#Batch, #ETL, #EAI, #ESB, #API… d’année en année depuis plus de 20 ans les professionnels de l’intégration ont développé et fait évoluer leurs produits pour accompagner les nouveaux modèles d’architectures.
A l’ère du #Cloud, un nouveau produit tisse progressivement sa toile : l’iPaaS.
Faciliter l’intégration des applications dans un écosystème hybride (Cloud to Cloud, Cloud to OnPrem) est la promesse phare de ces integration-Platform-as-a-Service.
Quels sont les acteurs de ce nouveau segment ? Quelle est la philosophie de leur produit ? Quels patterns d’intégration supportent-ils ? Ont-ils vocation à remplacer les solutions historiques OnPrem ? autant de questions que nous pouvons nous poser.
Ces quelques minutes de lecture vous donneront à la fois une vision théorique et concrète du marché et des concepts issus d’une démarche d’Appel d’Offre et de Proof-Of-Concept.
[Le marché] Se réinventer pour survivre
IBM, Informatica, TIBCO, Talend, Axway sont des grands noms de l’intégration parmi tant d’autres dans cet écosystème foisonnant.
Chacun propose une ou plusieurs solutions (IBM Datastage PX, IBM WebSphere TX, Informatica PowerCenter, TIBCO Business Works, TIBCO Mashery, Axway Amplify, …) pour couvrir tous les besoins d’intégration applicative des grandes entreprises.
Ces besoins ayant émergé successivement d’année en année, les DSIs ont lancé des programmes IT dont la résultante est un millefeuille de progiciels d’intégration différents, avec des recoupements fonctionnels et une multiplicité d’interfaces de conception / management / supervision / monitoring.
Autant dire que la simplicité et l’agilité ne sont pas au rendez-vous.
Ces solutions s’appuyaient sur une palette de connecteurs out-of-the-box mais surtout sur de grands bus d’entreprise monolithiques qui ont fait couler beaucoup d’encre (et sûrement de larme et de sueur). Cette architecture pouvait satisfaire les intégrations Ground to Ground au sein d’un même SI mais elle se confronte désormais :
A la recherche de modularité,
A l’ouverture du SI (Cloud, partenaire, …),
A l’augmentation prévisible ou non de la charge d’intégration (scalabilité) (OpenData, IoT, …),
A l’agilité introduit avec les démarches DevOps et l’outillage CI/CD,
Au shadow IT pratiqué par les métiers qui souhaitent aller vite sur des cas d’intégration simple,
…
La société Boomi, spécialisée initialement dans les échanges EDI, est l’instigatrice de ce nouveau mouvement iPaaS lancé en 2007. Rachetée par Dell en 2010, Dell Boomi truste la place de leader du marché.
Pour répondre à cette concurrence, les éditeurs historiques ont créé à leur tour des offres iPaaS sur la base de leurs solutions existantes. Simple rebranding ou véritable nouvelle offre ?
En parallèle de ces éditeurs bien ancrés, des acteurs born to be Cloud (à l’instar de Moskitos) apparaissent désormais dans le Magic Quadrant Gartner.
[Le concept] Une boîte à outils survitaminée
Bien malin celui qui pourra vous donner une définition unanime d’un iPaaS. Nous pouvons cependant la qualifier de plateforme d’intégration unifiée administrée dans le Cloud pour répondre simplement et facilement à tous les besoins d’intégration* : ETL, EAI/ESB, EDI, API, MOM, MFT.
Certaines offres affichent également des capacités autour du Master Data Management, du Workflow Management et du développement d’applications Web.
Un véritable couteau suisse de l’intégration en somme qui théoriquement pourra :
Etre mis en production en moins de temps qu’il n’en faut pour l’écrire,
Faciliter la création des flux d’intégration grâce à une approche LOW CODE avec du glissé-déposé. Vous rêviez de créer un flux moyen (transformation / composition) en moins de 2 jours, ils l’ont fait,
Rationaliser très fortement vos outils d’intégration actuels,
Simplifier la gouvernance et l’exploitation de la plateforme et de vos flux grâce à une plateforme centrale unifiée,
S’intégrer dans votre démarche DevOps et vos outillages CI/CD grâce à leur approche API Led / API First.
* Les éditeurs ne se cachent pas derrière ces grandes lignes et assument pleinement de ne pas offrir la même couverture fonctionnelle et le niveau de performance des solutions spécialisées (exemple : Dell Boomi MoM versus le bus SOLACE). Ce point n’est pas bloquant et sera totalement compensé par l’adoption d’une stratégie Hybrid Integration Platform (HIP) que nous détaillerons dans un second article.
[Architecture] Une architecture au goût du jour
En quête de simplicité de mise en oeuvre et d’agilité, les offres iPaaS trouvent leur essence dans les capacités offertes par le Cloud.
Cependant deux degrés de Cloudification s’opposent :
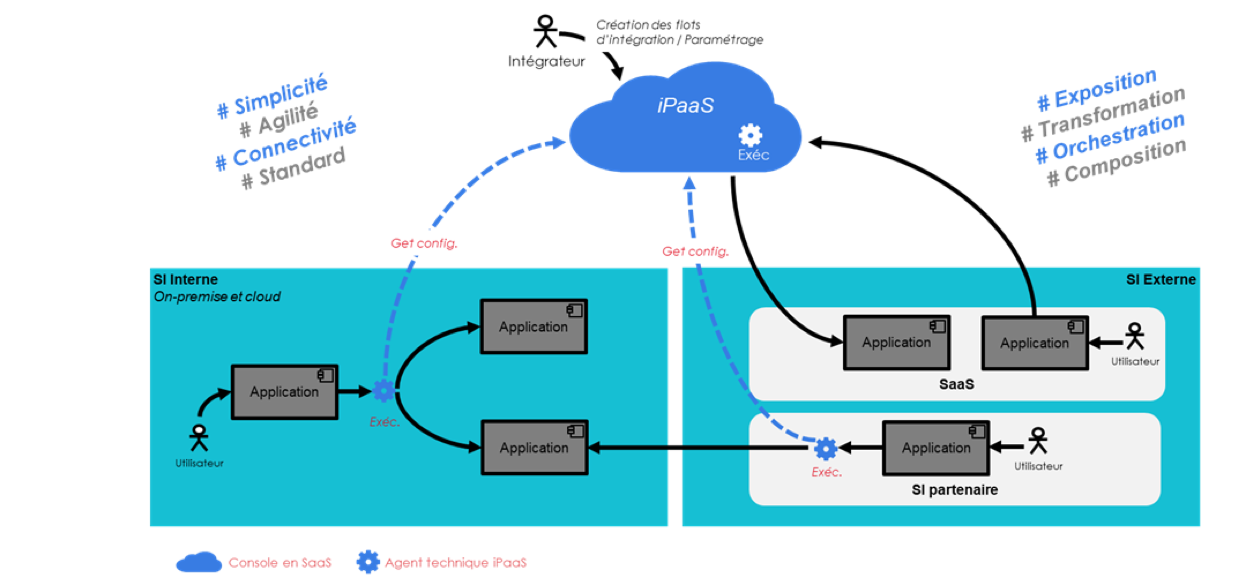
Le Cloud ou rien (Moskitos) : chaque flux d’intégration est orchestré dans le Cloud. Des agents techniques assurant la connectivité et les transformations sont déployés au plus près des applications sources et cibles. Ces agents techniques sont orchestrés par la plateforme centrale qui exécute les flux. Aussi chaque donnée métier, sensible ou pas, transite par votre plateforme iPaaS dans le Cloud. Cette architecture est pertinente pour les échanges Cloud-to-Cloud ou Cloud-to-On Premise. En revanche elle est peu pertinente par la latence induite, la dépendance à la connectivité internet et les enjeux de sécurité pour les échanges On Premise-to-On Premise.
L’hybridation avec un modèle distribué (Mulesoft, Dell Boomi) : les flux s’exécutent en toute autonomie sur les agents techniques (microservices) distribués au coeur du SI (On Premise, partenaire, Cloud). Ces agents techniques remontent des métadonnées vers la plateforme centrale disponible en SaaS qui permet de les manager.
La plateforme SaaS est :
Soit autosuffisance (Dell Boomi) pour créer des processus d’intégration simple/moyen/complexe et les déployer en un clic sur l’agent technique de votre choix pour sa future exécution. Le concept de Low Code est poussé à son paroxysme. En cas de besoin de transformation exotique, la plateforme SaaS dispose d’un éditeur de code en ligne (Python, Groovy) pour développer la fonction adéquate (qui pourra être réutilisée sur étagère dans vos autres processus d’intégration).
Soit plus limitée (Mulesoft, Moskitos, …) et il vous sera nécessaire d’utiliser un environnement local développeur (IDE, Éclipse ou autre) pour développer vos processus (avec une moins bonne gestion du Low Code) et finalement les sauvegarder sur le Cloud (Moskitos) soit les exporter en .jar (Mulesoft) en fonction de l’architecture de la plateforme.
[Licensing] J’aurais bien besoin d’un FinOps
Le modèle de souscription annuelle “as-a-service” de ces plateformes offre bien des avantages mais également des difficultés lorsque vient la comparaison des différentes offres du marché.
Effectivement chacune s’appuie sur des métriques de licensing fines qui lui sont propres :
Facturation au nombre de User Développeur / User Métier,
Facturation au nombre de connexions techniques unitaires,
Facturation au nombre de partenaires EDI,
Facturation au nombre de transaction par seconde,
…
Quand d’autre facture pour la mise à disposition d’une typologie de plateforme (small, medium, large) peu importe le nombre d’applications connectées, peu importe le nombre d’utilisateurs développeurs/métiers et peu importe le nombre de flux processés. La métrique la plus restrictive est ici la volumétrie des données qui transitent par la plateforme Cloud.
Il saute aux yeux que le premier modèle sera difficilement prédictif :
Combien de clients ont suffisamment de métriques sur leur existant : nombre de connexions, nombre de flux, nombre de specialist integrator / citizen integrator, …
Combien de clients ont une vision claire et arrêtée sur leur démarche de transition, sur l’accostage des nouveaux projets pour projeter le ramp up de la plateforme et ses coûts.
Cette connaissance est néanmoins primordiale pour deux raisons :
L’effet de volume induit un levier de négociation possible avec l’éditeur,
Une vision claire de ces métriques peut mettre en exergue un modèle de facturation éditeur qui n’est pas du tout adapté à votre contexte (qui voudrait payer 20M€ pour s’intégrer avec ses 4000 partenaires en EDI ?). Un nouveau modèle doit alors être pensé.
Certains produits du marché sont une véritable révolution soit par leur approche, soit par leur maturité et simplicité d’utilisation. Un véritable atelier de génie logiciel vous permet au travers d’une plateforme centrale unifiée de réduire grandement la complexité de conception, de documentation, de déploiement, d’exécution et de monitoring de vos flux.
Un iPaaS pour les gouverner tous…
Un iPaaS pour tout concevoir…
Un iPaaS pour tous les traitements…
… Rien n’est moins sûr.
Le suspens reste entier jusqu’au prochain article qui présentera la vision stratégique du moment : l’Hybrid Integration Platform (HIP).
#ToBeContinued
Les autres articles qui peuvent vous intéresser
L’impact de la dette technique n’est pas qu’un problème de « Techos »
L’impact de la dette technique n'est pas qu'un problème de "Techos"
Souvent, on oppose la vision métier à la vision IT. Cependant, itérer des refontes de processus dans une optique d’optimisation, sans regard pour leur implémentation, revient à vouloir placer Lewis Hamilton dans une 4L : l’idée est bonne, mais il y a peut-être plus efficace.
Le premier impact de la dette technique, c’est la difficulté à faire évoluer les fonctionnalités de son système d’information.
Souvent, on prend des raccourcis en phase de cadrage pour des raisons budgétaires, de planning, ou tout simplement parce que l’on se dit que l’on fera mieux les choses plus tard… sans jamais le faire.
Cela entraine un manque de capacité à répondre aux besoins ultérieurs, notamment à tous ces nouveaux enjeux qui apparaissent régulièrement (par exemple, construire une vision 360 est compliqué sans une démarche référentiel maitrisée). Le SI devient une sorte de boulet au pieds du métier, qui l’empêche de s’adapter aux évolutions du marché. Certains chantiers sans valeur ajoutée métier, mais structurant pour les évolutions futures, ne peuvent pas être repoussé : c’est la notion de chantier « enablers ». Ce point peut devenir particulièrement préoccupant dans le cadre de projet règlementaires (les différents chantiers issus de Bâle 2, ou les sujets LAB LAT sont de bons exemples, du fait des exigences en termes de qualité des données), ou dans des contextes ou l’agilité est vitale (le secteur du Retail, par exemple, où le déploiement d’une nouvelle fonctionnalité devient rapidement un enjeux critique vis-à-vis de la concurrence).
Le deuxième impact de la dette technique est l’image que l’on renvoie aux différentes parties prenantes externes à l’entreprise, mais aussi aux internes.
Une interruption de service due à un plantage nécessitant de redémarrer les environnements de production entraine une image très négative pour le client, qui peut entrainer un désengagement en cas de fréquence trop élevée (pensez à la dernière fois où votre connexion internet personnelle ne fonctionnait plus, et au stoïcisme dont vous avez su faire preuve à ce moment). En interne, cela entraine un désengagement progressif des équipes, du fait de tâches répétitives à très faible valeur ajoutée, du sentiment de faire systématiquement des solutions dégradées, ou à la survenue fréquente d’incidents de production. Ces points génèrent de la frustration, dans le sens où ils donnent le sentiment que la qualité n’est pas le souci de l’entreprise (surtout lorsqu’on leur demande de prioriser un sujet, pour au final dénaturer le résultat de l’étude). Si cela entraine un turn over dans vos équipes, le sujet est préoccupant. Si vous êtes en difficulté de recrutement, cela peut devenir critique, d’autant que les premières victimes du turn over sont les hauts potentiels, qui souhaitent être pilotés par la qualité et la richesse des sujets.
Le dernier impact de la dette technique que j’évoquerai dans cet article est budgétaire.
En effet, toute dette doit se rembourser un jour, et entraîne des coûts récurrents d’ici là. Cela va générer des coûts projets plus importants lors des évolutions, ou des actions humaines pour corriger des erreurs issues de ces dettes (par exemple, le rapprochement des chiffres comptabilité / gestion réalisé manuellement, faute de chaîne de traitement fiable). N’oublions pas aussi ces applications dont le décommissionnement est acté, mais jamais terminé (ce qui entraîne de nombreux coûts, mais une augmentation significative de la complexité du SI du fait de la parallélisation des chaines).
Au final, cela se traduit par des coups de canif dans votre budget projet, sous forme de coûts de runs importants, ou de chiffrages projets plus importants que prévu (matérialisés par le classique « La DSI coûte trop cher »).
Il y a bien entendu beaucoup d’autres raisons qui devraient nous pousser à ne pas négliger la dette, cependant, ces 3 points sont des enjeux que l’on retrouve dans toutes les DSI : Agilité, Expérience utilisateur / qualité de service, et maîtrise budgétaire.
Dans un prochain article, nous allons parler de la gestion de la dette dans le cadre des projets Agile.
Aujourd’hui, j’ai décidé de prendre ma plume (enfin mon clavier) pour partager avec vous un petit billet d’humeur à propos de deux activités qui occupent une grande partie de mes journées, le Crossfit et ma vie de Consultant chez Rhapsodies Conseil.
Vous vous demandez sûrement, mais où veut-il en venir ? Quel est le rapport avec la choucroute ? (#expressiondesannées80)
En fait, le Crossfit, que je pratique depuis plus de 3 ans, est devenu pour moi bien plus qu’un sport ou une passion, c’est un vrai mode de vie qui a naturellement pris une place majeure dans mon quotidien, pour une vie plus saine et plus équilibrée. Qui dit mode de vie, dit que mon job de consultant doit être en adéquation avec les valeurs prônées par celui-ci afin d’atteindre une harmonie pro/perso. C’est ce que j’essayerais de vous présenter juste après le petit rappel historique ci-dessous (le moment « culture » de ce billet d’humeur).
Le crossfit – kézako ?
Pour les non connaisseurs, le CrossFit est un programme de conditionnement physique général créé aux États-Unis par Greg Glassman dans les années 70 et qui prendra son appellation officielle en 1995. Il repose sur 3 principes clés : des exercices constamment variés, des mouvements fonctionnels et un entraînement à haute intensité.
Le mot CrossFit vient de Cross Fitness (en français, entraînement croisé), appelé ainsi parce qu’il mélange différentes activités physiques et sportives préexistantes. En effet, il combine principalement l’haltérophilie (épreuves JO, kettlebell, dumbell, …), la gymnastique (pompes, tractions, exercices à la barre ou aux anneaux, …) et des activités de cardio training (rameur, vélo, course, corde à sauter, …).
L’objectif ici, n’étant pas de faire la page Wikipédia du Crossfit, je vous explique comment cette activité sportive dynamise positivement ma vie professionnelle , surtout quand ses valeurs font écho à celles d’un Cabinet comme Rhapsodies Conseil.
Le programme CrossFit veut augmenter la capacité de travail dans ces différents domaines en provoquant par les entraînements des adaptations neurologiques et hormonales au travers des différentes filières métaboliques. Ceci afin de préparer ses pratiquants à s’adapter à n’importe quels efforts physiques rencontrés tous les jours grâce à la variété des entraînements, l’utilisation de mouvements poly-articulaires et l’intensité élevée du travail.
Crossfit Inc.
Crossfit et conseil même combat ?
Si nous analysons un peu les fondements précisés ci-dessus, le crossfiteur combine et mixe des exercices d’haltérophilie, d’endurance et des mouvements de gymnastique comme le consultant combine des activités d’expertise (métier, fonctionnelle, technique), de R&D, d’intelligence situationnelle (organisation, transformation, change ou tout simplement relations interpersonnelles avec les clients), de marcom (marketing des offres/produits, publications, évènements, …), de management (interne dans le cabinet ou externe dans ses projets clients) ou encore commerciales et cela au profit de chacune des activités (et donc de son métier de consultant) car elles se nourrissent les unes des autres tirant ainsi vers une amélioration continue globale.
Chez Rhapsodies Conseil, nous prônons cette pluridisciplinarité sur-mesure pour chaque individu et soutenons des trajectoires personnalisées en donnant les clés à chacun pour s’approprier sa carrière et orienter son parcours d’évolution. C’est aussi une façon de casser la routine et garder nos consultants motivés en leur évitant l’ennui.
Toujours plus loin, toujours plus haut
Si nous regardons un peu plus loin, le Crossfit a été conçu pour tester et challenger mentalement et physiquement avec une très haute intensité de travail ce qui pousse chacun des pratiquants au dépassement de soi (un des principes fondamentaux du Crossfit). Cette habitude à dépasser ses limites, à sortir de sa zone de confort, à aller là où on n’est encore jamais allé se traduit chez Rhapsodies Conseil également. Nous mettons en place un environnement propice et favorable à l’innovation et la disruption des idées établies !
Une citation de Mark Twain symbolise bien ce dépassement de soi, cette persévérance et cette exigence aussi bien personnelle que professionnelle.
Ils ne savaient pas que c’était impossible, alors ils l’ont fait.
Ensuite, une autre valeur fondamentale de notre cabinet de conseil, la bienveillance, se reflète très bien dans la pratique du Crossfit ! En effet, nous nous sommes toujours refusé à mettre nos collaborateurs en concurrence interne, nous favorisons une organisation collaborative faite de synergies et de complémentarités.
Dans le Crossfit, vous n’êtes en concurrence et en compétition qu’avec vous-même pour accomplir vos propres objectifs personnels (perte de poids, meilleure forme physique, meilleure santé, etc.).
De plus, la communauté Crossfit offre un environnement d’entraide et de partage. Vous n’êtes pas juste un membre qui a payé sa cotisation, vous faites partie d’une équipe soudée qui vous soutient durant chacun de vos entraînements. C’est la même chose pour l’ensemble de nos collaborateurs, malgré une localisation souvent dispersée en mission chez nos clients, ils savent qu’ils peuvent compter sur leur coach et leurs co-équipiers (principe d’équipes resserrées) en cas de besoin ou de difficulté.
Pour conclure, je dirais que malgré un monde piloté de plus en plus par l’égocentrisme et les réseaux sociaux, dans le Crossfit comme chez Rhapsodies Conseil, pas de place à la vanité et l’individualisme !
De la même manière que vous ne trouverez pas de miroir dans une salle de CrossFit, vous ne trouverez pas de récompense individuelle au détriment d’un autre collaborateur ou du collectif, car comme le dit un proverbe africain, « Tout seul on va plus vite, ensemble, on va plus loin. »
Nous sommes un acteur de référence de la transformation et nous recrutons pour étoffer notre équipe d’Architectes d’Entreprise.
Découvrez dans cette vidéo une équipe sérieuse qui ne se prend pas au sérieux. Des personnalités variées, pleines d’humour et passionnées par le même métier : l’Architecture d’Entreprise.
Il fut un temps où, pour être un bon architecte d’entreprise, il suffisait de maîtriser la modélisation (BPMN, UML, Archimate…), les activités d’architecture (TOGAF, Club Urba-EA notamment), les 4 couches (les processus, le POS, etc.), et bien sûr une bonne vision des technologies.
Un article à ce sujet, de CIO, m’a interpelé récemment. Sur les 12 certifications présentées pour un architecte d’entreprise : 5 sont orientées infrastructures et cloud, 3 sur la méthode, une sur le réseau, une sur l’open source, une sur la sécurité et la dernière sur Salesforce.
Rien, pas un mot, sur la posture de l’architecte ?
Notre contexte a évolué
Or, l’architecte évolue désormais dans un écosystème différent : plus mouvant, plus incertain et plus collaboratif. Si l’environnement de l’architecte évolue, son spectre de compétences aussi. C’est devenu une combinaison à la fois de savoir-faire techniques (voir plus haut) et des savoir-être spécifiques à ces nouvelles manières d’organiser le travail : production en cycle court, décloisonnement des métiers, bref : l’architecte TOGAF se doit aussi d’être un architecte agile. Et parce que les certifications peuvent être utiles comme gage de confiance envers votre employeur ou vos équipes, je vous propose un tour d’horizon des 6 formations devenues indispensables selon moi, pour notre métier d’architecte.
1 : Poser les bases de l’agilité – scrum master ou product owner
L’architecte d’entreprise doit impérativement connaître les bases de fonctionnement des projets Agile (les cérémonies et les daily meetings, back-log, MVP, planification, etc.). Une formation Scrum Master ou Product Owner permet de se familiariser avec les essentiels. Une petite expérience pratique dans l’un ou l’autre ne nuirait pas !
2 : Appréhender l’agilité à l’échelle – safe
Pour passer à une dimension supérieure, il faut alors s’intéresser aux cadres d’agilité à l’échelle. LeSS, DA, Scrum of Scrum sont des bons cadres. Connaître les avantages des uns et des autres permettra d’en discuter en connaissance de cause.
SAFe est le cadre qui intéresse le plus les entreprises en ce moment.
Discuter des avantages et inconvénients de ce cadre est intéressant ; en attendant il est devenu un incontournable. Une certification serait alors utile (en tant que responsable d’une équipe de consultants, je pense que nos clients vont nous le demander de plus en plus).
3 : Adopter une posture agile – management 3.0
Connaître des cadres d’agilité à l’échelle ne fait pas de nous des agilistes. Il faut comprendre la posture agile et ce qui va avec. Une formation de type Management 3.0 est un bon exemple pour comprendre les vrais fondements de l’agilité et de l’auto-organisation.
Les principes du management 3.0 sont basés sur : faire les choses justes de la bonne manière. Quelques principes que l’on peut citer : manager le système plutôt que les individus, prendre en compte les inter-actions sociales dans les relations de travail et simplifier les règles de collaboration entre individus.
Cette formation, comme son nom ne l’indique pas, s’adresse à tous, manager ou non.
4 : Savoir animer des ateliers – design thinking et lean start-up
Avec l’avènement de l’agile et aussi du digital, de nombreux types d’ateliers pour inventer / construire des solutions et des plannings, travailler l’intelligence collective, bâtir des équipes, etc. sont maintenant disponibles.
Avec un collègue coach agile, j’avais recensé plus de 40 ateliers ! Il est important pour un architecte d’entreprise, qui est amené à dialoguer avec nombre de personnes différentes dans l’entreprise, de maîtriser la pratique de ces ateliers pour les mettre en œuvre quand le besoin s’en fait sentir. Le Design Thinking et le Lean Start-up sont des essentiels de nos jours, mais les autres méritent de s’y intéresser.
Vous verrez même qu’à force, vous pourrez aussi créer / inventer vos propres jeux et animations !
5 : Savoir jouer / construire la solution – lego
Savoir présenter une synthèse des travaux, réconcilier plusieurs points de vue (merci TOGAF de nous avoir rappelé ce bon principe), construire les solutions les plus simples possibles, sont dans les fondamentaux de l’architecture. Au-delà d’une formation à la « facilitation graphique », nous pouvons même aller vers les bases du scripting et de la présentation de vidéos pour « vendre » nos solutions.
Dans les nouvelles techniques de construction de solutions, notons le Lego Serious Play qui prend une certaine importance et peut s’avérer très utile pour faire parler et converger différentes populations.
6 : Devenir un coach – process communication
Dans son/ses (nouveau(x)) rôle(s), l’Architecte d’Entreprise aura sûrement besoin d’être coaché pour l’aider dans son changement de posture et trouver sa place dans les nouvelles organisations. Mais il peut lui aussi profiter des techniques de coaching pour aider des projets, des équipes, des chefs de projet ou tout simplement des collègues architectes !
La process communication, mais aussi la PNL, sont des voies intéressantes à maîtriser.
Pour les architectes, les équipes en agilité (Product Owner, Scrum Master, membres) et aussi pour les parties prenantes. Une vue d’ensemble de l’agilité (de SCRUM à l’entreprise, en passant par les cadres d’agilité à l’échelle), une vue d’ensemble des travaux de l’architecture (selon différents référentiels), des exemples concrets de mises en œuvre et surtout un jeu participatif pour découvrir les interactions entre les architectes et les projets agiles (à une certaine échelle) font de cette formation une synthèse de l’évolution de l’architecture et des projets agile. Au-delà de la technique nous évoquons aussi les soft-skills nécessaires.
Conclusion
Voilà mes idées de méthodes et certifications d’animation, de facilitation et de co-construction pour faire évoluer notre métier complexe vers les enjeux d’aujourd’hui.
Tout comme une dette financière choisie intelligemment peut être synonyme de succès financier, toutes les dettes techniques ne sont pas nécessairement handicapantes pour l’entreprise, et peuvent aussi être un levier de croissance rapide. Cela se vérifie tout particulièrement lorsqu’on ajoute un nouveau système pour prendre des parts de marché : la dépense présente pour répondre au « time-to-market » est faite dans l’espoir d’un gain futur.
Attention cependant, tout comme les dettes financières non maîtrisées, les dettes techniques peuvent devenir un « poids mort » pour l’entreprise. En cas de difficultés trop importantes, elles accaparent les équipes et engendrent une évolution défavorable du rapport Run / Projet. Cela est synonyme de baisse dans la capacité à livrer de nouvelles fonctionnalités, mais aussi souvent de démobilisation des équipes, voire de turn over. Dans les cas extrêmes, par exemple pour les entreprises avec des ressources limitées, cela peut devenir léthal si la direction n’est pas vigilante à cet indicateur Run/Projet.
C’est pourquoi dans ce premier article, nous avons identifié 3 types de dettes IT et 3 parades pour les traiter :
Dette technique opportuniste et plan de remédiation
Un concepteur sait, en général, qu’il y a deux façons de créer une fonctionnalité : la bonne ou la rapide. La manière rapide n’est pas nécessairement la mauvaise, car elle consiste à ne pas faire de sur-qualité. Cependant, l’économie peut très bien avoir été faite au détriment de la scalabilité : la bonne idée d’un jour se révèle être un choix non pérenne. Bien souvent le concepteur est contraint de faire ainsi pour réduire le time-to-market.
Ce choix est parfaitement acceptable, mais il faut l’accompagner d’un plan de remédiation, pour assurer la pérennité du nouveau système une fois que celui-ci en sera en production. Dans le cas contraire, les dettes techniques vont s’accumuler petit à petit, ce qui entraînera inexorablement la baisse de la qualité de service pour les utilisateurs, la frustration des équipes en charge de la maintenance applicative et l’accroissement des coûts d’exploitation du fait des incohérences techniques et fonctionnelles à corriger continuellement.
Ce type de dette doit donc être tracé, pour permettre des actions de remédiation. En parallèle, un sponsor / product owner doit être tenu responsable de l’évolution de la dette technique sur son périmètre, et donc être objectivé sur ce sujet. La cohérence n’est pas un artifice.
Dette technique liée à l’innovation et pilotage des exigences
Dans le monde de l’IT, de nouveaux patterns et technologies apparaissent sans cesse. Il en va de même pour les usages.
Un choix de conception, à un moment donné, peut être remis en cause soit par une évolution des usages métiers, soit par l’apparition d’une nouvelle technologie entraînant une obsolescence fonctionnelle.
Ce type de dette finit toujours par apparaître qu’on le veuille ou non. Il est donc important de sensibiliser le sponsor / product owner à la nécessité de suivre la satisfaction des exigences sur son périmètre, afin de déclencher des actions de remédiation le cas échéant.
Dette technique « endémique » et vastes chantiers de modernisation
Ce type de dette est relatif aux vieux systèmes, sur lesquels ont été empilées au fur-et-à mesure des demandes d’évolution de nouveaux traitements complexes, sous forme de « verrues », jusqu’à créer une complexité telle que les systèmes deviennent impossibles à maintenir / faire évoluer, sans parler du turn over, entraînant inexorablement une amnésie informatique.
Dans le cas de fonctionnalités critiques pour le métier, cela constitue un risque opérationnel pour l’entreprise.
Ce type de dette doit être évité autant que possible, et faire l’objet de vastes chantiers de modernisation. Souvent, cela implique un remplacement pur et simple du système par un nouveau, plus adapté, et surtout mieux conçu.
Il existe aussi d’autres types de dettes, notamment celles créées inconsciemment …
Dans tous les cas, un système de classification des dettes techniques va permettre de les identifier et de sensibiliser les donneurs d’ordre, et leur proposer des plans de résolution adaptés :
Plan de remédiation pour favoriser la scalabilité et la pérennité au fil de l’eau
Pilotage des exigences pour accompagner l’évolution technologique
Vastes chantiers pour faire face à la dette « endémique »
Le sujet vous intéresse ? Restez à l’écoute, dans un prochain article, nous discuterons des différents impacts de la dette technique sur l’entreprise, et pourquoi cela n’est pas qu’une question « d’informaticiens ».
Dette technique : 3 types, et 3 approches pour la maîtriser