En combinant MCP et A2A, on passe d’un ensemble d’agents et de ressources isolés à un écosystème cohérent, interopérable et scalable, où l’accès aux données et la coordination des agents sont contrôlés, réutilisables et auditables.
Avant l’utilisation de serveurs MCP, l’accès pour un client IA à des ressources extérieures à son environnement se faisait le plus souvent avec des techniques peu robustes et peu standardisées entre écosystèmes IA différents.
L’entrée en scène des LLM dans les échanges entre systèmes d’information a relevé le fait que l’existant en termes d’échange de données n’est que très peu adapté à ce nouvel acteur. Les premières méthodes permettant à un hôte IA de rechercher des informations auprès de sources extérieures ont permis de mettre en lumière les problèmes structurels de l’approche première.
Contexte Pré-MCP
Le principal problème de l’approche initiale est qu’elle nécessitait un couplage fort entre le framework IA d’une part et d’autre part les APIs et autres ressources externes qui, elles, pouvaient être amenées à évoluer indépendamment. Ce couplage rendait la maintenance des intégrations une préoccupation persistante pour le développeur d’une solution IA.
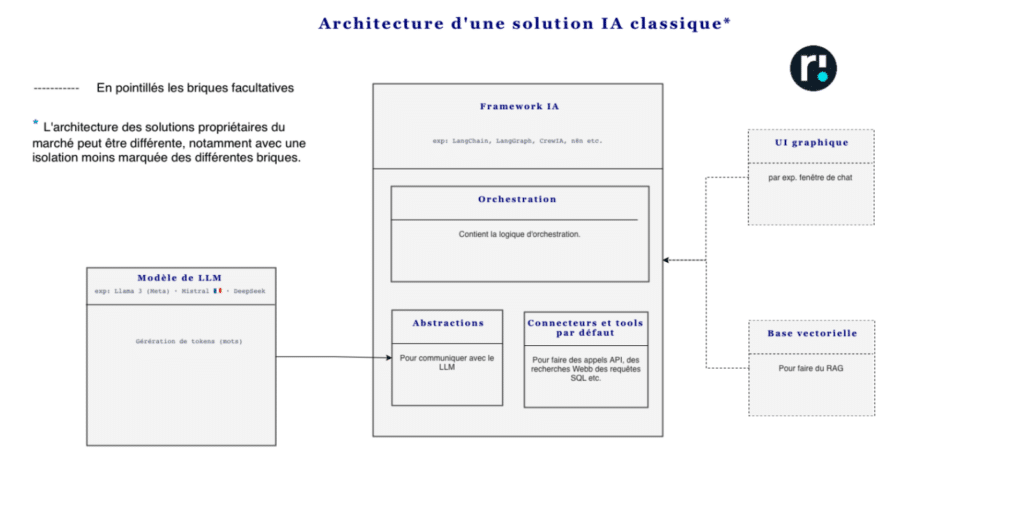
Afin de comprendre comment un hôte ou agent IA communique avec des API externes, il est nécessaire de comprendre la séparation entre la couche LLM (qui émet des tokens) et le framework IA qui permet la logique autour de l’interaction avec le modèle.
La couche LLM est la couche basique de génération de tokens, elle ne comprend qu’une suite de tokens et ne renvoie qu’une autre suite de tokens. Elle n’a accès ni à des API externes, ni aux fonctions qui permettent de les appeler.
C’est le framework IA (langChain, AutoGPT etc.), qui fera le lien entre la “volonté” ou “action” exprimée en langage naturel par le LLM, et l’exécution de cette action.
Pour cela le Framework IA, comprend une bibliothèque interne de tools, qui permettent d’effectuer les appels ou requêtes nécessaires.
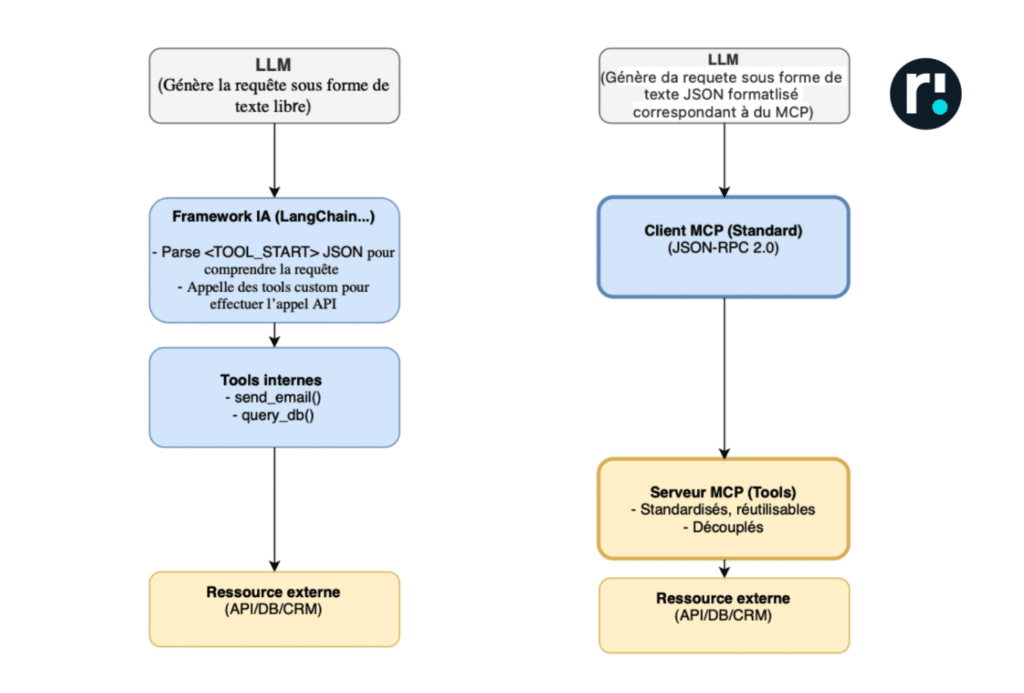
Le workflow de récupération de ressources externes par un hôte IA, pré-MCP était le suivant:
La Définition des capacités: La liste des tools disponibles à l’utilisation, ainsi que les exigences sur le format d’instruction attendu est transmise au LLM par le framework via le System Prompt .
L’interception et exécution de la commande: Il existe plusieurs paradigmes pour intercepter une commande émise par un LLM. Celui que nous décrirons ici repose sur le principe suivant : lorsque, au cours de sa génération de texte, le LLM s’apprête à déclencher un appel vers une action externe, il émet une “signal” textuel – différent d’un framework à l’autre, indiquant qu’un tool doit être invoqué.
Ce signal informe l’orchestrateur que la suite de la génération ne correspond plus à du texte libre, mais à une structure attendue, généralement un objet JSON. Le framework peut alors parser le JSON via des regex ou un parseur dédié, identifier le tool à invoquer ainsi que les arguments à rattacher. Il peut alors exécuter l’action en lançant par exemple un script python écrit et stocké dans le framework.
“signal”
{
"name": "send_email",
"arguments": {
"recipient": "bob@example.com",
"subject": "Urgent",
"body": "Bonjour Bob, voici les infos demandées."
}
}
“signal”
Exemple de génération LLM demandant au framework l'envoi d'un email.
Renvoi de la réponse: Une fois le résultat de la requête réceptionnée, le framework envoie le résultat (ex: “Email envoyé avec succès. Heure: 12h34), qu’il le renvoie au comme System prompt ou Contexte supplémentaire au LLM, qui peut alors répondre à l’utilisateur “C’est fait, l’email a été envoyé à Bob.”
Problématiques intrinsèques
Intégration sur mesure pour chaque ressource exploitée: Chaque API ou base (CRM, météo, paiement, DB interne, etc.) nécessite une intégration spécifique, qui plus est doit être faite et maintenue au niveau du framework IA et diffère donc d’un framework à l’autre.
Duplication: L’intégration et les tools ne sont que très peu ou pas réutilisés, et sont repensés pour chaque framework même si la donnée à récupérer est la même
Maintenance explosive: Le moindre changement de contrat d’API imposait de modifier le tool ou même le schéma de function calling, avec risque de régressions silencieuses.
Solution apportée: le MCP
Le MCP (Model Context Protocol) est un protocole ouvert proposé par Anthropic fin 2024 et qui propose une nouvelle façon pour une source de donnée quelconque, d’exposer ses informations de sorte à pouvoir être exploitées de façon plus fluide par un hôte IA.
Pour cela il propose plus qu’un langage d’échange différent (le MCP repose sur JSON-RPC, qui est déjà connu et éprouvé). Son apport réel réside dans un changement de paradigme : on passe d’un modèle où l’hôte IA va chercher l’information directement chez chaque source via des intégrations spécifiques, à un modèle où les sources de données exposent leurs capacités et leurs informations via des serveurs MCP standardisés.
Comparatif de l’architecture avant et après MCP – L’exposition de la donnée est faire côté source de donnée, via un serveur MCP qui va exposer de façon compréhensible par tout client utilisant du MCP, les données qu’elle veut exposer.
On observe ici un déplacement de l’effort d’intégration et de maintenance : il passe de l’intérieur des frameworks IA vers l’extérieur, en couplant le point d’entrée MCP directement à la source de données. Une fois instancié et maintenu, le serveur MCP devient alors mutualisable et peut être consommé par autant de clients MCP que nécessaire, qu’il s’agisse d’hôtes IA, d’applications, d’IDE ou de tout autre service compatible avec le format MCP.
Ce changement de paradigme qu’apporte le protocole MCP permet de solutionner une partie des problèmes qui se présentaient avant.
Standardisation de l’intégration: L’intégration, via le serveur MCP est écrite une seule fois, et est utilisée indépendamment du framework ou du modèle utilisé.
Mutualisation et réutilisabilité : Un serveur MCP peut être consommé par plusieurs clients sans réécriture spécifique. La logique d’accès à la donnée n’est plus dupliquée pour chaque framework. On sépare clairement la couche d’orchestration de la couche d’accès aux ressources.
Isolation des évolutions et réduction du couplage : Les changements d’API sont traités dans le serveur MCP. Le contrat client et serveur reste stable et un seul serveur exposant la donnée est à maintenir à jour;
Le A2A: Communiquer entre Agents IA
Comme le MCP la communication entre Agents se faisait via un mode de communication prévu alors pour les échanges entre systèmes déterministes “traditionnels” et non entre LLM.
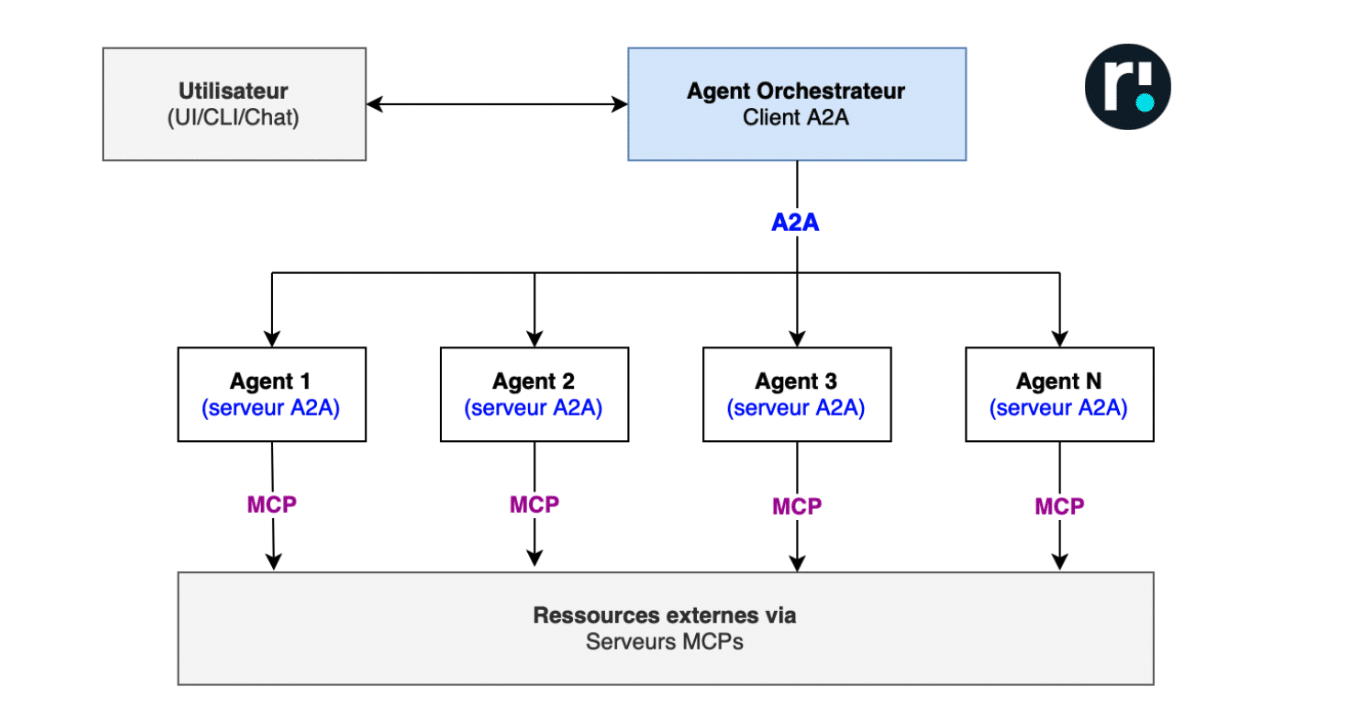
Le protocole A2A, développé par Google apparaît peu après le MCP et se veut explicitement complémentaire: MCP gère l’accès aux ressources pour un agent et A2A coordonne la communication et la délégation entre réseau d’agents.
Pourquoi le A2A
Si nous prenons l’exemple d’une architecture multi agents centralisée (Orchestrateurs et subordonnés). L’agent principal va vouloir déléguer ses tâches à d’autres agents soit
Spécialisés: pour lui permettre d’acquérir des compétences et expertises supplémentaires.
Génériques: pour lui permettre de paralléliser et déléguer ses tâches
Le protocole A2A va permettre de standardiser cette communication et dynamiser la découverte de capacités, c’est-à-dire permettre à l’agent orchestrateur de savoir quelles sont les capacités des agents à sa disposition afin de filtrer/sélectionner le bon agent pour chaque usage.
Concrètement, il va permettre à chaque agent d’exposer une “Agent Card” qui joue de rôle de fiche descriptive ou carte d’identité listant ce que l’agent sait faire et comment l’utiliser.
Dans cette fiche descriptive, l’agent indique les contraintes et capacités, par exemple les limites d’accès, les scopes autorisés, ou les prérequis pour invoquer une fonction.
Le A2A prévoit notamment la gestion de scopes et permissions, l’authentification envers les agents et un de suivi en temps réel (streaming, notifications) des tâches déléguées, entre autres capacités.
Le A2A comme solution
Le protocole A2A répond à un besoin nouveau : faire communiquer un réseau d’agents, majoritairement pilotés par des LLM, de manière à la fois standardisée et maîtrisée. Concrètement, il permet :
Standardisation et déterminisme : le standard permet une certaine maîtrise des échanges et de l’exposition des agents. Cela malgré le comportement intrinsèquement non déterministe et parfois chaotique des LLMs.
Gouvernance et observabilité : La standardisation des règles et du mode de communication entre agents se complète d’autres mécanismes comme le suivi des échanges grâce à du monitoring ainsi que des audit trails par exemple.
Interopérabilité plug-and-play : Les agents “encapsulés” de façon standard peuvent rejoindre ou quitter un réseau sans nécessiter de réécriture des intégrations.
Scalabilité : La résultante de ces différents mécanismes est une délégation et coordination plus efficaces entre agents, qu’ils soient spécialisés ou génériques, et ce même dans des réseaux complexes.
Ainsi, A2A transforme un ensemble d’agents en un écosystème coopératif, contrôlable et extensible.
Conclusion
En combinant MCP et A2A, on passe d’un ensemble d’agents et de ressources isolés à un écosystème cohérent, interopérable et scalable, où l’accès aux données et la coordination des agents sont contrôlés, réutilisables et auditables. Ces protocoles ouvrent la voie à des architectures multi-agents robustes, capables de gérer des réseaux complexes d’IA tout en garantissant sécurité, standardisation et évolutivité. Les capacités apportées par l’IA générative et encadrées par ces deux protocoles permettent d’élargir encore plus le champ des possibles en envisageant une industrialisation à large échelle de l’IA générative.
Terraform, grand favori du public concernant les logiciels d’Infrastructure as Code est connu principalement comme étant Cloud Agnostic. Mais le connaissez-vous réellement ? Terraform c’est près de 5000 fournisseurs de plateformes, infrastructure ou Saas allant bien au-delà du Cloud et un rachat récent soulevant un problématique de souveraineté.
Quelles sont les limites de cet outil qui paraît pouvoir tout faire ? Comment marche t-il et où se trouve sa prévalence par rapport à ses concurrents ? Sa place de favori est déjà remise en question et cette dynamique semble bel et bien en marche..
Le fonctionnement de Terraform ainsi que ses limites
Bien que Terraform soit souvent qualifié d’outil cloud agnostic, cela ne signifie pas pour autant que le même code peut être déployé tel quel sur AWS, Azure ou OVH. En réalité Terraform nécessite une configuration spécifique pour chaque (cloud) provider.
Pour bien comprendre cette nuance, il est essentiel de revenir sur le fonctionnement de Terraform et de clarifier ce que signifie réellement le terme cloud – ou provider – agnostic dans ce contexte.
Terraform utilise le langage HLC (Hashicorp Langage Configuration) pour communiquer avec les plateformes des fournisseurs. Cette communication se fait par le biais d’appels vers les APIs mis en place par ces fournisseurs. En théorie Terraform peut communiquer avec toute plateforme ou service qui expose une API. Mais bien évidemment la plupart des plateformes dont on parle sont intégrées via des “providers Terraform”.
Les APIs des fournisseurs, que ce soit niveau protocole, services exposés, champs requis etc diffèrent les uns des autres entraînant inéluctablement une différence au niveau de la suite d’instructions demandée à Terraform pour chaque provider.
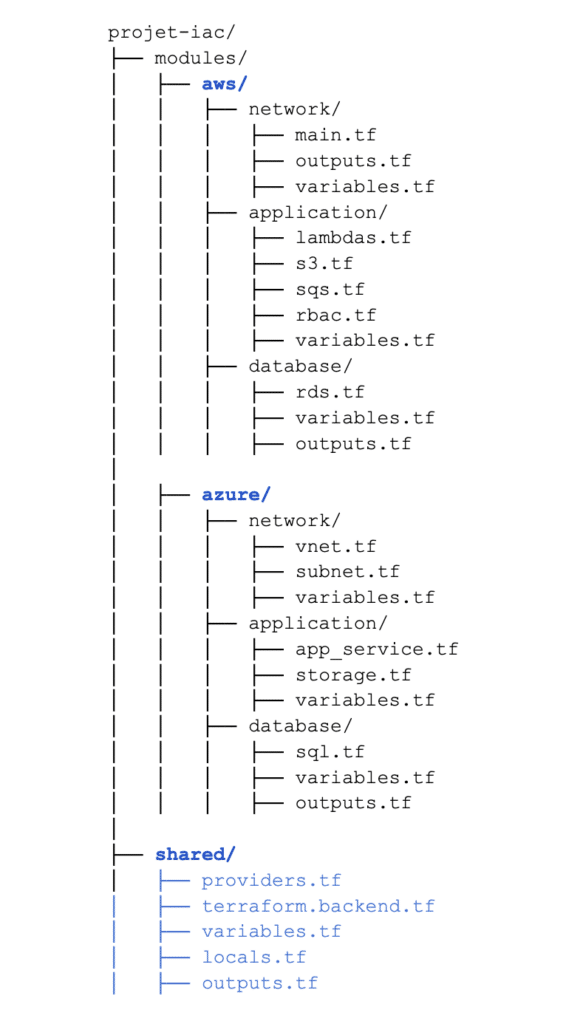
Comme on peut le voir dans l’arborescence suivante, on devra typiquement créer un dossier spécifique à chaque provider, en plus d’un dossier partagé pour des variables plus globales.
Le fait d’avoir tous les providers décrits dans le même projet nous permet d’établir une logique et des conditions sur quand et comment utiliser chaque provider. Terraform a bien évidemment d’autres avantages.
Utilisez pleinement Terraform
On l’a dit Terraform c’est près de 5000 providers dont les solutions souveraines OVH, Scaleway ainsi que les incontournables Kubernetes, Datadog, AWS, GitHub etc.
Cette diversité permet :
De combiner des infrastructures on-premise et cloud, permettant de gérer au même endroit l’intégralité des ressources d’un projet hybride.
En corollaire, optimiser les coûts en mettant en concurrence les services des différents fournisseurs (exp. stockage dans AWS, bases de données dans GCP)
Créer des configurations spécifiques et réutilisables: En choisissant d’exposer certains modules comme point d’entrée, l’équipe OPS ou Opérationnelle peut offrir aux équipes de développeurs une façon simple de créer des ressources en masquant toute la logique propre au fournisseur à l’intérieur desdits modules.
Exemple: Ici on implémente les modules application, database etc avec toute leur complexité “cachée”
De plus, Terraform est de type déclaratif, c’est-à-dire qu’il décrit l’état final de l’infrastructure: l’ordre dans lequel on déclare les ressources n’est donc pas important, ce qui peut faire une préoccupation technique en moins.
Enfin, Terraform permet de réduire la courbe d’apprentissage lors du lancement ou du basculement d’un projet vers de l’IaC.
Nous le verrons dans les lignes suivantes, l’IaC est également une façon non négligeable d’optimiser ses ressources.
Optimisation des ressources, résilience et numérique durable
Les outils d’IaC quels qu’ils soient permettent de décrire comment construire et donc reconstruire une infrastructure simplement en exécutant un code. Cette facilité offre de la résilience: si l’infrastructure est corrompue, il suffit de la reconstruire en ré-exécutant le code versionné “avant incident”.
Un autre avantage est qu’on peut se permettre de détruire totalement notre infrastructure au moment où l’on en a pas besoin, pour la reconstruire aussitôt que le besoin s’en re-fait sentir. Cela implique que l’on peut supprimer notre environnement de dev ou de pré-prod le week-end ou le soir en fin de journée pour la reconstruire à l’identique le lundi matin.
Cette économie de ressources génère des optimisations financières notamment pour les services facturés à l’heure et une utilisation plus responsable des ressources.
Souveraineté de la plateforme
L’acquisition récente de Hashicorp (la société derrière Terraform) par IBM pose un problème au niveau de la souveraineté.
Terraform propose trois offres :
Terraform CLI : Communautaire (chacun peut créer/rajouter un provider) et “Open Source” (voir note en fin d’article)
HCP Terraform : Terraform version SaaS, hébergé sur la plateforme Cloud de Terraform: la Hashicorp Cloud Platform
Terraform Enterprise : La version hébergeable dans nos propres datacenters ou cloud privés.
En matière de souveraineté, la discussion s’articule ici autour de la version Communautaire Terraform CLI qui, en plus d’être la plus populaire, est la seule qui ne soit pas propriétaire.
Ce rachat de Terraform par IBM donc, pourrait entraîner des changements de licences dans la version communautaire. Le mot d’ordre pourrait peu à peu devenir l’accroissement des bénéfices commerciaux au détriment de la communauté Terraform.
Et pour cela, pas forcément besoin d’un revirement de situation à 180°, des décisions à priori anodines pourraient contraindre la liberté d’agir sur la version communautaire et ainsi inciter à se tourner vers les versions payantes.
De plus, IBM ayant également sa propre plateforme Cloud, l’entreprise pourrait mettre celle-ci en avant, au détriment du multi-cloud à la Terraform. (1)
A noter le parallèle flagrant avec le rachat de Red Hat par IBM en 2019.
Vous avez la main…
La souveraineté des données est une préoccupation majeure de notre temps et force est de noter que la communauté est très résiliente à s’efforcer de proposer des solutions Open Source dès lors que celle-ci est menacée.
Depuis le changement en 2023 de la license de Terraform CLI, la version “Open Source” de Terraform vers la license BSL (Business Source License) qui restreint les usages à but de compétition commercial directe, une solution dérivée nommée Open TOFU a vu le jour et continue de prendre de l’ampleur avec le rachat récent.
Il est vrai que IBM assure à ce jour sur le site Hashicorp que Terraform CLI restera “Always Free”, mais les adages “la confiance n’exclut pas le contrôle”, “il ne faut pas pas mettre tous ses oeufs dans le même panier non souverain”, ainsi que le principe du “zero trust”, sont autant de beaux préceptes qu’il serait prudent de garder à l’esprit.
Articles qui pourraient vous intéresser
GÉRER SES DÉPENSES CLOUD: UNE INTRODUCTION AU FINOPS
GÉRER SES DÉPENSES CLOUD: UNE INTRODUCTION AU FINOPS
12 décembre 2024
Architecture
Samira Hama Djibo
Consultante
Dans cette ère où les infrastructures Cloud et on premise se côtoient et se toisent, le critère de la rentabilité est déterminant. Cependant là où le Cloud nous promet des économies à petite mais surtout à grande échelle, on peut parfois tomber sur des mauvaises surprises une fois la facture reçue.
Quelle que soit la taille de l’architecture Cloud, on n’est jamais vraiment à l’abri d’un dépassement budgétaire inattendu. Mais en appliquant quelques principes simples du FinOps, on peut arriver à facilement minimiser ce risque.
Comment donc suivre efficacement ses dépenses ? Et comment optimiser financièrement son infrastructure Cloud ?
Nous allons ici nous appuyer sur le Cloud Provider AWS pour étayer nos propos ainsi que nos exemples.
Pourquoi est-ce qu’on peut se retrouver avec des factures plus importantes qu’attendu ?
Une des particularités d’une infrastructure Cloud, c’est qu’il est très facile de commissionner des ressources. Prenons a contrario une architecture on-premise: pour commissionner un serveur physique et installer des machines virtuelles, ce n’est souvent pas une mince affaire. Il faut choisir un fournisseur, lancer la commande et souvent attendre plusieurs mois sans compter d’éventuels problèmes logistiques.
De plus, la commande d’un serveur on-premise est souvent conditionnée par une étude minutieuse des caractéristiques nécessaires du serveur en question et une étude de budget à valider, réétudier etc.
En comparaison, la commande d’un serveur avec les mêmes caractéristiques sur le Cloud se fait en quelques clics, même pour un non-initié, et la disponibilité est immédiate.
La promesse du Cloud, c’est de pouvoir héberger tout aussi bien une architecture basique (comme par exemple un site web statique) qu’ une architecture extrêmement complexe répondant à des besoins spécifiques et des contraintes exigeantes. L’un des principaux clients d’AWS, l’entreprise Netflix responsable de 15% du trafic internet mondial, stocke jusqu’à 10 exaoctets (10 millions de téraoctets) de données vidéo sur le serviceAmazon S3. Ce chiffre inclut les copies stockées dans différentes régions afin d’assurer la haute disponibilité du service ainsi que sa résilience en cas de panne dans un des data centers d’AWS.
Une telle variance des offres et des possibilités que permettent le Cloud rend facile d’allouer des ressources largement supérieures à celles nécessaires, ou souscrire à des options qui, normalement conçues pour des cas très précis, font augmenter votre facture de façon apparemment démesurée..
Qu’on utilise l’interface graphique du Cloud Provider, ou alors un outil d’Infrastructure As Codecomme Terraform ou CloudFormation, sans la maîtrise suffisante au moment de l’allocation des ressources, ou par simple erreur humaine, on peut réquisitionner des ressources largement au-dessus de nos besoins, et donc se faire surprendre par une facture exorbitante.
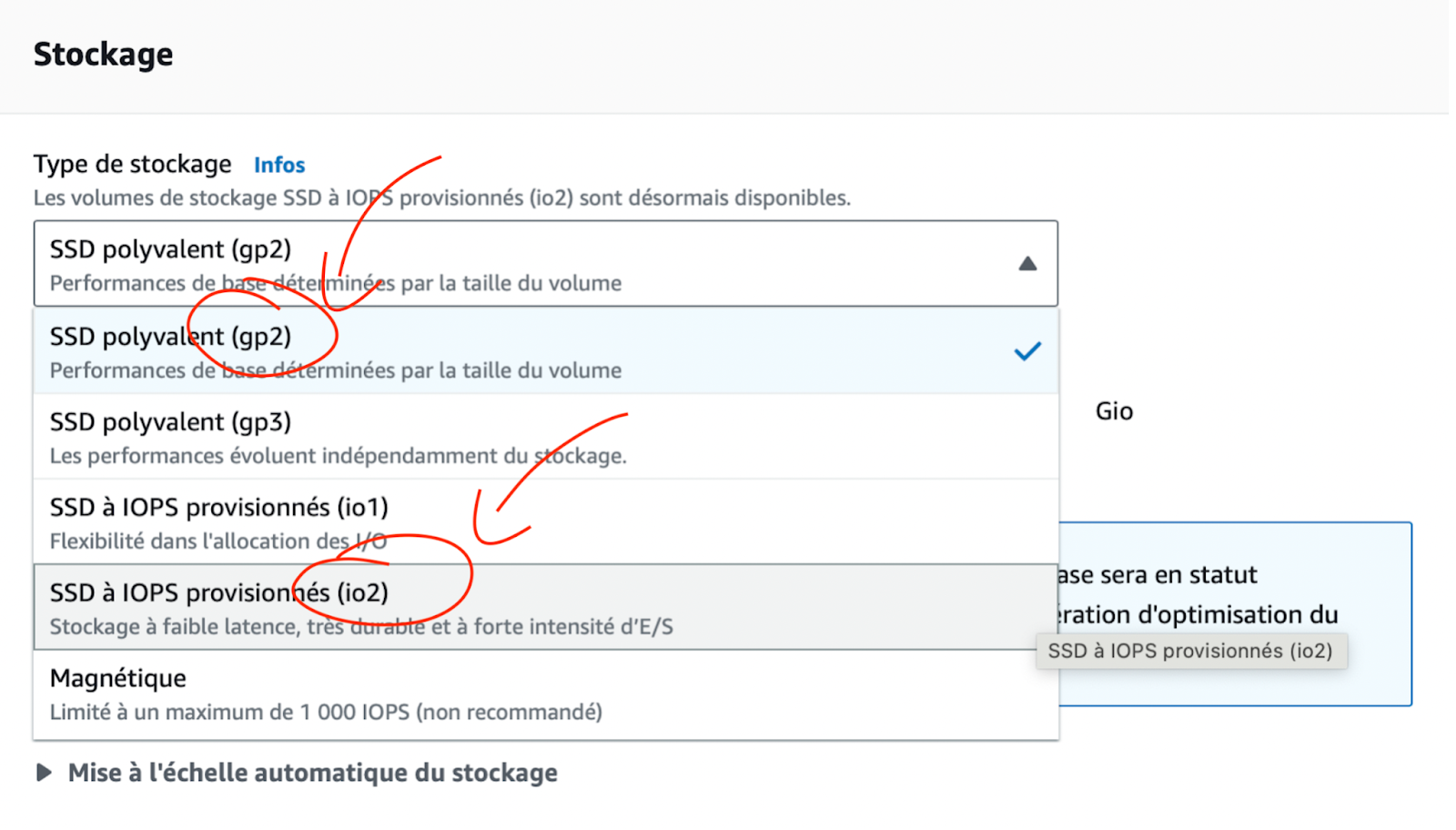
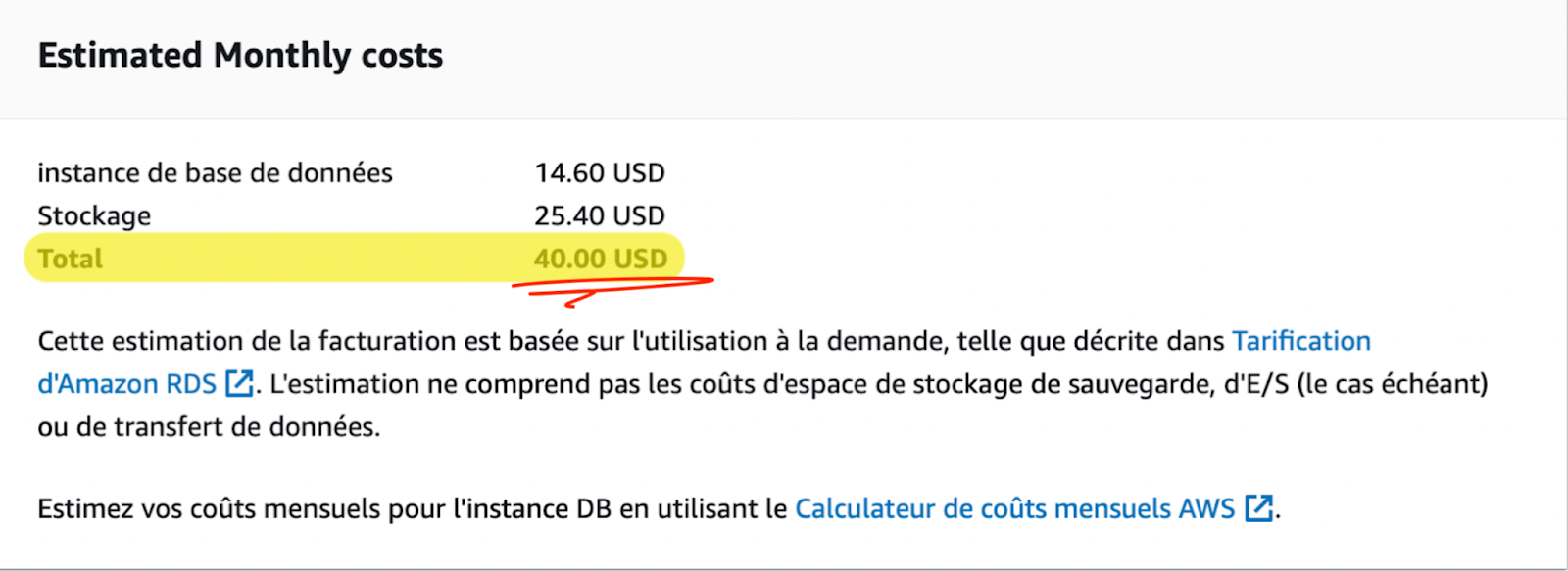
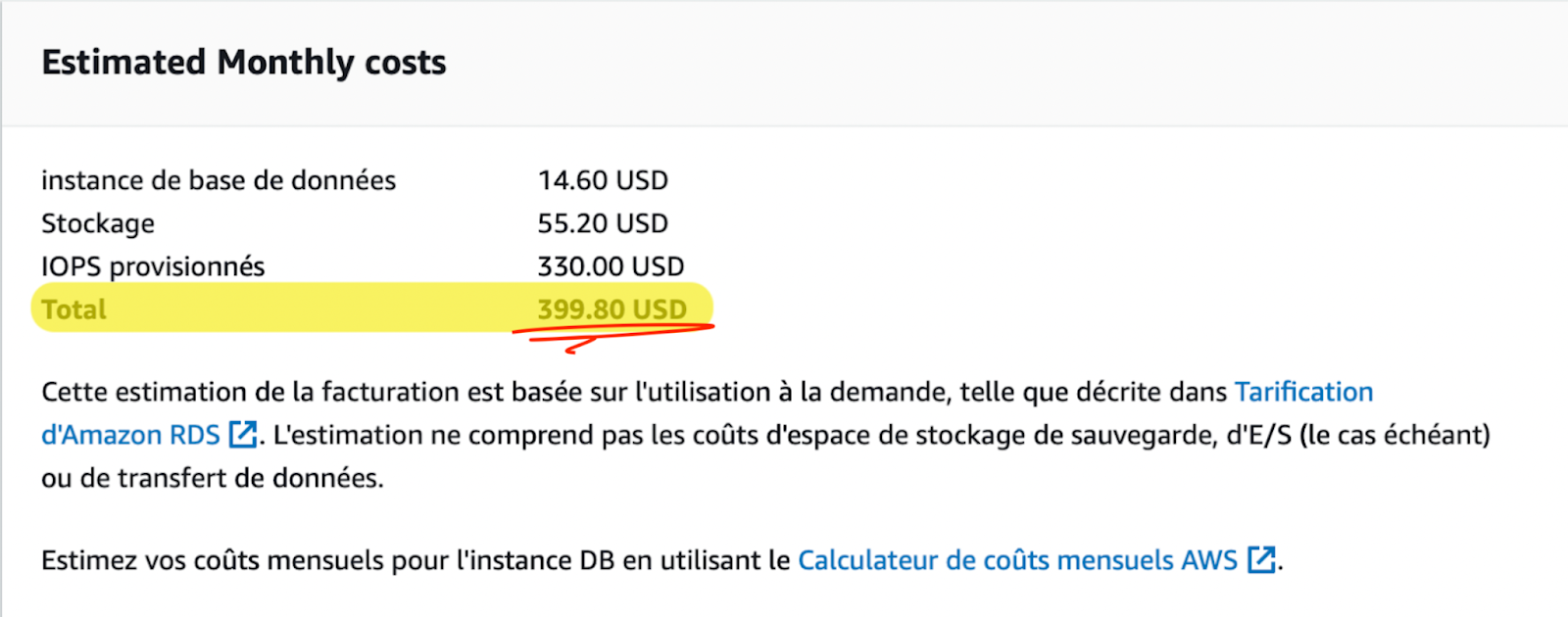
Pour illustrer ce point, prenons par exemple l’allocation d’une petite base de données via l’interface graphique d’AWS. Pour les mêmes caractéristiques de vCPU et de RAM, en choisissant par erreur, ou en méconnaissance de nos besoins réels, un stockage io2 au lieu de gp2, on multiplie tout simplement la facture par 10 !
Pour bien maîtriser les coûts, il faut donc tout d’abord une bonne maîtrise des termes techniques, du vocabulaire spécifique au Cloud Provider et ne pas se perdre dans des options trop avancées.
Une fois cela pris en compte, il faut noter que ces mêmes cloud providers mettent à disposition des outils qui permettent de facilement détecter et limiter l’impact d’erreurs de jugement ou d’implémentation.
Les solutions mises en place par les cloud providers pour pallier à ce problème
AWS a mis en place le Well-Architected Framework qui sert de guide pour la conception d’applications dotées d’infrastructures sûres, hautement performantes, résilientes et efficientes.
Le framework est basé sur six piliers: excellence opérationnelle, sécurité, fiabilité, efficacité de la performance, optimisation des coûts et durabilité.
Le pilier Optimisation des coûts qui nous intéresse le plus ici est axé sur l’évitement des coûts inutiles.
A toutes les échelles, des services sont mis en place par AWS pour faciliter l’implémentation de ce pilier. Leur connaissance et leur utilisation permettent sans faute d’optimiser le coût de son architecture.
Nous allons voir ici les approches de base qui permettent de s’assurer à un cadrage et une compréhension exhaustive de sa facture cloud et en amont l’optimisation des ressources allouées.
Il existe pour cela trois approches complémentaires:
Surveillance et budgétisation de ses dépenses,
Limitation des accès au strict nécessaire,
Optimisation des ressources avec des méthodes comme par exemple:
Le rightsizing: Le rightsizing est le processus consistant à adapter les types et tailles d’instances ni plus ni moins qu’aux exigences de performance et de capacité de la charge de travail.
Par exemple, cela peut se traduire par le fait de faire appel à de l’auto-scaling qui est la possibilité d’ajouter et supprimer des instances d’une ressources (scalability) ou augmenter et diminuer la taille de ces instances (elasticity) en fonction de l’utilisation en temps réel qui en est faite. Lorsque la charge de travail augmente, plus de ressources sont allouées, et lorsqu’elle diminue, une partie des ressources allouées est libérée.
.
Voici un autre exemple de rightsizing: Dans un projet les environnements de développement et de test sont généralement utilisés uniquement 8h par jour pendant la semaine de travail. Il est donc possible d’arrêter ces ressources lorsqu’elles ne sont pas utilisées pour réaliser des économies potentielles de 75 % (40 heures contre 168 heures).
L’utilisation de Saving Plans & Reserved instances: Prévoir et réserver à l’avance les ressources dont on aura besoin sur 1 ou 3ans permet de faire des économies jusqu’à 72% ! L’utilisation de Spot Instances – des instances éphémères – permet, elle, des économies jusqu’à 90% !
L’utilisation des classes de stockage dont on verra un exemple détaillé plus bas.
Voici quelques pratiques et services incontournables suivant ces différentes approches :
Surveiller et budgétiser ses dépenses
AWS Cost Explorer
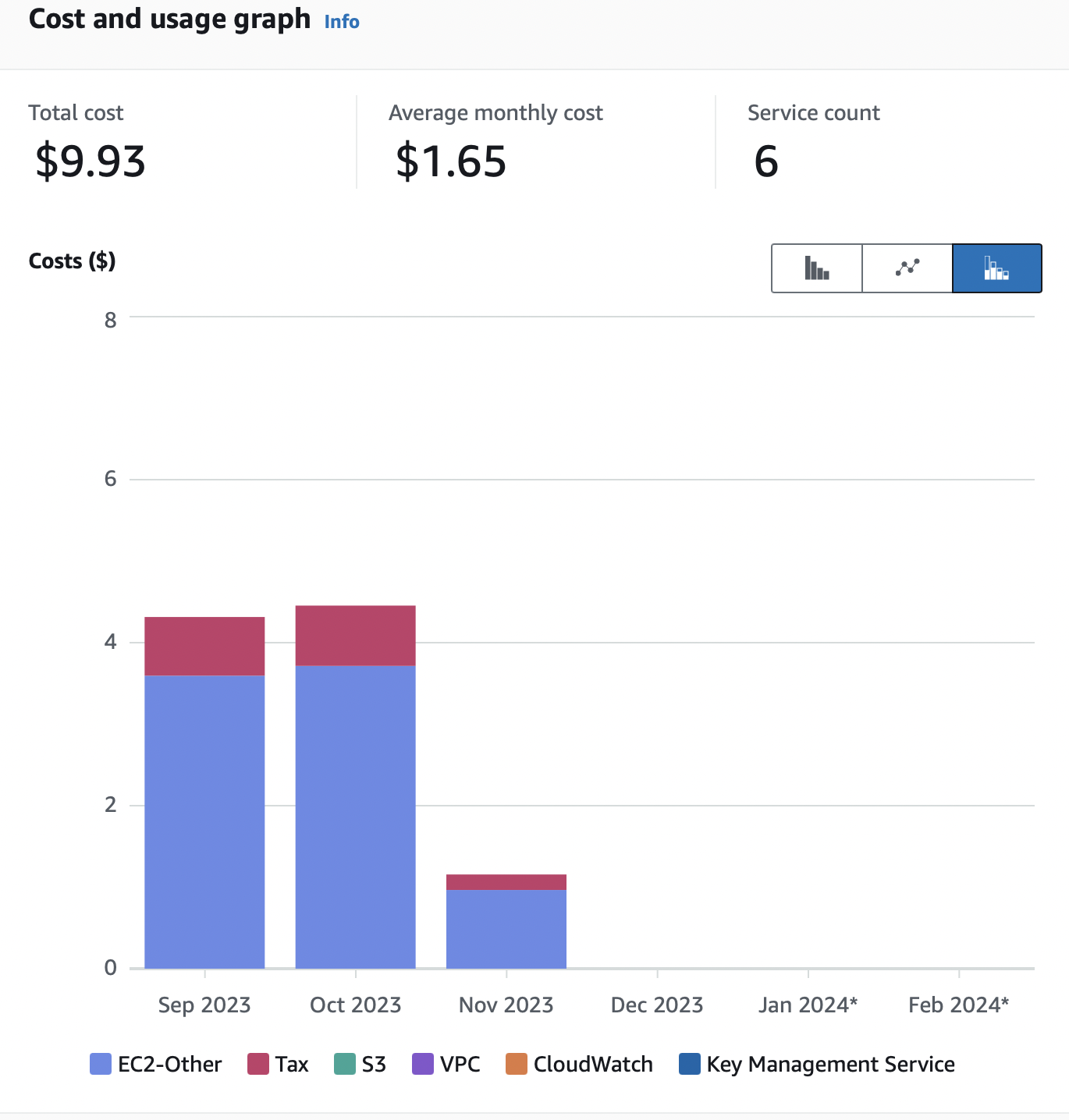
C’est une solution de Cost Analysis Dashboard qui permet de voir en temps réel sur une certaine période le total des dépenses par services utilisés.
Exemple d’un Cost Analysis Dashboard
AWS Budgets
AWS Budgets permet de créer des Budgets de dépense et de les exporter notamment sous forme de rapports. Des alertes sont levées et des emails envoyés lorsque les budgets sont dépassés.
AWS Cost Anomaly detection
Grâce au machine learning, AWS peut détecter une augmentation anormales des dépenses qu’il serait plus difficile de repérer manuellement.
Parmi les services de gestion de coûts proposés par AWS, on voit que ceux présentés ici, gratuits et mis en place par défaut, permettent déjà à eux trois d’obtenir une vue assez synthétique de ses dépenses et d’être alerté en cas de potentielles anomalies.
Limiter les accès au strict nécessaire
Un des principes de base qu’il s’agit de sécurité est la limitation au maximum des accès aux ressources au strict minimum et uniquement aux personnes accréditées (principe du RBAC). Ce même principe permet de réserver la création de ressources sensibles qui peuvent, comme on l’a vu, faire rapidement monter la facture aux personnes qui sauront faire bon usage de ces droits..
Que ce soit cloud ou hors cloud, la règle est la même : le least privilege access, c’est-à-dire limiter les droits au strict minimum, en fonction du rôle, du groupe d’appartenance, et même pour les grosses organisations en fonction du département ou du sous compte AWS depuis laquelle la requête est faite.
En plus de monitorer et contrôler ses dépenses, le cloud offre plusieurs possibilités d’optimisation des coûts dont voici un exemple.
Exemples d’optimisations possibles: les classes de stockage
Prenons comme exemple une boite de finance qui stocke les dossiers de leurs clients, tout comme notre géant Netflix sur le service de stockage Amazon S3.
Au début de la procédure, les dossiers sont consultés très souvent, plus le dossier avance, moins ils sont consultés, une fois clôturés ils sont archivés. Chaque année les services d’audit consultent les dossiers archivés. Après 10 ans, ils ne sont pratiquement jamais consultés mais doivent être conservés pour des raisons légales.
AWS met en place des classes de stockage en fonction de la fréquence d’utilisation des fichiers permettant ainsi de réduire les coûts sur les fichiers qui sont plus rarement consultés.
Ainsi nous mettrons les les dossiers en cours dans la classe S3 standard, puis dans la classe S3 Standard Infrequent Accessau fur et à mesure qu’ils sont moins consultés. Une fois le dossier clôturé, nous le déplaçons dans une des classes S3 Glacier à accès instantané ou flexible. Puis une fois la période d’Audit passée, nous les archivons finalement dans la classe S3 Deep Glacier aux coûts de stockage les plus bas.
A noter que nous pouvons également déposer les fichiers directement dans la classe S3 Intelligent Tiering dans laquelle AWS se chargera automatiquement de déplacer les fichiers dans les classes les plus rentables en fonction de l’utilisation réelle constatée.
Par exemple, pour la région Europe(Irlande), les tarifs en fonction des classes sont les suivants :
S3 Standard
S3 Infrequent access
S3 Glacier
S3 Deep Archive
Prix par GB/mois
0,021€
0,011€
0,0033€
0,00091€
Frais de récupération des fichiers ?
Non
Non
Oui
Oui
En analysant le besoin ou en faisant appel aux Intelligent Tiering d’AWS, nous pouvons donc économiser jusqu’à 100% du prix standard de stockage / Gb et par mois pour les fichiers les moins consultés.
Nous avons vu ici une partie des optimisations financières rendues possibles en faisant levier de la puissance du Cloud. Les labs du Well-Architected Framework mis fournis par AWS permettent de voir de façon concrète les voies d’optimisation des coûts présentées par le Cloud provider lui-même.
En plus de l’application des principes essentiels vu dans cet article, vous pourrez creuser facilement le sujet à cette adresse.
En guise de conclusion, je me permets d’appuyer sur le fait que la connaissance à minima basique des principes fondamentaux du FinOps comme décrits dans cet article est essentielle autant au développeur qu’à l’architecte en passant par le management et la finance. C’est uniquement cette collaboration étroite qui permettra une surveillance à toutes les échelles des coûts engendrés et une optimisation financière d’un projet Cloud.