L’émergence des systèmes SCADA (Supervisory Control and Data Acquisition) dans les années 1980 et l’avènement de l’internet des objets (capteurs et dispositifs connectés) ont été un tournant majeur dans la tendance technologique de l’informatique industrielle. Force est de constater qu’aujourd’hui, l’informatique industrielle représente un vecteur incontournable pour transformer et moderniser l’exploitation et la maintenance des systèmes industriels.
Pour autant, de nombreuses entreprises se heurtent à des défis majeurs liés à la fragmentation de leur systèmes d’information industriels, la plupart pour des raisons historiques.
Dans ce contexte de fragmentation, un impact majeur est la difficulté à obtenir une vue d’ensemble cohérente des opérations industrielles ; ce qui entraîne une duplication des efforts d’exploitation et de maintenance.
Partant de ce constat, il devient dès lors intéressant de proposer une perspective visant à soutenir et à faciliter la vision d’ensemble à travers la mise en place d’une plateforme unifiée : la plateforme SI industrielle
Dans cet article, nous vous proposons de présenter les enjeux ainsi que les composants fondamentaux qui soutiennent une plateforme SI industrielle.
Proposition de définition
Une plateforme SI industrielle est un ensemble intégré de capacités technologiques et de moyens matériels fournissant un écosystème pour l’exploitation et la maintenance des systèmes industriels (usine, installations de fabrication, lignes de production, etc.).
Quels sont les enjeux pour une entreprise de mettre en place une plateforme si industrielle ?
l’entreprise car elle nécessite des changements à plusieurs niveaux :
Au niveau organisationnel et humain : la déclinaison de nouveaux processus organisationnels et leur adoption est un enjeu majeur pour la mise en place de la plateforme. Celà peut inclure en outre l’adhésion et la formation des opérateurs aux capacités technologiques ainsi que les bonnes pratiques de pilotage
Au niveau données et sécurité : il s’agit de l’un des enjeux majeurs pour la mise en place d’une telle plateforme. Garantir la protection des données sensibles implique la mise en œuvre de mesures de sécurité robustes
Au niveau intégration des systèmes existants: l’une des principales difficultés réside dans l’intégration des systèmes informatiques déjà en place et l’interopérabilité avec les systèmes existants
Quels avantages tire-t-on de la mise en place d’une plateforme si industrielle ?
Une entreprise dotée d’une plateforme SI industrielle pour le pilotage de ses opérations industrielles peut tirer profit des avantages suivant :
La réduction des coûts, en optimisant l’utilisation des ressources et la planification de la production industrielle
L’optimisation des processus opérationnels avec l’automatisation des tâches répétitives et l’augmentation de l’efficacité globale au niveau de la production
La vision en temps réel de l’activité de production à travers les capacités de supervision des systèmes industriels
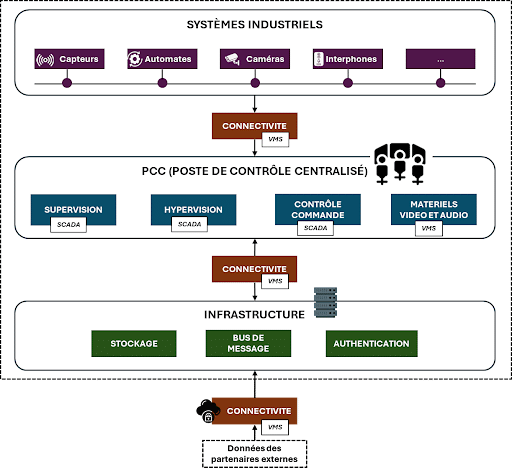
Les composants de l’architecture de référence d’une plateforme si industrielle
Schéma : composants de base de l’architecture d’une plateforme SI industrielle
1- LES CAPACITÉS SCADA
LA “SUPERVISION”
La visualisation en temps réel de données en provenance des systèmes industriels revêt d’une importance cruciale pour une plateforme SI industrielle.Le rôle de cette capacité est de :
Collecter des données à partir de dispositifs et de systèmes spécifiques, tels que des capteurs, actionneurs et automates programmables.
Fournir des informations en temps réel sur l’état et les performances des équipements surveillés dans le but d’analyser les données et d’apporter des mesures correctives ou préventives
L’“HYPERVISION”
L’hypervision est le niveau supérieur de surveillance et de gestion englobant l’ensemble de l’environnement industriel au travers d’une interface graphique centralisée. Cette capacité a pour objectif de :
Visualiser les données consolidées au travers de l’interface graphique sous forme de graphiques, tableau de bords ou de carte thermique
Gérer les alarmes en récupérant et en affectant des alertes de supervision issues des systèmes industriels
LE “CONTRÔLE COMMANDE”
Il s’agit de la capacité permettant la gestion et le pilotage à distance d’un système industriel (exemple : arrêt à distance d’une écluse sur une voie d’eau navigable).
Cette capacité permet de contrôler les équipements industriels avec la possibilité pour les opérateurs d’activer ou de désactiver les paramètres des équipements à distance ; ce qui offre une flexibilité dans la gestion des opérations industrielles
2- LES CAPACITÉS VMS
Les capacités VMS (Video Management System) se réfèrent à l’ensemble des fonctionnalités offertes par les systèmes de gestion vidéo et audio. L’objectif est de permettre la gestion, l’analyse et le stockage des flux de données vidéo provenant de multiples dispositifs.
LA CONNECTIVITÉ
Elle a pour rôle d’assurer la communication et l’échange de données entre les différents systèmes et l’environnement industriel. Les éléments pris en charge par cette capacité sont :
La mise en place et la gestion des réseaux industriels avec les caractéristiques spécifiques portées sur des protocoles de communication spécialisée adaptées aux contrainte de l’environnement industriel
L’interconnexion des équipements industriels tels que les capteurs, les actionneurs, les automates programmables, les robots ou encore les systèmes de contrôle-commande.
La gestion des flux ascendants et descendants de la donnée depuis les équipements industriels vers les capacités de supervision, les postes de contrôle et l’infrastructure
LES MOYENS MATÉRIELS
Les capacités VMS reposent sur divers moyens matériels pour un fonctionnement efficace. Ces matériels (audio et vidéo) sont essentiels pour la capture, le traitement, le stockage, la visualisation et la gestion des flux de données. Parmi ces moyens matériels, nous pouvons citer les capteurs et périphériques (capteurs de mouvement, microphones, haut-parleurs, etc.), les équipements réseau (switches, routeurs, etc.), ou encore les caméras de surveillance.
3- L’INFRASTRUCTURE
La capacité Infrastructure concerne les systèmes d’exploitation et de stockage qui supportent les activités industrielles. Les principaux aspects du rôle de l’infrastructure de ce contexte sont :
L’installation et la configuration des équipements industriels
La gestion des données générées par les équipements industriels, de leur collecte, leur stockage, leur traitement, leur analyse et leur archivage. Cela peut inclure la mise en place de bases de données ou de systèmes d’information décisionnels
La sécurité informatique en offrant des fonctionnalités de sécurité adéquat telles que des pare-feu, des mesures de détection des intrusions, des mesures de chiffrement ou encore des politiques d’authentification
4- LE PCC (Poste de Contrôle Centralisée)
En plus de ces capacités technologiques, une plateforme SI industrielle doit intégrer un Poste de Contrôle Centralisée (PCC) offrant un cadre où les opérateurs gèrent à travers les capacités technologiques listées les opérations industrielles. Le PCC coordonne également les interventions et prend des décisions en temps réel pour assurer le bon fonctionnement des installations industrielles.
Conclusion
La mise en place d’une plateforme SI industrielle représente une étape cruciale pour la transformation numérique des entreprises industrielles. En intégrant des capacités de SCADA, de gestion vidéo (VMS), de connectivité, et d’infrastructure, une telle plateforme permet de centraliser et d’optimiser la gestion des opérations industrielles. Cela se traduit par une réduction significative des coûts, une meilleure efficacité opérationnelle et une vision en temps réel des processus de production.
Cependant, la réalisation de cette transformation n’est pas sans défis. Les entreprises doivent surmonter des obstacles organisationnels, sécuritaires et techniques pour réussir l’intégration des systèmes existants et assurer une adoption fluide des nouvelles technologies par les opérateurs. La sécurité des données et l’interopérabilité des systèmes sont des enjeux majeurs à prendre en compte pour garantir le succès de cette initiative.
D’autres articles qui pourraient vous intéresser …
La mise en place d’une usine logicielle CI/CD (intégration et déploiement continu) est un élément clé pour les équipes DevOps. Cependant, il existe un débat sur la meilleure approche pour atteindre cet objectif : construire en interne ou acheter une solution sur le marché.
Dans les 2 cas, un investissement initial est nécessaire, mais indispensable pour obtenir des résultats probants sur la durée.
Toutefois, les options sont nombreuses et variées. Dès lors, toutes les possibilités offertes sur le marché peuvent rapidement dépasser une entreprise.
La transition vers le DevOps implique un changement culturel et une collaboration étroite entre développeurs (Dev) et exploitants (Ops). Cette évolution repose sur le choix judicieux et la mise en œuvre efficace d’une chaîne d’outils adaptée.
Quels sont les éléments à prendre en considération pour construire un écosystème DevOps à la fois agile et performant ?
Quelles sont les étapes pour mener à bien cette réflexion ?
L’usine logicielle : l’outil indispensable pour une approche DevOps réussie
Une usine logicielle (UL) permet d’automatiser les processus liés au développement de logiciels avec une approche structurée. L’usine logicielle tire son inspiration des pratiques de Toyota dans les années 70, avec des processus de fabrication automatisée.
Les objectifs auxquels répond ce type de plateforme sont multiples :
Réduire les pertes de temps et gagner en efficacité
Maintenir une qualité du code tout au long de la chaîne de production
Livrer des fonctionnalités à forte valeur ajoutée
Détecter les régressions applicatives immédiatement grâce aux tests et obtenir rapidement le feedback utilisateur sur les risques commerciaux
Améliorer et développer le logiciel de façon continue
Les développeurs réduisent les risques lors des déploiements en utilisant une plateforme commune pour le contrôle de version, l’analyse de code, et les tests.
L’orchestration et l’automatisation de ces activités fiabilisent ainsi les mises en Production. Elles assurent une livraison continue du produit tout en restant conforme à l’évolution du marché.
Il est désormais incontestable que les entreprises qui adoptent la culture DevOps bénéficient d’un retour sur investissement significatif. Pour plus d’informations, consultez notre article les 6 bonnes raisons afin de vous convaincre de franchir le pas !
Travailler avec une architecture de référence
Pour commencer, utilisez une architecture de référence pour guider la construction d’un système de développement et de livraison automatisé.
Une plateforme DevOps est constituée d’outils nécessaires à l’industrialisation du développement. Ces outils peuvent être regroupés sous 5 grandes familles d’activités :
Réaliser : Ensemble des capacités nécessaires à la construction, l’assemblage et aux tests du code en continu
Livrer : Ensemble des capacités visant à déployer les applications et leurs infrastructures en continu
Orchestrer : Ensemble des capacités de coordination et de l’automatisation de tâches
Superviser et Exploiter : Ensemble des capacités à surveiller et à assurer la disponibilité de la Production
Planifier et Collaborer : Ensemble des capacités de simplification du partage et de communication entre les équipes de réalisation
Chaque famille comprend plusieurs fonctions qui ne sont pas destinées à être toutes implémentées, et encore moins au même moment. Ainsi, vous pouvez réaliser les tests de non-régression en dehors du pipeline et les intégrer dans un deuxième temps.
La création d’une usine logicielle nécessite une vision à court, moyen et long terme. Elle nécessite l’application des bonnes pratiques dès le début, et une réflexion sur le niveau d’intégration souhaité.
Définir sa stratégie de déploiement et d’organisation UL
Combien de chaînes DevOps à mettre en place ? Pour quels besoins ?
La définition de l’architecture de référence n’est que la première étape de votre démarche.
Avant de commencer à construire des pipelines de livraison de logiciels, il est crucial de définir les utilisateurs de ces usines.
L’usage doit être étudié sous plusieurs aspects :
par technologie : l’UL est construite en fonction du langage de programmation : python, java, framework .NET… Elle sera utilisée par les équipes et applications qui développent suivant ces technologies
par criticité de l’application : l’UL regroupe une ou plusieurs applications en fonction de sa criticité au sein de l’entreprise
par département : l’UL est considérée au niveau du département/direction. Les applications d’une même branche d’activité sont intégrées au sein de cette UL. Toutefois, il est possible de rationaliser les applications de plusieurs départements au sein d’une seule UL.
par type de plateforme et d’infrastructure : l’UL est utilisée par les applications se trouvant uniquement sur une infrastructure On-premise. Une autre UL est créée pour les applications hébergées dans le Cloud
Mettre en place plusieurs pipelines n’implique pas une totale autonomie de chaque équipe en matière de choix technologiques et de stratégie globale.
Avant de créer une UL, il est essentiel que les équipes coopèrent, partagent leurs décisions et alignent leurs savoir-faire pour le déploiement et le partage des connaissances : You build it, You run it (celui qui conçoit est aussi celui qui déploie), and You share it (et partage ses connaissances à travers des communautés de pratiques pour aligner les savoir-faire).
Par choix stratégique de l’entreprise, il arrive souvent que des applications fusionnent pour ne former qu’un seul et même outil. Si une seule usine logicielle ne gère pas initialement les applications, réévaluez le choix de l’usine pour réaliser les tests et se conformer aux risques de sécurité des différentes parties.
En revanche, il n’est pas nécessaire d’administrer plusieurs outils de gestion du code source sur le(s)quel(s) seraient raccordés le(s) pipeline(s).
Les possibilités sont nombreuses et la conception ne s’arrête pas à ces perspectives. Certains découpages seront plus favorables à l’entreprise en fonction de la maturité des équipes, de l’homogénéité des solutions, du budget, ou encore des enjeux métiers.
Pipeline CI/CD : Make or buy ?
Vaut-il mieux acheter une solution du marché, payer à l’usage, ou se créer sa propre pile technologique ?
Le choix relève d’une décision stratégique et est porté suivant plusieurs axes de réflexion :
La maturité de l’équipe DevOps : quel est le niveau d’expérience de l’équipe DevOps en place ?
Le nombre potentiel d’utilisateurs : vaut-il le coût de construire une UL pour une application à faible fréquentation ?
Les coûts de revient : combien l’UL va-t-elle coûter à l’année en termes d’infrastructure, de maintenance et d’exploitation ? Quel est le gain apporté en contrepartie ?
La compatibilité entre les outils pour une UL custom : un développement spécifique peut être nécessaire pour faire communiquer les outils entre eux
La capacité des logiciels et technologies à s’inscrire dans le temps
Ne sous-estimez pas l’effort et le coût nécessaire pour construire et maintenir un pipeline basé sur des logiciels open source (ex: GIT, Jenkins, SonarQube, Maven) : l’open source ne signifie pas nécessairement que c’est gratuit, mais que vous avez la possibilité de modifier et customiser le code source à votre convenance.
L’avantage d’utiliser une plateforme externalisée en mode PaaS ou SaaS (ex: Azure Devops, AWS CodePipeline, Google Cloud Build, GitLab) est de pouvoir immédiatement en tirer de la valeur. Certes, un outil propriétaire générera des coûts de licence ou d’utilisation, mais vous pourrez vous concentrer à 100% sur l’essentiel : délivrer de la valeur pour les métiers.
De plus, une solution orientée « As A Service » propose une chaîne d’outils “Tout-en-Un” et s’affranchit des risques d’obsolescence. Les mises à jour sont généralement transparentes pour les utilisateurs.
Les différences entre les logiciels open source et propriétaires vont bien au-delà de l’accessibilité du code source. Elles incluent également des éléments cruciaux tels que l’assistance technique, l’UX/UI, l’innovation, la sécurité et les coûts.
La réussite d’une organisation DevOps repose en grande partie sur une vision partagée à long terme et des ressources humaines et financières allouées à sa mise en place : auditez vos équipes et votre organisation !
Hébergement de l’UL : comment choisir entre On-Premise et Cloud ?
Pour identifier les applications de votre entreprise et celles éligibles à une automatisation, commencez par les localiser.
Selon la cartographie que vous établirez, une stratégie envisageable consisterait à mettre en place :
Une infrastructure DevOps On-premise pour déployer des applications hébergées sur site
Une infrastructure DevOps dans le Cloud pour déployer des applications également hébergées dans le Cloud
Cette option a notamment pour avantage de limiter la gestion des routes et des flux réseau.
Certains éditeurs proposent des solutions clé-en-main et gèrent la maintenance de l’UL à la place du client.
Même s’il peut y avoir des avantages à utiliser une plateforme “As A Service”, il faut néanmoins rester vigilant avant de se lancer. En effet, certaines peuvent couvrir plusieurs langages ou sont compatibles avec plusieurs fournisseurs Cloud, alors que d’autres vont chercher à vous verrouiller avec un fournisseur en particulier.
Aussi bien d’un point de vue de l’infrastructure que du logiciel, une étude est à mener et plusieurs éléments sont à prendre en considération.
Pour un outil propriétaire :
Veillez à la maturité de l’éditeur et de ses produits sur le marché, les services proposés, la couverture du support, le mode de licence et de tarification
Pour un outil open source :
Vérifiez leurs années d’existence, la communauté derrière ces logiciels et son degré d’investissement, la facilité pour monter de version et la stabilité des versions majeurs (fréquence de montée de version)
Pour les 2 types :
Contrôlez les systèmes d’exploitation supportés, la facilité d’installation et d’utilisation au quotidien (interface ‘user-friendly’), l’intégration avec les autres logiciels propriétaires ou open source, le type d’hébergement accepté (On-premise et/ou Cloud), l’accessibilité à l’UL par les différentes équipes internes et/ou externes
Organisez un REX : renseignez-vous auprès de votre réseau professionnel, mais également au sein de votre direction ou département. Il se pourrait qu’une autre entité de votre entreprise ait déjà installé une UL et qui corresponde à votre besoin ! Un retour d’expérience est une mine d’information qui pourra conforter ou orienter les décisions, évitant ainsi quelques études complémentaires à l’implémentation.
Stoplight est un outil de conception d’API qui permet aux développeurs de créer, de documenter et de tester des API de manière efficace et collaborative. Il embarque les fonctionnalités que l’on retrouve en partie sur les outils accélérateurs de développement d’API tels que Postman, SoapUI ou encore l’écosystème Swagger.
Quelles sont les caractéristiques spécifiques de l’outil et ses limites le cas échéant ?
Comment se positionne-t-il par rapport à des outils implémentant des fonctions comparables ?
Pexels – Thisisengeneering
Étape 1 : Créer un nouveau projet
Stoplight permet de créer de nouveaux projets sous la spécification OpenAPI. A noter que GraphQL ou AsyncAPI ne sont pas encore supportés. L’outil pouvant s’interfacer avec GitLab, GitHub, BitBucket ou encore Azure DevOps, il est aussi possible d’importer des projets existants.
Étape 2 : Définir l’API
Une fois le projet créé, il faut maintenant définir notre API. Il est possible soit de la créer (fichier format JSON ou YAML), soit d’importer un fichier de spécification OpenAPI, ou une collection Postman. Diverses versions d’OpenAPI sont supportées (2.0, 3.0 et 3.1 à l’heure de la rédaction de cet article).
On pourra définir des modèles d’objets communs à notre projet ou spécifiques à une API. L’édition des endpoints, des paramètres et des réponses se fera facilement soit en utilisant la vue formulaire, soit la vue code, dans tous les cas avec une preview en temps réel.
Pour bien garder à jour notre projet, en se branchant par exemple à GitHub, il est possible de configurer les échanges souhaités et ainsi de mettre à jour l’API à chaque changement de Git et vice-versa.
Étape 3 : Linter l’API
Le linting d’une API est une analyse de son code pour faire remonter des erreurs, warnings et incohérences, à la manière d’un compilateur.
Stoplight propose des style guides de linting par défaut qu’on peut ensuite modifier ou importer. Ces règles seront utilisées pour l’outil de linting intégré basé sur Spectral.
Cela permet de vérifier que la définition de l’API correspond aux bonnes pratiques du marché et aux méthodes spécifiques à l’entreprise.
La configuration du linting est évidemment modifiable à souhait. On pourra ainsi garantir plus facilement une cohérence accrue entre des API qui auraient été faites par diverses personnes, ainsi que réduire le nombre d’erreurs. D’où finalement une API de meilleure qualité.
Étape 4 : Documenter l’API
La documentation de l’API dans Stoplight est gérée via le composant open source Elements intégré à la plateforme. Suivant la spécification OpenAPI, on pourra facilement créer la documentation des endpoints, des réponses, le tout avec un environnement interactif et non figé.
De plus, Stoplight supporte les fichiers Markdown (dans l’onglet Docs) permettant de documenter l’API davantage. Cela offre la possibilité d’y intégrer du contenu non textuel : tableaux, images, diagrammes Mermaid ou contenu d’autres sites (Twitter, Youtube, Giphy, Spotify, etc.). La documentation n’en sera que plus riche et la découverte de votre API facilitée, d’où une meilleure adoption.
Étape 5 : Tester, sécuriser et déployer l’API
Il est possible de tester l’API à l’aide de fonctionnalités nativement intégrées dans l’outil. Ainsi la vérification de contrat sera t-elle automatique via le cross checking de la spécification Open API.
Stoplight propose une interface à travers laquelle écrire et exécuter des tests pour évaluer la réponse de chaque endpoint et méthode. Il est également possible d’utiliser le module Prism pour simuler les appels, dans un environnement de test minimal intégré.
La plateforme supporte les méthodes d’autorisation OAuth2 et OpenIDConnect. L’outil met à disposition une interface dans laquelle il est ainsi possible de déclarer la modalité de contrôle utilisée, le flow et les paramètres évalués (clé d’API, token, credentials)
Enfin l’outil intègre également l’utilitaire de ligne de commande NPM et permet de pousser les mises à jour d’une API sur l’interface de navigation de Stoplight. L’API sera alors sur le Studio Web.
Étape 6 : Générer du code
Une fois l’API testée et validée, vous pouvez utiliser Stoplight pour générer du code serveur et client à partir de votre définition d’API. En effet la plateforme est équipée d’un générateur de code (stubs serveur, configuration…) supportant plusieurs langages de programmation (notamment Java, JavaScript…).
Les capacités de Stoplight à l’heure de la rédaction de cet article sont cependant plus focalisées sur la documentation et les features de collaboration, et sont plus limitées sur la génération de code que celles d’un Swagger Codegen par exemple.
On peut noter pour conclure que Stoplight est un outil avec une couverture relativement large des fonctionnalités de conception et de construction d’une API. Il supporte également les standards d’implémentation en la matière (norme OpenAPI, flux de sécurisation avec OAuth et OIDC…).
Il répond de manière plus complète à des besoins en amont de conception et de développement. Cependant, il présente des limites. Il offre également une couverture moins importante sur des fonctions plus aval, telles que la publication et le contrôle plus fin d’accès à des ressources exposées par API.
Dans les précédents volets, nous avons expliqué ce qu’est une architecture MACH et dans quels cas elle exploite tout son potentiel.
Dans cet article nous allons décrire les 5 points fondamentaux à la mise en place d’une architecture MACH dans un contexte legacy.
Définir le parcours utilisateur et les points de bascule
Le parcours utilisateur est naturellement le point de départ de la création d’une architecture web, mais dans quelle mesure il me permet de la définir et de la concevoir ?
L’identification des différents points de bascule est primordiale pour identifier le découpage de l’architecture. Le “point de bascule” est une étape dans le parcours client qui nous permet de passer d’un contexte fonctionnel à un autre.
Pour identifier les points de bascule, pensez données
Le point important à retenir, pour assurer un bon découpage de l’application, est que ma donnée peut passer de mon navigateur (micro front-end) à mon application back-end (micro-service) jusqu’à mon back-office (SAP, etc.) sans avoir des dépendances et des liens qui se croisent. En gros, un micro-service qui fait appel à un autre micro-service, n’est plus un micro-service.
Pour cela, nous devons bien identifier les données impliquées dans chaque étape.
Bien que nous ayons des données qui semblent similaires, le découplage est garanti : l’information du panier n’est pas forcément persistée, c’est un “brouillon” de ma commande que je vais abandonner une fois qu’elle sera confirmée, il aura donc un cycle de vie différent avec une “fin de vie” au moment de la création de la commande.
Si nous voulons faire du micro-service, nous devons réfléchir au découpage des micro-services
Quand on parle de mise en place d’une architecture MACH, avec des back-office legacy, alors le découpage doit être adapté au contexte applicatif.
L’utilisation de la logique DDD (Domain Driven Design) ne doit pas s’abstraire de l’implémentation car quand on parle micro-service on parle bien de domaine métier mais également d’indépendance, etc. des principes qui découlent de choix d’implémentation.
Nous devons donc analyser les applications legacy et identifier les interactions qui seront nécessaires.
Ce découpage logique, simple, va créer le découplage entre mon application web, mon site eCommerce, et mes back office legacy, tout en exploitant leur potentiel et en créant des verticaux liés par le processus et indépendants dans leur conception et déploiement.
Penser déploiement et cloud-first
Bien que le Cloud ne soit pas une condition sinequanone, ces architectures se prêtent bien à un déploiement Cloud.
Les services managés des cloudeurs s’adaptent bien à ce type d’architecture. Nous pouvons parler ici de serverless (ex. AWS Lambda, Google Cloud Functions, etc.), de la containerisation dynamique (ex. AWS Fargate, Azure Containers) ou, bien que moins intéressant, de la simple virtualisation.
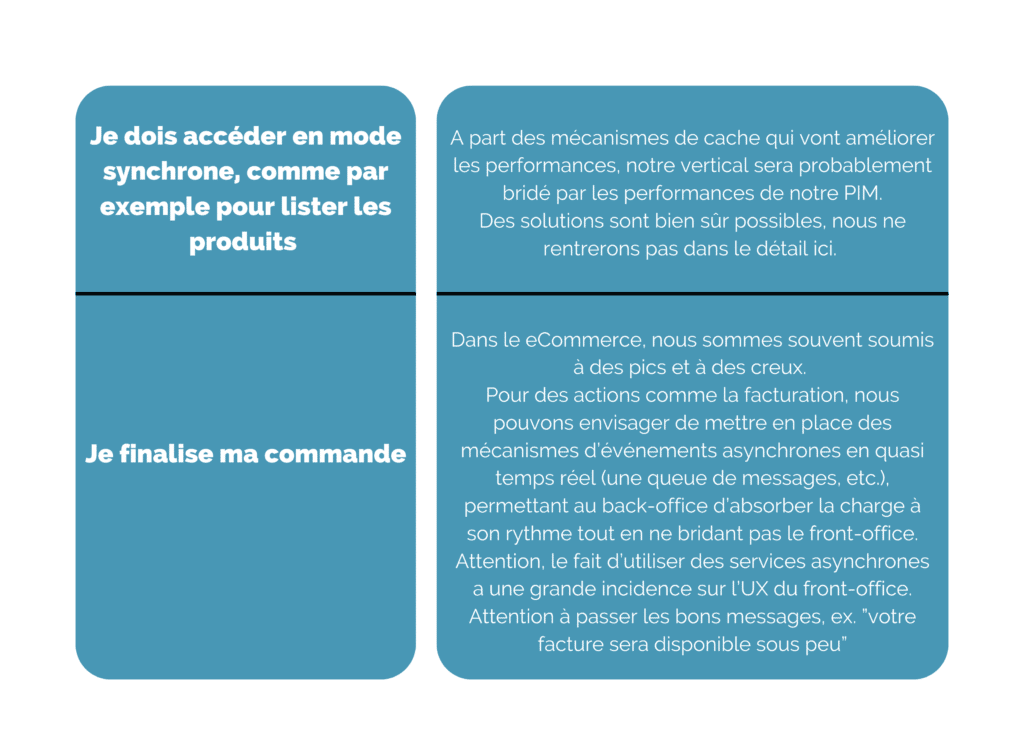
Mais attention, les systèmes legacy ne sont pas forcément scalables autant que nous le souhaiterions. Penser à la chaîne complète des intéractions n’est pas un luxe. Dans certains cas l’échange avec ces outils peut réduire notre potentiel de montée en charge.
Dans ces cas, pensons découplage front-office / back-office.
Voici deux cas de figure et des solutions possibles :
L’architecture MACH s’avère être une solution hautement pertinente pour les entreprises souhaitant accroître leur agilité et améliorer leur réactivité technologique. Malgré les défis que son adoption peut poser, notamment dans des contextes dominés par des systèmes hérités, les bénéfices en matière de personnalisation, de performance et de gestion de l’infrastructure sont incontestables. Les organisations doivent soigneusement évaluer leur capacité à intégrer cette architecture, en considérant leur environnement technique actuel et leurs objectifs futurs.
#2 DÉFINIR POURQUOI L’ARCHITECTURE MACH S’ADAPTE BIEN À L’ECOMMERCE
#2 DÉFINIR POURQUOI L’ARCHITECTURE MACH S’ADAPTE BIEN À L'E COMMERCE
3 juin 2024
Architecture
Erik Zanga
Manager Architecture
L’architecture MACH convient-elle à tous les métiers et cas d’usages, ou existe-t-il des situations où elle est plus avantageuse et d’autres où elle est moins adaptée ?
Pour répondre à cette question nous allons à nouveau décomposer ce style d’architecture dans ses 4 briques essentielles : Microservices, API First, Cloud First et Headless.
La lettre M : Micro-services
C’est probablement ce premier point qui dirige notre choix de partir vers une architecture MACH vs aller chercher ailleurs.
Nous pourrions presque dire que si l’architecture s’adapte à un découpage en Micro-services, le MACH est servi.
Pour aller un peu plus dans le détail, nous allons introduire le concept de “point de bascule” dans le parcours utilisateur. Nous définissons “point de bascule”, dans un processus, chaque étape qui permet de passer d’une donnée à une autre, ou d’un cycle de vie de la donnée à une autre.
Une première analyse pour comprendre si notre architecture s’adapte ou pas à une architecture MACH, est d’établir si dans le parcours utilisateur nous pouvons introduire ces points de bascule, qui permettent de découper l’architecture des front-end et back-end en micro front-end et micro-services.
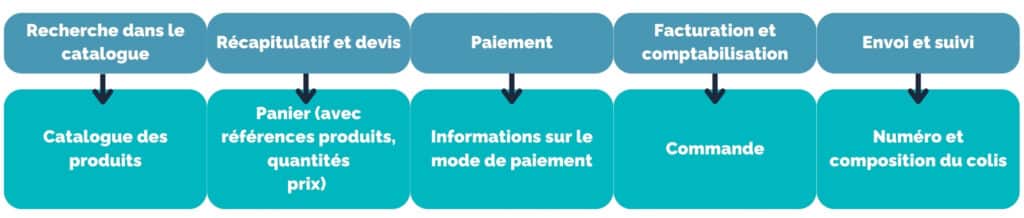
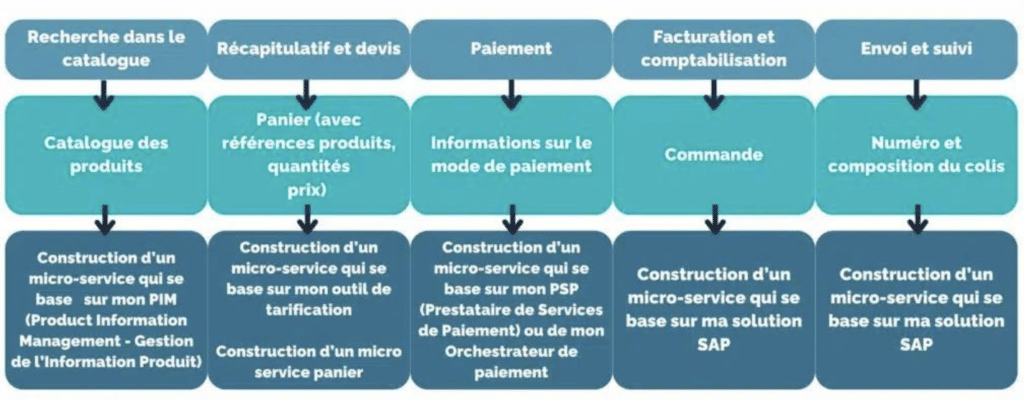
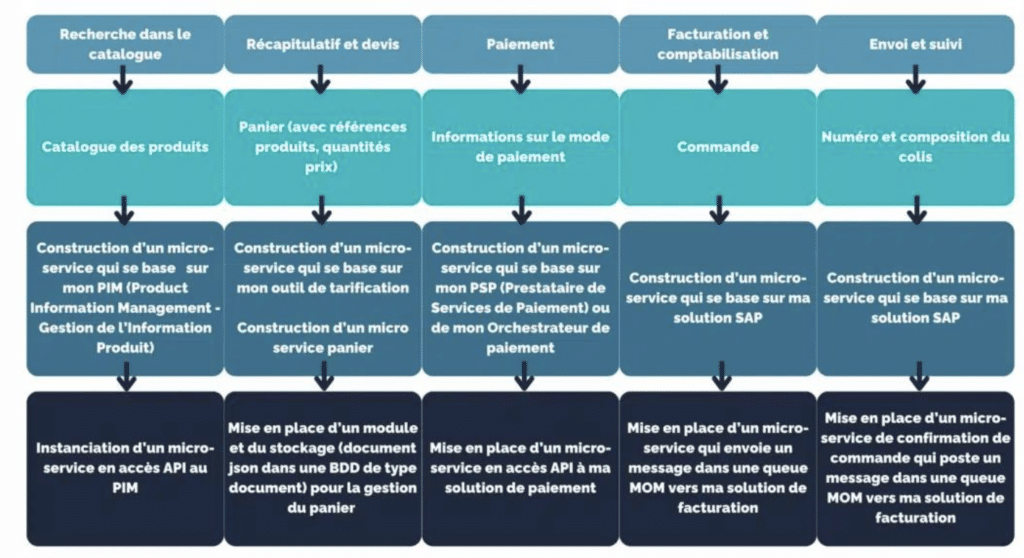
Un processus eCommerce par exemple s’adapte bien à ce type de raisonnement. Les étapes sont souvent découpée en :
Recherche dans le catalogue
Mise en panier
Confirmation
Paiement
Gestion de la livraison
Ces 5 étapes traitent les données de façon séparée, et sont donc adaptées à un découpage en Micro-services.
Résultat : Le “M” de MACH et l’efficacité de cette architecture est fortement liée au cas d’usage et au domaine d’application.
La lettre A : API-First
Qui parle web a forcément dû penser aux APIs, dans le sens de Rest API, pour garantir la communication entre front-end et back-end.
Pas de surprise que cela s’adapte à pas mal de solutions, car la communication entre le front-end (navigateur) et le back-end (application) se base sur le protocole HTTP et donc très adapté à ce type d’interface.
Nous ajoutons à tout ça le fait que la création d’un Micro-services et d’un Micro front-end, avec un découpage vertical sur les données traitées, implique naturellement la mise en place d’APIs et ressources spécifiques à chaque étape du parcours client.
Le contexte eCommerce, encore une fois, est bien adapté à ce cas de figure. Les étapes de parcours dont nous avons parlé avant s’inscrivent dans une logique d’APIsation, avec pour chacune d’entre elles une API dédiée.
Recherche dans le catalogue : adresser une API produits
Mise en panier : adresser une API panier ou devis
Confirmation : adresser une API commande
Paiement : adresser les APIs de paiement d’un prestataire (PSP, orchéstrateur de paiement, etc.)
Gestion de la livraison : adresser une API livraison
Résultat : Le “A” de MACH impacte moins que le “M” dans le choix de l’architecture mais épouse bien les concepts définis dans le “M”. Il est donc également très approprié pour un contexte eCommerce.
Pexels – ThisIsEngineering
La lettre “C” : Cloud-Native
Ce cas est probablement le plus simple : les seules raisons qui nous poussent à rester chez soi (infrastructure on premise), à ne pas s’ouvrir au cloud aujourd’hui sont de l’ordre de la sécurité, de l’accès et de la confidentialité de nos données (éviter le Cloud Act, etc.).
Au-delà de ces considérations, le passage au Cloud est une décision d’entreprise plus dans une optique d’optimisation de l’infrastructure que dans le cadre d’un cas d’usage, de processus spécifiques.
Résultat : Le “C” de MACH n’est pas d’un point de vue architectural pure une variante forte.
Néanmoins si nous regardons le cas d’usage cité auparavant, eCommerce, les restrictions sont levées car qui parle eCommerce parle naturellement d’ouverture, de mise à disposition sur le web, d’élasticité, concepts bien adaptés au contexte Cloud.
La lettre “H” : Headless
L’approche Headless convient particulièrement aux entreprises qui recherchent une personnalisation poussée de l’expérience utilisateur et qui ont la capacité de gérer plusieurs interfaces utilisateur en parallèle.
C’est le cas pour du eCommerce, où l’évolution rapide, le time to market et la réactivité au changements du marché peuvent influencer l’appétence, le ciblage du besoin client et le taux de conversion.
Résultat : Le « H » de MACH souligne l’importance de l’expérience utilisateur et de la flexibilité dans la conception des interfaces. Il est particulièrement avantageux dans les contextes où la personnalisation et l’innovation de l’interface utilisateur sont prioritaires. Cependant, il nécessite une réflexion stratégique sur la gestion des ressources et des compétences au sein de l’équipe de développement.
En somme, l’architecture MACH offre une grande flexibilité, évolutivité, et permet une innovation rapide, ce qui la rend particulièrement adaptée aux entreprises qui évoluent dans des environnements dynamiques et qui ont besoin de s’adapter rapidement aux changements du marché. Les secteurs tels que l’e-commerce, les services financiers, et les médias, où les besoins en personnalisation et en évolutivité sont élevés, peuvent particulièrement bénéficier de cette approche.
Cependant, l’adoption de l’architecture MACH peut représenter un défi pour les organisations avec des contraintes fortes en termes de sécurité et de confidentialité des données, ou pour celles qui n’ont pas la structure ou la culture nécessaires pour gérer la complexité d’un écosystème distribué. De même, pour les projets plus petits ou moins complexes, l’approche traditionnelle monolithique pourrait s’avérer plus simple et plus économique à gérer.
En définitive, la décision d’adopter une architecture MACH doit être prise après une évaluation minutieuse des besoins spécifiques de l’entreprise, de ses capacités techniques, et de ses objectifs à long terme.
L’architecture MACH, de par son acronyme, regroupe quatre pratiques courantes et actuelles dans le développement d’applications web.
C’est quoi Architecture MACH ?
Dans ce premier volet, nous allons nous concentrer sur les concepts fondamentaux qui composent ce concept : Microservices, API First, Cloud First, Headless, afin d’adresser l’objectif de chacun.
Tout d’abord un avis personnel, le fait de mettre ces concepts ensemble découle du bon sens : ce type d’architecture est considéré comme simple, efficace, intuitive, bien structurée, modularisée, bref… un travail que les vrais architectes doivent forcément apprécier !
Quid d’Amazon annonçant faire marche arrière pour Prime Video car la mise en application des micro-services implique un nombre d’orchestrations élevées ?
Les Micro-services, tels qu’expliqués dans d’autres articles (voir article micro-services), sont dans notre vision très fortement liés à un découpage DDD (Domain Driven Design).
Dans notre conception un micro-service définit un composant, dérivé d’un découpage métier et fonctionnel, agissant sur une donnée définie.
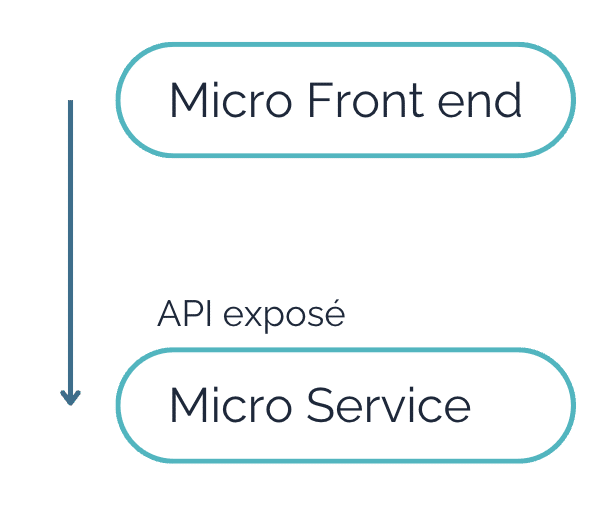
Le micro-service ne se limite pas uniquement à la partie back-end. Dans un contexte d’architecture web, il peut s’appliquer également au front-end.
Le Micro front-end et le Micro back-end se retrouvent intimement liés par une logique “composant d’affichage” et “composant qui traite applicativement la donnée affichée”.
Une architecture micro-services implique donc une certaine verticalité affichage, traitement et data.
API-First
C’est presque logique, on fait communiquer les différents composants par APIs.
Être API-first signifie d’intégrer la conception des APIs au cœur du processus de conception globale de l’application. Un peu comme si les APIs étaient le produit final.
Attention par contre, autant nous allons retenir l’API entre micro front end et micro back end, autant ce principe n’est pas partagé avec la communication entre le micro-service et d’autres composants du SI.
Une étude des différents patterns d’échange et un choix judicieux entre des méthodes synchrones et asynchrones est très importante pour éviter de mettre des contraintes fortes là où nous n’en avons pas besoin : pour partager une donnée avec les applications back office, tels qu’une confirmation de prise de commande avec un SAP, nous n’avons pas toujours besoin de désigner des flux synchrones ou API, nous pouvons par exemple découpler avec une logique de messaging, le cas d’usage nous le dira !
Cloud-First
Une vraie prédilection pour le Cloud, que du buzzword ?
En réalité, le fait de mettre en avant du Cloud dans cette démarche n’est que du bon sens.
Nous pouvons mettre en place une architecture on premise, pourquoi pas, mais dans certains cas il s’agit d’un vrai challenge : mise en place des serveurs, déploiement de la couche OS, des services, de la partie VM ou Container, etc.
Le Cloud First des architecture MACH vise la puissance des services managés, rapides de déploiement, scalables et élastiques, sur lesquels le déploiement en serverless ou en conteneur et la mise en place des chaînes CI/CD sont en pratique les seules choses à maîtriser, le reste étant fourni dans le package des fournisseurs de services cloud !
HEADLESS
Le Headless représente une tendance croissante dans le développement web et mobile. Cette approche met l’accent sur la séparation entre la couche de présentation, ou « front-end », et la logique métier, ou « back-end ». Cette séparation permet une plus grande flexibilité dans la manière dont le contenu est présenté et consommé. Elle offre ainsi une liberté de création sans précédent aux concepteurs d’expérience utilisateur et aux développeurs front-end.
Dans un contexte Headless, les front-ends peuvent être développés de manière indépendante. Les développeurs peuvent utiliser les meilleures technologies adaptées à chaque plateforme. Cela s’applique au web, aux applications mobiles, aux assistants vocaux, et à tout autre dispositif connecté. Cette approche favorise une innovation rapide. Cela permet aux entreprises de déployer ou de mettre à jour leurs interfaces utilisateur sans avoir à toucher à la logique métier sous-jacente.
La question qui nous vient à l’esprit maintenant est :
Ce type d’architecture s’applique à tout cas d’usage ? Certains sont plus réceptifs que d’autres de par leur configuration, gestion du parcours utilisateur ?