#2 DÉFINIR POURQUOI L’ARCHITECTURE MACH S’ADAPTE BIEN À L’ECOMMERCE
#2 DÉFINIR POURQUOI L’ARCHITECTURE MACH S’ADAPTE BIEN À L'E COMMERCE
3 juin 2024
Architecture
Erik Zanga
Manager Architecture
L’architecture MACH convient-elle à tous les métiers et cas d’usages, ou existe-t-il des situations où elle est plus avantageuse et d’autres où elle est moins adaptée ?
Pour répondre à cette question nous allons à nouveau décomposer ce style d’architecture dans ses 4 briques essentielles : Microservices, API First, Cloud First et Headless.
La lettre M : Micro-services
C’est probablement ce premier point qui dirige notre choix de partir vers une architecture MACH vs aller chercher ailleurs.
Nous pourrions presque dire que si l’architecture s’adapte à un découpage en Micro-services, le MACH est servi.
Pour aller un peu plus dans le détail, nous allons introduire le concept de “point de bascule” dans le parcours utilisateur. Nous définissons “point de bascule”, dans un processus, chaque étape qui permet de passer d’une donnée à une autre, ou d’un cycle de vie de la donnée à une autre.
Une première analyse pour comprendre si notre architecture s’adapte ou pas à une architecture MACH, est d’établir si dans le parcours utilisateur nous pouvons introduire ces points de bascule, qui permettent de découper l’architecture des front-end et back-end en micro front-end et micro-services.
Un processus eCommerce par exemple s’adapte bien à ce type de raisonnement. Les étapes sont souvent découpée en :
Recherche dans le catalogue
Mise en panier
Confirmation
Paiement
Gestion de la livraison
Ces 5 étapes traitent les données de façon séparée, et sont donc adaptées à un découpage en Micro-services.
Résultat : Le “M” de MACH et l’efficacité de cette architecture est fortement liée au cas d’usage et au domaine d’application.
La lettre A : API-First
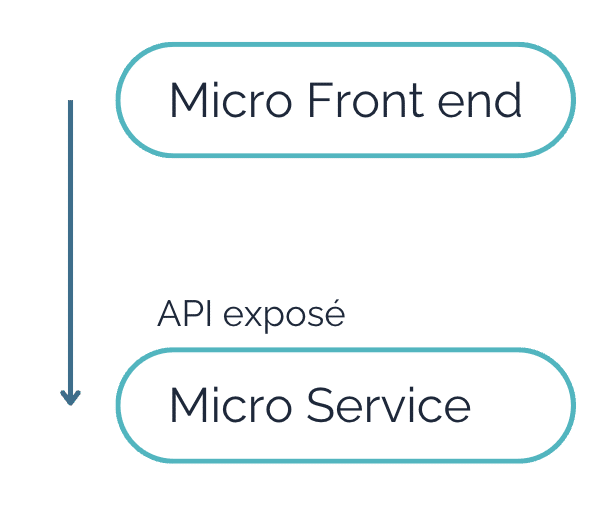
Qui parle web a forcément dû penser aux APIs, dans le sens de Rest API, pour garantir la communication entre front-end et back-end.
Pas de surprise que cela s’adapte à pas mal de solutions, car la communication entre le front-end (navigateur) et le back-end (application) se base sur le protocole HTTP et donc très adapté à ce type d’interface.
Nous ajoutons à tout ça le fait que la création d’un Micro-services et d’un Micro front-end, avec un découpage vertical sur les données traitées, implique naturellement la mise en place d’APIs et ressources spécifiques à chaque étape du parcours client.
Le contexte eCommerce, encore une fois, est bien adapté à ce cas de figure. Les étapes de parcours dont nous avons parlé avant s’inscrivent dans une logique d’APIsation, avec pour chacune d’entre elles une API dédiée.
Recherche dans le catalogue : adresser une API produits
Mise en panier : adresser une API panier ou devis
Confirmation : adresser une API commande
Paiement : adresser les APIs de paiement d’un prestataire (PSP, orchéstrateur de paiement, etc.)
Gestion de la livraison : adresser une API livraison
Résultat : Le “A” de MACH impacte moins que le “M” dans le choix de l’architecture mais épouse bien les concepts définis dans le “M”. Il est donc également très approprié pour un contexte eCommerce.
Pexels – ThisIsEngineering
La lettre “C” : Cloud-Native
Ce cas est probablement le plus simple : les seules raisons qui nous poussent à rester chez soi (infrastructure on premise), à ne pas s’ouvrir au cloud aujourd’hui sont de l’ordre de la sécurité, de l’accès et de la confidentialité de nos données (éviter le Cloud Act, etc.).
Au-delà de ces considérations, le passage au Cloud est une décision d’entreprise plus dans une optique d’optimisation de l’infrastructure que dans le cadre d’un cas d’usage, de processus spécifiques.
Résultat : Le “C” de MACH n’est pas d’un point de vue architectural pure une variante forte.
Néanmoins si nous regardons le cas d’usage cité auparavant, eCommerce, les restrictions sont levées car qui parle eCommerce parle naturellement d’ouverture, de mise à disposition sur le web, d’élasticité, concepts bien adaptés au contexte Cloud.
La lettre “H” : Headless
L’approche Headless convient particulièrement aux entreprises qui recherchent une personnalisation poussée de l’expérience utilisateur et qui ont la capacité de gérer plusieurs interfaces utilisateur en parallèle.
C’est le cas pour du eCommerce, où l’évolution rapide, le time to market et la réactivité au changements du marché peuvent influencer l’appétence, le ciblage du besoin client et le taux de conversion.
Résultat : Le « H » de MACH souligne l’importance de l’expérience utilisateur et de la flexibilité dans la conception des interfaces. Il est particulièrement avantageux dans les contextes où la personnalisation et l’innovation de l’interface utilisateur sont prioritaires. Cependant, il nécessite une réflexion stratégique sur la gestion des ressources et des compétences au sein de l’équipe de développement.
En somme, l’architecture MACH offre une grande flexibilité, évolutivité, et permet une innovation rapide, ce qui la rend particulièrement adaptée aux entreprises qui évoluent dans des environnements dynamiques et qui ont besoin de s’adapter rapidement aux changements du marché. Les secteurs tels que l’e-commerce, les services financiers, et les médias, où les besoins en personnalisation et en évolutivité sont élevés, peuvent particulièrement bénéficier de cette approche.
Cependant, l’adoption de l’architecture MACH peut représenter un défi pour les organisations avec des contraintes fortes en termes de sécurité et de confidentialité des données, ou pour celles qui n’ont pas la structure ou la culture nécessaires pour gérer la complexité d’un écosystème distribué. De même, pour les projets plus petits ou moins complexes, l’approche traditionnelle monolithique pourrait s’avérer plus simple et plus économique à gérer.
En définitive, la décision d’adopter une architecture MACH doit être prise après une évaluation minutieuse des besoins spécifiques de l’entreprise, de ses capacités techniques, et de ses objectifs à long terme.
Articles qui pourraient vous intéresser
#1 DÉFINIR RAPIDEMENT L’ARCHITECTURE MACH ET POURQUOI ON EN PARLE
#1 DÉFINIR RAPIDEMENT L’ARCHITECTURE MACH ET POURQUOI ON EN PARLE
L’architecture MACH, de par son acronyme, regroupe quatre pratiques courantes et actuelles dans le développement d’applications web.
C’est quoi Architecture MACH ?
Dans ce premier volet, nous allons nous concentrer sur les concepts fondamentaux qui composent ce concept : Microservices, API First, Cloud First, Headless, afin d’adresser l’objectif de chacun.
Tout d’abord un avis personnel, le fait de mettre ces concepts ensemble découle du bon sens : ce type d’architecture est considéré comme simple, efficace, intuitive, bien structurée, modularisée, bref… un travail que les vrais architectes doivent forcément apprécier !
Quid d’Amazon annonçant faire marche arrière pour Prime Video car la mise en application des micro-services implique un nombre d’orchestrations élevées ?
Les Micro-services, tels qu’expliqués dans d’autres articles (voir article micro-services), sont dans notre vision très fortement liés à un découpage DDD (Domain Driven Design).
Dans notre conception un micro-service définit un composant, dérivé d’un découpage métier et fonctionnel, agissant sur une donnée définie.
Le micro-service ne se limite pas uniquement à la partie back-end. Dans un contexte d’architecture web, il peut s’appliquer également au front-end.
Le Micro front-end et le Micro back-end se retrouvent intimement liés par une logique “composant d’affichage” et “composant qui traite applicativement la donnée affichée”.
Une architecture micro-services implique donc une certaine verticalité affichage, traitement et data.
API-First
C’est presque logique, on fait communiquer les différents composants par APIs.
Être API-first signifie d’intégrer la conception des APIs au cœur du processus de conception globale de l’application. Un peu comme si les APIs étaient le produit final.
Attention par contre, autant nous allons retenir l’API entre micro front end et micro back end, autant ce principe n’est pas partagé avec la communication entre le micro-service et d’autres composants du SI.
Une étude des différents patterns d’échange et un choix judicieux entre des méthodes synchrones et asynchrones est très importante pour éviter de mettre des contraintes fortes là où nous n’en avons pas besoin : pour partager une donnée avec les applications back office, tels qu’une confirmation de prise de commande avec un SAP, nous n’avons pas toujours besoin de désigner des flux synchrones ou API, nous pouvons par exemple découpler avec une logique de messaging, le cas d’usage nous le dira !
Cloud-First
Une vraie prédilection pour le Cloud, que du buzzword ?
En réalité, le fait de mettre en avant du Cloud dans cette démarche n’est que du bon sens.
Nous pouvons mettre en place une architecture on premise, pourquoi pas, mais dans certains cas il s’agit d’un vrai challenge : mise en place des serveurs, déploiement de la couche OS, des services, de la partie VM ou Container, etc.
Le Cloud First des architecture MACH vise la puissance des services managés, rapides de déploiement, scalables et élastiques, sur lesquels le déploiement en serverless ou en conteneur et la mise en place des chaînes CI/CD sont en pratique les seules choses à maîtriser, le reste étant fourni dans le package des fournisseurs de services cloud !
HEADLESS
Le Headless représente une tendance croissante dans le développement web et mobile. Cette approche met l’accent sur la séparation entre la couche de présentation, ou « front-end », et la logique métier, ou « back-end ». Cette séparation permet une plus grande flexibilité dans la manière dont le contenu est présenté et consommé. Elle offre ainsi une liberté de création sans précédent aux concepteurs d’expérience utilisateur et aux développeurs front-end.
Dans un contexte Headless, les front-ends peuvent être développés de manière indépendante. Les développeurs peuvent utiliser les meilleures technologies adaptées à chaque plateforme. Cela s’applique au web, aux applications mobiles, aux assistants vocaux, et à tout autre dispositif connecté. Cette approche favorise une innovation rapide. Cela permet aux entreprises de déployer ou de mettre à jour leurs interfaces utilisateur sans avoir à toucher à la logique métier sous-jacente.
La question qui nous vient à l’esprit maintenant est :
Ce type d’architecture s’applique à tout cas d’usage ? Certains sont plus réceptifs que d’autres de par leur configuration, gestion du parcours utilisateur ?
Un exemple dans le prochain épisode !
Articles qui pourraient vous intéresser
Un guide des bonnes pratiques d’Architecture pour le Numérique Durable: pourquoi faire ?
Un guide des bonnes pratiques d’architecture pour le Numérique Durable : pourquoi faire?
23 mai 2024
Architecture
Olivier Constant
Senior Manager Architecture
Le Numérique Durable ou Responsable est en plein essor. Des guides sont sortis récemment et proposent divers outils.
A notre niveau de cabinet de conseil et d’architecture des SI, il nous paraît indispensable d’ajouter notre pierre à cet édifice. D’autant que les précités n’ont pas tout dit…
Le Numérique Durable: pourquoi faire ?
On le dit et le redit et c’est bien le sous titre de notre travail : L’architecture est “Green by design”. En effet, depuis longtemps les architectes construisent des SI solides, non redondants donc sobres en fait…
Sans compter le temps passé à challenger les métiers sur leurs besoins. Et à éviter les travaux inutiles… Faire et défaire c’est du travail inutile et si on peut éviter c’est toujours ça d’économisé…
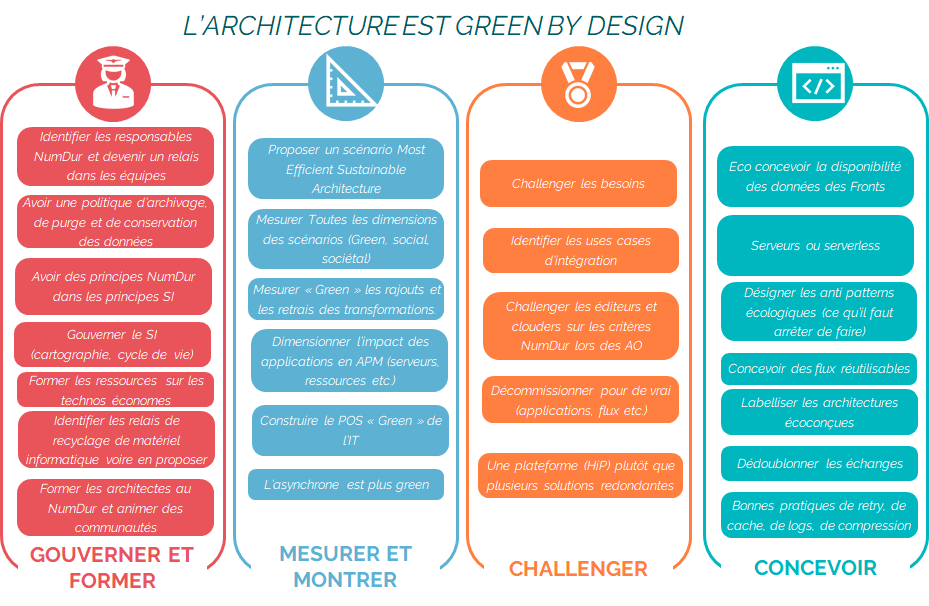
4 grands thèmes qui ne sont pas propres à l’architecture
Nous avons voulu que notre travail puisse être adapté en tant que guide à beaucoup d’expertise en plus de l’architecture :
Gouverner et former : qu’est ce que votre expertise / discipline / domaine de compétences peut mettre en place dans sa gouvernance et dans la formation des personnes pour intégrer les dimensions de responsable et de durable ?
Mesurer et montrer : que va-t-on pouvoir mesurer dans votre discipline et quels résultats va-t-on pouvoir montrer ?
Challenger : quels sont les thèmes ou autres domaines sur lesquels vous allez pouvoir challenger pour aller vers la diffusion des bonnes pratiques ?
Concevoir : quelles sont les bonnes pratiques lors de vos travaux de conception qui peuvent permettre d’aller vers plus de durabilité ?
Les architectes au coeur du Système d’Information
Le travail des architectes est on le rappelle ci-dessous :
L’Architecture d’Entreprise organise le dialogue entre les différents corps de métier pour définir une vision commune de l’entreprise de demain et de son SI, ainsi que la trajectoire pour y parvenir. Elle met en œuvre les approches nécessaires pour assurer la connaissance, la gouvernance et le pilotage opérationnel du SI.
A ce titre, les architectes sont au coeur des SI et des transformations et doivent donc jouer un rôle d’influenceur dans la direction du Numérique Durable. Ce guide est là pour fournir des clés à cette population particulière.
Impulsées par l’avènement du Cloud et du DevOps, les mouvances “as Code” et “Software Defined X” ont grandement amélioré la gestion du cycle de vie des assets informatiques (infrastructure, middleware, serveur d’application, …) avec principalement :
L’Infrastructure as Code (IaC),
La Configuration as Code,
Nous détaillerons dans un futur article le positionnement de chacun et les grands paradigmes en présence (procédurale vs déclaratif), qui reposent sur une caractéristique commune: l’utilisation de template/playbook au format normalisé (HCL, YAML, …) décrivant l’état final à atteindre ou le moyen d’y aller.
Même si la syntaxe est Human Readable, il peut être fastidieux à l’échelle d’un SI enperpétuelle évolution d’écrire et de mettre à jour ces fichiers de description.
Bien qu’il existe de plus en plus de plateformes simplifiant la création de ceux-ci sur base de conception visuelle en LowCode/NoCode ou de schématisation…Que diriez-vous de troquer d’un point de vue utilisateur le ”as Code” par du ‘as Prompt” ?
#GenAI à la rescousse
Le terrain de jeux des Large Language Models (LLM) et de la GenAI ne cesse de croître, en n’oubliant pas au passage l’ingénierie logicielle.
Imaginez pouvoir simplement demander “Provisionne un cluster de VM EC2 avec NGINX en exposition publique ainsi qu’une base Elasticache” pour voir votre souhait exaucé instantanément.
D’ailleurs, n’imaginez plus, car l’Infrastructure as Prompt (IaP) est déjà proposée par Pulumi AI, et bien d’autres en cours (depX) ou à venir.
Ce positionnement et les avancées rapides et significatives dans ce domaine ne sont pas étonnantes car nous sommes en plein dans le domaine de prédilection des LLMs: les langages.
Qu’ils s’agissent de langages parlés (Français, Anglais, …), de langages de programmation (Python, JavaScript, Rust), de langage de description (HCL, YAML, …), ils ont tous deux concepts fondamentaux:
Un dictionnaire, un vocabulaire, une liste de mots avec une (plusieurs) signification(s) connue(s),
Une grammaire et des règles syntaxiques plus ou moins strictes donnant un sens particulier à la suite de mots d’une phrase ou d’une ligne de fichier de configuration.
Plus le dictionnaire et la grammaire d’un langage sont dépourvus d’ambiguïtés, plus le degré de maturité et la mise en application de la GenAI et des LLMs sur celui-ci peut-être rapide.
L’Infrastructure as Prompt n’est pas une rupture totale avec le “as Code”, simplement une modernisation de l’interface “Homme-Clavier”.
En effet, peu importe le moyen (création manuelle, auto-génération via prompt) l’aboutissement de cette première étape est la disponibilité du fichier de description.
Le cœur du réacteur, à savoir la traduction du <fichier de conf> en actions pour <provisionner et configurer les ressources>, est toujours nécessaire.
A l’avenir elle pourra se révéler un parfait assistant pour faire des recommandations et propositions d’ajustement vis-a-vis de la demande initiale pour optimiser l’architecture à déployer:
Prioriser les services managés,
Prioriser le serverless,
Etre compliant avec les best practices des frameworks d’architecture des Clouders (AWS Well Architected Framework, …),
Security By Design,
RIght sizing de l’infrastructure,
Opter pour des ressources ayant une empreinte carbone et environnementale optimisées.
#La confiance n’exclut pas le contrôle
Bien que la baguette magique qu’apporte cette surcouche soit alléchante, nous ne pouvons qu’abonder les paroles de Benjamin Bayard dans son interview Thinkerview Intelligence artificielle, bullsh*t, pipotron ? (25min) : “tous les systèmes de production de contenus si ce n’est pas à destination d’un spécialiste du domaine qui va relire le truc, c’est dangereux.” Dans un avenir proche l’Infrastructure as Prompt // la Configuration as Prompt n’est pas à mettre dans les mains de Madame Michu (que nous respectons par ailleurs) qui ne saura pas vérifier et corriger le contenu de Provisioning, de Configuration ou de Change qui a été automatiquement généré. Nous vous laissons imaginer les effets de bords potentiels en cas de mauvaise configuration (impact production, impact financier, …) dont le responsable ne serait autre que la Personne ayant validé le déploiement. Impossible de se dédouaner avec un sinistre “c’est de la faute du as Prompt”.
Vous l’avez compris, la déferlante LLM et GenAI continue de gagner du terrain dans l’IT, le potentiel est énorme mais ne remplace en rien la nécessité d’avoir des experts du domaine. Le “as Prompt” se révèle être un énorme accélérateur pour l’apprentissage du sujet, ou dans le quotidien de l’expert .. qui devra avoir une recrudescence de prudence quant aux configurations qui ont été automatiquement générées.
Articles qui pourraient vous intéresser
Service Mesh/Event Mesh/Data Mesh – Rien à voir, mais tellement proche !
Service Mesh/Event Mesh/Data Mesh - Rien à voir, mais tellement proche !
J’ai pu constater régulièrement que beaucoup de gens s’emmêlent les pinceaux quand il est question de définir et d’expliquer les différences entre Service Mesh, Event Mesh et Data Mesh.
Ces trois concepts, au-delà de l’utilisation du mot “Mesh”, n’ont pas grand chose de semblable. Quand d’un côté, nous avons :
Le Service Mesh qui est un pattern technique pour les microservices, qui se matérialise par la mise en place d’une plateforme qui aide les applications en ligne à mieux communiquer entre elles de manière fiable, sécurisée et efficace
L’Event Mesh, qui est un pattern technique d’échanges, afin de désiloter les différentes technologies de messaging
Et le Data Mesh qui lui, est un pattern général d’architecture de données, qui se matérialise par toute une série d’outils à mettre en place, et qui pousse le sujet de la productification de la donnée
On se dit déjà que comparer ces trois patterns ne fait pas sens ! Néanmoins, il y a peut-être un petit quelque chose, une évidence naturelle, qui peut découler de la comparaison.
Mais commençons donc d’abord par présenter nos trois protagonistes !
Le Service Mesh, ou la re-centralisation des fonctions régaliennes des microservices
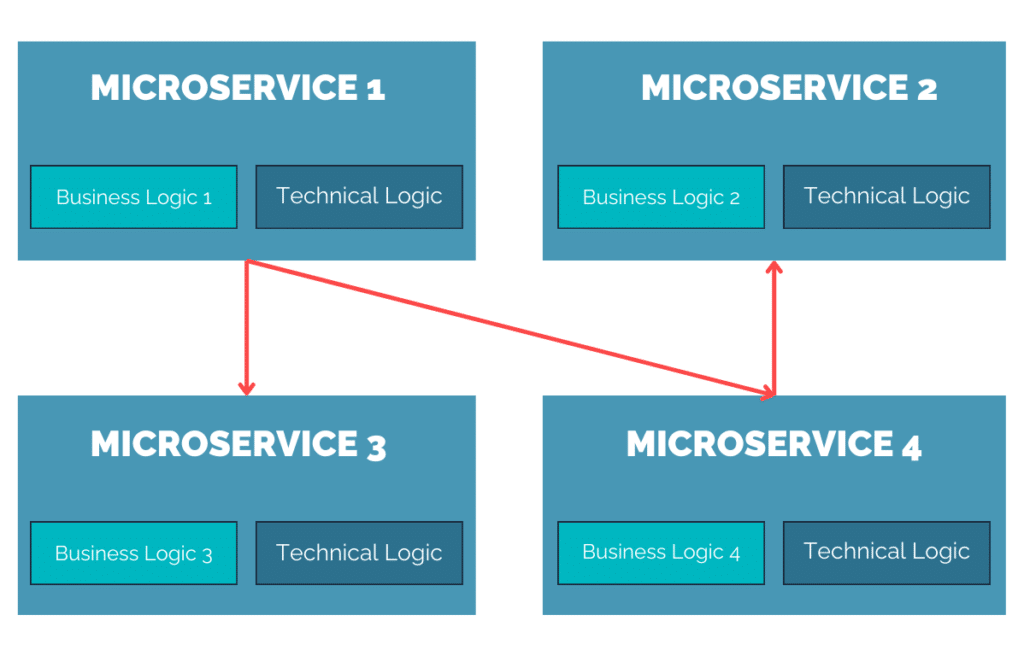
Historiquement, l’approche microservice a été motivée, entre autres, par cette passion que nous autres informaticiens avons souvent, pour la décentralisation. Adieu horrible monolithe qui centralise tout, avec autant d’impacts que de nouvelles lignes de code, impossible à scaler en fonction des besoins fonctionnels réels. Sans compter qu’on peut quasiment avoir autant d’équipes de développement que de microservices ! A nous la scalabilité organisationnelle !
Cela a abouti, de manière simplifiée bien sûr, au schéma suivant :
Chaque microservice discute avec le micro service de son choix, indépendamment de toute considération. La liberté en somme ! Mais en y regardant de plus près, on voit bien une sous-brique qui est TRÈS commune à tous les microservices, ce que j’appelle ici la “Technical Logic”. Cette partie commune s’occupe des points suivants :
La découverte de services
La gestion du trafic
La gestion de tolérance aux pannes
La sécurité
Or quel intérêt à “exploser” cette partie en autant de microservices développés? Ne serait-ce pas plutôt une horreur à gérer en cas de mise à jour de cette partie? Et nous, les microserviciens (désolé pour le néologisme…), ne serions nous pas contradictoire dans nos souhaits de décentralisation? Oui! Car autant avoir une/des équipes dédiées à cette partie, qui travaillerait un peu de manière décentralisée, mais tout en centralisant sur elle-même ce point?
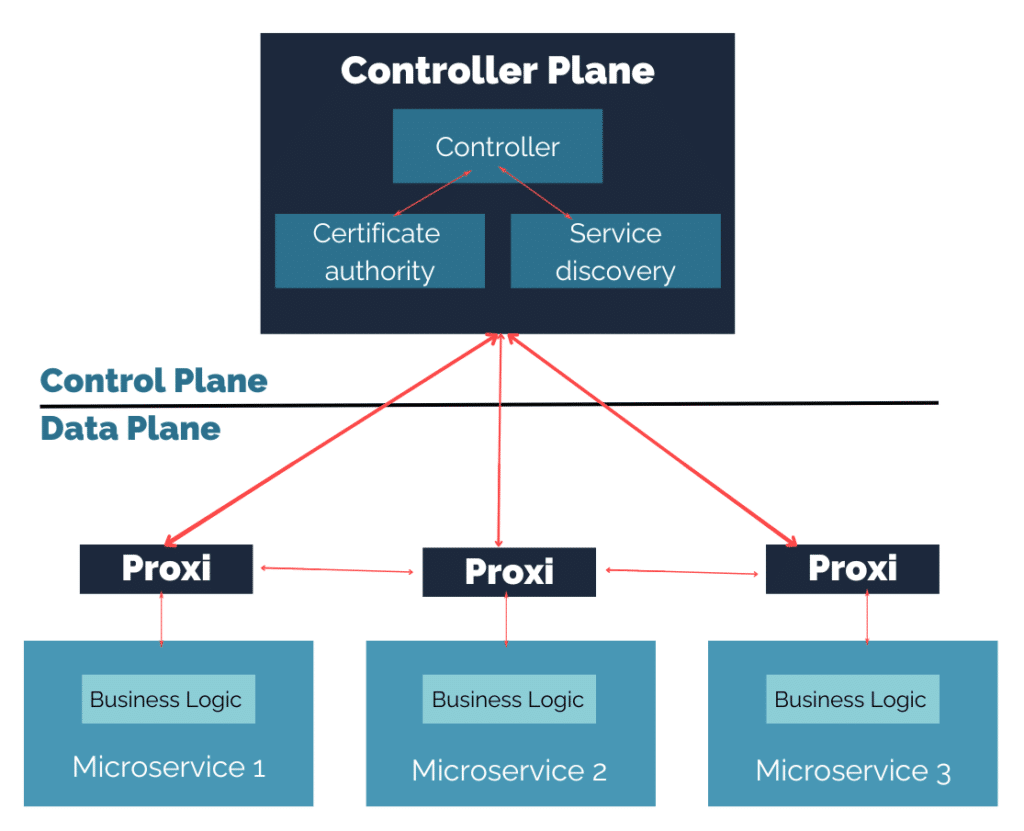
C’est ainsi qu’est apparu le pattern de Service Mesh, décrit dans le schéma suivant :
Dans ce pattern, les fonctions techniques sont définies de manière centralisée (Control Plane), mais déployées de manière décentralisée (Data Plane) afin de toujours plus découpler au final son architecture. Et cela se matérialise par des plateformes comme Consul ou Istio, mais aussi tout un tas d’autres plus ou moins compatibles avec votre clouder, voire propres à votre clouder.
Maintenant que nous avons apporté un premier niveau de définition pour le service mesh, allons donc voir du côté de l’Event Mesh !
L’Event Mesh, ou la re-centralisation pour désiloter
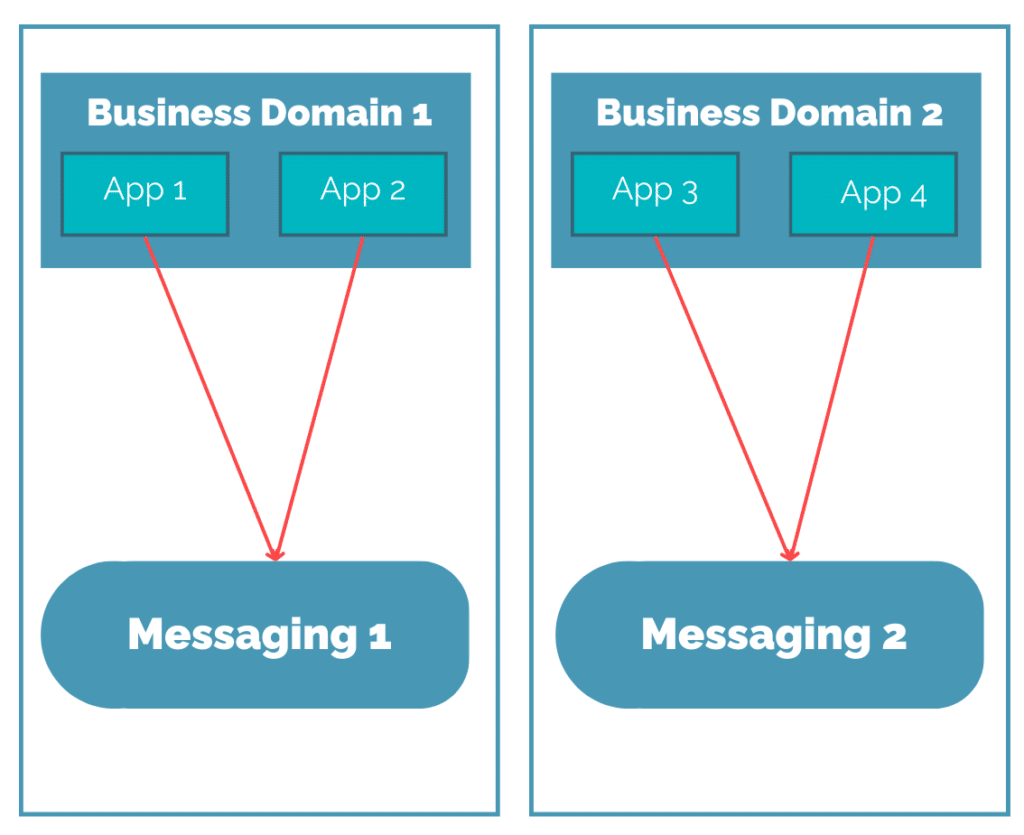
L’histoire informatique a eu l’occasion de voir tout un ensemble de solutions de messaging différentes, avec des origines différentes. Qu’on retourne à l’époque des mainframes, ou qu’on regarde de côté des technologies comme Kafka qui ont “nourri” les plateformes Big Data, les solutions se sont multipliées. Et c’est sans compter le fait de faire du messaging par dessus du http!
On obtient donc assez facilement des silos applicatifs qui sont freinés dans leur capacité à échanger, comme montré sur le schéma suivant :
Certes, les solutions de bridge existaient, mais elles permettaient souvent de faire le pont entre seulement deux technologies en même temps, le tout avec des difficultés à la configuration et l’exploitation.
Et si on rajoute le fait qu’un certain nombre d’entreprises se sont dit qu’il serait intéressant d’utiliser les technologies propriétaires de chacun de leurs clouders, on imagine bien les difficultés auxquelles elles font face.
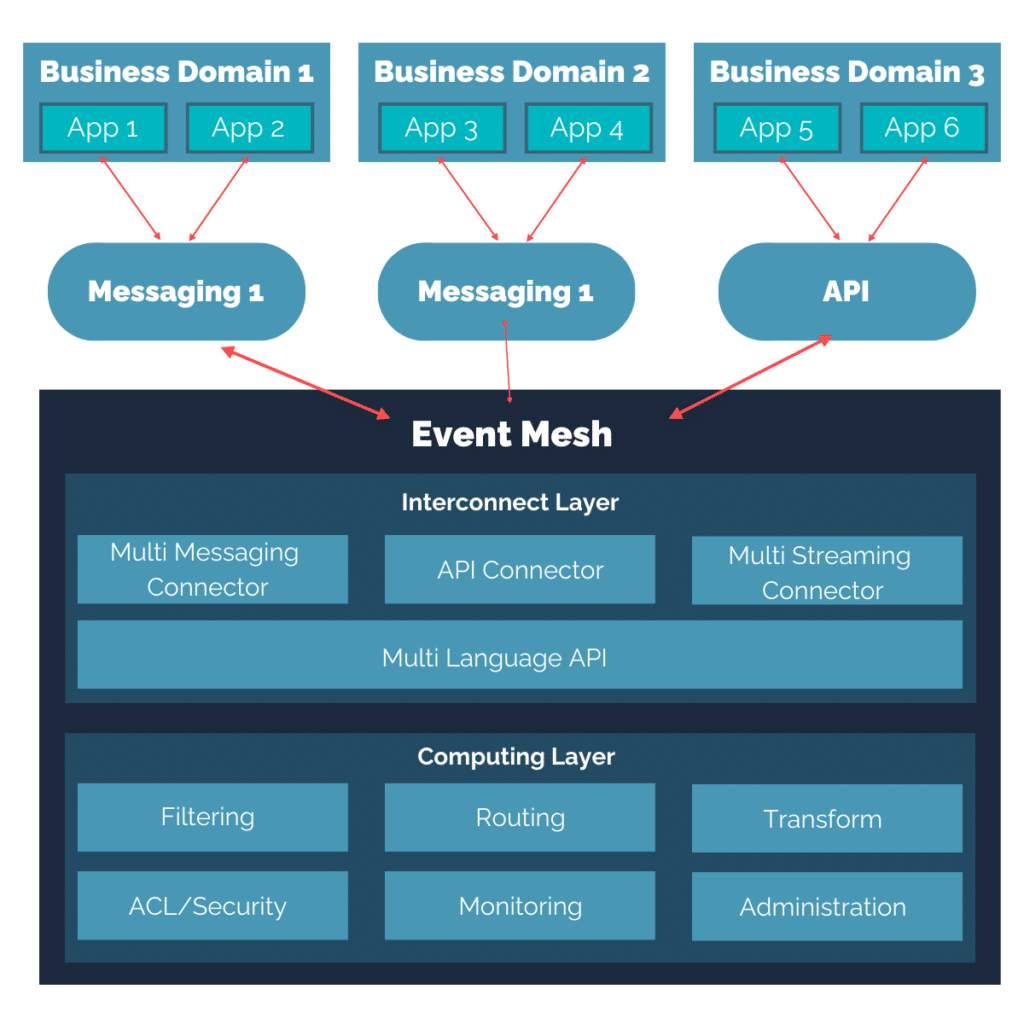
Est donc apparu le pattern Event Mesh, imaginé entre autre, implémenté et popularisé par l’éditeur Solace, qui permet de centraliser sur une solution unique, capable entre autres d’avoir des “agents” locaux aux SI (selon la zone réseau, le datacenter, le clouder, le domaine métier, etc…). Digression mise à part, on notera que le terme Event Mesh a été repris aussi bien par le Gartner que par des solutions open-source.
Indépendamment des architectures de déploiement, cela nous donne l’architecture simplifiée suivante :
Son intérêt vient qu’on peut ainsi relier tout le monde, y compris du Kafka avec du JMS, ou avec des API.
Le Data Mesh, décentralisation ou relocalisation des compétences ?
Le Data Mesh, de son côté, vient de son côté en réaction d’une précédente architecture très centralisée, faite de Data Lake, de Datawarehouse, de compétences BI, d’intégration via ETL ou messaging, le tout géré de manière très centralisée.
En effet, il était coutume de dire que c’est à une même équipe de gérer tous ces points, faisant d’eux des spécialistes de la data certes, mais surtout des grands généralistes de la connaissance de la data. Comment faire pour être un expert de la donnée client, de la donnée RH, de la donnée logistique, tout en étant un expert aussi en BI et en intégration de la donnée?
Ce paradigme d’une culture centralisatrice, a du coup amené un certain nombre de grosses équipes Data à splitter leur compétences, créant toujours plus de silos de compétences. De l’autre côté, les petites équipes pouvaient devenir très tributaires des connaissances des sachants métiers. Si cela vous rappelle les affres de la bureaucratie, ce serait évidemment pur hasard!
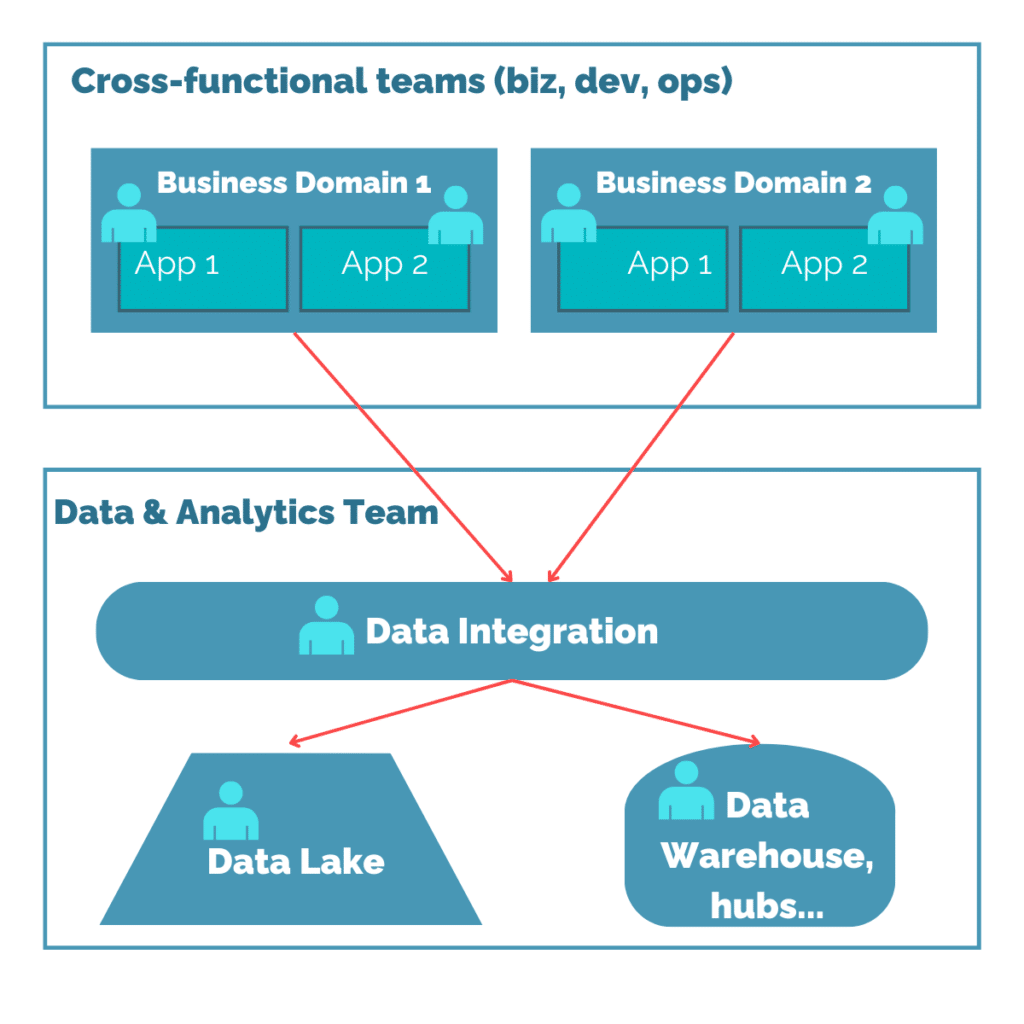
Ci-joint une représentation simplifiée de l’architecture dont nous avons pu hériter :
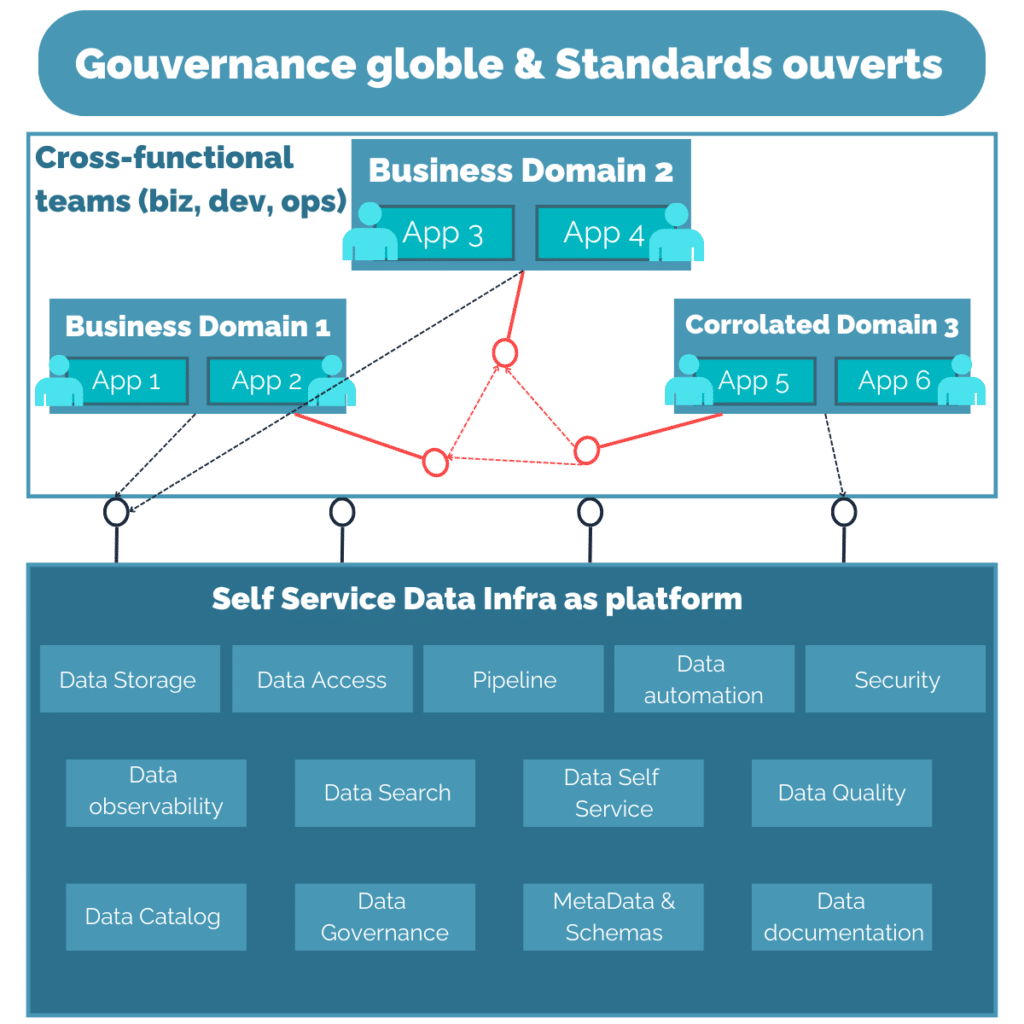
C’est ainsi qu’est apparu le pattern Data Mesh. Dans ce pattern, ce sont aux équipes Domaine de :
Collecter, stocker, qualifier et distribuer les données
Productifier la donnée pour qu’elle ait du sens à tous
Fédérer les données
Exposer des données de manière normée
Ce qui impose en l’occurrence de :
Mettre en place un self-service de données
Participer activement à la gouvernance globale
Et d’avoir un nouveau rôle de Data Engineer, qui doit mettre en place la plateforme de données pour justement faciliter techniquement, et proposer des outils.
Nous avons donc en schéma d’architecture le suivant :
Mais alors quid des points communs ?
Et en réalité, le gros point commun de ces trois patterns, c’est leur histoire !
Les trois proviennent de cette même logique centralisatrice, et les trois cherchent à éviter les affres d’une décentralisation dogmatique. A quoi cela sert de décentraliser ce que tout le monde doit faire, qui est compliqué, et qui en vrai n’intéresse pas tout le monde?
Et à quoi cela sert de forcément tout vouloir centraliser, alors même que les compétences/appétences/expertises/spécialisations sont elles-même “explosées” en plusieurs personnes ?
Certes, la centralisation peut avoir comme intérêt de mettre tout le monde autour de la même table, ce qui peut être intéressant pour de gros projets qui ne vivront pas, ou quand on est dans des phases d’une maturité exploratoire…
Et cela pousse tout un ensemble de principes, dont entre autre (liste non exhaustive):
Découvrabilité : Il faut pouvoir retrouver les services et les données simplement, en les exposants via des « registry » dédiés simples d’accès
Flexibilité et évolutivité : Il faut qu’une modification dans l’infrastructure ou dans un domaine puisse être accueilli sans douleur
Sécurité : Les politiques de sécurité sont propres aux champs d’actions de ces patterns, et sont donc inclus dans ces patterns
Distribution et autonomie : On distribue les responsabilités, les droits et les devoirs, afin de construire un système robuste organisationnellement
Alors oui, je vous entend marmonner “Et oui, c’est toujours la même chose! C’est comme ça”.
Mais en fait pas forcément ! En ayant en tête :
Ces éternels mouvements de yoyo,
Le Domain Driven Design qui est aussi un point commun au Data Mesh et à l’Event Mesh,