
11 mars 2026
– 7 minutes de lecture
Samira Hama Djibo
Consultante
MCP: Accéder à des ressources extérieures
Avant l’utilisation de serveurs MCP, l’accès pour un client IA à des ressources extérieures à son environnement se faisait le plus souvent avec des techniques peu robustes et peu standardisées entre écosystèmes IA différents.
L’entrée en scène des LLM dans les échanges entre systèmes d’information a relevé le fait que l’existant en termes d’échange de données n’est que très peu adapté à ce nouvel acteur. Les premières méthodes permettant à un hôte IA de rechercher des informations auprès de sources extérieures ont permis de mettre en lumière les problèmes structurels de l’approche première.
Contexte Pré-MCP
Le principal problème de l’approche initiale est qu’elle nécessitait un couplage fort entre le framework IA d’une part et d’autre part les APIs et autres ressources externes qui, elles, pouvaient être amenées à évoluer indépendamment. Ce couplage rendait la maintenance des intégrations une préoccupation persistante pour le développeur d’une solution IA.
Afin de comprendre comment un hôte ou agent IA communique avec des API externes, il est nécessaire de comprendre la séparation entre la couche LLM (qui émet des tokens) et le framework IA qui permet la logique autour de l’interaction avec le modèle.
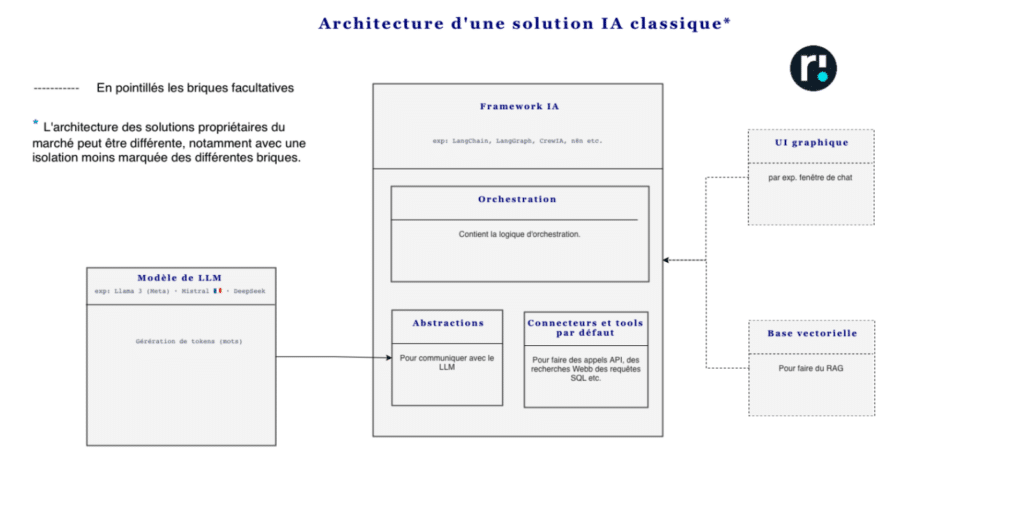
La couche LLM est la couche basique de génération de tokens, elle ne comprend qu’une suite de tokens et ne renvoie qu’une autre suite de tokens. Elle n’a accès ni à des API externes, ni aux fonctions qui permettent de les appeler.
C’est le framework IA (langChain, AutoGPT etc.), qui fera le lien entre la “volonté” ou “action” exprimée en langage naturel par le LLM, et l’exécution de cette action.
Pour cela le Framework IA, comprend une bibliothèque interne de tools, qui permettent d’effectuer les appels ou requêtes nécessaires.
Le workflow de récupération de ressources externes par un hôte IA, pré-MCP était le suivant:
- La Définition des capacités: La liste des tools disponibles à l’utilisation, ainsi que les exigences sur le format d’instruction attendu est transmise au LLM par le framework via le System Prompt .
- L’interception et exécution de la commande: Il existe plusieurs paradigmes pour intercepter une commande émise par un LLM. Celui que nous décrirons ici repose sur le principe suivant : lorsque, au cours de sa génération de texte, le LLM s’apprête à déclencher un appel vers une action externe, il émet une “signal” textuel – différent d’un framework à l’autre, indiquant qu’un tool doit être invoqué.
Ce signal informe l’orchestrateur que la suite de la génération ne correspond plus à du texte libre, mais à une structure attendue, généralement un objet JSON. Le framework peut alors parser le JSON via des regex ou un parseur dédié, identifier le tool à invoquer ainsi que les arguments à rattacher. Il peut alors exécuter l’action en lançant par exemple un script python écrit et stocké dans le framework.
“signal”
{
"name": "send_email",
"arguments": {
"recipient": "bob@example.com",
"subject": "Urgent",
"body": "Bonjour Bob, voici les infos demandées."
}
}
“signal”
Exemple de génération LLM demandant au framework l'envoi d'un email.- Renvoi de la réponse: Une fois le résultat de la requête réceptionnée, le framework envoie le résultat (ex: “Email envoyé avec succès. Heure: 12h34), qu’il le renvoie au comme System prompt ou Contexte supplémentaire au LLM, qui peut alors répondre à l’utilisateur “C’est fait, l’email a été envoyé à Bob.”
Problématiques intrinsèques
- Intégration sur mesure pour chaque ressource exploitée: Chaque API ou base (CRM, météo, paiement, DB interne, etc.) nécessite une intégration spécifique, qui plus est doit être faite et maintenue au niveau du framework IA et diffère donc d’un framework à l’autre.
- Duplication: L’intégration et les tools ne sont que très peu ou pas réutilisés, et sont repensés pour chaque framework même si la donnée à récupérer est la même
- Maintenance explosive: Le moindre changement de contrat d’API imposait de modifier le tool ou même le schéma de function calling, avec risque de régressions silencieuses.
Solution apportée: le MCP
Le MCP (Model Context Protocol) est un protocole ouvert proposé par Anthropic fin 2024 et qui propose une nouvelle façon pour une source de donnée quelconque, d’exposer ses informations de sorte à pouvoir être exploitées de façon plus fluide par un hôte IA.
Pour cela il propose plus qu’un langage d’échange différent (le MCP repose sur JSON-RPC, qui est déjà connu et éprouvé). Son apport réel réside dans un changement de paradigme : on passe d’un modèle où l’hôte IA va chercher l’information directement chez chaque source via des intégrations spécifiques, à un modèle où les sources de données exposent leurs capacités et leurs informations via des serveurs MCP standardisés.
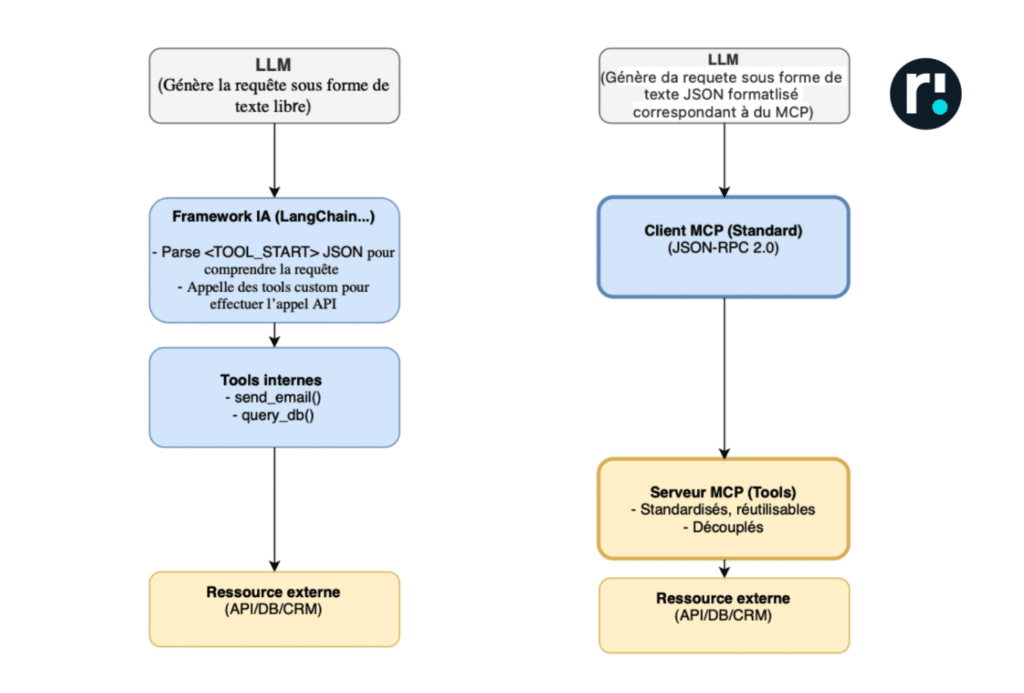
Comparatif de l’architecture avant et après MCP – L’exposition de la donnée est faire côté source de donnée, via un serveur MCP qui va exposer de façon compréhensible par tout client utilisant du MCP, les données qu’elle veut exposer.
On observe ici un déplacement de l’effort d’intégration et de maintenance : il passe de l’intérieur des frameworks IA vers l’extérieur, en couplant le point d’entrée MCP directement à la source de données. Une fois instancié et maintenu, le serveur MCP devient alors mutualisable et peut être consommé par autant de clients MCP que nécessaire, qu’il s’agisse d’hôtes IA, d’applications, d’IDE ou de tout autre service compatible avec le format MCP.
Ce changement de paradigme qu’apporte le protocole MCP permet de solutionner une partie des problèmes qui se présentaient avant.
- Standardisation de l’intégration: L’intégration, via le serveur MCP est écrite une seule fois, et est utilisée indépendamment du framework ou du modèle utilisé.
- Mutualisation et réutilisabilité : Un serveur MCP peut être consommé par plusieurs clients sans réécriture spécifique. La logique d’accès à la donnée n’est plus dupliquée pour chaque framework. On sépare clairement la couche d’orchestration de la couche d’accès aux ressources.
- Isolation des évolutions et réduction du couplage : Les changements d’API sont traités dans le serveur MCP. Le contrat client et serveur reste stable et un seul serveur exposant la donnée est à maintenir à jour;
Le A2A: Communiquer entre Agents IA
Comme le MCP la communication entre Agents se faisait via un mode de communication prévu alors pour les échanges entre systèmes déterministes “traditionnels” et non entre LLM.
Le protocole A2A, développé par Google apparaît peu après le MCP et se veut explicitement complémentaire: MCP gère l’accès aux ressources pour un agent et A2A coordonne la communication et la délégation entre réseau d’agents.
Pourquoi le A2A
Si nous prenons l’exemple d’une architecture multi agents centralisée (Orchestrateurs et subordonnés). L’agent principal va vouloir déléguer ses tâches à d’autres agents soit
- Spécialisés: pour lui permettre d’acquérir des compétences et expertises supplémentaires.
- Génériques: pour lui permettre de paralléliser et déléguer ses tâches
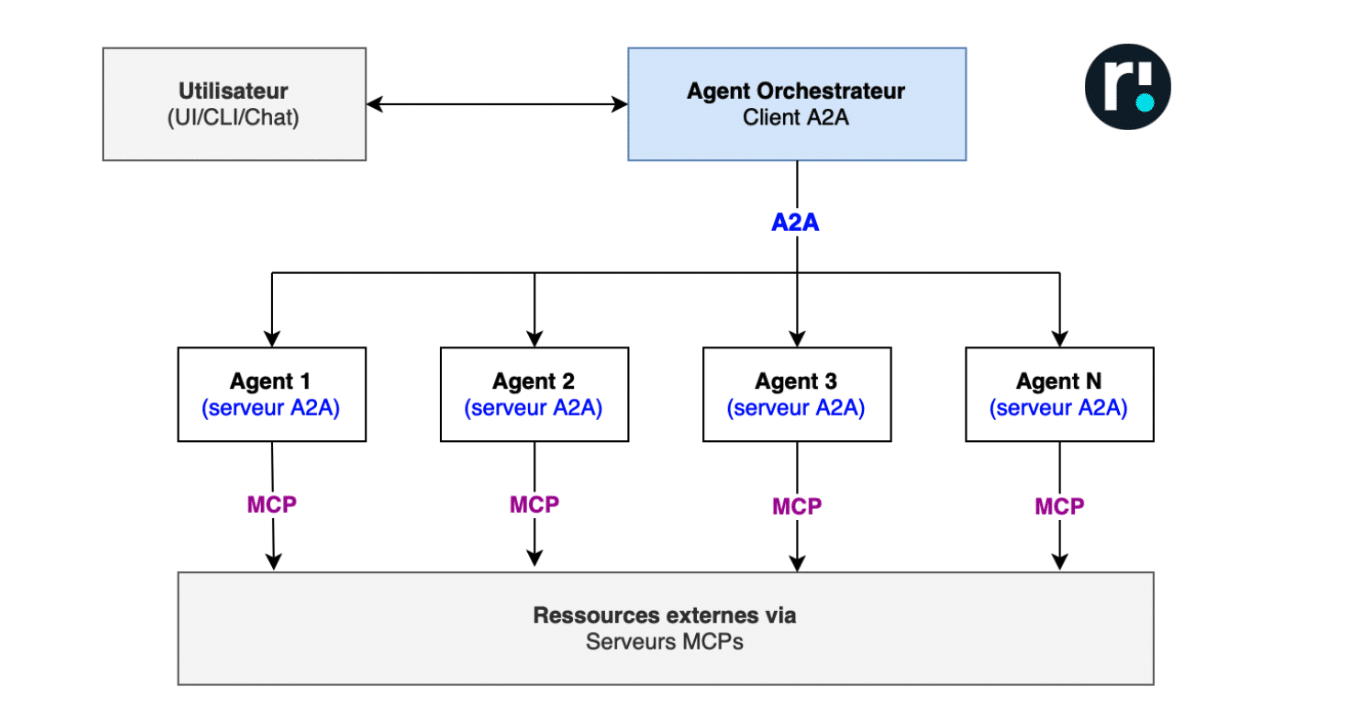
Le protocole A2A va permettre de standardiser cette communication et dynamiser la découverte de capacités, c’est-à-dire permettre à l’agent orchestrateur de savoir quelles sont les capacités des agents à sa disposition afin de filtrer/sélectionner le bon agent pour chaque usage.
Concrètement, il va permettre à chaque agent d’exposer une “Agent Card” qui joue de rôle de fiche descriptive ou carte d’identité listant ce que l’agent sait faire et comment l’utiliser.
Dans cette fiche descriptive, l’agent indique les contraintes et capacités, par exemple les limites d’accès, les scopes autorisés, ou les prérequis pour invoquer une fonction.
Le A2A prévoit notamment la gestion de scopes et permissions, l’authentification envers les agents et un de suivi en temps réel (streaming, notifications) des tâches déléguées, entre autres capacités.
Le A2A comme solution
Le protocole A2A répond à un besoin nouveau : faire communiquer un réseau d’agents, majoritairement pilotés par des LLM, de manière à la fois standardisée et maîtrisée. Concrètement, il permet :
- Standardisation et déterminisme : le standard permet une certaine maîtrise des échanges et de l’exposition des agents. Cela malgré le comportement intrinsèquement non déterministe et parfois chaotique des LLMs.
- Gouvernance et observabilité : La standardisation des règles et du mode de communication entre agents se complète d’autres mécanismes comme le suivi des échanges grâce à du monitoring ainsi que des audit trails par exemple.
- Interopérabilité plug-and-play : Les agents “encapsulés” de façon standard peuvent rejoindre ou quitter un réseau sans nécessiter de réécriture des intégrations.
- Scalabilité : La résultante de ces différents mécanismes est une délégation et coordination plus efficaces entre agents, qu’ils soient spécialisés ou génériques, et ce même dans des réseaux complexes.
Ainsi, A2A transforme un ensemble d’agents en un écosystème coopératif, contrôlable et extensible.
Conclusion
En combinant MCP et A2A, on passe d’un ensemble d’agents et de ressources isolés à un écosystème cohérent, interopérable et scalable, où l’accès aux données et la coordination des agents sont contrôlés, réutilisables et auditables. Ces protocoles ouvrent la voie à des architectures multi-agents robustes, capables de gérer des réseaux complexes d’IA tout en garantissant sécurité, standardisation et évolutivité. Les capacités apportées par l’IA générative et encadrées par ces deux protocoles permettent d’élargir encore plus le champ des possibles en envisageant une industrialisation à large échelle de l’IA générative.
Parlons de votre projet !
Ces articles pourraient vous interesser
11 février 2026

Architecture
Baromètre de souveraineté numérique : de la prise de conscience à l’autonomie stratégique


10 septembre 2025
Architecture