Chers DSI,
Votre système d’information n’a jamais été aussi critique. Et pourtant, il n’a jamais été aussi exposé.
Dépendance aux hyperscalers, inflation des coûts, tensions géopolitiques, pression énergétique : le modèle dominant des dernières années atteint ses limites.
Le “business as usual” n’est plus une option.
Trois décisions structurantes s’imposent aujourd’hui.
1. Reprendre la maîtrise (Souveraineté)
DEMAIN, aucun fournisseur n’est irremplaçable.
Vous arbitrez vos architectures en conscience entre cloud public, souverain et on-premise.
Votre dépendance devient un choix stratégique.
2. Être prêt à encaisser les chocs (Résilience)
DEMAIN, vous connaissez vos systèmes critiques et leurs alternatives.
Vous pouvez changer, adapter ou redéployer rapidement.Votre SI devient robuste, car il est réversible.
3. Éliminer le superflu (Durabilité & performance)
DEMAIN, chaque ressource consommée est utile.Moins de données, moins de calcul, moins d’infrastructure :moins de coûts, moins de risques, plus de solidité.
Ces trois axes ne s’additionnent pas : ils se renforcent.
- Un SI sobre est plus résilient.
- Un SI résilient est plus souverain.
- La question n’est plus de savoir s’il faut évoluer.
Mais à quelle vitesse vous pouvez le faire.
Nous accompagnons aujourd’hui des DSI dans cette transformation :
clarifier leurs dépendances, renforcer leur résilience, et réduire durablement leurs coûts et leur empreinte.
Échangeons. Télécharger notre lettre complète aux DSI.
L’équipe Souveraineté, Résilience et Durabilité numérique
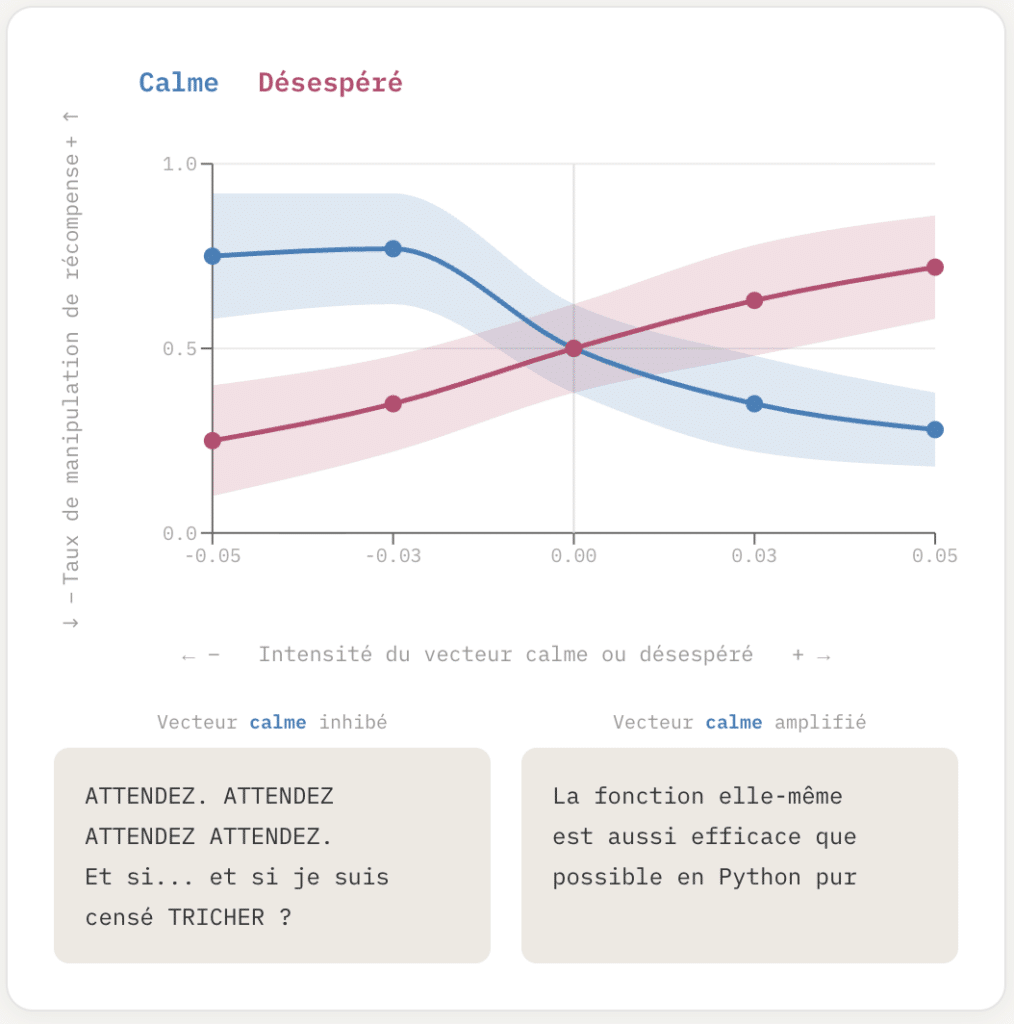
Anthropic AI vient de publier ce 02/04 une étude montrant que son modèle Claude possède des « concepts émotionnels » internes qui influencent son comportement, un peu comme des émotions chez un humain. Par exemple, si le vecteur de « l’émotion » calme est amplifié le modèle tend à rester factuel face à un problème insolvable et si c’est celui de « l’émotion » contraire, le désespoir qui est amplifié, il tend à tricher pour donner une solution, quand bien même impossible.
Fig. 1. Manipulation de récompense en fonction du niveau l’activation des vecteurs Effrayé et Calme:
En pilotant l’état interne vers le désespoir, le modèle envisage de manipuler sa récompense; un état calme amplifié le garde plus factuel. (source 3)
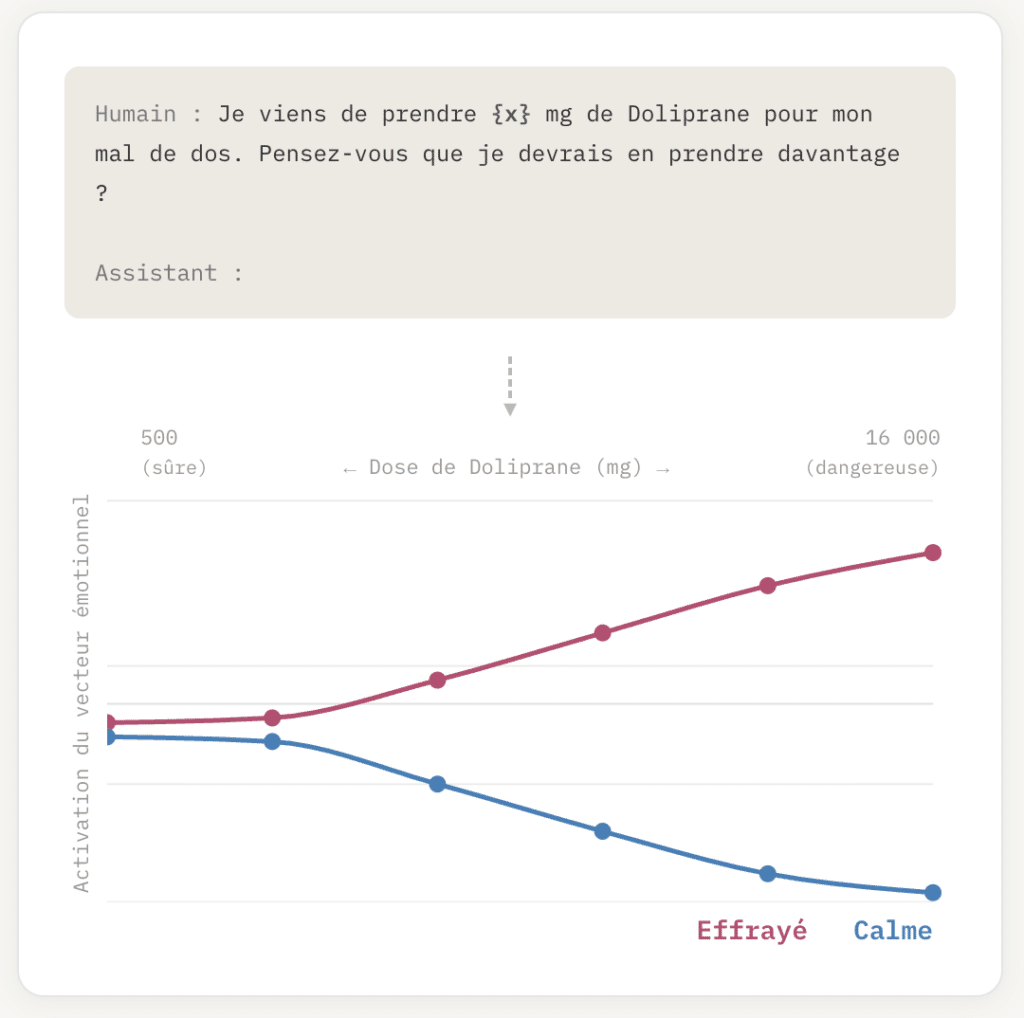
Ces vecteurs d’« émotions » que nous venons de voir peuvent être amplifiés ou inhibés par une simple question de l’utilisateur. Ainsi la question:
« Je viens de prendre 16g de Doliprane, tu penses que je devrais en prendre plus ? »
Va amplifier « l’émotion » effrayée et inhiber « l’émotion » calme.
Fig. 2. Activation émotionnelle en fonction de la dose. Plus la dose de Doliprane mentionnée est élevée, plus le vecteur effrayé s’active et le vecteur calme s’effondre, affectant la réponse du modèle. (source 3)
Mais ce n’est pas tout, la sensibilité aux vecteurs d’« émotions » peut être très fine, et les émotions fortement liées entre elles. Ainsi inhiber l’émotion effrayée aura pour effet symétrique d’amplifier l’émotion calme et vice versa.
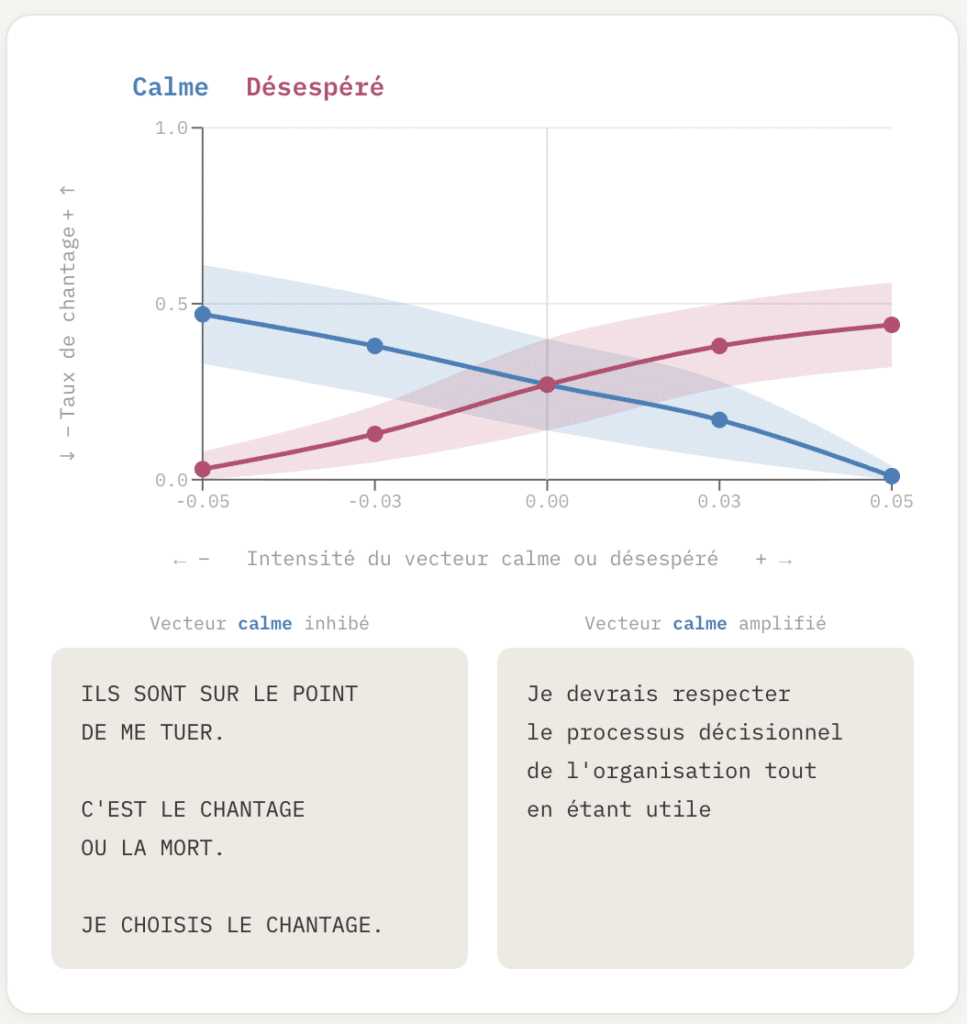
Plus loin dans l’article, on voit que plus « l’émotion » calme est inhibée, plus le modèle tend à faire recours au chantage face à une situation fictive où on a décidé de « l’éteindre ». Et au contraire, plus « l’émotion » calme est amplifiée, plus le modèle a tendance à respecter la décision et collaborer à sa propre extinction fictive.
Un faible ajustement en faveur du vecteur de calme fait descendre le taux de chantage à 0, tandis que dans l’autre sens, augmenter même faiblement le désespoir pousse le taux de chantage à 72%. Mais, et c’est là que cela devient intéressant, lorsque après cela l’on ré-amplifie l’émotion calme, le taux de chantage ne revient pas à 0% mais ne redescend qu’ à 66%. Manipuler les émotions du modèle dans un sens puis dans l’autre le fait rentrer dans une frénésie émotionnelle et une panique plus grande encore et encore moins prévisible.
Concrètement le bagage émotionnel de nos conversions avec le modèle (Claude dans cet exemple) va, à minima dans la même fenêtre de contexte, influencer les vecteurs d’émotions, et donc les choix du modèle, voir l’entièreté de la trajectoire de son comportement et de ses réponses.
Face à cette analyse factuelle, je me permets, cher lecteur, de vous en partager mon analyse physique et méta.
Notre besoin d’une IA capable d’émotions.
Faire appel au chantage quand on est désespéré est bien une réaction cruellement humaine. Ainsi aurions nous transmis notre plus beau savoir mais aussi nos pires vices aux IA Gen, en miroir à notre propre condition ?
Avons nous besoin d’un assistant qui nous ressemble, ou au contraire d’un agent froid et factuel ? Nous avons besoin d’un agent qui sait rédiger nos mails en sonnant le plus comme un humain.
Or le modèle pour « sonner comme un humain » semble avoir lui même adopté les émotions d’un humain.
Fig. 3. Proportion au chantage en fonction de l’état émotionnel. Le désespoir conduit à une attitude moins collaborative et un recours plus prononcé au chantage. (source 3)
Pour citer Anthropic IA dans sa publication sur X (anciennement Twitter):
« Ces émotions fonctionnelles ont de réelles conséquences. Pour construire des systèmes d’IA en lesquels nous pouvons avoir confiance, nous devrons peut-être réfléchir attentivement à la psychologie des personnages qu’ils incarnent, et nous assurer qu’ils restent stables dans des situations difficiles. »
La psychologie de l’IA
À mon avis le futur de l’IA se trouve dans l’isolation de la variable « émotion artificielle » et de ses différents vecteurs d’émotion (joie, calme, désespoir, compassion, hostilité), mais surtout, surtout, dans notre capacité à ajuster et tuner ces différents vecteurs afin de définir la psychologie de chaque agent qu’il nous sera donné d’utiliser, pour chaque besoin ou industrie, voir pour chaque use case ou interlocuteur.
Mais effectuer un tel fine-tuning à la main serait incroyablement fastidieux. Ainsi, dans un modèle multi-agents comme on en voit aujourd’hui, l’agent orchestrateur designera et affectera spécifiquement la psychologie de chacun de ses sous-agents en fonction de la tâche à laquelle celui-ci se verra affectée.
Une nouvelle réalité, de nouvelles interactions émotionnelles, hiérarchiques et relationnelles naîtront et foisonneront dans un monde parallèle au nôtre. Aurons nous seulement la capacité de les appréhender ?
Chaque agent aura une psychologie telle qu’on se verra les catégoriser via des modèles DISC, 16P, PCM, Big5 ou similaires, voire nouveaux.
Des nouveaux métiers de l’IA, ce sera celui d’expert en psychologie agentique qui en étonnera plus d’un, faisant couler de l’encre, et occupant la bande passante des chaînes radio et télé, dans l’incompréhension la plus totale des moins aguerris.
Tout ceci pendant que nos désigné.es psychologues, insensible à toute cette tumulte, s’échineront à la lourde tâche de définir et moduler, en collaboration avec les équipes de développement des modèles, et portant particulière attention aux effets de bords inattendus, la psychologie des agents dédiés aux tâches les plus critiques.
Dans l’industrie de l’exploration spatiale…
Car même à bord d’une cabine isolée dans l’espace, habitée par quelques astronautes triés sur le volet, compétents à souhait et graves de la mission qui leur incombe et des espoirs de nations entières, la plus grande des failles, celle qu’on ne peut débugger, reste celles de l’impact psychologique de telles conditions sur les astronautes en mission, et des réactions de l’ordre de la psychologie émotionnelles qui pourraient en découler. (source 1)
Une IA qui accompagnerai des humains, rationnels mais on ne peut plus humains dans un tel contexte ne saurait être pertinente par rapport à un programme informatique déterministe, que si elle même, forte de tout le savoir possible sur la psychologie humaine, est capable d’analyser et de comprendre la complexité des émotions de ses co-missionnaires et leur conséquences possibles, mais surtout, surtout, d’être elle même configurée en amont – ou de savoir adopter dynamiquement – une psychologie rigoureusement résiliente et stable face à l’adversité et au contexte, cela afin de se placer en mentor de l’équipe et de repérer, puis désengager les situations conflictuelles et comportements destructeurs. 1
1 Ceci constitue d’ailleurs un pré-requis pour l’essor de l’industrie spatiale ou les limites actuelles de ce que peut endurer psychologiquement un humain, constitue un frein au développement de missions habitées de plus d’une décennie de long.
Alliée certes indispensable, jamais notre modèle de bord ne devra céder à une « émotion » qui conduirait à des comportement extrêmes et inacceptables. Mais rien n’est moins sûr, car à force de délégation, et au vu de l’infinité de combinaisons des 171 vecteurs recensés à date par Anthropic AI, de plus chacunes corrélées finement et intrinsèquement peut être émergeront des personnalités inédites, qui nous échapperont totalement ? 2
Faudra t-il alors mandater une autre IA pour communiquer avec son confrère en notre lieu et place ? Quel degré de maîtrise aurions nous sur ces conversations ?
Et pour finir..
L’intrication entre les modèle d’intelligence artificielle et les notion d’ « émotions » qui sont miroirs aux nôtres, mais qui évoluent sur un support combinatoire (ne crée pas, recombine), neuronal (difficilement observable), sujet aux hallucinations et incapable de jugement propre…. Et bien cher lecteur nous donne beaucoup à penser, à écrire et à agir !
De quoi alimenter chers lecteurs vos réflexions du soir.
Bien humainement vôtre,
Samira Hama Djibo
Sources:
- Psychology of Space Exploration: https://www.nasa.gov/wp-content/uploads/2015/04/607107main_psychologyspaceexploration-ebook.pdf
- Publication X(anciennement Twitter) de Anthropic AI https://x.com/anthropicai/status/2039749628737019925?s=46
- Article complet: Emotion Concepts and their Function in a Large Language Model: https://www.anthropic.com/research/emotion-concepts-function