
13 novembre 2019
– 4 min de lecture
Erik Zanga
Manager Architecture
Le phénomène d’API GraphQL est en progression, aujourd’hui sommes-nous prêts à abandonner à nouveau tout ce qui a été fait sur les API ces 15 dernières années et passer à un nouveau concept d’intégration ? Le GraphQL est-il une option viable pour remplacer l’API telle que nous l’avons définie jusqu’à aujourd’hui ?
Qu’est ce que le graphql ?
Le GraphQL se résume par la mise à disposition d’une interface de requêtage qui s’appuie sur les mêmes technologies d’intégration utilisées par les API REST. Nous allons toujours passer par le protocole HTTP et par un payload de retour, préférablement au format JSON, mais la différence pour le client repose sur le contrat d’interface.
Si nous essayons de vulgariser, les réponses apportées par le REST et le GraphQL à la même question sont fondamentalement différentes.
Analysons la question suivante : qui es-tu ?
Voici comment elle serait abordée par Rest et par le GraphQL
Le REST :
- QUESTION : qui es-tu ?
- REPONSE : voici ma pièce d’identité (ni plus, ni moins)
Le GraphQL
- QUESTION : quels sont ton nom, prénom, date de naissance, adresse de résidence, lieu de travail et tes coordonnées personnelles ?
- RÉPONSE : voici toutes ces informations ciblés (et tu peux avoir encore plus de détails si tu veux, en une seule fois)
On a affaire ici à un changement radical dans la manière d’aborder les requêtes.
Ce qui reste central : la data
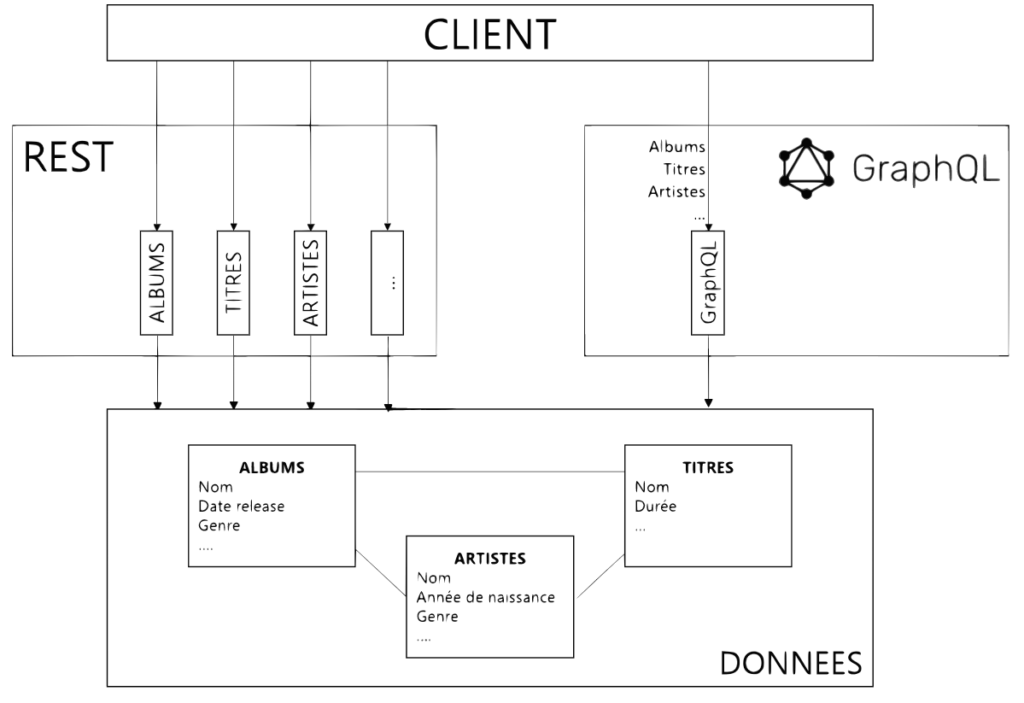
La DATA reste l’élément central de la réflexion autour du GraphQL. Sur ce point, nous pouvons voir l’héritage venant des paradigmes du REST, avec une focalisation sur la ressource. Alors que les pratiques précédentes, comme le SOAP, étaient plus axées “action”, le GraphQL est très axé sur la DATA, l’objectif primaire étant la manipulation de la donnée et pas l’exécution d’une opération.
Le concept de DATA est cependant présenté différemment. Elle n’est pas contrainte par une structure strictement définie à l’avance mais il est désormais possible de la naviguer par l’API GraphQL, ce qui change complètement le concept du contrat d’interface.
Il n’y a donc plus de contrat d’interface ?
Nous pourrions en déduire que le contrat d’interface, très cher aux démarches SOAP et REST, n’est plus d’actualité pour le GraphQL…
Notre vision se résume en une simple phrase : ”Le contrat d’interface change de forme. Il n’est plus centré sur la structure de l’information retournée par l’API mais s’intéresse au modèle de données lui-même”
Le contrat d’interface s’appuie sur le modèle de données qui devient encore plus crucial puisqu’il est maintenant directement exposé / connu par les clients de l’API. Pour rappel, nous avons défini le GraphQL comme un langage de requêtage qui s’appuie sur la structure de la donnée définie dans notre schéma de modélisation. Bien qu’une couche d’abstraction ne soit pas totalement à exclure, le modèle de données, défini dans nos bases de données et exposé aux clients (par introspection ou connaissance directe), devient le point de départ de toute requête.
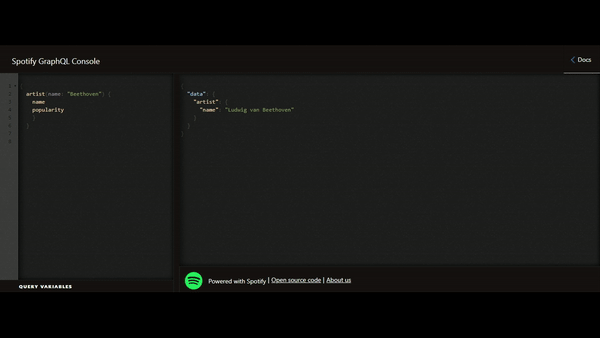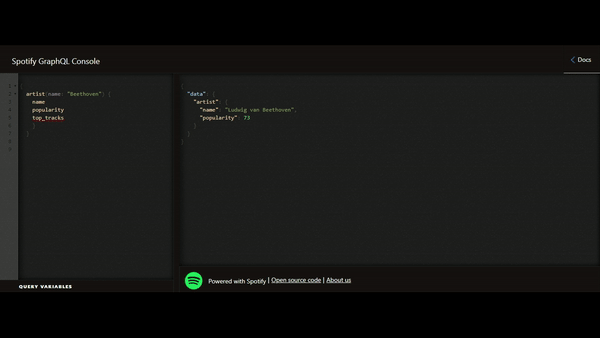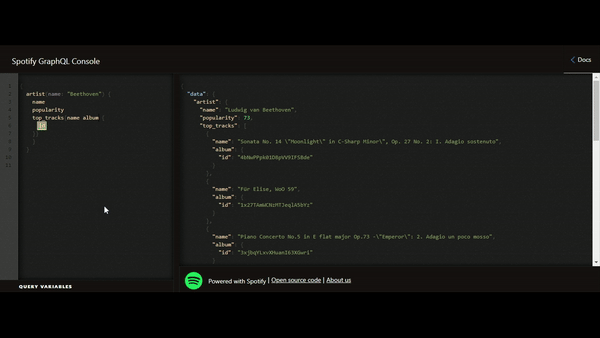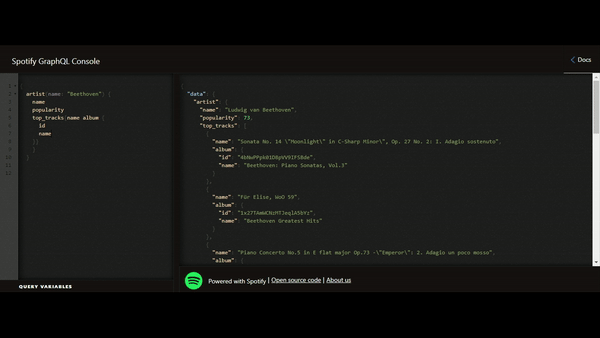
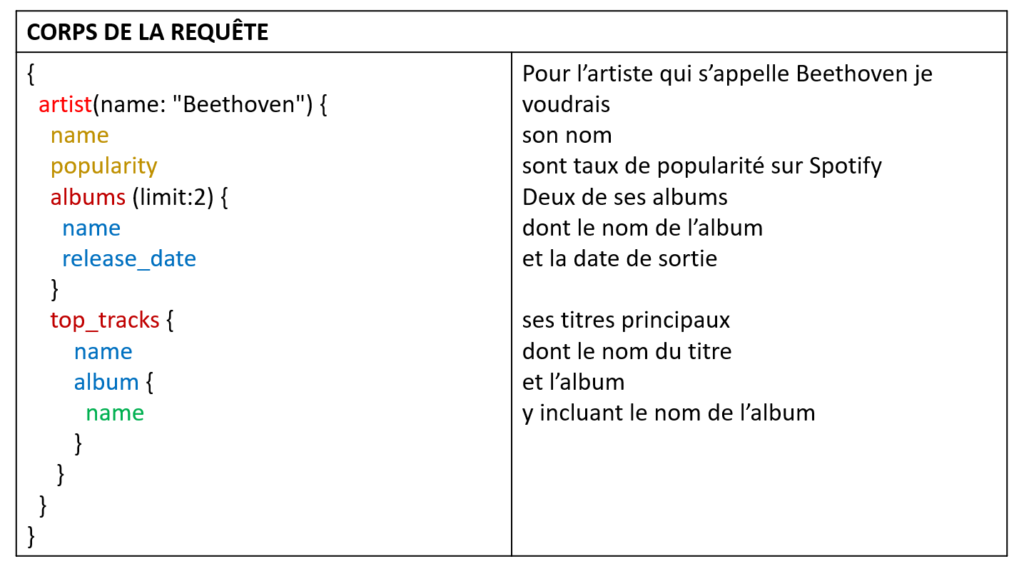
Voici un exemple de lecture issu de l’API GraphQL Spotify :

Des avantages…
Cela saute aux yeux, la flexibilité est le grand avantage apporté par le GraphQL. Nous ne sommes plus contraints par le retour de données défini par le fournisseur de l’API mais uniquement par la donnée qui nous est mise à disposition. Cela permet de réduire le phénomène de l’underfetching (obligation d’utiliser plusieurs appels car un seul ne permet pas de remonter la totalité des informations nécessaires) et de l’overfetching (récupération de plus de données par rapport au besoin réel), vrais casse-têtes lors de la conception des APIs.
L’autre vrai avantage est la rapidité de mise en œuvre. Sans vouloir rentrer dans la réalisation, la mise à disposition d’une API classique a toujours comporté des longues périodes de réflexion sur le périmètre, le découpage, la profondeur des données retournées. Ces phases de réflexion qui, sans un besoin clair en face, avaient tendance à se prolonger et à réduire le Time-To-Market des APIs. GraphQL permet de pallier ces problèmes :
- En libérant le fournisseur de l’API de cette lourde tâche de conception,
- En évitant la multiplication des APIs sur le même périmètre,
- En facilitant le choix du périmètre de la part du consommateur, sans qu’il soit forcément obligé d’orchestrer plusieurs requêtes afin obtenir ce dont il a besoin, sans limites théoriques.
…mais aussi des contraintes
La liberté donnée au client de l’API est certainement un avantage pour les deux parties mais apporte également des contraintes de sécurisation et de gestion de la charge serveur.
La charge
Une API, REST ou SOAP, est globalement maîtrisée. Elle a un périmètre bien défini et donc la seule question à se poser porte sur la volumétrie et/ou la fréquence d’appel. Le GraphQL, par le fait que les requêtes sont variables, réduit la prévisibilité de la charge associée :
- La non-prédictibilité des requêtes expose au risque de retours complexes et volumineux, sans pagination, ce qui pourrait mettre en difficulté une infrastructure mal dimensionnée ;
- L’utilisation du cache est complètement révolutionnée / complexifiée, car la probabilité d’avoir la même requête de deux différents consommateurs est très faible et ne permet donc pas de s’appuyer complètement sur le cache pour décharger les machines.
La sécurité
Dans l’ancienne conception nous pouvions avoir des niveaux de sécurité induits par le périmètre restreint de l’API.
Le GraphQL, de par la liberté d’exploration des données, oblige à une réflexion plus profonde sur la question des habilitations et de l’accès aux informations. Cette sécurisation doit être garantie par une sorte de “douane” qui se définie comme la couche par laquelle nous devons transiter pour accéder aux données, et qui gère directement les droits d’accès par utilisateur.
Cette pratique n’est pas nouvelle, elle devrait accompagner toute démarche API, toutes technologies confondues. La couche de sécurisation et d’habilitations devrait toujours être indépendante de l’exposition de l’API. Parfois, un défaut de conception non identifié de cette couche de sécurité était pallié, tant bien que mal, par la limitation de périmètre imposé par l’API or cette limitation n’existe plus avec le GraphQL.
Conclusion
GraphQL représente la tentative la plus intéressante de “flexibiliser” la gestion des APIs et apporte une nouvelle dynamique à celle-ci, tout en respectant les contraintes induites par ce mode d’intégration.
Si l’objectif n’est pas forcément de “tout casser”, pour recommencer tout en GraphQL, cette approche devient une alternative concrète aux démarches API dites “classiques”.Exemple en est la mise en application de cette méthode d’intégration sur une plateforme de paiement, Braintree, filiale de Paypal.
