypes pour aboutir à des outils finaux pour implémentation chez les acteurs du tourisme
Rédiger un cahier des charges amenant au développement d’une solution numérique qui valorise les acteurs du tourisme à faible empreinte carbone, permettant aux utilisateurs finaux d’organiser leur séjour à faible impact selon leurs choix
Sensibiliser les acteurs du tourisme dans la mise en place de futures feuilles de route
Résultats
Un outil auto-diagnostic permettant de calculer les bilans carbone “simplifiés” des acteurs de la restauration, de l’hébergement et des activités de loisirs (sport, culture, événements), accompagnés de leurs guides méthodologiques.
Un outil auto-diagnostic permettant d’estimer les niveaux d’engagement des établissements dans leur pratiques durables (restaurants, hébergements et activités de loisirs), accompagnés de leurs guides méthodologiques.
Des parties prenantes responsabilisées sur la mise en œuvre de ces outils et dans leur utilisation (Office de tourisme, acteurs du tourisme, CCI, agents municipaux..)
Notre client du secteur bancaire souhaite construire le socle d’un chantier de transformation Numérique Responsable au sein de sa DSI. Ce chantier s’inscrit également dans la labellisation NR de la filière SI Groupe qui rend le contexte d’autant plus favorable.Les enjeux de la mission se trouve dans l’alignement stratégique entre filière SI Groupe et filière SI BDT, la mobilisation des parties prenantes pour faciliter l’adoption des pratiques NR, des résultats tangibles pour montrer rapidement des impacts concrets, l’optimisation des ressources pour promouvoir l’écoconception comme un levier frugal tant sur le volet économique qu’écologique, et enfin, la structuration organisationnelle pour s’intégrer dans les processus et gouvernances existants afin de pérenniser l’initiative.
Missions
La mission se divise en 4 axes :
Axe 1 : Stratégie NR Construire les ambitions et les objectifs NR de la filière SI BDT et embarquer les parties prenantes clés dans la définition de ces ambitions
Axe 2 : Construction et déploiement du cadre d’éco-conception Élaborer un cadre d’éco-conception pragmatique adapté aux méthodologies actuelles et le tester puis l’affiner sur deux projets pilotes
Axe 3 : Sensibilisation & Formation Former les acteurs opérationnelles des projets pilotes aux bonnes pratiques d’éco-conception dans les projets IT
Axe 4 : Organisation & Gouvernance Intégrer l’éco-conception by-design dans les gouvernances existantes, proposer des principes organisationnels et mettre en place une gouvernance pour le suivi et la pérennisation des actions NR tout en suivant le chantier de labellisation NR de la filière SI Groupe.
Résultats et bénéfices
Mission en cours, livrables identifiés :
Axe 1 : Audit de l’existant, Ambitions & objectifs NR, supports de présentations et constitution d’une Core Team
Axe 2 : Cadre d’éco-conception, Expression de besoin pour de l’outillage transverse NR et synthèses d’ateliers de travail
Axe 3 : Séminaires NR, Sessions de formations (+ supports), Plan & Besoin de formation NR sur 2026
Axe 4 : Animations de COMOP, éléments NR intégrés au processus de gouvernance SI BDT, livrables de labellisation NR
Participez à notre événement Sobriété Numérique avec Axa et la STIME
Suite aux travaux que nous avons menés dans notre livre blanc “Continuum de la sobriété numérique”, nous vous invitons à une table ronde exceptionnelle pour parler sobriété avec des intervenants engagés sur ces sujets. Ces derniers seront invités à partager et à débattre autour de ces questions essentielles :
Quel est le rôle de la sensibilisation et de la formation?
Comment mettre le “marketing” et ses techniques au service de la sobriété ?
Peut-on vraiment réussir sa transformation “Numérique Durable et Responsable” sans imposer des vraies contraintes (sur les volumes de données, les consommations, quotas…) ?
Comment sortir de l’impasse d’un système numérique en accélération permanente (5G, 6G, NG, GenAI, Metaverse, ….) ?
Et à l’inverse, comment percevoir les signes positifs apparents en ce moment (Montée en puissance des fresques du numérique, CSRD, …).
Sont-ils suffisants pour marquer le début d’une bascule ?
Quelles actions concrètes dans les organisations pour accélérer la sobriété du système d’information ?
Rhapsodies Conseil vous invite le mardi 24 septembre à 8h30 à un événement éco-conçu, engagé et responsable au centvingtseptbypixelis avec le traiteur meetmymama.
Notre table ronde sera animée par Rémy Marrone, Journaliste Indépendant en Marketing et Numérique Responsable, en présence d’invités exceptionnels :
Alexandra Bouet-Rochard, Responsable ESG – IT & Opérations Services au sein de Crédit Agricole – CIB
Céline Lescop, Lead Digital Sustainability & Data Architect au sein de AXA Group et Membre du groupe de travail à The Shift Project
Emmanuelle Bravard‑Sarraz, Directrice Communication et RSE à la STIME – DSI Les Mousquetaires
Gilles Juan, auteur indépendant de livres et documentaires, consultant en ingénierie pédagogique,
Mathieu Bourgeois Avocat associé – Immatériel & Numérique chez Klein & Wenner et Membre fondateur du Cercle de la Donnée
Jean-Baptiste Piccirillo, Senior Manager en charge de l’expertise Numérique Durable au sein de Rhapsodies Conseil, auteur de “Continuum de la sobriété”
Olivier Marchand, Team Leader Numérique Durable chez Rhapsodies Conseil
Rythmée, cette table ronde sera l’occasion pour nos intervenants de vous faire part de leurs retours d’expériences, de partager leur vision et leurs questionnements, et enfin d’aborder les actions concrètes qu’ils ont mis en place dans leurs organisations autour de ces enjeux.
A cette occasion, nous vous remettrons un exemplaire du livre-blanc « Continuum de la sobriété numérique ». Merci de confirmer votre participation pour que nous puissions assurer votre place !
On profite du nouveau plan d’intéressement de RC et des choix de supports financiers dans lesquels vous allez pouvoir investir votre épargne salariale, pour vous parler de l’épargne responsable.
Le saviez-vous ?
La première empreinte carbone individuelle, sans qu’on le sache, c’est notre compte en banque. Notre argent n’est pas du tout neutre vis-à-vis du climat.
Quand l’empreinte carbone annuelle moyenne d’un Français en 2020 est de 11,2 tonnes équivalent CO2 (eqCO2) par an, celle de son épargne grimperait à 16 tonnes eqCO2 par an pour 25.000 euros placés à la Société Générale,15 tonnes eqCO2 chez BNP Paribas, 11 tonnes au Crédit Agricole… contre 8,8 tonnes à La Banque Postale, calcule Oxfam.
Choisir une banque plus responsable peut donc être une action, placer son épargne salariale de façon plus responsable en constitue une autre.
Alors c’est quoi l’épargne responsable et pourquoi ?
L’épargne responsable a pour objectif d’allier à la fois le rendement financier et l’impact positif sur la société et/ou l’environnement, en prenant en compte des critères « extra-financiers » pour sélectionner les entreprises dans lesquelles investir. On les appelle « critères ESG ».
Cette approche permet de mieux comprendre les stratégies des entreprises sur le long terme et de mesurer leur capacité à faire face aux grands enjeux de société présents et à venir. Autrement dit, les risques et opportunités sont identifiés de façon plus exhaustive. Cette même approche est appliquée aux obligations des États et des collectivités publiques.
La recherche de performance et l’épargne responsable sont parfaitement compatibles : les études académiques montrent que statistiquement l’épargne responsable est, au moins, aussi performante que celle sans critères ESG.
Concrètement comment faire ?
Vous entendez parler d’ISR, d’ESG, d’éthique, de bas carbone, de supports verts… Comment s’y retrouver ?
Investir dans des fonds responsables
Il existe un certain nombre de pratiques et de labels qui vous permettent de savoir si le produit d’épargne ou les supports que vous choisissez ont un objectif responsable ou intégrent des critères ESG :
En examinant la documentation pré-contractuelle (DIC document d’informations clés) fournie par votre conseiller, vous pouvez :
– Consulter la liste des supports disponibles qui soutiennent des causes environnementales et sociales, ou qui ont pour objectif l’investissement durable.
– Vérifier les stratégies d’investissement décrites dans ce document :
Bien qu’il existe plusieurs stratégies, 3 stratégies se distinguent des autres.
Les stratégies dites « Best » consistent à sélectionner les entreprises les mieux notées selon les critères ESG. On en trouve 3 variantes en fonction des secteurs d’activité concernés et de l’évolution de la prise en compte des critères ESG par les entreprises qui composent le fonds
Les stratégies d’exclusion désignentle fait d’exclure par principe certaines sociétés parce que leur chiffre d’affaires provient d’activités considérées comme néfastes pour la société ou contraire à l’éthique (par exemple le tabac, les jeux d’argent), ou parce qu’elles ne respectent pas certaines normes internationales (par exemple la Déclaration universelle des droits de l’homme)
Les approches thématiques consistent, elles, à identifier les entreprises de secteurs d’activité précis liés au développement durable ou à la transition énergétique. Par exemple la gestion de l’eau, l’alimentation durable, etc.
– Vous aider des informations réglementaires :
Règlement SFDR : Depuis 2021, la réglementation européenne permet d’identifier les fonds qui ont des critères ESG.
Les institutions financières (banques, assurances, sociétés de gestion) doivent désormais classer leurs fonds en fonction de différents critères. L’objectif est de fournir des informations claires et comparables sur la durabilité de leurs fonds, selon la classification suivante :
Règlement Taxonomie Verte Européenne : Cette réglementation classe les activités économiques considérées durables selon 6 grands objectifs et des principes. Un % d’alignement à la taxonomie verte indique à quel point le placement peut être considéré comme durable.
En consultant les labels accordés par des organismes indépendants, vous pouvez vérifier que le support répond à certains critères de financement d’activités responsables :
Les différents labels français
– Le label ISR : Créé par l’État français, le label Investissement Socialement Responsable identifie les fonds intégrant une dimension responsable dans la gestion de leurs investissements. Cette dimension responsable englobe la prise en compte de critères ESG dans le processus d’investissement.
– Le label Relance : Mis en place par l’État français suite à la crise liée à la pandémie de Covid-19, le label Relance répond aux besoins de financement des entreprises françaises en mobilisant l’épargne pour relancer l’économie, tout en respectant des critères ESG.
– Finansol : Attribué par l’association FAIR, le label Finansol vise à promouvoir les fonds adoptant une démarche solidaire et inclusive, notamment en soutenant l’insertion, le logement social et le commerce équitable.
– Greenfin : Créé par l’État français en faveur de la transition énergétique et écologique, le label Greenfin assure la qualité écologique des fonds d’investissement.
Investir directement dans des entreprises ou des projets
Si vous souhaitez épargner de façon responsable, vous n’êtes pas obligés d’investir au travers d’un fonds. Vous pouvez aussi sélectionner vous-même des actions d’entreprises en fonction des informations extra-financières disponibles. Certaines sociétés ont même l’obligation de publier ce type d’informations au travers de la déclaration de performance extra-financière (DPEF)
Quels sont les bons réflexes pour investir de façon responsable ?
Avant de se lancer dans l’investissement responsable, il est important de s’interroger de la même manière que pour un investissement classique (objectif, durée de placement, épargne de précaution, frais, etc.).
Et n’hésitez pas à questionner votre conseiller bancaire ou d’épargne pour en savoir plus sur l’épargne responsable.
Afin de vous aider votre dans votre prise de décision, vous pouvez consulter ces ressources complémentaires :
– Connaître l’empreinte écologique de votre épargne https://agirpourlatransition.ademe.fr/particuliers/finances/finance-durable/rift-outil-pour-connaitre-impact-ecologique-epargne
Les premiers pas pour diminuer l’empreinte environnementale de votre SI
Vous travaillez sur la réduction de l’empreinte carbone de votre SI ?
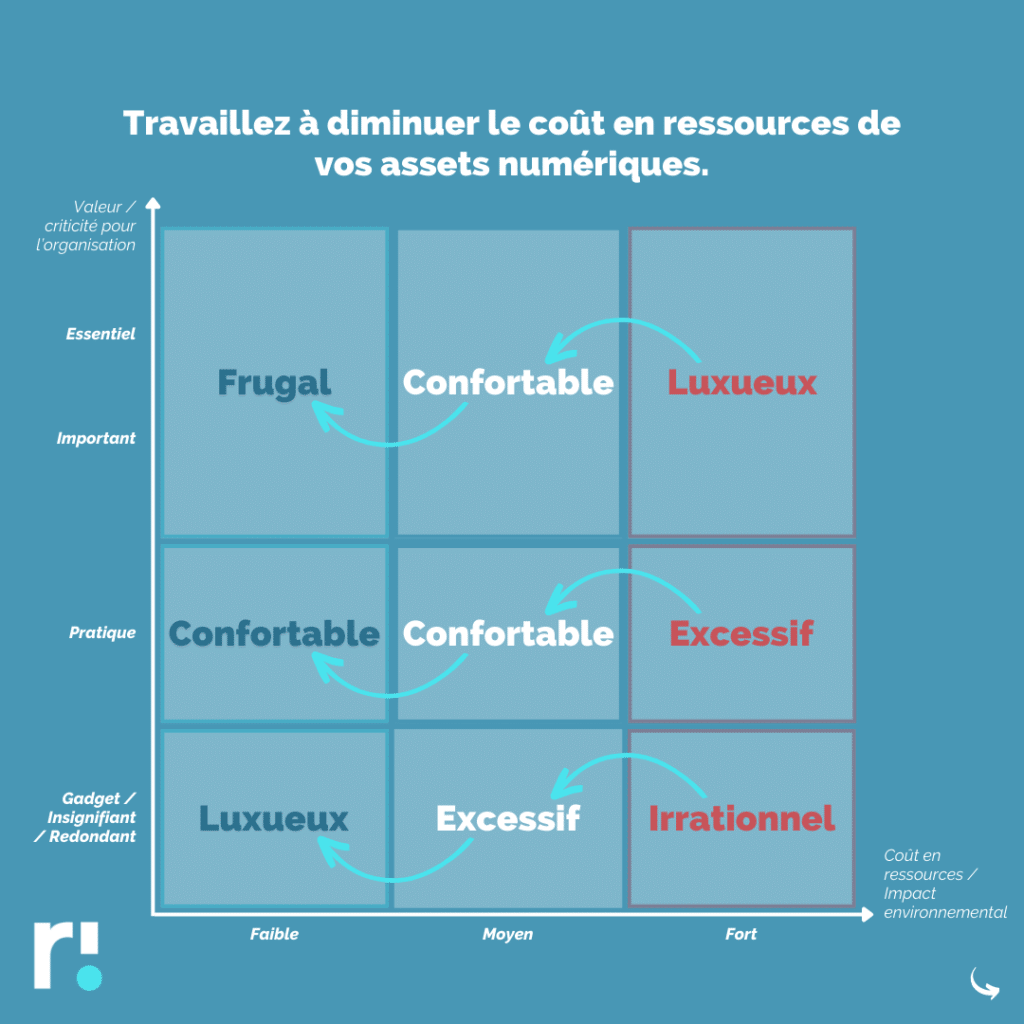
Les deux axes clés de réduction sont la Sobriété et l’Optimisation
Notre matrice propose un cadre pour construire une vision claire sur l’équilibre entre la valeur pour votre organisation et l’impact environnemental de vos assets numériques (services IT, applications, composants d’infrastructures, …)
L’Optimisation
Elle permet certes de réduire dans certains cas l’empreinte environnementale / carbone
Mais il faut prendre garde qu’elle ne mène pas vers plus d’effets rebonds : « Comme c’est plus efficace, et plus bas carbone, alors on peut en rajouter tant qu’on veut ! »
Non !
Il faut donc être proactif pour travailler l’élimination et l’évitement du superflu en continu.
C’est le deuxième axe.
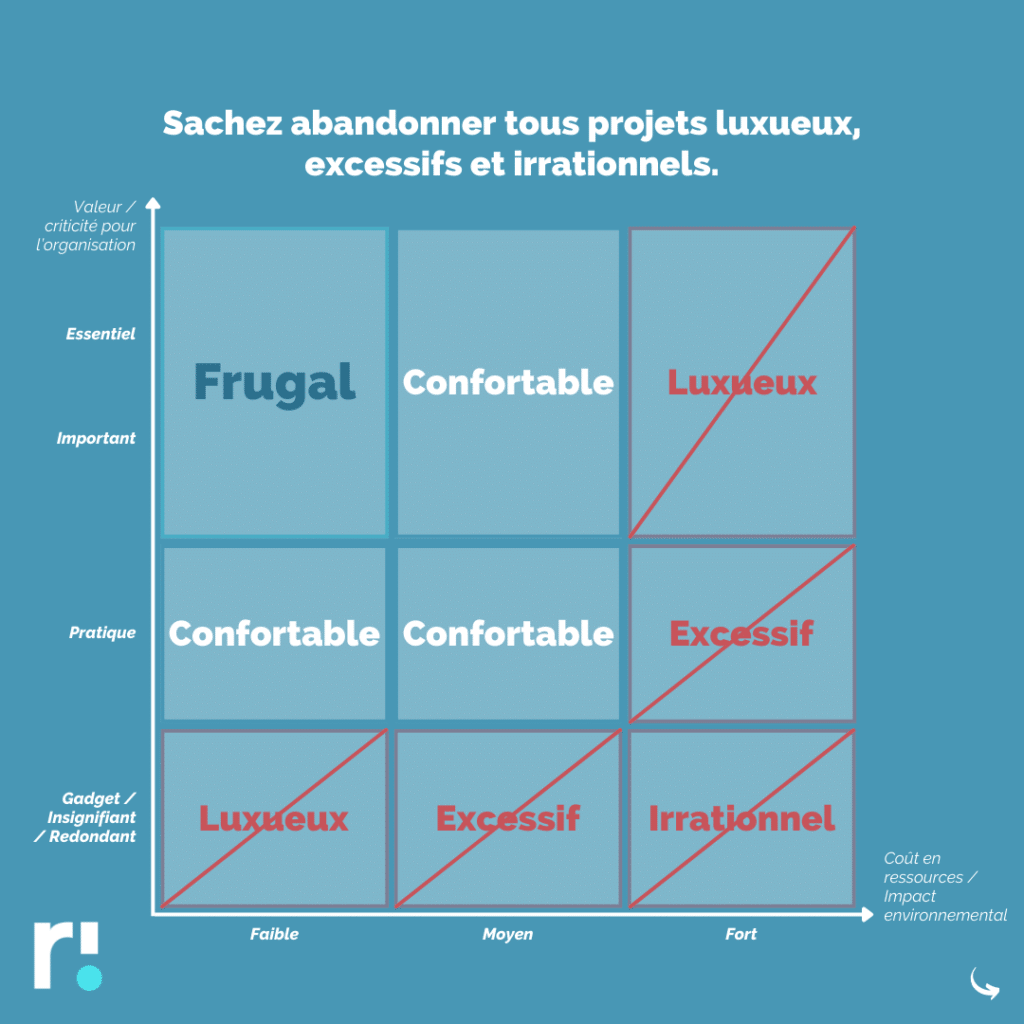
La Sobriété
Sachez abandonner tous assets et projets Luxueux, Excessifs, Superflus, voire parfois Irrationnels…
Nous partagerons régulièrement dans les prochaines semaines des leviers et exemples concrets autour des axes de Sobriété et d’Optimisation